深度学习在解决许多复杂的机器学习问题方面一直是一个有趣的课题,特别是最近在图数据方面。然而,大多数的解决方案要么是监督或半监督,高度依赖于数据中的标签,导致过拟合和整体鲁棒性较弱。自监督学习(Self-Supervised Learning, SSL)是一种很有前途的解决方案,它从无标记数据中挖掘有用的信息,使其成为图数据领域中一个非常有趣的选择。
为什么自监督学习更适合图形数据?
SSL有助于理解图形数据中存在的结构和属性信息,使用标记数据时可能会忽略这些信息
对于现实世界的数据,获取带标签的图形数据非常昂贵且不切实际。 由于图形的常规和复杂数据结构,因此SSL前置任务在这种情况下可以更好地工作
如何在图形数据上进行自我监督学习?
自我监督模型通过执行一些前置任务来帮助学习未标记图形数据中的通用信息。 前置任务是补充任务的组合,这些任务可帮助获取监测信号,而无需手动添加注释的数据
图形数据和定义
图的定义
图是一组节点和一组边。 邻接矩阵用于表示图的拓扑。 节点和边具有自己的属性(特征)的图称为属性图。 异构图具有不止一种类型的节点或边,而同类图则相反。
下游图分析任务的类型
通过神经网络(编码器)从输入图创建嵌入,然后将其馈送到输出头以执行不同的下游任务。 下游任务有三种主要类型,可以归纳如下:
- Node-level 节点级任务是与图形中的节点相关的不同任务,例如,节点分类,其中在少量标记节点上训练的模型会预测其余节点的标签。
- Link-level 链接级任务专注于节点的边缘和表示形式,例如,链接预测,其目标是识别边缘之间的任何连接。
- Graph-leve 图级任务以图形表示为目标,它们从多个图中学习并预测单个图的属性。
自监督训练

根据图编码器,自监督的前置任务和下游任务之间的关系,自监督的训练方案可以分为以下三种类型:
- 预训练和微调是第一种训练方案,其中在编码器中预先进行预置任务,然后在特定下游任务中进行微调。
- 联合学习是一种将编码器与前置任务和下游任务一起进行预训练的方案。
- 无监督表示学习,其中先使用前置任务对编码器进行预训练,然后在使用下游任务训练模型时冻结编码器的参数。 在此训练方案中,在编码器训练期间没有监督。
图自监督学习的类型
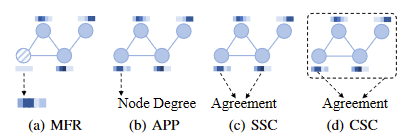
在本节中,我们将探讨图自我监督学习中的四种不同类别的预设设计技术-
蒙版特征回归(MFR)
此技术用于计算机视觉中的图像修复,该过程是通过填充图像的蒙版像素来恢复损坏的图像的过程。 在图形数据的上下文中,节点和边的特征被零或其他标记掩盖。 此步骤之后,目标是使用图形神经网络(GNN)根据未屏蔽的数据恢复被屏蔽的特征。
就图数据而言,该分支的现有方法可以总结如下:
- 屏蔽节点特征回归图补全—通过启用GNN从上下文中提取特征
- AttributeMask —它的目标是重建经过PCA处理的密集特征矩阵
- AttrMasking —通过用特殊的掩码替换边和节点的属性,强制GNN同时重建它们
- 重构技术-从干净或损坏的输入中重构特征或嵌入,并使用它们以联合学习的方式训练编码器
辅助性能预测(APP)
该分支可用于理解底层图的结构和属性信息,提取自我监督信号。这可以使用分类或基于回归的方法来完成,如下所示
- 基于回归的方法(R-APP)——在这种方法中,学习了图的局部属性,例如,关于图的整体结构的代表性节点属性。然后,利用这些信息可以根据图中预定义的簇预测未标记节点的属性
- 基于分类的方法(C-APP)——与R-APP相比,这种方法依赖于构建伪标签。在训练过程中分配伪标签并使用这些自我监督标签(属性)、基于固有拓扑(基于结构)对节点进行分组、图属性预测(节点的统计属性和节点的中心性)是基于分类方法(C-APP)的一些例子。
同比例对比(SSC)
通过预测图中两个元素之间的相似性(例如,节点-节点对比或图-图对比)来学习方法的这一分支。 此方法的不同分支可以总结如下-
- 基于上下文的方法(C-SSC)-此方法的主要思想是在嵌入空间中拉近上下文节点。 假设上下文相似的节点更可能在图中互连
- 基于增强的方法(A-SSC)-通过这种方法从原始数据样本生成增强的数据样本,并将来自同一来源的样本视为正对,而来自不同来源的样本视为负对
跨尺度对比(CSC)
与SSC相反,此方法通过对比图中的不同元素来学习表示,例如,节点图对比,节点子图对比。
混合自我监督学习
在混合学习中,可以使用不同类型的前置任务来组合以提高性能,而不是使用单一方法。
-
例如,GPT-GNN将MFR和C-SSC组合成一个图生成任务以预训练图神经网络
-
使用节点特征重构(MFR)和图结构恢复(C-SSC)来预训练图变换器模型的Graph-Bert
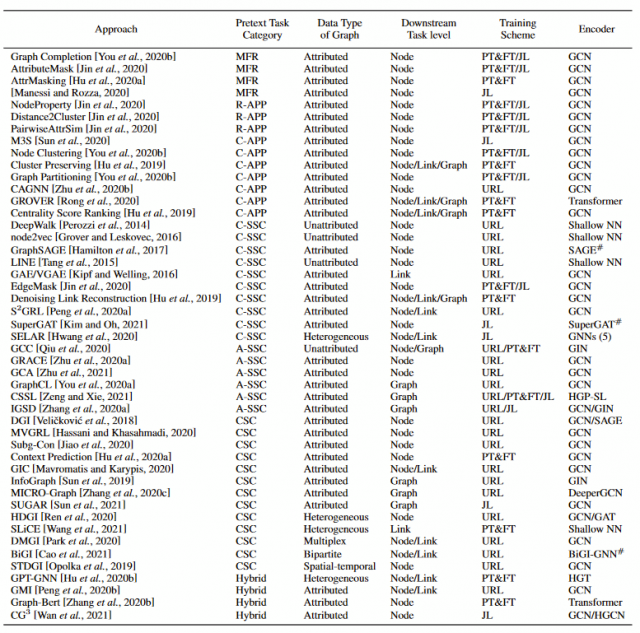
挑战
缺乏理论基础—现有的方法要么依赖直觉,要么依赖经验实验。一个强大的图SSL理论基础可以缩小经验SSL和图理论之间的差距
增强-由于图SSL有许多基于增强的方法,因此应进一步探索数据增强方案
复杂图的前置任务-现有方法主要用于属性图,只有少数几种方法着重于复杂图。 希望有更多的前置任务设计用于复杂图和更普遍的图
结论
图自我监督学习是一个有趣的话题,因为大多数数据都是图结构的,并且通常没有标签。 诸如此类的方法有助于提供更好的概括性和健壮的模型。 使用这些方法,我们可以了解图表中存在的结构和属性信息,而这些信息在使用标记数据时通常会被忽略。
论文地址:Graph Self-Supervised Learning: A Survey arxiv:2103.00111
作者:Gayathri Pulagam
本文链接:https://my.lmcjl.com/post/18395.html
4 评论