Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
摘要
- 不仅发送和接收语言,还发送和接收图像
- 提供复杂的视觉问题或视觉编辑指令,这些问题需要多个AI模型以多步骤协作
- 提供反馈并要求纠正结果
- 考虑到多输入/输出模型和需要视觉反馈的模型,设计了一系列提示符将可视化模型信息注入到ChatGPT中
- 代码地址
引言
- ChatGPT建立在InstructGPT的基础上,专门训练以真正的对话方式与用户交互,从而允许它保持当前对话的上下文,处理后续问题,并自行生成正确答案
- 视觉基础模型(VFMs)在计算机视觉中显示出巨大的潜力
- BLIP模型是理解和提供图像描述的专家
- Stable Diffusion是一个基于文本提示合成图像的专家
- 不是从头开始训练一个新的多模态ChatGPT
- 直接基于ChatGPT构建可视化ChatGPT,并结合各种VFM
- 显式地告诉ChatGPT每个VFM的可靠性,并指定输入输出格式
- 将不同的视觉信息,例如png图像、深度图像和掩码矩阵,转换为语言格式,以帮助ChatGPT理解
- 处理不同的可视化基础模型的历史、优先级和冲突
方法
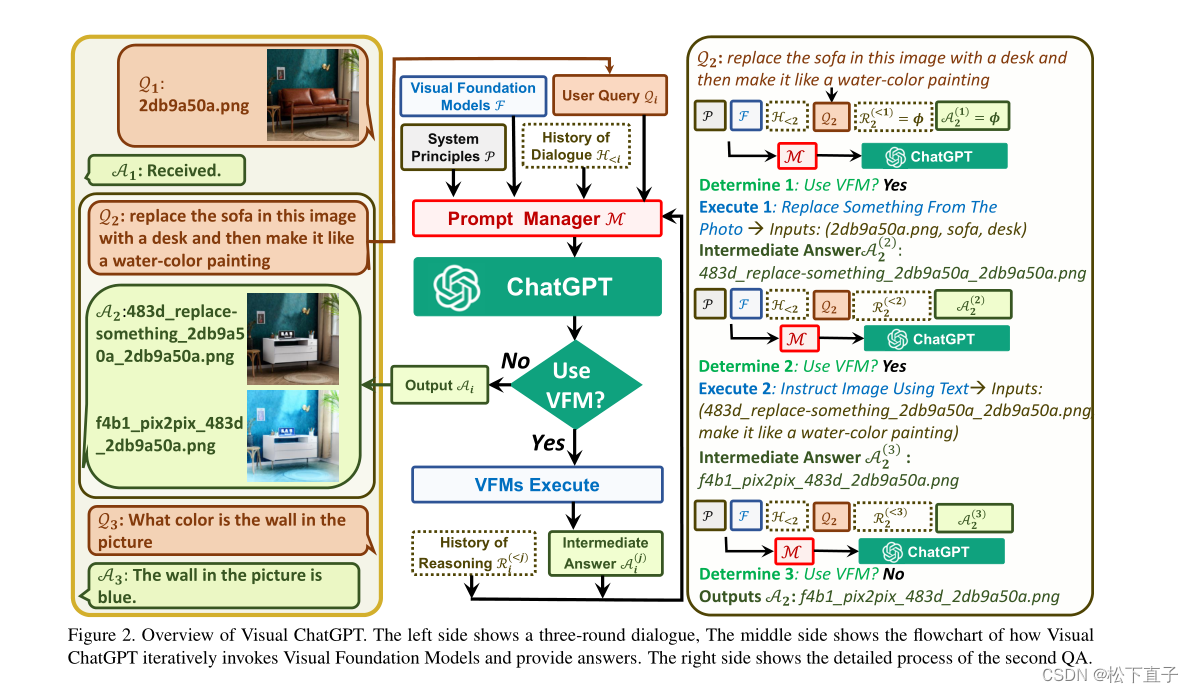
通过上图可以看出:
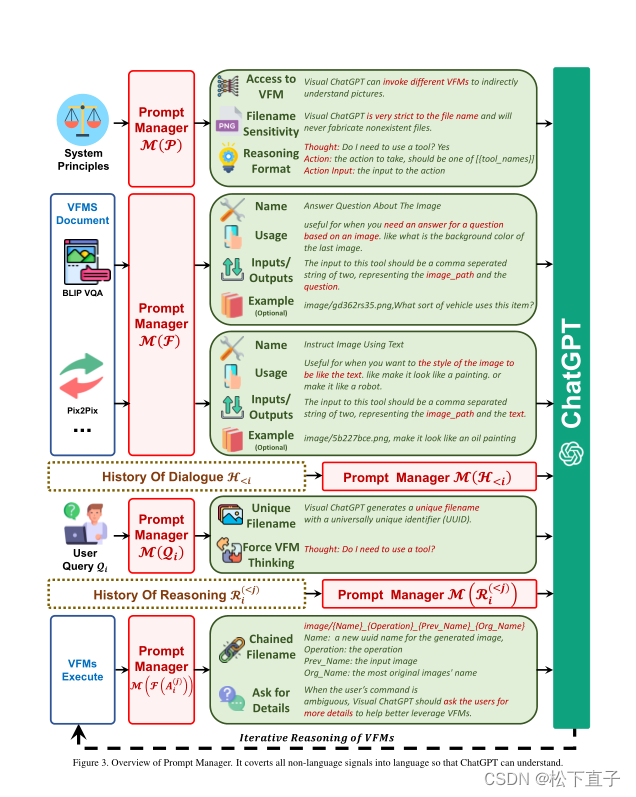
根据图片慢慢体会,他的方法
局限性
- 依赖chatgpt和VFM
- 需要大量的prompt工程
- 实时能力不好
- token长度的限制
- 安全和隐私
本文链接:https://my.lmcjl.com/post/3406.html
展开阅读全文
4 评论