声明
本篇文章的相关图片来源于论文:Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
论文链接如下:https://arxiv.org/pdf/2303.04671.pdf
碍于本人的知识水平所限,本篇文章的总结可能存在不妥之处,如:
作为参考,请谨慎推理内容的真实性(人某种意义上与chatgpt也没差)
欢迎各路大佬指出问题!
文章分类
-
领域定位:自然语言处理,计算机视觉
-
领域细分
-
大语言模型的多模态
-
ChatGPT衍生产品
-
这篇文章的创新点在哪里?
-
整了一个prompt manager,让视觉模型能通过prompt manager与ChatGPT打配合,使得ChatGPT可以”生图“与”看图“
-
执行了大量的零样本实验(感觉这个说法是基于把ChatGPT当成黑箱模型来得到的,本篇文章的许多结论建立在这个假设上)
这篇文章的技术点在哪里?
顾名思义,技术点,即可以运用在工程项目上面的point,如下:
提示工程方法:基于chatgpt的提示工程方法。提示工程是一种基于”大大语言模型是个黑盒模型“得到的实验性理论,通过提示工程可以加强诸如chatgpt等大语言模型某些方面的表示能力。
-
基于提示工程实现的tricks
-
自我询问方法:让chatgpt自我对问题进行询问,从而提高chatgpt使用prompt manager的概率
-
主动问讯:主动向用户询问更多细节,减少GPT的主观臆断
-
规则限制:强制使用某些命名规则
-
定义了visual ChatGPT的作用:基于思维链路暗示CHatgpt的任务
-
可靠性:基于提示使chatgpt忠于视觉基础模型的输出
-
视觉模型列表可访问性支持:ChatGPT可以访问VFMs列表,以解决各种VL任务。
-
-
提示学习
-
思维链模型引导:通过思维链(CoT)方法引导ChatGPT
-
这篇论文的相关工作及其主线为?
涉及到的主线有3条:
-
大语言模型的发展
-
NLP与CV
-
视觉语言(VL)任务
这篇文章主要的设计是?
-
设计思路:
-
用户提出一个query(可能带图)
-
query经过prompt manager,追加了一系列系统原则与提示交给chatgpt
-
chatgpt返回一系列表述给prompt manager
-
(判断若需要生图工作)prompt manager将部分表述交给VFMs(视觉模型们)进行生图操作
-
VFMs将图像数据返回给prompt manager
-
prompt manager基于图像数据生成图像语言
-
图像语言交给ChatGPT判断正确性,该过程不断迭代直到满足一定条件
-
输出处理后的语言与图像结果
-

-
整体架构设计:
-
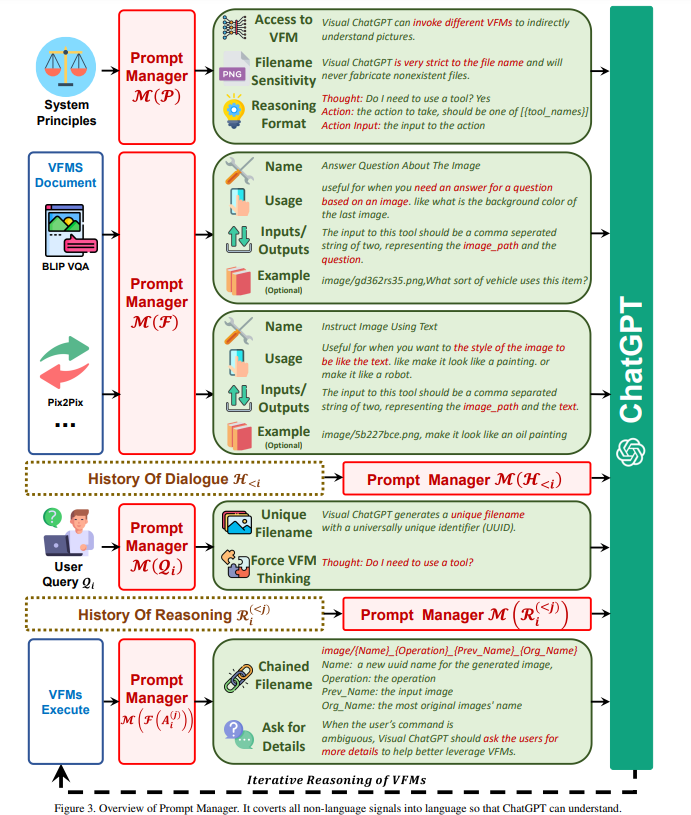
Prompt manager的基本设计
-
系统原则
-
定义了visual ChatGPT的作用:基于思维链路暗示CHatgpt的任务
-
VFMs可访问性:ChatGPT可以访问VFMs列表,以解决各种VL任务。使用哪个基础模型完全由ChatGPT模型本身决定,因此很容易支持新的vfm和VL任务。
-
文件名敏感性:暗示其严格使用文件名以避免其混淆不同的图像文件
-
思维链模型建模:引入了CoT辅助建模
-
可靠性:基于提示使chatgpt忠于视觉基础模型的输出
-
优先使用VFMs:构建的提示将引导ChatGPT优先利用vfm,而不是根据会话历史生成结果
-
-
历史对话的处理
-
多轮问题的字符串串接
-
基于最大长度阈截断对话历史
-
-
用户询问的处理
-
一个用于提醒gpt使用vfm的提示
-
它提示Visual ChatGPT使用基础模型,而不是仅仅依靠它的想象力
-
它鼓励Visual ChatGPT提供由基础模型生成的特定输出,而不是像“您在这里”这样的通用响应。
-
-
一个具有通用唯一标识符(UUID)的唯一文件名,并添加一个前缀字符串“image”表示相对目录
-
新上传的图像不会被输入到ChatGPT,但会生成一个假的对话历史记录,其中一个问题说明了图像的文件名,而一个答案表明图像已被接收。
-
-
-
模型输入输出步骤
-
图像保存至image文件夹下,图像命名——名称+操作+预览名+组织名称
-
使用这样的命名规则,它可以提示ChatGPT中间结果属性,即。图像,以及它是如何从一系列操作中生成的。
-
自我问询方法:让ChatGPT通过在每一代结束时扩展一个后缀“Thought:”来不断地询问自己是否需要vfm来解决当前的问题
-
主动向用户询问更多细节,减少GPT的主观臆断
-
-
-
VFMs:基于视觉任务的模型
-
支持22中不同任务的视觉模型,具备视觉任务上很好的扩展性
-
-
部分实验过程摘录

论文的详细内容详见https://arxiv.org/pdf/2303.04671.pdf欧~
本文链接:https://my.lmcjl.com/post/6247.html
4 评论