在MAC的Anaconda上使用pyspark,主要包括以下步骤:
- 在MAC下安装Spark,并配置环境变量。
- 在Anaconda中安装引用pyspark。
1. MAC下安装Spark
到Apark Spark官网上下载Spark文件,无论是windows系统,还是MAC系统,亦或者Linux系统,都可以下载这个文件(独立于系统)。

将下载的文件进行解压(可以使用命令行进行解压,也可以使用解压软件)。解压之后的文件如下:
配置环境变量。打开MAC命令行窗口,输入如下命令:
sudo vi ~/.bash_profile #bash_profile是当前用户的环境变量文件
打开bash_profile文件,并在该文件中增加以下两行命令:
export SPARK_HOME="/Users/sherry/documents/spark/spark-3.1.2-bin-hadoop2.7" #spark文件的完整解压目录
export PATH=${PATH}:${SPARK_HOME}/bin
如下图

保存并退出之后,运行以下命令:
source ~/.bash_profile #让修改的bash_profile生效 echo $PATH #查看环境变量,可以看到新增的路径名
一般MAC上使用的是zsh的shell工具,需要修改zshrc文件来使环境变量永久生效(若不修改该文件,在命令行中输入spark- shell或者pyspark时可能会提示zsh:command not found:pyspark 或 zsh:command not found spark-shell )。输入以下命令:
vi ~/.zshrc
修改该文件,添加如下命令:
if [ -f ~/.bash_profile ]; then
source ~/.bash_profile
fi
保存并退出即可。下面来验证spark是否正确安装,具体如下:
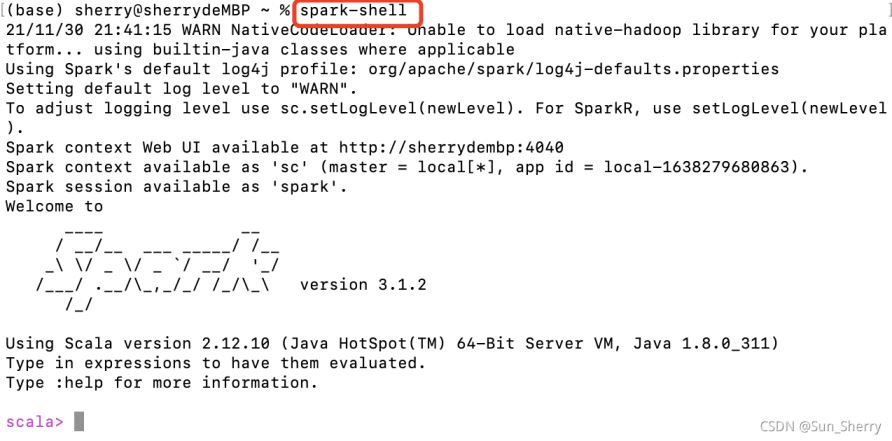
(1)命令行中输入spark-shell
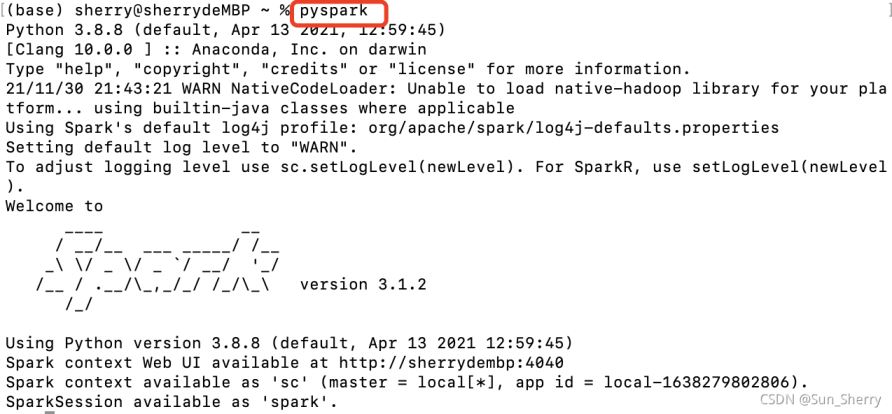
(2)命令行中输入pyspark
至此,spark已经安装成功。
2.在Anaconda中引用pyspark
想要在Anacond中使用pyspark, 只需将spark解压文件中python文件夹下的pyspark复制到Anaconda下的site-packages文件中。下面来验证一下是否能在spyder中使用pyspark, 使用如下代码:
from pyspark import SparkContext, SparkConf
if __name__ == "__main__":
spark_conf = SparkConf()\
.setAppName('Python_Spark_WordCount')\
.setMaster('local[2]')
#使用spark最原始的API进行数据分析
sc = SparkContext(conf=spark_conf)
sc.setLogLevel('WARN')
print (sc)
# ------创建RDD,需要分析的数据 --------------------------------------
def local_rdd(spark_context):
datas = ['hadoop spark','hadoop hive spark','hadoop hive spark',\
'hadoop python spark','hadoop python spark',]
return spark_context.parallelize(datas)
rdd = local_rdd(sc)
print (rdd.count())
print (rdd.first())
sc.stop()
运行发现提示如下错误:

从提示信息可以知道,找不到SPARK_HOME。可以在上述主函数中增加如下代码:
import os #添加spark安装目录 os.environ['SPARK_HOME'] ='/Users/sherry/documents/spark/spark-3.1.2-bin-hadoop2.7'
重新运行即可得到如下结果:
本文链接:https://my.lmcjl.com/post/11493.html
4 评论