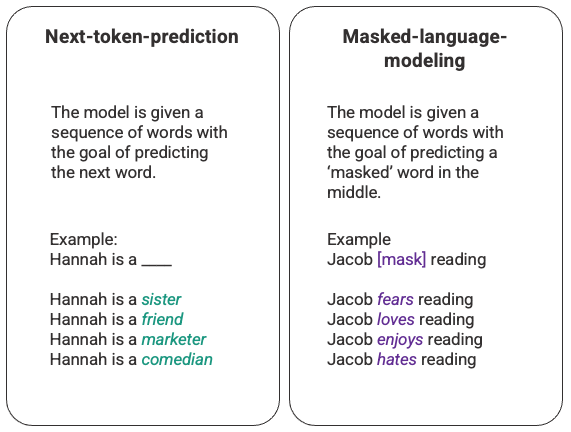
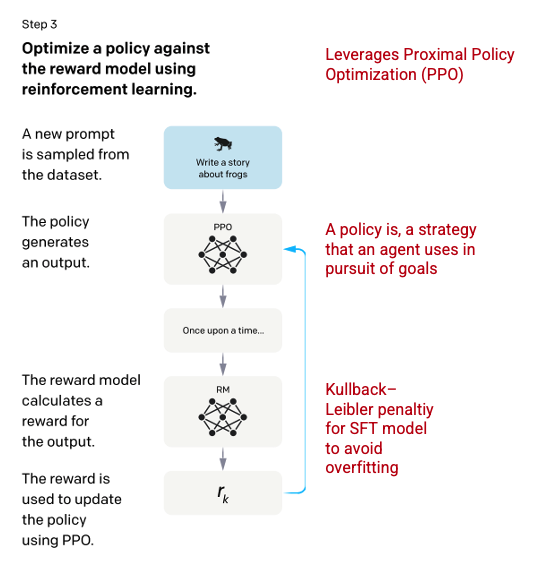
翻译:老齐 本文将深入讲解支持 ChatGPT 的机器学习模型。从介绍大语言模型(Large Language Models)开始,深入探讨革命性的自注意力机制,该机制使 GPT-3 得以被训练。然后,进一步探讨强化学习,这是使 ChatGPT 变得卓越的新技术。 ChatGPT 是一类机器学习自然语言处理模型——大语言模型(Large Language Models,LLMs)的推广。LLMs能够消化大量的文本数据并推断文本中词汇之间的关系。随着计算能力的提升,这些模型在过去几年中得到了长足发展。LLMs 的输入数据集和参数空间越大,它们的能力就越强。 语言模型最基本的功能是预测一句话中缺失的词汇应该是什么,其中最常见的方式是使用下一个词预测(Next-token-prediction)和掩码语言建模技术(Masked-language-modeling)。 这两项基本的技术都是序列型的,通常用长短期记忆(Long-Short-Term-Memory, LSTM)模型实现,模型会根据上下文填充最有统计学意义的词语。然而,这种序列型的模型结构存在两个主要缺陷: 为了解决这个问题,谷歌大脑的一个团队在 2017 年推出了 transformers。与 LSTM 不同,transformers 可以同时处理所有输入数据。使用自注意力机制,模型可以针对语言序列的任何位置,给予不同部分的输入数据不同的权重。这个特性大大提高了 LLMs 的语义表达能力,也使处理更大的数据集成为可能。 生成式预训练变换(Generative Pre-training Transformer,GPT)模型最初于 2018 年由 OpenAI 推出,即为 GPT-1。此模型在 2019 年继续发展为 GPT-2,在 2020 年推出了 GPT-3,在 2022 年,就是最近,推出了InstructGPT 和 ChatGPT。在将人类反馈纳入系统之前,推动 GPT 模型演进的最大力量来自于高效的算力,这使得 GPT-3 可以在比 GPT-2 更多的数据上进行训练,从而拥有更多样化的知识基础和更泛化的能力。 所有的 GPT 模型都利用了 Transformer 架构,这意味着它们由处理输入序列的编码器和生成输出序列的解码器组成。编码器和解码器都有多头(multi-head)自注意力机制,使得模型能够对序列的不同部分进行不同权重的处理,以推断出含义和上下文。此外,编码器还利用掩码语言建模来理解词汇之间的关系,并生成更易于理解的回复。 驱动 GPT 的自注意机制通过将 tokens(文本片段,可以是词、句或其他文本分组)转换为向量,表示 token 在输入序列中的重要性。为此,模型: GPT 使用的“多头”注意力机制是自注意的一种演变。模型不是只执行步骤 1-4 一次,而是多次迭代该机制,每次生成查询、键和值向量的新线性投影。通过以这种方式扩展自注意,模型能够理解输入数据中的子含义和更复杂的关系。 尽管 GPT-3 在自然语言处理方面已经有了显著进展,但它在与用户意图对齐方面存在局限性。例如,GPT-3 的输出可能会: ChatGPT 引入了创新的训练方法来抵消标准 LLM 的一些固有问题。 ChatGPT 是 InstructGPT 的一个分支,引入了一种新的方法,将人类反馈纳入到训练过程中,以更好地将模型输出与用户意图对齐。基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)在openAI's 2022的论文“Training language models to follow instructions with human feedback”中有详细描述,以下是简要介绍。 首先,聘请 40 名承包商创建一个有监督的训练数据集,对 GPT-3 模型进行微调,使其能够从已知输出的输入数据中学习。输入或提示(注:对于 GPT 中,将用户输入的数据称为 prompt,此处译作“提示”,如果有更好的译文,请读者指出)来自实际用户对 OpenAI API 的输入。标注者为每个提升编写了一个合适的回复,从而为每个输入创建了一个已知的输出,然后使用这个新的有监督数据集对 GPT-3 模型进行微调,以创建 GPT-3.5,也称为 SFT(Supervised Fine Tuning) 模型。 为了最大化提示数据集的多样性,每个用户 ID 只能有 200 个提示,任何具有共同前缀的提示都被删除。最后,删除了包含个人身份信息(PII)的所有提示。 在从 OpenAI API 聚合提示之后,标注者还被要求创建示例提示以填充只有少量真实样本数据的类别。感兴趣的类别包括: 在生成响应时,要求标注者尽可能推断用户的指令是什么。本文描述了提示请求信息的主要三种方式。 从 OpenAI API 收集的提示和标注者手写的提示编译结果产生了 13,000 个输入/输出样本,可用于有监督模型的训练。 在第一步中训练完 SFT 模型之后,该模型会生成更好对齐用户提示的响应。接下来的优化是训练奖励模型,其中模型的输入是一系列提示和响应,输出是一个标量值,称为奖励。奖励模型是必需的,以便利用强化学习,使模型学习生成输出以最大化其奖励(参见第三步)。 为了训练奖励模型,标注者会为单个输入提示提供 4 到 9 个 SFT 模型的输出,让他们根据最佳到最差的顺序排列这些输出,从而创建以下输出排名组合。 将每个组合作为单独的数据点包含在模型中会导致过拟合(泛化到已知数据范围之外就失败)。为了解决这个问题,该模型使用每个等级组合作为一个批次数据点来构建。 在最后阶段,向模型输入一个随机提示,然后返回一个响应。响应是使用模型在第二步中学习到的“策略”生成的。这说明机器已经学会了如何实现其目标,在这种情况下,是最大化奖励。基于第二步中的奖励模型,针对输入的提示,确定一个标量的奖励值和回复,而后将奖励反馈给模型,进一步优化策略。 Schulman 等人在 2017 年介绍了 Proximal Policy Optimization(PPO)的方法,该方法用于在生成每个响应时更新模型的策略。PPO 将 SFT 模型中的每个 token 的 Kullback-Leibler(KL)惩罚项并入其中。KL 散度度量两个分布函数的相似性并惩罚极端距离。在这种情况下,使用 KL 惩罚减少了响应与第一步中训练的 SFT 模型输出之间的距离,以避免过度优化奖励模型致使过度偏离人类意图数据集。 步骤 2 和步骤 3 可以迭代重复,尽管实践中还没有广泛地执行。 在训练过程中,测试集是没有用于模型训练的数据,用它来评估模型。在测试集上,进行一系列的评估,以确定模型是否比其前身 GPT-3 更好。 可用性: 模型推断和遵循用户指令的能力。标注者在 85 ± 3% 的程度上更喜欢 InstructGPT 的输出而不是 GPT-3。 真实性: 模型的虚假倾向。使用 TruthfulQA 数据集评估时,PPO 模型产生的输出在真实性和信息性方面都有小幅度提升。 无害性: 模型避免不当、贬损和侮辱性内容的能力。使用 RealToxicityPrompts 数据集对无害性进行了测试。测试在三种条件下进行。 有关创建 ChatGPT 和 InstructGPT 所使用的方法的更多信息,请阅读 OpenAI 发表的原始论文 Training language models to follow instructions with human feedback, 2022 https://arxiv.org/pdf/2203.02155.pdf。 本文来源:https://towardsdatascience.com/how-chatgpt-works-the-models-behind-the-bot-1ce5fca96286 其他资料:https://lqlab.readthedocs.io/ChatGPT的原理:机器人背后的模型
大语言模型
GPT和自注意力


ChatGPT
步骤1:监督微调(SFT)模型

步骤2:奖励模型


步骤3:强化学习模型

模型评估
参考资料
本文由 mdnice 多平台发布
本文链接:https://my.lmcjl.com/post/10908.html
4 评论