边缘智能
作为人工智能领域的当红炸子鸡,深度学习技术近年来得到了学术界与产业界的大力追捧。目前,深度学习技术已在计算机视觉、自然语言处理以及语音识别等领域大放异彩,相关产品正如雨后春笋般涌现。由于深度学习模型需要进行大量的计算,因此基于深度学习的智能通常只存在于具有强大计算能力的云计算数据中心。考虑到当下移动终端设备的高度普及,如何将深度学习模型高效地部署在资源受限的终端设备,从而使得智能更加贴近用户这一问题以及引起了学术界与工业界的高度关注。针对这一难题,边缘智能(Edge Intelligence, EI)技术通过协同终端设备与边缘服务器,来整合二者的计算本地性与强计算能力的互补性优势,从而达到显著降低深度学习模型推理的延迟与能耗的目的。
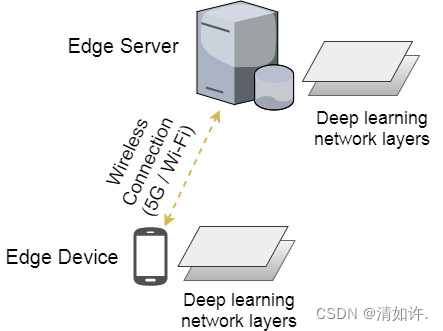
边缘智能的核心研究问题在于如何在资源受限的边缘端高效部署深度学习模型,其中包括边缘设备深度学习模型优化,深度学习计算迁移,边缘服务器与终端设备间的协同调度等问题。
边缘计算驱动实时深度学习
作为人工智能领域的主流技术之一,深度学习近年来得到了学术界与产业界的大力追捧。由于深度学习模型需要进行大量的计算,因此基于深度学习的智能算法通常存在于具有强大计算能力的云计算数据中心。随着移动终端和物联网设备的高速发展与普及,如何突破终端设备资源限制,从而将深度学习模型高效地运行在资源受限的终端设备这一问题已经引发了大量关注。为解决这一难题,可考虑边缘计算赋能人工智能的思路,利用边缘计算就近实时计算的特性,降低深度学习模型推理的时延与能耗。
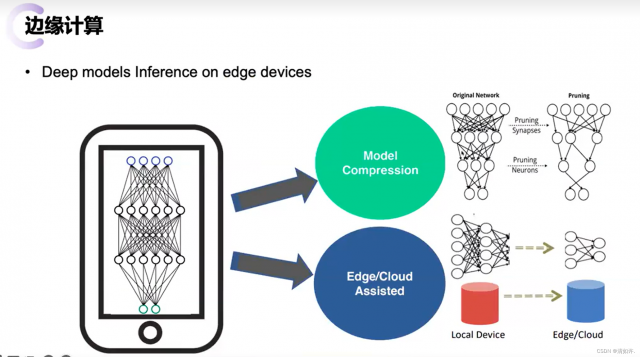
综合运用上述模型切分和模型精简两种方法调整深度学习模型推断时间的优化手段,并小心权衡由此引发的性能与精度之间的折中关系,本文定义如下研究问题:对于给定时延需求的深度学习任务,如何联合优化模型切分和模型精简这种方法,使得在不违反时延需求的同时最大化深度学习模型的精确度。
模型切分
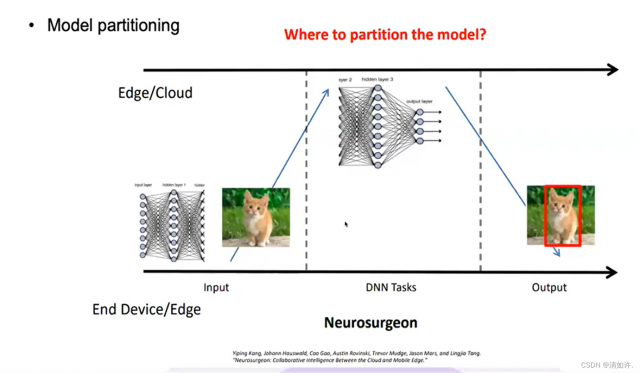
对于常见的常见的深度学习模型,如深度卷积神经网络CNN,是由多层神经网络相互叠加而成。由于不同网络层的计算资源需求以及输出数据量都具有显著的差异性,那么一个直观的想法是将整个深度学习模型切分成两部分,其中计算量大的一部分卸载到边缘端服务器进行计算,而计算量小的一部分则保留在终端设备本地计算,如图2所示。显然,上述终端设备与边缘服务器协同推断的方法能有效降低深度学习模型的推断时延。然而,选择不同的模型切分点降导致不同的计算时间,我们需要选择最佳的模型切分点从而最大化发挥终端与边缘协同的优势。
深度神经网络模型多具有良好的内部结构,如图 4 所示,按照模型的内部结构可通过纵切、横切及混切等方式将模型切分成不同粒度且具有相互依赖关系的模型切片[45],之后将切片按照依赖关系分别部署在云及边缘端. 如采用纵切方式的 DeepThings[46-47],横切方式的 Neurosurgeon[34]、MoDNN[48]、Cogent[49].
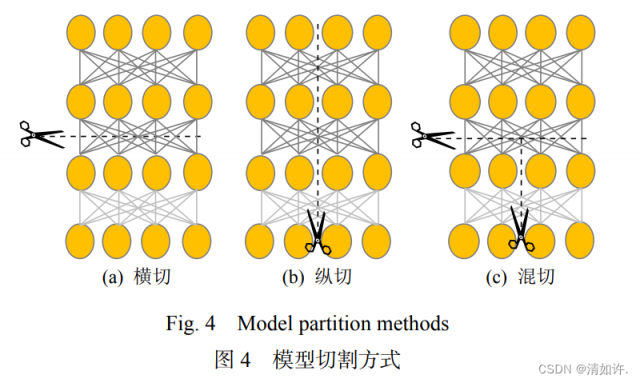
混切方式的 DeepX[50]、AOFL[51]、CRIME[52]、 DeepSlicing[53],以模型切割为主压缩等其他轻量化方法为辅的Edgent[54], ADCNN[55] 等,通过优化资源(能耗、通信或计算等)的代价函数对模型内部的切割点进行枚举,以寻找满足用户或系统需求的切割方案.
模型切割技术在保证模型推理精度不变的前提下,能更好的适应边缘计算. 但由于边缘计算中涉及资源分布广泛、性能不一,尤其是在动态场景下资源地理分布范围广,造成所面临的环境时刻发生变化且不唯一;网络规模变大造成网络拓扑变化;边缘计算场景中计算资源不集中,靠近用户侧,资源发散;应用、网络、设备的异构性等边缘计算资源类型多;由于同一节点运行多种类型服务的情况,资源分配困难使得网络拥堵,服务器波动大;故障频率高、性能波动大、节点协调困难、服务调整趋于被动,存在滞后性并需要分布式思维解决等问题.切割技术中需要引起关注的是切割的整体过程,其中包括切割的执行者、切割时的参考依据如何获取、切片的依赖关系映射、切片更新时间及频率等,这决定了切割的方案在边缘计算环境中的适用性及稳定性,表 1 给出了不同方法的模型切割过程中涉及的关键步骤的比较.

模型压缩
模型早推出
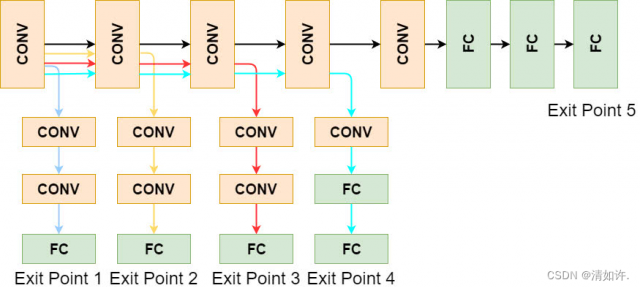
除了对模型进行切分(DNN partitioning),加速深度学习模型推断的另一手段为模型精简(DNN right-sizing),即选择完成时间更快的“小模型”,而非对资源需求更高的“大模型”。如图3所示,对于任意深度学习任务,我们可以离线训练具有多个退出点的分支网络,其中,退出点越靠后,模型越“大”, 准确率也越高但相应地推断时延越大。因此,当深度学习任务的完成时间比较紧迫时,我们可以选择适当地牺牲模型的精确度来换取更优的性能(即时延)。值得注意的是,此时我们需要谨慎权衡性能与精度之间的折衷关系(tradeoff)。
由于边缘节点内存、计算能力、能耗等有限,模型的鲁棒性、稀疏性等允许我们通过张量分解方法对张量降秩处理;通过剪枝剔除影响小的参数对模型进行压缩;通过量化方法降低权重和中间计算结果的位宽,进一步降低模型在内存与计算量上的需求。
在软件优化方面,除了与训练过程结合生成低稀疏性的紧致模型外,还包括对已有模型的处理,处理技术主要包含剪枝与量化 2 种技术.
剪枝
对剪枝而言,从模型的结构出发,可分别对滤波器(filter)、通道(channel)、神经元 等分别或混合进行压缩处理. 在剪枝粒度上,主要包含非结构化剪枝与结构化剪枝 2 种.
非结构化剪枝删除任意位置的权重,其特点是粒度细、压缩率高,如在多次迭代过程中删除冗余参数的知识蒸馏方法. 但非结构化剪枝并不能显著降低计算量且因存在的稀疏性带来额外开销,需要定制化加速器才能完成计算加速.
结构化剪枝中剪枝粒度大,具有良好的加速效果,如通过后继层对前驱层的重要性反馈删除影响小的通道,但此类方法压缩率相对较低. 这促进了对混合粒度的剪枝方法研究,如满足一定结构规则性的基于模式的剪枝方案对卷积内核进行修剪以满足特定模式.
剪枝操作通常会给推理精度带来不利影响,目前主流方法多采用重新训练的方式解决这个问题,但对重新训练而言,由于计算代价大,重新训练比较适用于精度及效率具有重要意义的场景,即需要评估模型部署后所带来的收益与重新训练的代价后才考虑是否选择重新训练.
量化
对量化而言,由于模型的参数量巨大,低位宽的数据表示方法可以极大压缩模型尺寸,提升推理速度. 根据取值范围,可将量化分为 2 值量化、3 值量化、线性量化、非线性量化,其本质是多对一的映射问题. 2 值量化方法中,主要是将权重映射为1 和−1,将激活值映射为 1 和 0;3 值量化主要是在 2 值量化基础上引入额外的 0 来增强所能表达的状态空间;线性量化则主要将原始权重数据量化为连续的对硬件友好的定点;非线性量化通常没有特定的映射规则,也有学者称其为参数共享,如使用不同的哈希映射对网络每一层进行压缩;使用 k-means 聚类实现相近参数的压缩,将最近邻居量化到相同位宽等. 由于数据表示的精度上存在损失,因此,量化方法会对推理精度带来一定影响.
边缘协同推理在动态场景下的挑战与展望
本文从边缘智能出发,简要描述了其发展过程.着重从边缘协同角度对模型推理阶段涉及到的关键技术进行了归纳总结,并从动态场景的角度分别进行了分析. 截至目前,边缘协同智能依然处于快速发展阶段,其大体分为 2 类:一类是基于原有的智能化方法与边缘计算资源特点不断结合(如深度神经网络架构实现搜索、混合精度量化);另一类是直接从边缘计算产生的方法(或称边缘原生方法,如模型选择)结合边缘计算资源的特点(地理分布、异构性、动态性等).目前还存在诸多挑战,下面介绍几个值关注与讨论的方向:
1)推理模型与动态性的适应问题. 以往优化算法较适用于云计算中同质化资源,其资源状态变化不大,一般按需分配、按需扩展,利于结合业务对负载实时调控.然而,在应对具有一定规模的呈地理分布的边缘节点时,由于边缘节点相对于云计算节点的可控性不强,且存在资源异构性及动态性,使当前边缘协同推理智能化的主流方法中还存在一些值得进一步关注的问题,如模型切割技术的整体或部分更新问题;模型压缩技术在不同节点间的可移植性及再训练问题;模型选择/早期退出在面对资源变化时的不同模型问题;分支切换灵活性及资源分配粒度问题. 同时,如 2.2 节所述,尽管目前已经呈现出不同技术的融合态势,但在协同环境下,边缘协同推理智能化方法依旧面临许多共性问题,如已部署模型的更新替换频率及兼容性问题、动态资源变化与所运行模型(或部分)资源需求的匹配问题、额外的中心调度或部署代价问题等.
2)在边缘协同推理验证方面,动态场景建模将促进协同推理相关方法的良性发展. 动态场景下的边缘计算普遍存在硬件故障、系统及软件的负载变化、人为与环境因素的影响、地理分布广泛以及服务状态复杂多变易受影响等特点,运维成为一大挑战.纵观已有研究,在验证思路时多数通过实际的生产场景,或较为简单的代价评估模型模拟,缺乏动态场景特点上的考虑. 造成这种现状的原因,一是生产场景对于广泛的研究人员并不容易可及,二是模拟场景考虑的影响因素不够全面,在边缘协同推理的有效性评估上还存在困难,给边缘协同智能的落地带来一定阻碍. 除此之外,边缘协同推理作为完整应用,还涉及各种网络、计算中间件的运行,这些中间件无一不需要大量的资源来维护. 因此,提供一个可信的动态仿真场景值得研究.
3)在边缘原生方法方面,在线学习与边缘计算的结合或可为边缘协同智能提供更广阔的适用场景.目前多数研究或工作将训练与推理分开,界线清晰,较适合于资源丰富且动态性不强的场景. 但对于涉及计算、网络等资源存在限制且动态的场景,单独的训练过程并不适用,如何利用有限的资源对推理模型进行在线更新值得研究,相关研究领域或可参考感知计算、触觉网络等。
结语
边缘协同推理具有极大的应用价值,目前,正处于快速发展期,但清晰而又统一的处理方法尚未形成,值得我们重点研究. 本文对边缘协同智能的发展历史进行了简要回顾,对推理过程中涉及到的关键技术进行了归纳整理. 通过对不同关键技术的纵向总结、适用场景分析以及技术间的对比等,重点从动态场景角度提出了边缘协同推理存在的挑战与值得发展的方向. 整体来看,边缘协同推理目前还有极大的发展空间,我们未来的研究工作重点将放在动态场景建模以及动态场景下的边缘协同推理可靠性保障方面。
参考文献:
[1]王睿,齐建鹏,陈亮,杨龙.面向边缘智能的协同推理综述[J].计算机研究与发展,2023,60(02):398-414.
[2] Shi Weisong, Zhang Xingzhou, Wang Yifan, et al. Edge computing:Status quo and prospect[J]. Journal of Computer Research and Development, 2019, 56(1): 69−89 (in Chinese)
[3]李恩,周知,陈旭.边缘智能:边缘计算驱动的深度学习加速技术[J].自动化博览,2019(01):48-52.
[4]周知,于帅,陈旭.边缘智能:边缘计算与人工智能融合的新范式[J].大数据,2019,5(02):53-63.
[5] Gao Han, Tian Yulong, Xu Fengyuan, et al. Overview of deep learning model compression and acceleration[J]. Journal of Software, 2021, 32(1): 68−92 (in Chinese)
[6] Wang Xiaofei. Smart edge computing: The bridge from the Internet of everything to the empowerment of everything[J]. People ’s Forum·Academic Frontiers, 2020(9): 6−17 (in Chinese)
等. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . … . . . . . .
本文链接:https://my.lmcjl.com/post/13754.html
4 评论