目录
- 引言
- 1、面试官:我看你提到,项目中使用了Reids作为缓存,为什么是Reids而不是其他,Redis有什么优势吗?
- 2、面试官:刚刚你提到Redis是单线程,为什么单线程模型的Redis性能不减。
- 3、面试官:那你刚刚说的Redis数据结构都有哪几种,如何选择使用哪种?
- 深入分析
- 1、简单动态字符串结构,Redis字符串的实现方式
- 2、链表数据结构,List底层结构
- 3、跳跃表,sortedset底层结构
-
关于缓存的一些算法
- 常用缓存数据淘汰策略
- 缓存数据更新策略
-
总结
引言
面完了负载均衡,正向代理,反向代理,终于松了一口气,然后话题转向了缓存Redis,为什么是这个顺序呢?
回想了一下系统架构,我大概知道原因了。

Redis 处于服务最上层。面试官是按照这个顺序从上到下考察我对整个系统设计能力,围着整个系统自顶向下的结构考察基础。不纠结这么多,反正先问后问,Redis一定是你必须掌握的。
1、面试官:我看你提到,项目中使用了Reids作为缓存,为什么是Reids而不是其他,Redis有什么优势吗?
问题分析: Redis的设计理念已经成了很多一线互联网公司自主研发分布式缓存框架的标杆,因为相比传统的 Memcache ,Redis 丰富的数据结构实在太香。
答:
- 首先 Redis 支持丰富的数据结构,新版本数据结构从最初的5种变成9种。
- 其次 Redis 是读写单进程单线程,不用考虑并发读写的复杂场景,速度也快。
- Reids 功能完备,支持数据持久化,支持主从复制和集群。
- 还有Lua脚本,事务,发布订阅模型,Reids 都支持。
在高并发请求时,为何我们频繁提到缓存技术?最直接的原因是,磁盘IO及网络开销是直接请求内存IO千百上千倍,做个简单计算,如果我们需要某个数据,该数据从数据库磁盘读出来需要0.0045S,经过网络请求传输需要0.0005S,那么每个请求完成最少需要0.005S,该数据服务器每秒最多只能响应200个请求,而如果该数据存于本机内存里,读出来只需要100us,那么每秒能够响应10000个请求。通过将数据存储到离CPU更近的未位置,减少数据传输时间,提高处理效率,这就是缓存的意义。
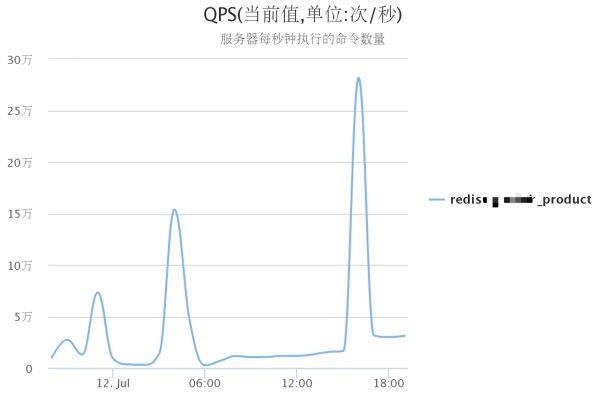
给您列举一个我利用Reids把项目QPS提到几十万级别的案例:
一个风控系统在日常24H中 Redis集群 QPS 曲线图,从业务低峰期几千或晚高峰最高30W,一个 Redis 集群都可轻松应对,30WQPS 在大型系统中流量并不算高,且不是核心系统,如果在多几倍几十倍多流量,一个结构优良的Redis 集群都可轻松应对,这充分说明了我们为什么要使用缓存,缓存可以把系统响应能力提高N个数量级,远高于传统基于硬盘的关系型数据库
面试官心想:看来是做足了功课。
2、面试官:刚刚你提到Redis是单线程,为什么单线程模型的 Redis 性能不减。
问题分析:成功挖坑,提到单线程肯定会问我为什么要这样设计。
答:
单线程不代表一定就慢,单线程有一个最大好处就是节省线程切换的开销,更不用考虑并发读写带来的复杂操作场景,这就大大节省了线程间切换的时间了。
单线程模型避免了多线程的频繁上下文切换,这也避免了多线程可能产生的竞争问题。
Reids 是基于内存的读写操作,内存肯定比传统磁盘IO数据库快。
Reids 核心是基于非阻塞的IO多路复用机制。
3、面试官:那你刚刚说的Redis数据结构都有哪几种,如何选择使用哪种?
问题分析: 常用的5种,重点学会这5种数据结构的使用足够了。
答:比较常用的有5种
字符串 String: 字符串是 Redis 中最为基础的数据存储类型,数据结构简单,可存储文本,Json,图片数据等任何二进制文件。如姓名,订单号等,对于一些特殊的数据结构,比如List、Set等,建议采用相应的下面介绍的List和Set数据结构进行存储,这样不仅可以节省存储空间还可以提高操作效率。
列表 List: 类似 Java 中的 List ,按照插入顺序排序的字符串链表,在插入时,如果该键并不存在,Redis将为该键创建一个新的链表。与此相反,如果链表中所有的元素均被移除,那么该键也将会被从数据库中删除。
集合 Set: 类似 Java 中的set,但它是一个无序集合,用于存储无序(存入和取出的顺序不一定相同)元素,值不能重复。可以使用Redis的Set数据类型跟踪一些唯一性数据,比如访问系统的唯一IP地址,唯一用户ID等信息,再比如在微博应用中,每个人的好友存在一个集合(set)中,这样求两个人的共同好友的操作,可能就只需要用求交集命令即可。
有序集合 Sorted Set: 类似 Java 中的 TreeSet,支持从小到大排序的 set,适用于排行榜结构的数据存储。
Hash: 类型相当于Java中的HashMap,所以该类型非常适合于存储值对象的信息,比如用户基本信息对象含有昵称、性别和Age等属性,可以使用Hash来存储User对象,Key可以为用户的唯一ID属性。
除此之外,新版本的Redis还提供了位图,地理坐标,流几种结构。
深入分析
曾经有面试官问我,你看过Reids源码吗,我说没有看过,他说有精力可以研究一下,Redis那几种常用的数据结构底层实现原理还是值得学习的。
1、简单动态字符串结构,Redis字符串的实现方式
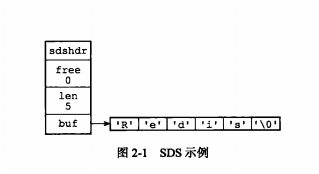
简单动态字符串(simple dynamic string)简称SDS。Redis使用C语言编写,但是传统的C字符串使用长度为 N+1 的字符串数组来表示长度为N的字符串,所以为了获取一个长度为C字符串的长度,必须遍历整个字符串。和C字符串不同,动态字符串的数据结构中,有专门用于保存字符串长度的变量,我们可以通过获取len属性的值,直接知道字符串长度,从一定程度上提高了读取效率。
Redis源码中,动态字符串的定义:
?
|
1 2 3 4 5 6 7 8 9 10 11 |
|
len 变量,用于记录buf 中已经使用的空间长度。
free 变量,用于记录buf 中还空余的空间,初次分配空间,一般没有空余,在对字符串修改的时候,会有剩余空间出现,这样做是为了杜绝C语言中缓冲区溢出的可能性,当我们需要对一个SDS进行修改的时候,Redis 会在执行拼接操作之前,预先检查给定SDS空间是否足够,如果不够,会先拓展SDS的空间,然后再执行拼接操作。
buf 字符数组,用于记录我们的字符串(记录Redis)。
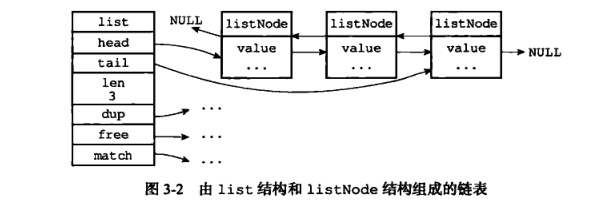
2、链表数据结构,List 底层结构
链表还是常规的普通双端链表,可以支持反向查找和遍历,更方便操作,通过增删节点来灵活地调整链表的长度,双端链表在Redis内部也是被多次使用:
- 事务模块使用双端链表依序保存输入的命令。
- 服务器模块使用双端链表来保存多个客户端。
- 订阅/发送模块使用双端链表来保存订阅模式的多个客户端。
- 事件模块使用双端链表来保存时间事件(time event)。
3、跳跃表,sorted set底层结构
Redis sorted set的内部使用HashMap和跳跃表(SkipList)来保证数据的存储和有序,(如果你还不了解红黑树,需要先额外补补功课),HashMap里放的是成员到score的映射,而跳跃表里存放的是所有的成员,排序依据是HashMap里存的score,使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。
那为什么Redis的作者使用 SkipList 结构而不是红黑树?
红黑树:红黑树的查找效率很高,但是在进行重新平衡时,会涉及到大量节点的变化,因此实现和操作起来都比较复杂。
跳跃表:通过简单的多层索引结构,实现简单,且能达到近似于红黑树的查找效率,插入节点(多层插入)不需要像红黑树那样有额外操作。而且跳跃表还能实现范围查找及输出,而红黑树只支持单个元素查找,对于范围查找效率低。
关于缓存的一些算法
(偷偷告诉你,这几个关于Reids的算法很大概率也会被问到,需要多少知道几种)
常用缓存数据淘汰策略
缓存是非常宝贵的资源,不能把所有数据都放入缓存,只能把最重要的或者要求查询速度最快的数据缓存起来,比如微博热门话题排行榜功能,通常使用缓存查询,而不是数据库。
FIFO(First In First Out): 先进先出算法,即先放入缓存的先被移除。
LRU(Least Recently Used): 最近最少使用算法,使用时间距离现在最久的那个被移除。
LFU(Least Frequently Used): 最不常用算法,一定时间段内使用次数(频率)最少的那个被移除。
缓存数据更新策略
- 定时任务从数据库直接更新缓存:适用于对时间不敏感的数据。
- 查询时写缓存,即查询优先查询缓存,若缓存未命中,查询数据库,将返回结果写入缓存,数据更新时先 delete缓存,再更新缓存。
- MQ 消息异步更新缓存,后文中会针对MQ的应用做单独讲解。
总结
这一节重点讲解分布式缓存 Redis ,本地缓存不一定每个项目都会使用,但是 Redis 数据设计合理,保证超高命中率,集群足够稳定,那完全可以替代一级本地缓存。所以 Redis 非常值得你花更多时间学习。分布式缓存是面试必问。
Redis 是建设高性能网站后台不可缺少的工具,无论你是面试业务开发工程师还是架构师,都需要熟练掌握。
关于Redis,推荐阅读黄建宏的《Redis 设计与实现》,能够掌握Redis的5种数据结构,Redis 的持久化方式 RDB 和 AOF,两者有什么优点和缺点,如何选型,以及了解高可用 Redis 集群的建设方案。
以上就是分布式架构Redis中有哪些数据结构及底层实现原理的详细内容,更多关于分布式架构Redis底层数据结构及原理的资料请关注服务器之家其它相关文章!
原文链接:https://blog.csdn.net/qq_34272760/article/details/120734895
本文链接:https://my.lmcjl.com/post/3301.html
4 评论