本教程分享了在寒武纪设备上 pytorch-mlu 中添加逐层算子的方法。
pytorch-mlu 逐层模式中算子间数据传递和存储的基本单元是 tensor。pytorch-mlu 根据 tensor 中的 device 属性值将算子分发到不同设备。以 abs() 算子为例,在 dispatch 阶段会根据 input_tensor 的设备属性值将算子调用分发到具体设备,逻辑如下图所示:
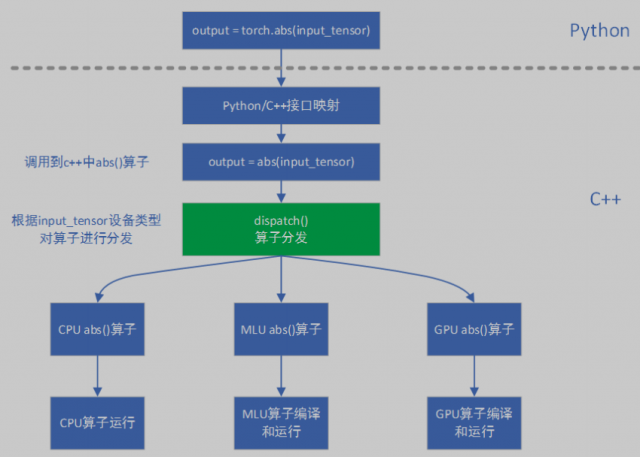
Catch 通过注册添加 MLU 算子方式与 pytorch 源码解耦,下面介绍在 Catch 中添加 MLU 算子的具体步骤。
1、注册算子
在 catch/torch_mlu/csrc/generated/aten_mlu_type_default.cpp 中注册算子:
.op(torch::RegisterOperators::options().schema("aten::add.Tensor(Tensor self, Tensor other, *, Scalar alpha=1) -> Tensor") // NOLINT
.impl_unboxedOnlyKernel<at::Tensor(const at::Tensor &, const at::Tensor &, at::Scalar), &AtenMluType::add>(at::TensorTypeId::MLUTensorId)
aliasAnalysis(c10::AliasAnalysisKind::FROM_SCHEMA))
2、算子分发
AtenMluType 和 AtenMluCustomType 是 Catch 模块中算子的入口。AtenMluType 类主要包含框架中的标准算子;而 AtenMluCustomType 类包含客制化的算子。根据算子属性选择在 AtenMluType 还是 AtenMluCustomType 中添加相应算子声明和实现。
标准算子分发
在 catch/torch_mlu/csrc/aten/aten_mlu_type.h 和 catch/torch_mlu/csrc/aten/aten_mlu_type.cpp 中添加算子声明和实现:
aten_mlu_type.h
static at::Tensor add(const at::Tensor& self, const at::Tensor& other, at::Scalar alpha);
aten_mlu_type.cpp
at::Tensor AtenMluType::add(const at::Tensor& self, const at::Tensor& other, at::Scalar alpha){
return OP_DISPATCH(add, self, other, alpha);
}
客制化算子分发
对于 MLU 特有算子,在 catch/torch_mlu/csrc/aten/aten_mlu_type.h和 catch/torch_mlu/csrc/aten/aten_mlu_custom_type.cpp 中添加算子申明和实现:
aten_mlu_type.h
static at::Tensor linear(const at::Tensor& input,
const at::Tensor& weight,
const at::Tensor& bias,
const at::Tensor& q_scale,
const at::Tensor& q_mode);
aten_mlu_custom_type.cpp
at::Tensor AtenMluCustomType::linear(const at::Tensor& input,
const at::Tensor& weight,
const at::Tensor& bias,
const at::Tensor& q_scale,
const at::Tensor& q_mode){
return OP_DISPATCH(linear, input, weight, bias, q_scale, q_mode);
}
3、修改 OpMethods 基类
从 AtenMluType 和 AtenMluCustomType 中都会通过 OpMethods 下发到推理算子或训练算子。在 catch/torch_mlu/csrc/aten/operators/op_methods.h 和 catch/torch_mlu/csrc/aten/operators/op_methods.cpp 中添加算子申明和实现。OpMethods 中的实现部分为该算子的 CPU 实现。
op_methods.h
virtual at::Tensor add(const at::Tensor& self, const at::Tensor& other, at::Scalar alpha);
op_methods.cpp
at::Tensor OpMethods::add(const at::Tensor& self,
const at::Tensor& other,
at::Scalar alpha){
auto input_cpu = self.cpu();
auto other_cpu = other.cpu();
auto output = at::add(input_cpu, other_cpu, alpha);
return output.to(at::Device(at::Device::Type::MLU));
}
4、下发算子
在 catch/torch_mlu/csrc/aten/operators/cnml_ops.h 和 catch/torch_mlu/csrc/aten/operators/cnml_ops.cpp 中添加推理算子申明和实现。
cnml_ops.h
at::Tensor add(const at::Tensor& self, const at::Tensor& other, at::Scalar alpha);
cnml_ops.cpp
at::Tensor CnmlOps::add(const at::Tensor& self, const at::Tensor& other, at::Scalar alpha){
CNML_DISPATCH(add, cnml_add, self, other, alpha); // CNML_DISPATCH 宏第一个参数是该接口名,第二个参数是wrapper个名字,其余
}
5、添加 wrapper
wrapper 是对算子 kernel 的封装,每个算子对应一个 wrapper。这里以 add 算子为例,添加 wrapper 如下所示:
cnml_kernel.h
at::Tensor cnml_add(const at::Tensor& input, const at::Tensor& other, at::Scalar alpha);
add.cpp
at::Tensor cnml_add(const at::Tensor& input, const at::Tensor& other, at::Scalar alpha_scalar){
TORCH_CHECK(input.dim() >= 0 || other.dim() >= 0, "dimension not support");
at::Tensor input_ = input;
at::Tensor other_ = other;
auto alpha_data = alpha_scalar.to<scalar_t>();
if(alpha_data != 1){
// scale_t
other_ = cnml::ops::cnml_scale(other_, alpha_data, 0);
}
if(other_.dim() < 1 && other_.device().type() == c10::DeviceType::CPU){
auto other_scalar = other_.item();
return cnml_add_internal(input_, other_scalar); // 调用kernel
}
if(input_.dim() < 1 && input_.device().type() == c10::DeviceType::CPU){
auto input_scalar = input_.item();
return cnml_add_internal(other_, input_scalar); // 调用 kernel
}
bool broadcast = input_.sizes() != other_.sizes();
if(broadcast){
auto broadcast_size = at::infer_size(input.sizes(), other.sizes());
at::Tensor broadcast1 = cnml::ops::cnml_expand(input_, broadcast_size, false);
at::Tensor broadcast2 = cnml::ops::cnml_expand(other_, broadcast_size, false);
return cnml_add_internal(broadcast1, broadcast2); // 调用 kernel
}else{
return cnml_add_internal(input_, other_); //调用 kernel
}
return cnml_add_internal(input_, other_); //调用 kernel
}
6、添加 wrapper
Wrapper 中通过调用 kernel 实现算子功能。示例中调用的是 cnml_add_internal。算子的具体实现主要通过调用 CNML 库的接口来完成,下面是 CNML 库的逻辑:

kernel 实现就是按照上述编程逻辑调用 CNML 库接口完成的,在 catch/torch_mlu/csrc/aten/operators/cnml/internal/cnml_internal.h 和 catch/torch_mlu/csrc/aten/operators/cnml/internal/add_internal/cpp 中添加 kernel 函数的声明和实现。
cnml_internal.h
at::Tensor cnml_add_internal(const at::Tensor& input1, const at::Tensor& input2);
add_internal.cpp
at::Tensor cnml_add_internal(const at::Tensor& input1, const at::Tensor& input2){
auto output = at::native::empty_like(input1);
// prepare input cnml tensor
auto* input1_impl = getMluTensorImpl(input1); // 获取MluTensorImpl
auto input1_cnml = input1_impl->CreateCnmlTensor(
CNML_TENSOR, toCnmlDataType(input1.dtype())); // 类型自适应:toCnmlDataType()
auto* input2_impl = getMluTensorImpl(input2);
auto input2_cnml = input2_impl->CreateCnmlTensor(
CNML_TENSOR, toCnmlDataType(input2.dtype()));
// prepare output cnml tensor
auto* output_impl = getMluTensorImpl(output);
auto output_cnml = output_impl->CreateCnmlTensor(
CNML_TENSOR, toCnmlDataType(output.dtype()));
// End the execution flow if not MLU device
CHECK_MLU_DEVICE(output);
// setup operator
cnmlBaseOp_t add_op;
TORCH_CNML_CHECK(cnmlCreateAddOp(&add_op, input1_cnml, input2_cnml, output_cnml));
// return to JIT if running mode is fuse
CHEXK_RETURN_TO_FUSE(add_op, output);
// compile op
TORCH_CNML_CHECK(cnmlCompileBaseOp(add_op, GET_CORE_VERSION, GET_CORE_NUMBER));
auto queue = getCurQueue();
TORCH_CNML_CHECK(cnmlComputeAddOpForward_V4(add_op,
NULL,
input1_impl->raw_mutable_data(),
NULL,
input2_impl->raw_mutable_data(),
NULL,
output_impl->raw_mutable_data(),
queue,
NULL));
syncQueue(queue);
TORCH_CNML_CHECK(cnmlDestroyBaseOp(&add_op));
return output;
}
对 MLU 不支持算子的处理
对于 MLU 暂不支持的操作,输入数据将会拷贝到 CPU 上,然后调用 CPU 相关操作,使其在 CPU 上运行,最后再将输出结果拷会到 MLU 上。具体实现,可以查询 op_methods.cp,该文件在 catch/torch_mlu/csrc/aten/operators/ 目录下。
op_methods.cpp
at::Tensor OpMethods::add(const at::Tensor& self,
const at::Tensor& other,
at::Scalar alpha){
auto input_cpu = self.cpu();
auto other_cpu = other.cpu();
auto output = at::add(input_cpu, other_cpu, alpha);
return output.to(at::Device(at::Device::Type::MLU));
}
对于新增的算子在执行过程中抛出异常时,如果 CPU 上没有对应的算子操作,那么该操作无法切换到 CPU 上运行;
Wrapper一般以 cnml_算子名命名,kernel一般以cnml_算子名_internal命名
7、算子测试
使用基于 python 的 unittest 模块编写算子单元测试。测试时需提供相同的参数和输入数据,分别在 MLU 和 CPU 上执行算子,对比两者的输出结果。MLU 和 CPU 计算结果可能会有差异,一般情况下两者的相对误差在 2% 以内均是可以接受的。
def test_add(self):
# "Tensor + Tensor" mode testing
for shape1, shape2 in [((1,3,224,224),(1,3,224,224)),((2,30,80),(2,30,80)),((3,20),(3,20)),((10),(10))]:
input1_cpu = torch.rand(shape1, dtype=torch.float)
input2_cpu = torch.rand(shape2, dtype=torch.float)
input1_mlu = input1_cpu.to(xm.mlu_device())
input2_mlu = input2_cpu.to(xm.mlu_device())
# 在 CPU 上计算
output_cpu = input1_cpu + input2_cpu
# 在 MLU 上计算
output_mlu = input1_mlu + input2_mlu
# 计算 MLU 的误差,并确保相对误差在 2% 以内
self.assertTensorsEqual(output_cpu, output_mlu.cpu(), 0.02, use_MSE=True)
以上分享了在寒武纪设备 pytorch-mlu 中添加逐层算子的方法,并以 add() 算子为例进行了示例编写,希望我的分享会对你的学习有一点帮助。
到此这篇关于Pytorch-mlu 实现添加逐层算子方法详解的文章就介绍到这了,更多相关Pytorch内容请搜索服务器之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持服务器之家!
原文链接:https://blog.csdn.net/weixin_42405819/article/details/121520614
本文链接:https://my.lmcjl.com/post/16144.html
4 评论