SQL语言是一门简单易学却又功能强大的语言,它能让你快速上手并写出比较复杂的查询语句。但对于大多数开发者来说,使用SQL查询数据库并没有一个抽象的过程和一个合理的步骤,这很可能会使在写一些特定的SQL查询语句来解决特定问题时被”卡”住,本系列文章主要讲述SQL查询时一些基本的理论,以及写查询语句的抽象思路。
SQL查询简介
SQL语言起源于1970年E.J.Codd发表的关系数据库理论,所以SQL是为关系数据库服务的。而对于SQL查询,是指从数据库中取得数据的子集,这句话貌似听着有些晦涩是吧,下面通过几张图片简单说明一下:
假如一个数据库中只有一个表,再假如所有数据如下图(取自AdventureWork示例数据库):
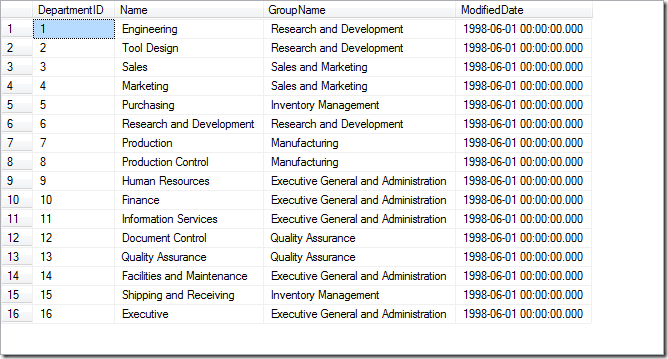
而对于子集的概念,look下图:
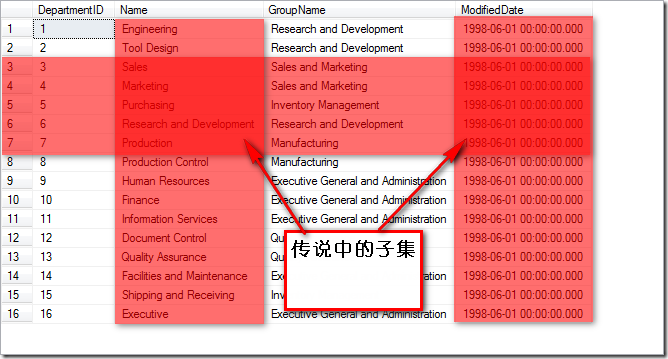
最后,子集如下:
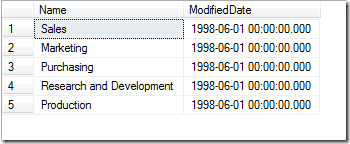
其实,SQL中无论多复杂的查询,都可以抽象成如上面的过程.
精确查询的前置条件
对于正确取得所需要的数据子集.除了需要思路正确并将思路正确转变为对应SQL查询语句之外。还有很重要的一点是需要数据库有着良好的设计.这里的良好设计我所指的是数据库的设计符合业务逻辑并至少实现第三范式,对于实现第三范式,这只是我个人观点,对于范式的简单介绍,请看我的博客:数据库范式那些事.如果数据库设计很糟糕,存在很多冗余,数据库中信息存在大量异常,则即使SQL写的正确,也无法取得精确的结果。
两种方式,同一种结果
在SQL中,取得相同的数据子集可以用不同的思路或不同的SQL语句,因为SQL源于关系数据库理论,而关系数据库理论又源于数学,思考如何构建查询语句时,都可以抽象为两种方法:
1.关系代数法
关系代数法的思路是对数据库进行分步操作,最后取得想要的结果.
比如如下语句:
复制代码代码如下:
Select Name,Department,Age
From Employee
where Age>20
关系代数的思路描述上面语句为:对表Employee表进行投影(选择列)操作,然后对结果进行筛选,只取得年龄大于20的结果.
2.关系演算法
相比较关系代数法而言,关系演算法更多关注的是取得数据所满足的条件.上面SQL可以用关系演算法被描述为:我想得到所有年龄大于20的员工的姓名,部门和年龄。
为什么需要两种方法
对于简单的查询语句来说,上面两种方法都不需要.用脚就可以想出来了。问题在于很多查询语句都会非常复杂。对于关系演算法来说更多的是关注的是所取出信息所满足的条件,而对于关系代数法来说,更多关注的是如何取出特定的信息.简单的说,关系演算法表示的是”what”,而关系代数法表达的是”how”.SQL语句中所透漏的思路,有些时候是关系代数法,有些时候是关系演算法,还有些是两种思路的混合.
对于某些查询情况,关系代数法可能会更简单,而对于另外一些情况,关系演算法则会显得更直接.还有一些情况.我们需要混合两种思路。所以这两种思维方式在写SQL查询时都是必须的.
单表查询
单表查询是所有查询的中间状态,既是多个表的复杂查询在最终进行这种连接后都能够被抽象成单表查询。所以先从单表查询开始。
选择列的子集
根据上面数据子集的说法,选择列是通过在select语句后面添加所要选择的列名实现的:
比如下面数据库中通过在select后面选择相应的列名实现选择列的子集.
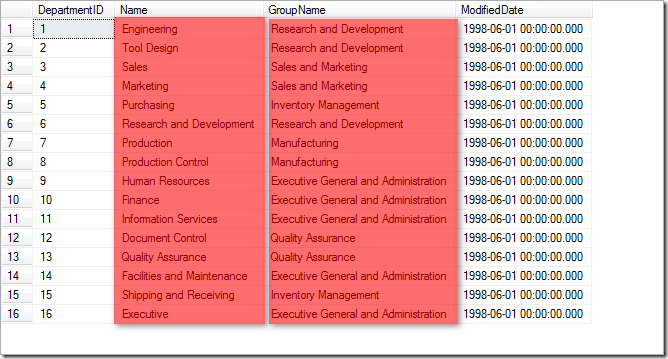
相应sql语句如下:
复制代码代码如下:
SELECT [Name]
,[GroupName]
FROM [AdventureWorks].[HumanResources].[Department]
选择行的子集
选择行的子集是在Sql语句的where子句后面加上相应的限制条件,当where子句后面的表达式为“真”时,也就是满足所谓的“条件”时,相应的行的子集被返回。
where子句后面的运算符分为两类,分别是比较运算符和逻辑运算符.
比较运算符是将两个相同类型的数据进行比较,进而返回布尔类型(bool)的运算符,在SQL中,比较运算符一共有六种,分别为等于(=),小于(<),大于(>),小于或等于(<=),大于或等于(>=)以及不等于(<>),其中小于或等于和大于或等于可以看成是比较运算符和逻辑运算符的结合体。
而逻辑运算符是将两个布尔类型进行连接,并返回一个新的布尔类型的运算符,在SQL中,逻辑运算符通常是将比较运算符返回的布尔类型相连接以最终确定where子句后面满足条件的真假。逻辑运算符一种有三种,与(AND),或(OR),非(NOT).
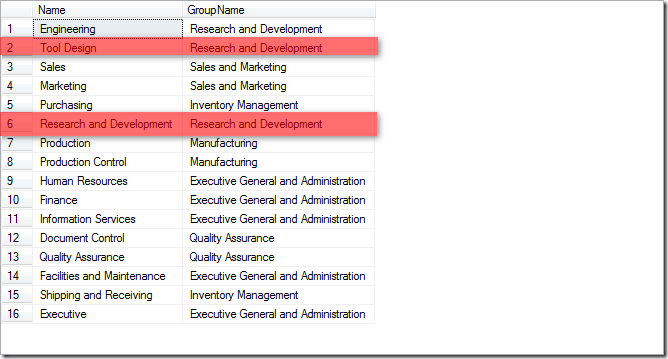
比如上面,我想选择第二条和第六条,为了说明比较运算符和逻辑运算符,可以使用如下Sql语句:
复制代码代码如下:
SELECT [Name]
,[GroupName]
FROM [AdventureWorks].[HumanResources].[Department]
WHERE DepartmentID>1 and DepartmentID<3 or DepartmentID>5 and DepartmentID<7
由此我们可以看出,这几种运算符是有优先级的,优先级由大到小排列是比较运算符>于(And)>非(Or)
当然,运算符也可以通过小括号来改变优先级,对于上面那个表
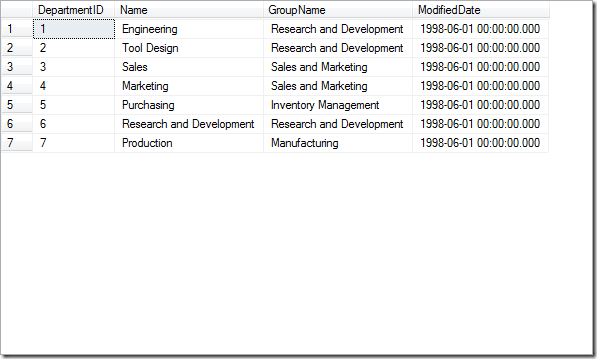
对于不加括号时:
复制代码代码如下:
SELECT *
FROM [AdventureWorks].[HumanResources].[Department]
WHERE DepartmentID>=1 and DepartmentID<=3 and DepartmentID>=5 or DepartmentID<=7
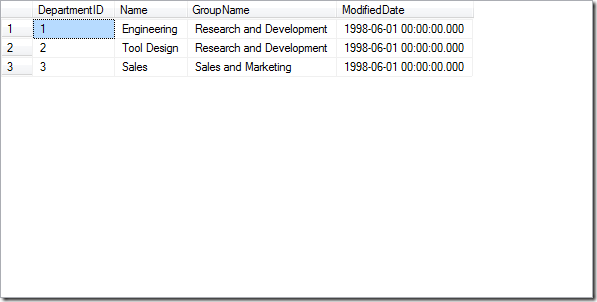
加了括号改变运算顺序后:
复制代码代码如下:
SELECT *
FROM [AdventureWorks].[HumanResources].[Department]
WHERE DepartmentID>=1 and DepartmentID<=3 and (DepartmentID>=5 or DepartmentID<=7)
很特别的NULL
假如在一个用户注册的表中,一些选填信息并不需要用户必须填写,则在数据库中保存为null,这些null值在利用上面where子句后的运算符时,有可能造成数据丢失,比如一个选填信息是性别(Gender),假设下面两条条件子句:
复制代码代码如下:
where Gender="M"
where NOT (Gender="M")
由于null值的存在,这两条语句返回的数据行加起来并不是整个表中的所有数据。所以,当将null值考虑在内时,where后面的条件子句拥有可能的值从真和假,增加为真,假,以及未知(null)。这些是我们在现实世界中想一些问题的时候可能的答案--真的,假的,我不知道。
所以我们如何在这种情况下不丢失数据呢,对于上面的例子来说,如何才能让整个表的数据不被丢失呢,这里必须将除了“真”,“假”以外的“未知”这个选项包含在内,SQL提供了IS NULL来表明未知这个选项:
where Gender IS NULL 将上面语句加入进去,则不会再丢失数据。
排序结果
上面的那些方法都是关于取出数据,而下面是关于将取出的子集进行排序。SQL通过Order by子句来进行排序,Order by子句是Sql查询语句的最后一个子句,也就是说Order by子句之后不能再加任何的子句了。
Order By子句分为升序(ASC)和降序(DESC),如果不指定升序或者降序,则默认为升序(由小到大),而Order by是根据排序依据的数据类型决定,分别为3种数据类型可以进行排序:
字符
数字
时间日期
字符按照字母表进行排序,数字根据数字大小排序,时间日期根据时间的先后进行排序。
其它一些有关的
视图
视图可以看作是一个保存的虚拟表,也可以简单看做是保存的一个查询语句。视图的好处是视图可以根据视图所查询表的内容的改变而改变,打个比方来理解这句话是:
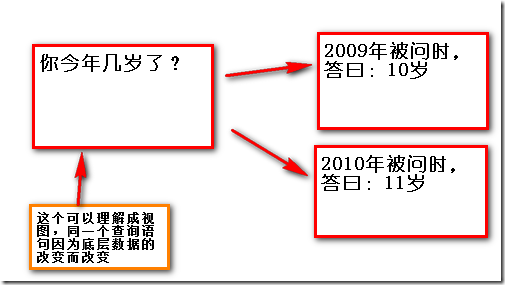
使用视图的优点是可以对查询进行加密以及便于管理,据说还可以优化性能(我不认可这点).
防止重复
有时候我们对于取出的数据子集不想重复,比如你想知道一些特定的员工一共属于几个部门
复制代码代码如下:
SELECT [EmployeeID]
,[DepartmentID]
FROM [AdventureWorks].[HumanResources].[EmployeeDepartmentHistory]
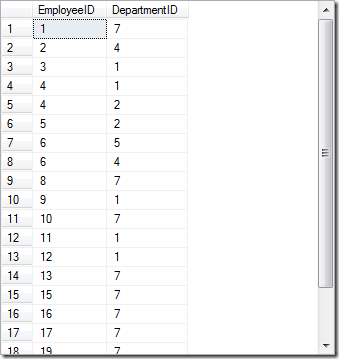
这样的结果是没有意义的,SQL提供了Distinct关键字来实现这点:
复制代码代码如下:
SELECT distinct DepartmentID
FROM [AdventureWorks].[HumanResources].[EmployeeDepartmentHistory]
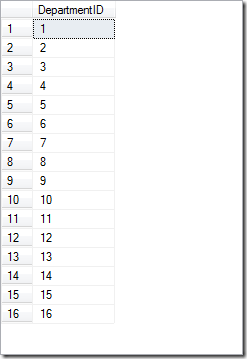
聚合函数
所谓聚合函数,是为了一些特定目的,将同一列多个值聚合为一个,比如我想知道一群人中最大年龄是多少可以利用MAX(Age),比如我想知道一个班级平均测验成绩是多少可以用AVG(Result)……
总结
文章简单概述了SQL查询的原理以及简单的单表查询,这些都是数据库查询的基础概念,对于进行复杂查询来说,弄明白这些概念是必不可少的。
本文链接:https://my.lmcjl.com/post/11925.html
4 评论