文章目录
- 1. 布尔检索概述
- 2. 布尔索引方法
- 2.1. 关联矩阵索引
- 2.2. 倒排索引
- 2.2.1. 倒排索引概述
- 2.2.2. 倒排索引建立
- 3. 布尔查询的处理
- 3.1. 布尔查询在倒排表上的操作
- 3.2. AND查询的处理
- 3.3. 布尔查询在倒排表上的优化
- 4. 布尔检索的优缺点
1. 布尔检索概述
针对布尔查询的检索,布尔查询是指利用 AND, OR 或者 NOT操作符将词项连接起来的查询。
例如检索需求:哪些文档包含了Brutus及Caesar二词但不包含Calpurnia一词?
布尔表达式:Brutus AND Caesar AND NOT Calpurnia
2. 布尔索引方法
2.1. 关联矩阵索引
对于规模较小的的文档集(每一个文档中的词项少,文档数量少)。可以对文档集构建词项-文档(term-doc)的关联矩阵,如下图:

在上图中,每一列都是一个关联向量,该向量内的0、1分别表示在文档(蓝色)中是否出现某词项(褐色)。同样的,每一行中的0、1也可以表示该词项(褐色)在文档(蓝色)中出现。
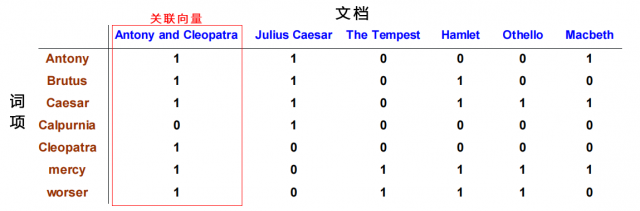
有了这样一个关联矩阵后,就可以进行布尔查询了,回到一开始提到的布尔表达式:Brutus AND Caesar AND NOT Calpurnia,很容易就找出:
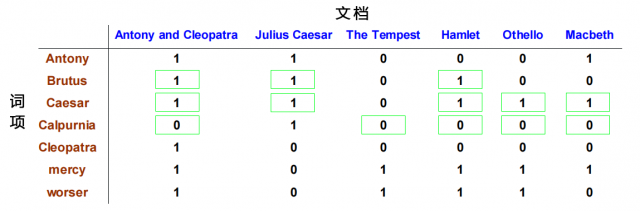
同时满足既有Brutus,又有Caesar,同时没有Calpurnia的文档是Antony and Cleopatra和Hamlet。
2.2. 倒排索引
2.2.1. 倒排索引概述
但是我们很容易发现,一旦文档集变大,关联矩阵的实用性将大大降低。假定现在有一百万篇文档(1M),每篇有1000个词(1K),每个词平均有6个字节,那么所有文档将约占6GB 空间。同时由于庞大的词项数,导致关联矩阵高度稀疏,使关联矩阵的搜索效率不高。
基于此,提出了倒排索引来解决关联矩阵的问题。所谓倒排,是对于关联矩阵而言的,在关联矩阵中,我们统计的是一个文档内出现的词项,这种方法稀疏度高(0很多)。所以我们转换思路,统计一个词项在哪些文档中出现过。
首先,将文档名用文档ID代替,然后按某词出现文档ID序号从小到大排列,例如:

这样建立的索引不再稀疏,同时也无需使用连续空间存储。
2.2.2. 倒排索引建立
(1) 文本预处理
- 词条化(Tokenization)
将字符序列切分为词条,例如将“You are welcome.” 切分为 you、are、welcome三个词条。也需要解决诸如 “John’s”('s怎样处理?),“state-of-the-art” 算一个还是四个词条?的问题; - 规范化(Normalization)
将文档和查询中的词项映射到相同的形式,例如U.S.A. 和 USA应当看做同一个词; - 词干还原(Stemming)
将同一词汇的不同形式还原到词根,例如authorize, authorization是同一词根,在检索时应当都列出,避免用户在检索时可能出现的描述不准确现象; - 停用词去除(Stopwords removal)
去除高频但意义不大词项,例如the、a、to、of。
(2) 建立词条序列
简单来说就是将预处理后的词条和它们所属的文档一起建立<词条, 文档ID>二元组:

(3) 词条排序
首先将词条按某种方法进行排序,例如英文可以根据字母表进行排序;然后对排序后的列表再按文档ID进行排序,确保同一词条对应的ID较小的文档可以排在前面。
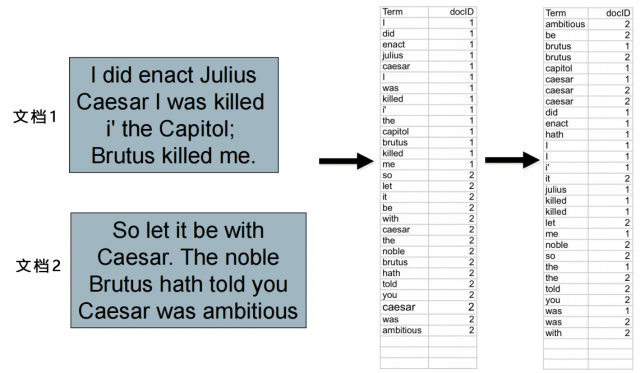
(4) 建立词典和倒排记录表
将出现多次的词项合并,并记录其出现的频数(在几个文档中出现过),之后按文档ID从小到大的顺序建立倒排记录表,并与词典进行链接:
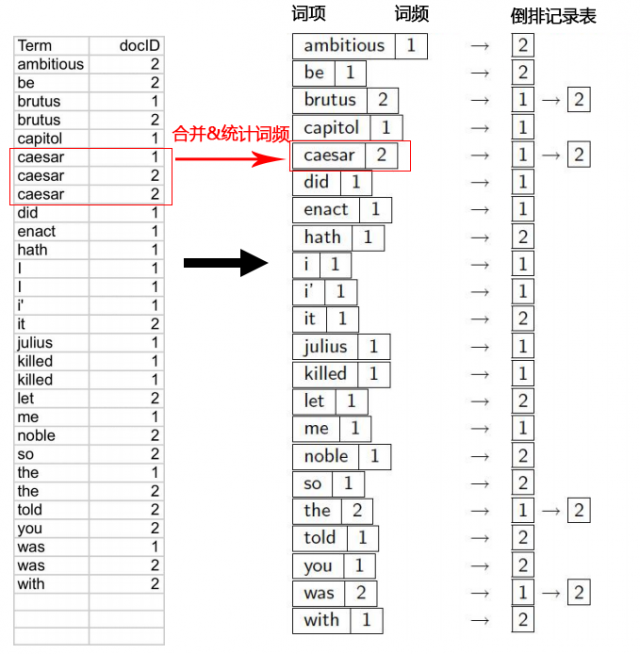
至此,倒排索引已经建立完毕。
3. 布尔查询的处理
3.1. 布尔查询在倒排表上的操作
- AND (Brutus AND Caesar)
两个倒排表的交集 - OR (Brutus OR Caesar)
两个倒排表的并集 - NOT (Brutus AND NOT Caesar)
两个倒排表的减集
3.2. AND查询的处理
考虑实现布尔查询表达式:Brutus AND Caesar
首先应该在词典中定位 Brutus和Caesar,并返回两个词项的倒排表。
然后为每个倒排表定义一个定位指针,两个指针同时从前往后扫描,每次比较当前指针对应的倒排记录,然后再向后移动指向文档ID较小的那个指针或在文档ID相等时同时两个指针,直到某一个倒排表被检索完毕。
这样就能轻易找出符合Brutus AND Caesar的文档,有:文档1、文档2和文档4。
OR和NOT的同理类似,只是对倒排表的操作不同。注意NOT操作不能简单理解为某一词项的补集,因为补集可能会很大,必须是两个倒排表的减集。
3.3. 布尔查询在倒排表上的优化
有两个简单的优化方法:
- 倒排表的文档ID升序排列
正如在AND操作中演示的那样,文档ID升序排列可以尽量地提前结束对倒排表的操作,而不需要对两个倒排表从头到尾进行检索。 - 优先处理词频小的词项
在复杂布尔表达式中,例如(tangerine OR trees) AND (marmalade OR skies) AND (kaleidoscope OR eyes),优先合并词频小的词项,生成文档数量少的词项,有利于结合上面的优化方法尽量地提前结束对倒排表的操作。
4. 布尔检索的优缺点
优点:
- 构建简单,或许是构建IR系统的一种最简单方式;
- 易被接收,仍是目前最主流的检索方式之一;
- 操作专业化,对于非常清楚想要查什么、能得到什么的用户而言,布尔检索是个强有力的检索工具。
缺点:
- 布尔查询构建复杂,不适合普通用户。如果构建不当, 检索结果就会过多或者过少;
- 没有充分利用词项的频率信息;
- 不能对检索结果进行排序。
本文链接:https://my.lmcjl.com/post/14841.html
4 评论