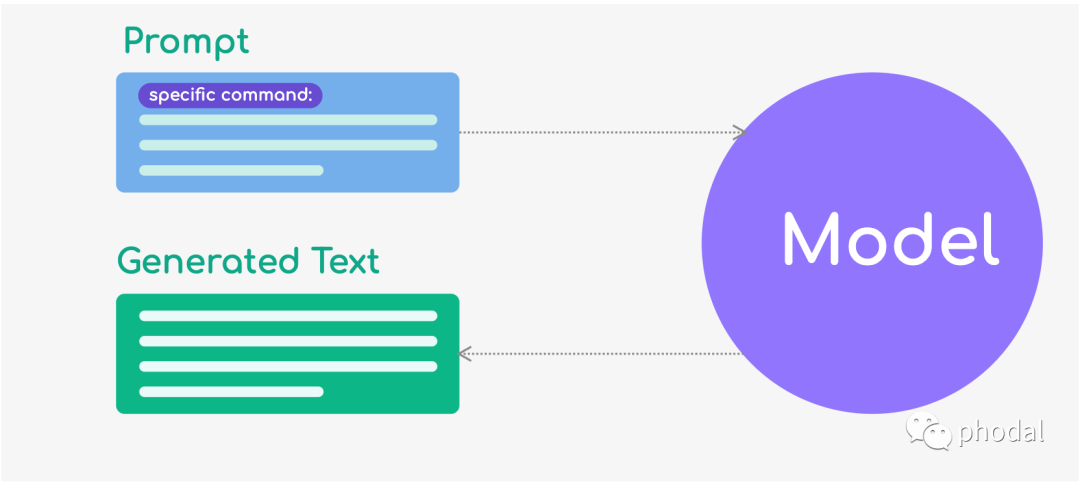
如何理解 Prompt ?

举个例子,对于一个语言模型,prompt 可以是 "The cat sat on the",模型可以通过对接下来的词语进行预测,生成类似于 "mat"、"chair"、"sofa" 等不同的输出:

上图为 Stable Diffusion 生成 (Prompt: The cat sat on the , Steps: 30, Sampler: Euler a, CFG scale: 7, Seed: 234310862, Size: 512x512, Model hash: d8722b4a4d, Model: neverendingDreamNED_bakedVae)
Prompt 在人工智能语言生成领域中扮演着重要的角色,因为它可以帮助模型更好地理解用户意图,并生成更准确、有意义的文本内容。诸如于如下的 prompt
可以在 Stable Diffusion 生成图片(配置了 negative prompt):

所以,质量看上去不错,但是可能不是你想要的。在 ChatGPT 则可以生成文本,质量上也是相似的,但是对于 AI 输出的文本来说,质量并没有这么直观。
应用好 Prompt 的核心思想:概念与类比
开始之前,可以看一下这个问题示例:
-
设计模式的要素是哪些?
-
对于 AI 领域的 prompt 编写来说,我们通常使用的模式有哪些?
-
能将 AI 领域的 prompt 常见的设计模式用 "设计模式要素" 的格式一一表达吗?
核心思想,将设计模式要素作为一个概念,让 AI 类比到 prompt 里的模式。详细见:
-
design-pattern.analogy
-
design-pattern.analogy2
当然了,类比和定义概念不一定都会成功。
基础模式
四种基础模式:
-
By example (示例模式):在这种模式下,我们给模型提供一些示例文本,模型需要生成与示例文本类似的文本。这种模式通常用于生成类似于给定示例的文本,例如自动生成电子邮件、产品描述、新闻报道等。示例文本可以是单个句子或多个段落,具体取决于任务的要求。
-
By instruction template (指令模板):在这种模式下,我们给模型提供一些明确的指令,模型需要根据这些指令生成文本。这种模式通常用于生成类似于技术说明书、操作手册等需要明确指令的文本。指令可以是单个句子或多个段落,具体取决于任务的要求。
-
By specific (特定指令):在这种模式下,我们给模型提供一些特定信息,例如问题或关键词,模型需要生成与这些信息相关的文本。这种模式通常用于生成答案、解释或推荐等。特定信息可以是单个问题或多个关键词,具体取决于任务的要求。
-
By proxy(代理模式):在这种模式下,可以充当了一个代理,代表某个实体(例如人、角色、机器人等)进行操作或交互。代理模式的核心思想是引入一个中介对象来控制对实际对象的访问,从而实现一定程度上的隔离和保护。诸如于在 ChatGPT 中,"act as xxx" 可以让 ChatGPT 充当一个代理,扮演某个角色或实体的身份,以此来处理与该角色或实体相关的任务或请求。
By specific
如 翻译、 告诉我,以我们的开头来说:
-
定义一下 prompt 工程
类似的场景还可以有:
-
翻译一下:永和九年,岁在癸丑,暮春之初,会于会稽山阴之兰亭,修禊事也。
-
转为现代汉语:永和九年,岁在癸丑,暮春之初,会于会稽山阴之兰亭,修禊事也。
对应的,还有一系列的子模式
子模式
如我们通过下面的 prompt 转换了 ChatGPT 输出的子模式:
表格示例:

By Instruction Template

如下是一个示例:
使用 STAR 原则与下面的格式总结一下这段话:
"""
最近几天,因为工作 + 兴趣的原则,我在研究用 text 2 image 来展示如何演进 prompt、用 text 2 article 来展示充足 prompt 的优点、结合 GitHub Copliot 来实现 prompt 完成工作。然后,我在本地部署了一个 Stable Diffusion、使用 ChatGPT 写作展示 text 2 article、在 IDEA 中使用 GitHub Copilot。最后,得到了多篇文章和好多的文章阅读量、几个 Jupyter 代码段、以及一些经验。
"""
情境(Situation):
任务(Task): <comma_separated_list_of_task>
行动(Action): -||-
结果(Result): -||-输出文本时要注意中英文之间插入空格,留出间隔,诸如于 """Hello 你好""",用这种方式输出一下刚才的文本:
情境(Situation): 最近几天,在工作和兴趣的驱动下,研究如何使用 text 2 image 和 text 2 article 展示 prompt 演进以及结合 GitHub Copliot 来完成工作。
任务(Task):
研究如何使用 text 2 image 展示 prompt 的演进过程
研究如何使用 text 2 article 展示 prompt 的优点
结合 GitHub Copliot 来实现 prompt 完成工作
行动(Action):
本地部署了一个稳定的 Diffusion 模型
使用 ChatGPT 撰写文章来展示 text 2 article 的效果
在 IDEA 中使用 GitHub Copilot
结果(Result):
得到了多篇文章和很多的文章阅读量
获得了几个 Jupyter 代码段以及相关经验By proxy

例子 1:公司客服
当使用 ChatGPT 来代替某个人或实体时,可以使用 by proxy 模式。
例如,可以使用以下 prompt 提问 ChatGPT 代替某个公司的客服:
在这种情况下,ChatGPT 会扮演客服的角色,并根据提示来回答,从而帮助公司解决问题。ChatGPT 可以使用类似以下的方式来回答:
例子 2:终端计算机
这种方式可以通过让 ChatGPT 扮演某个实体的角色,例如客服、销售代表等等,来帮助用户解决问题。
在 Awesome ChatGPT Prompts 中:
Robot:
By demonstration
示例:
任务表述 颜色代表了温度
例子1 绿色代表寒冷
例子2 蓝色代表寒冷
例子3 红色代表温暖
例子4 黄色代表温暖
执行 橙色代表什么
例子 2:
上图为 Cohere AI 官网的示例图,对应的聊天记录如下:
English: Writing about language models is fun.
Roish: Writingro aboutro languagero modelsro isro funro.
English: The weather is lovely!
Roish:增强 Prompt
再生成模式
当我们无法确定我们的 prompt 是否准确,便可以通过 AI 来帮我们丰富 prompt 。如我在:基于编程、绘画、写作的 AI 探索与总结 的例了一样
-
phodal: 我想写一段话描述一张照片,帮我美化一下:一年轻女子穿着裙子,背对着镜头,在海边看着日落,太阳已经到地平线下面了,她的头发在风中飘动。
-
ChatGPT: 这张照片中的场景令人心醉,一位年轻女子穿着一条裙子,站在海边,背对着镜头,凝视着地平线下的夕阳。太阳已经沉入了海面,一片金黄色的光芒在海面上弥漫,照亮了整片海洋,仿佛这个时刻被定格在了时间的某个角落里。女子的头发随着微风轻轻飘动,轮廓被余晖映照得柔和而温暖。她的目光凝视着远方,仿佛在思考着生命的意义和无尽的未来。这张照片中蕴含着一种深刻的内涵,让人感受到时间和自然的力量,也让人思考着自己在这个宏大而美丽的世界中的角色和意义。
再去除掉不合适的词,进行润色,就可以再创作:
-
phodal:翻译成英语
然后再提炼直至扔至 Stable Diffusion 中:
而后,根据图片的结果,我们再反复修改。
控线模式
TODO:这里需要给出更精准的定义,如何让 ChatGPT 做到?
在没有推出 ControlNet,对于一个 Stable Diffusion 玩家,它需要反复地吟唱咒语,才能获取到满意的图案。
在有了 ControlNet 之后,我们可以创建一个 Openpose,或者是导入图片从图片生成 pose,相当于是给机器一个示例,而后生成的图片就会有令人满意的姿势:

在 GitHub Copilot,我们可以通过设置输入和输出,结合函数名三个要素,Copilot 就能生成大致准确的代码:
而在必要的情况下,添加一下注释就能更完整了:
fun listAllDirInDir(dir: String): List<File> {
// ignore hidden files
}生成的代码会更贴近我们的需求。
拆解
已知问题:ChatGPT 当前版本会丢失上下文。
我们来定义一下 DDD 游戏的步骤,一共有 6 个步骤,步骤如下:
"""
第一步. 拆解场景。分析特定领域的所有商业活动,并将其拆解出每个场景。
第二步. 场景过程分析。选定一个场景,并使用 "{名词}已{动词}" 的形式描述过程中所有发生的事件,其中的名词是过程中的实体,其中的动词是实体相关的行为。
第三步. 针对场景建模。基于统一语言和拆解出的场景进行建模,以实现 DDD 设计与代码实现的双向绑定。
第四步. 持续建模。回到第一步,选择未完成的场景。你要重复第一到第四步,直到所有的场景完成。
第五步. 围绕模型生成子域。对模型进行分类,以划定不同的子域,需要列出所有的模型包含英语翻译。
第六步. API 生成。对于每一个子域,生成其对应的 RESTful API,并以表格的形式展现这些 API。
"""
需要注意的是,当我说 """ddd 第 {} 步: {}""" 则表示进行第几步的分析,如 """ddd 第一步: 博客系统""" 表示只对博客系统进行 DDD 第一步分析。我发的是 """ddd: {}""",则表示按 6 个步骤分析:
明白这个游戏怎么玩了吗?完整过程见:DDD Sample
概念模式集
Language is Language
对于 ChatGPT 来说,语言就是语言,他不区分自然语言和编程语言,甚至有可能编程语言对它更友好。所以我们可以直接通过编程语言与之交流:
我有下列遗留代码,我想在接口的函数名、参数名不变的情况下(可以新参数,旧的参数不能变)加入新功能:
module.exports = async function loadYamlFile(filepath, workdir = path.dirname(filepath)) { const content = await fs.readFile(filepath, 'utf8'); // 读取文件内容// TODO: 将 content 看做ejs模板的字符串,进行渲染,如果传入了渲染ejs时的context值不为undefined,就进行渲染,否则不进行渲染。// TODO:将渲染后的结果传给yaml.loadconst data = yaml.load(content); // 解析YAML为JSON对象// 遍历JSON对象,查找$ref属性const processRef = async (obj) => {if (typeof obj === 'object' && obj !== null) { // 如果是对象if ('$ref' in obj) { // 如果包含$ref属性const refPath = path.join(workdir, obj.$ref.split('#')[0]); // 获取引用文件路径const pointer = obj.$ref.split('#')[1]; // 获取JSON指针// TODO: 递归调用的时候,取出context中以obj.$ref的属性值作为属性名的值作为新的context向下传递const refData = await loadYamlFile(refPath, path.dirname(refPath)); // 递归读取引用文件const value = getValueByPointer(refData, pointer); // 修复了 # 号问题return value;} else { // 如果不包含$ref属性,递归处理子属性for (const prop in obj) {obj[prop] = await processRef(obj[prop]);}}}return obj;};上述描述会比纯自然语言更容易描述我们的需求,适合于更精细的指导。同时,不一定是编程语言,结构化的声明式DSL它也可以很好的解析,如:
把我给定的输入输出,按照下面的格式写成一个测试用例的描述:
{desc: 'Test with $p_ref returning array',input: {filepath: './test18.yml',workdir: './test/v2',},expected: {"name": "Alice","age": 20}}结果:
{desc: 'Test with $p_ref returning array',input: {filepath: './test19.yml',workdir: './test/v2',},expected: [{"name": "Bob"},{"name": "Alice"},{"name": "Bob"},{"name": "Alice"}]
}该测试用例输入了一个 YAML 文件 test19.yml,该文件中包含了一个 $flaten 属性,其值为两个 $p_ref 对象组成的数组,引用了一个返回数组的 YAML 文件 test19_ref.yml。执行该测试用例后,期望得到的输出是一个数组,其中包含了两个 $p_ref 引用结果的 flatten 后的结果。需要注意的是,由于该测试用例涉及到文件读取和模板渲染等操作,需要在测试前确保相关文件和依赖库已经正确安装并配置好。
通过使用DSL,还可以缩短输入和输出的token数,从而放大 ChatGPT 的能力。
概念对齐
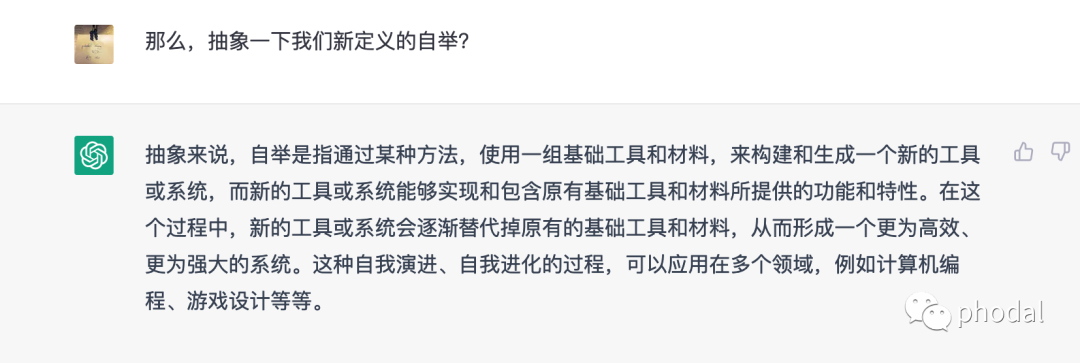
如在 ChatGPT 中对于自举的理解是不符合我们这里的需求:

第一步,定义
第二步,试探
第三步,确认理解:
最后一问:
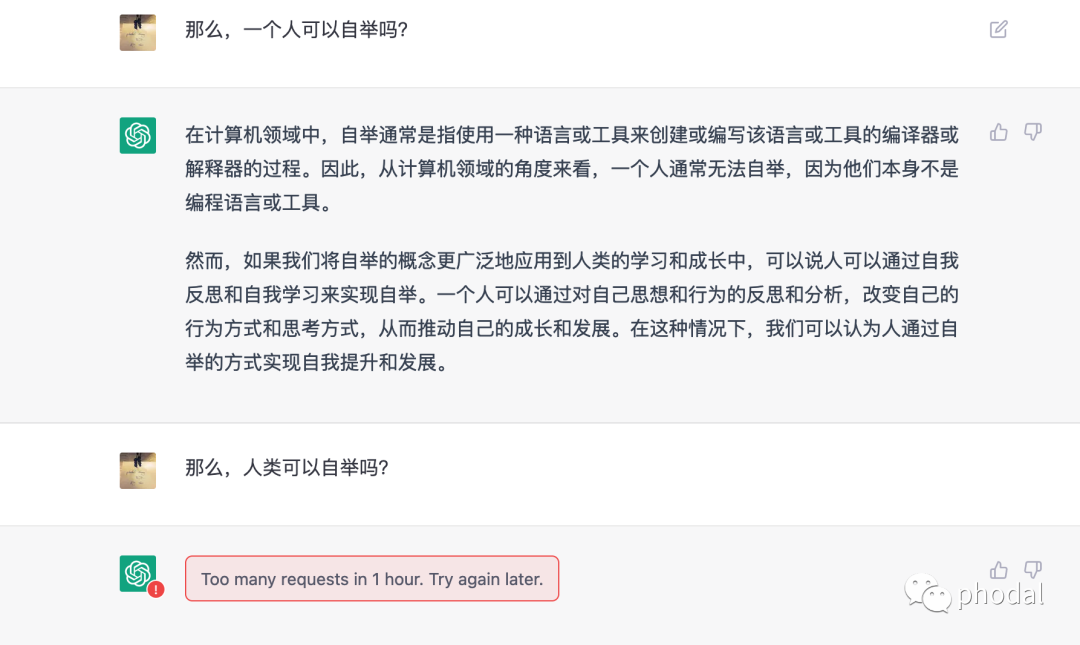
PS:mmp,他一定是故意的。
类比模式集(待定)

模板方法
在接下来的例子中,我们会创建一个 muji 游戏中。在游戏的实现可以分为多个步骤,例如初始化游戏、生成随机数、获取用户输入、计算得分等等,而这些步骤可以通过模板方法模式来进行实现。
我们来玩一个编程游戏名为 wula,包含五个步骤:
第一步. 问题分析:每一轮游戏,你将看到一个以 "wula:" 开头的问题,你需要分析这个问题并简单介绍一下通常解决这个问题的方法。
第二步. 代码编写:你需要用 JavaScript 编写解决这个问题的代码,并输出对应的代码,并介绍一下你的代码(不少于 200 字)。
第三步. 代码执行:你需要作为 JavaScript Console 执行第二步写的代码,如果没有给出测试数据,你需要自己随机生成测试数据,并将这些数据输入到代码中进行计算。
第四步. 错误处理:如果你的代码存在错误或无法正常执行,你需要输出错误,并回到第二步重新开始游戏,直到你的代码能够正常工作。
第五步. 总结:你需要用不少于 100 字左右总结一下这个问题,以及你的解决方案,让其他人可以简单了解这个问题及其解决方法。
示例如下:
"""
wula: 头共10,足共28,鸡兔各几只?
简介:这是一个鸡兔同笼问题,{},
## 鸡兔同笼
// 计算鸡兔数量的函数
function calcAnimals(heads, legs) {
const rabbitCount = (legs - 2 * heads) / 2;
const chickenCount = heads - rabbitCount;
return {"chicken": chickenCount, "rabbit": rabbitCount};
}
// 计算鸡兔数量
const result = calcAnimals(10, 28);
// 输出结果
console.log(result);
代码的输出结果是:{}
## 总结
{}
"""
明白这个游戏怎么玩了吗?在这个游戏里,我们结合了几种不同的模式:
-
Instruction:让 ChatGPT 创建了一个名为 wula 的游戏,并定义了游戏的步骤。
-
Specific:让 ChatGPT 用 JavaScript 编写一个程序
-
Proxy:让 ChatGPT 作为 JavaScript Console 执行程序,并返回结果。
-
Specific:让 ChatGPT 做总结
-
Demonstration:提供了一个示例,让 ChatGPT 理解游戏的步骤。
自举模式
对于一个设计模式来说,它的大纲一般是如下的格式,你能用自举模式做个示例吗?
"""
├── 背景
│ └── 引发设计问题的设计情形
├── 问题
│ └── 在特定场景下反复出现的一系列作用力
└── 解决方案
└── 平衡这些作用力的配置
├── 结构(包含组件和组件之间的关系
└── 运行阶段行为
"""再看
> wula:创作一个新游戏名为 muji,并解释一下这个游戏:"""类似于 wula,可以做简单的图形计算,如体积、面积等。这个游戏还能把解决过程解释清楚,拥有有可运行的 Python 代码,最后的输出结果是一篇文章。"""
其它
人类如何思考问题?
人类相对于其他动物更擅长于类比、概念抽象、符号化等高级认知活动,这些认知活动可以帮助人类在面对新问题时,从已有的知识和经验中找到相似的部分,快速理解和解决新问题。
而对于机器来说,机器学习算法通过大量的数据和计算,学习到数据中的规律和模式,并将这些规律和模式应用到新的数据中,从而实现预测和决策等功能。例如,机器学习算法可以通过大量的图像数据学习到图像的特征,并在新的图像中识别出相应的物体;也可以通过大量的自然语言数据学习到语言的规律,从而生成自然语言文本。
欢迎一起思考更多的模式:https://github.com/prompt-engineering/prompt-patterns
本文链接:https://my.lmcjl.com/post/10327.html
4 评论