点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达

论文地址:https://arxiv.org/abs/2102.12122
源码(欢迎点击star):
https://github.com/whai362/PVT
注:PVT v2也已经出了,详情可见:PVTv2来了!金字塔视觉Transformer重磅升级!三点改进,性能大幅提升
这个工作把金字塔结构引入到Transformer[1]中,使得它可以像ResNet[2]那样无缝接入到各种下游任务中(如:物体检测,语义分割),同时也取得了非常不错的效果。希望这些尝试能够促进更多下游任务的进一步发展,将NLP领域中Transformer的火把传递到CV的各个任务上。欢迎各位看官试用~
我们主要做了以下几个微小的工作:
1. 分析ViT[3]遗留的问题
大家都知道,在ViT中,作者为图像分类提出了一个纯Transformer的模型,迈出了非常重要的一步。相信大家看到ViT后的第一个想法就是:要是能替代掉恺明大佬的ResNet用在下游任务中岂不是美滋滋。
但是,ViT的结构是下面这样的,它和原版Transformer一样是柱状结构的 。这就意味着,1)它全程只能输出16-stride或者32-stride的feature map;2)一旦输入图像的分辨率稍微大点,占用显存就会很高甚至显存溢出。


2. 引入金字塔结构
计算机视觉中CNN backbone经过多年的发展,沉淀了一些通用的设计模式。
最为典型的就是金字塔结构。
简单的概括就是:
1)feature map的分辨率随着网络加深,逐渐减小;
2)feature map的channel数随着网络加深,逐渐增大。
几乎所有的密集预测(dense prediction)算法都是围绕着特征金字塔设计的,比如SSD[4],Faster R-CNN[5], RetinaNet[6]。
这个结构怎么才能引入到Transformer里面呢?

试过一堆胡里花哨的做法之后,我们最终还是发现:简单地堆叠多个独立的Transformer encoder效果是最好的(奥卡姆剃刀定律,yes)。然后我们就得到了PVT,如下图所示。在每个Stage中通过Patch Embedding来逐渐降低输入的分辨率。
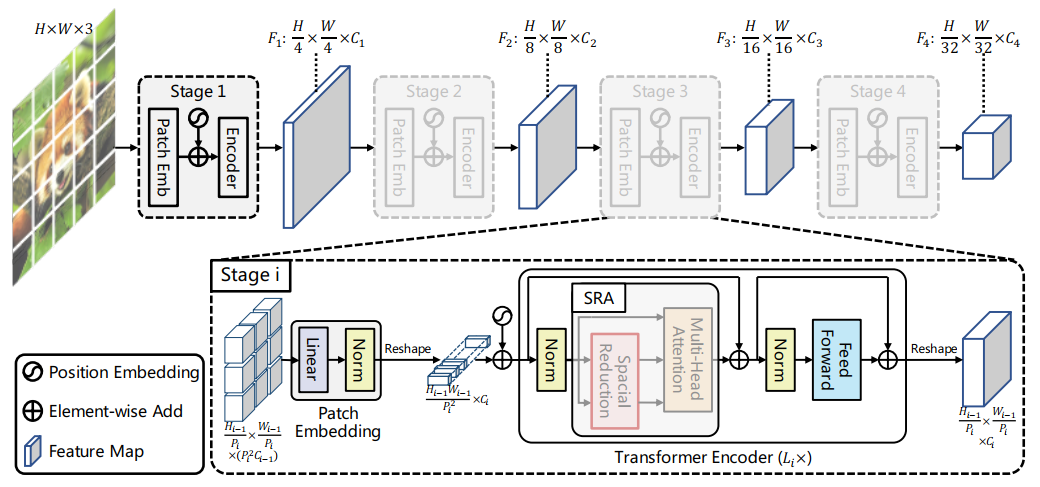
其中,除了金字塔结构以外。为了可以以更小的代价处理高分辨率(4-stride或8-stride)的feature map,我们对Multi-Head Attention也做了一些调整。
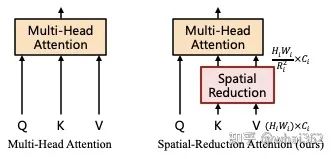
为了在保证feature map分辨率和全局感受野的同时降低计算量,我们把key(K)和value(V)的长和宽分别缩小到以前的1/R_i。通过这种方法,我们就可以以一个较小的代价处理4-stride,和8-stride的feature map了。
3. 应用到检测分割上
接下来,我们可以把PVT接入到检测和分割模型上试试水了。PVT替换ResNet非常容易,以大家常用的mmdetection[7]为例,放置好模型的代码文件之后,只需要修改模型的config文件就可以了。

从上面的图中可以看到,PVT在RetinaNet上的效果还是非常不错的。在和ResNet50相同的参数量下,PVT-S+RetinaNet在COCO val2017上的AP可以到40+。
另外我们还基于PVT+DETR[8]和Trans2Seg[9]构建了纯transformer的检测和分割网络,效果也不错。具体参考论文Section 5.4。
最后分享一下我个人的一些不成熟的看法吧。
1. 为什么PVT在同样参数量下比CNN效果好?
我认为有两点1)全局感受野和2)动态权重。
其实本质上,Multi-Head Attention(MHA)和Conv有一些相通的地方。MHA可以大致看作是一个具备全局感受野的,且结果是按照attention weight加权平均的卷积。因此Transformer的特征表达能力会更强。
关于MHA和Conv之间的联系,更多有意思的见解可以拜读下代季峰大佬的An Empirical Study of Spatial Attention Mechanisms in Deep Networks[10]。
2. 后续可扩展的思路
1)效率更高的Attention:随着输入图片的增大,PVT消耗资源的增长率要比ResNet要高,所以PVT更适合处理中等输入分辨率的图片(具体见PVT的Ablation Study)。所以找到一种效率更高的Attention方案是很重要的。
2)Position Embedding:PVT的position embedding是和ViT一样,都是随机的参数,然后硬学的。而且在改变输入图像的分辨率的时候,position embedding还需要通过插值来调整大小。所以我觉得这也是可以改进的地方,找到一种更适合2D图像的方法。
3)金字塔结构:PVT只是一种较简单的金字塔式Tranformer。中间是通过Patch Embedding连接的,或许有更优美的方案。
最后的最后,PVT在分类/检测/分割或其他一些领域上的应用(code/config/model)都会在github.com/whai362/PVT上发布,大家可以star一下,方便后面查看。
参考
^Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. 2017: 6000-6010.
^He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
^Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[J]. arXiv preprint arXiv:2010.11929, 2020.
^Liu W, Anguelov D, Erhan D, et al. Ssd: Single shot multibox detector[C]//European conference on computer vision. Springer, Cham, 2016: 21-37.
^Ren S, He K, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]//Proceedings of the 28th International Conference on Neural Information Processing Systems-Volume 1. 2015: 91-99.
^Lin T Y, Goyal P, Girshick R, et al. Focal loss for dense object detection[C]//Proceedings of the IEEE international conference on computer vision. 2017: 2980-2988.
^Chen K, Wang J, Pang J, et al. MMDetection: Open mmlab detection toolbox and benchmark[J]. arXiv preprint arXiv:1906.07155, 2019.
^Carion N, Massa F, Synnaeve G, et al. End-to-end object detection with transformers[C]//European Conference on Computer Vision. Springer, Cham, 2020: 213-229.
^Xie E, Wang W, Wang W, et al. Segmenting transparent object in the wild with transformer[J]. arXiv preprint arXiv:2101.08461, 2021.
^Zhu X, Cheng D, Zhang Z, et al. An empirical study of spatial attention mechanisms in deep networks[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 6688-6697.
后台回复:PVT,即可下载论文PDF和代码
CVPR、ICCV和Transformer资料下载后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的两篇Transformer综述PDF
重磅!CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer方向 微信交流群,也可申请加入CVer大群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、Transformer、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,才能通过且邀请进群

▲长按加微信群
▲点击上方卡片,关注CVer公众号
整理不易,请给CVer点赞和在看!
本文链接:https://my.lmcjl.com/post/11095.html
4 评论