问题背景
搜索关键字智能提示是一个搜索应用的标配,主要作用是避免用户输入错误的搜索词,并将用户引导到相应的关键词上,以提升用户搜索体验。
美团CRM系统中存在数以百万计的商家,为了让用户快速查找到目标商家,我们基于solrcloud实现了商家搜索模块。用户在查找商家时主要输入商户名、商户地址进行搜索,为了提升用户的搜索体验和输入效率,本文实现了一种基于solr前缀匹配查询关键字智能提示(Suggestion)实现。
需求分析
1.支持前缀匹配原则
在搜索框中输入“海底”,搜索框下面会以海底为前缀,展示“海底捞”、“海底捞火锅”、“海底世界”等等搜索词;输入“万达”,会提示“万达影城”、“万达广场”、“万达百货”等搜索词。
2.同时支持汉字、拼音输入
由于中文的特点,如果搜索自动提示可以支持拼音的话会给用户带来更大的方便,免得切换输入法。比如,输入“haidi”提示的关键字和输入“海底”提示的一样,输入“wanda”与输入“万达”提示的关键字一样。
3.支持多音字输入提示
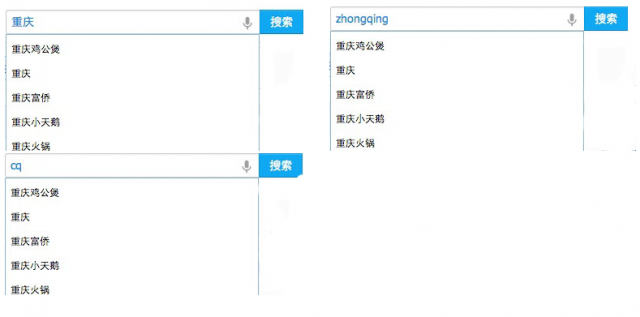
比如输入“chongqing”或者“zhongqing”都能提示出“重庆火锅”、“重庆烤鱼”、“重庆小天鹅”。
4.支持拼音缩写输入
对于较长关键字,为了提高输入效率,有必要提供拼音缩写输入。比如输入“hd”应该能提示出“haidi”相似的关键字,输入“wd”也一样能提示出“万达”关键字。
基于用户的历史搜索行为,按照关键字热度进行排序
为了提供suggest关键字的准确度,最终查询结果,根据用户查询关键字的频率进行排序,如输入[重庆,chongqing,cq,zhongqing,zq] —> [“重庆火锅”(f1),“重庆烤鱼”(f2),“重庆小天鹅”(f3),…],查询频率f1 > f2 > f3。
解决方案
1.关键字收集
当用户输入一个前缀时,碰到提示的候选词很多的时候,如何取舍,哪些展示在前面,哪些展示在后面?这就是一个搜索热度的问题。用户在使用搜索引擎查找商家时,会输入大量的关键字,每一次输入就是对关键字的一次投票,那么关键字被输入的次数越多,它对应的查询就比较热门,所以需要把查询的关键字记录下来,并且统计出每个关键字的频率,方便提示结果按照频率排序。搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。
2.汉字转拼音
用户输入的关键字可能是汉字、数字,英文,拼音,特殊字符等等,由于需要实现拼音提示,我们需要把汉字转换成拼音,java中考虑使用pinyin4j组件实现转换。
3.拼音缩写提取
考虑到需要支持拼音缩写,汉字转换拼音的过程中,顺便提取出拼音缩写,如“chongqing”,"zhongqing"--->"cq",”zq”。
4.多音字全排列
要支持多音字提示,对查询串转换成拼音后,需要实现一个全排列组合,字符串多音字全排列算法如下:
Java Code复制内容到剪贴板
-
public static List getPermutationSentence(List> termArrays,int start) {
-
-
if (CollectionUtils.isEmpty(termArrays))
-
return Collections.emptyList();
-
-
int size = termArrays.size();
-
if (start < 0 || start >= size) {
-
return Collections.emptyList();
-
}
-
-
if (start == size-1) {
-
return termArrays.get(start);
-
}
-
-
List<String> strings = termArrays.get(start);
-
-
List<String> permutationSentences = getPermutationSentence(termArrays, start + 1);
-
-
if (CollectionUtils.isEmpty(strings)) {
-
return permutationSentences;
-
}
-
-
if (CollectionUtils.isEmpty(permutationSentences)) {
-
return strings;
-
}
-
-
List<String> result = new ArrayList<String>();
-
for (String pre : strings) {
-
for (String suffix : permutationSentences) {
-
result.add(pre+suffix);
-
}
-
}
-
-
return result;
-
}
索引与前缀查询
方案一 Trie树 + TopK算法
Trie树即字典树,又称单词查找树或键树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。Trie是一颗存储多个字符串的树。相邻节点间的边代表一个字符,这样树的每条分支代表一则子串,而树的叶节点则代表完整的字符串。和普通树不同的地方是,相同的字符串前缀共享同一条分支。例如,给出一组单词inn, int, at, age, adv, ant, 我们可以得到下面的Trie:
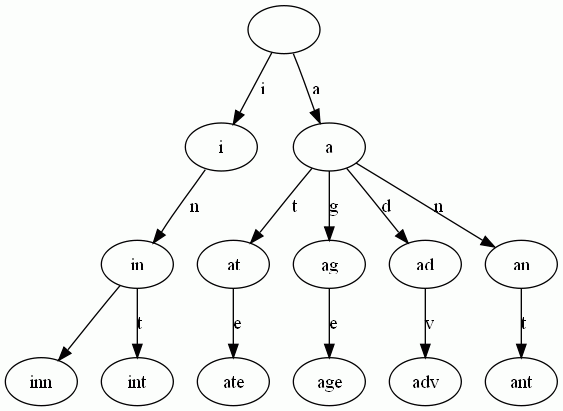
从上图可知,当用户输入前缀i的时候,搜索框可能会展示以i为前缀的“in”,“inn”,”int"等关键词,再当用户输入前缀a的时候,搜索框里面可能会提示以a为前缀的“ate”等关键词。如此,实现搜索引擎智能提示suggestion的第一个步骤便清晰了,即用trie树存储大量字符串,当前缀固定时,存储相对来说比较热的后缀。
TopK算法用于解决统计热词的问题。解决TopK问题主要有两种策略:hashMap统计+排序、堆排序
hashmap统计: 先对这批海量数据预处理。具体方法是:维护一个Key为Query字串,Value为该Query出现次数的HashTable,即hash_map(Query,Value),每次读取一个Query,如果该字串不在Table中,那么加入该字串,并且将Value值设为1;如果该字串在Table中,那么将该字串的计数加一即可,最终在O(N)的时间复杂度内用Hash表完成了统计。
堆排序:借助堆这个数据结构,找出Top K,时间复杂度为N‘logK。即借助堆结构,我们可以在log量级的时间内查找和调整/移动。因此,维护一个K(该题目中是10)大小的小根堆,然后遍历300万的Query,分别和根元素进行对比。所以,我们最终的时间复杂度是:O(N) + N' * O(logK),(N为1000万,N’为300万)。
该方案存在的问题是:
建索引和查询的时候都要把汉字转换成拼音,查询完成后还得把拼音转换成汉字显示,且需要考虑数字和特殊字符。
需要维护拼音、缩写两棵Trie树。
方案二 Solr自带Suggest智能提示
Solr作为一个应用广泛的搜索引擎系统,它内置了智能提示功能,叫做Suggest模块。该模块可选择基于提示词文本做智能提示,还支持通过针对索引的某个字段建立索引词库做智能提示。 (详见solr的wiki页面http://wiki.apache.org/solr/Suggester)
该方案存在的问题是:
返回的结果是基于索引中字段的词频进行排序,不是用户搜索关键字的频率,因此不能将一些热门关键字排在前面。
拼音提示,多音字,缩写还是要另外加索引字段。
方案三 Solrcloud建立单独的collection,利用solr前缀查询实现
如前所述,以上两个方案在实施起来都存在一些问题,Trie树+TopK算法,在处理汉字suggest时不是很优雅,且需要维护两棵Trie树,实施起来比较复杂;Solr自带的suggest智能提示组件存在问题是使用freq排序算法,返回的结果完全基于索引中字符的出现次数,没有兼顾用户搜索词语的频率,因此无法将一些热门词排在更靠前的位置。于是,我们继续寻找一种解决这个问题更加优雅的方案。
至此,我们考虑专门为关键字建立一个索引collection,利用solr前缀查询实现。solr中的copyField能很好解决我们同时索引多个字段(汉字、pinyin, abbre)的需求,且field的multiValued属性设置为true时能解决同一个关键字的多音字组合问题。配置如下:
schema.xml:
XML/HTML Code复制内容到剪贴板
-
<field name="kw" type="string" indexed="true" stored="true" />
-
<field name="pinyin" type="string" indexed="true" stored="false" multiValued="true"/>
-
<field name="abbre" type="string" indexed="true" stored="false" multiValued="true"/>
-
<field name="kwfreq" type="int" indexed="true" stored="true" />
-
<field name="_version_" type="long" indexed="true" stored="true"/>
-
<field name="suggest" type="suggest_text" indexed="true" stored="false" multiValued="true" />
------------------multiValued表示字段是多值的-------------------------------------
XML/HTML Code复制内容到剪贴板
-
<uniqueKey>kw</uniqueKey>
-
<defaultSearchField>suggest</defaultSearchField>
说明:
kw为原始关键字
pinyin和abbre的multiValued=true,在使用solrj建此索引时,定义成集合类型即可:如关键字“重庆”的pinyin字段为{chongqing,zhongqing}, abbre字段为{cq, zq}
kwfreq为用户搜索关键的频率,用于查询的时候排序
-------------------------------------------------------
XML/HTML Code复制内容到剪贴板
-
<copyField source="kw" dest="suggest" />
-
<copyField source="pinyin" dest="suggest" />
-
<copyField source="abbre" dest="suggest" />
------------------suggest_text----------------------------------
XML/HTML Code复制内容到剪贴板
-
<fieldType name="suggest_text" class="solr.TextField" positionIncrementGap="100" autoGeneratePhraseQueries="true">
-
<analyzer type="index">
-
<tokenizer class="solr.KeywordTokenizerFactory" />
-
<filter class="solr.SynonymFilterFactory"
-
synonyms="synonyms.txt"
-
ignoreCase="true"
-
expand="true" />
-
<filter class="solr.StopFilterFactory"
-
ignoreCase="true"
-
words="stopwords.txt"
-
enablePositionIncrements="true" />
-
<filter class="solr.LowerCaseFilterFactory" />
-
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt" />
-
</analyzer>
-
<analyzer type="query">
-
<tokenizer class="solr.KeywordTokenizerFactory" />
-
<filter class="solr.StopFilterFactory"
-
ignoreCase="true"
-
words="stopwords.txt"
-
enablePositionIncrements="true" />
-
<filter class="solr.LowerCaseFilterFactory" />
-
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt" />
-
</analyzer>
-
</fieldType>
KeywordTokenizerFactory:这个分词器不进行任何分词!整个字符流变为单个词元。String域类型也有类似的效果,但是它不能配置文本分析的其它处理组件,比如大小写转换。任何用于排序和大部分Faceting功能的索引域,这个索引域只有能一个原始域值中的一个词元。
前缀查询构造:
Java Code复制内容到剪贴板
-
private SolrQuery getSuggestQuery(String prefix, Integer limit) {
-
SolrQuery solrQuery = new SolrQuery();
-
StringBuilder sb = new StringBuilder();
-
sb.append(“suggest:").append(prefix).append("*");
-
solrQuery.setQuery(sb.toString());
-
solrQuery.addField("kw");
-
solrQuery.addField("kwfreq");
-
solrQuery.addSort("kwfreq", SolrQuery.ORDER.desc);
-
solrQuery.setStart(0);
-
solrQuery.setRows(limit);
-
return solrQuery;
-
}
效果如下图所示:
本文链接:https://my.lmcjl.com/post/20711.html
4 评论