AWS S3云存储服务
- 1 S3概念及基础知识
- 2 S3的基本操作
- 3 S3数据安全
- 4 S3数据加密以及命令行CLI
- 4.1 S3加密工作原理
- 4.1.1 server端的加密
- 4.1.2 client 端的加密
- 4.2 图形化方式——使用aws内置功能加密
- 4.3 命令行方式加密
- 4.3.1 SSE-S3
- 4.3.2 SSE-KMS
- 4.3.3 SSE-C
- 5 S3对象锁
- 6 s3版本控制及生命周期管理
- 7 s3网站托管
- 8 s3跨域资源共享(CORS)
- 9 CloudFront内容分发网络(CDN)
- 10 CloudFront发布私有内容
- 11 S3传输加速,跨区域复制以归档数据还原
- 11.1 传输加速
- 11.2 跨区域复制
- 11.3 归档数据的还原
- 12 Snow Family数据导入导出服务
- 13 存储网关
- 14 S3数据查询Athena服务
1 S3概念及基础知识
- S3(Simple Storage Service):简便的存储服务,它可以实现通过Key Value的方式,把一个对象存储在网络空间,常用于互联网多媒体对象比如视频,图像等的存储
- 特征:
- 高度可扩展(可看做是无限的存储空间)、稳定的、基于对象的存储(也就是说把数据当做对象进行存储)
- 单个文件的存储最大可以达到5T;单次上传的数据量是5G(如果大于5G,会分批上传)
- 提供不同的存储类型
- 支持Server-Side Encryption (SSE)数据加密,SSE-S3(使用具有Amazon S3 托管加密密钥的服务器端加密)、SSE-C(通过使用客户提供的加密密钥的服务器端加密)、SSE-KMS(使用具有AWS KMS 托管密钥的服务器端加密)
- S3的存储类型及特点:【根据情景选择合适的存储类型】
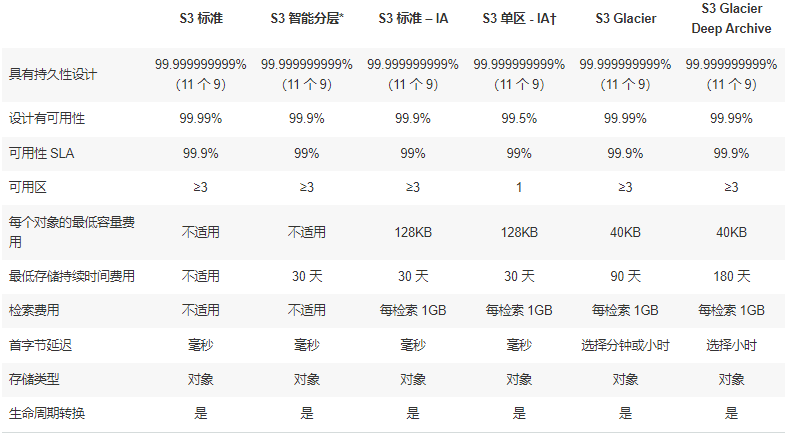
注意:† 由于 S3 单区 – IA 将数据存储在单个 AWS 可用区中,存储在这个存储类中的数据将在可用区销毁时丢失。
*S3 智能分层收取小额分层费用,对自动分层有 128KB 的最小合格对象大小限制。
2 S3的基本操作
-
登录IAM用户后,进入servies,在左边的storage处有S3,点击进入S3的管理界面;点击create bucket,输入名称(自定义,要唯一),根据所处区域选择


-
第二步主要是设置相关功能,在Tags处输入 Name、自定义名,其他目前全部默认方式即可
-
设置访问权限,默认是阻止所有公共的访问,直接默认即可
-
点击create bucket,如此便成功创建了bucket,点击进入就会看到有关bucket的属性、权限等信息(一个bucket就相当于一个容器)



-
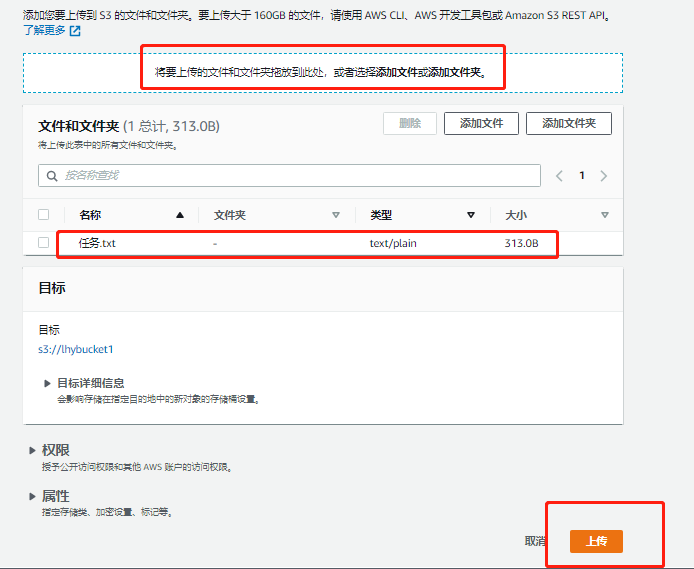
点击该bucket进入后在对象页面中可以看到upload,可以进行文件的上传,可以选择本地文件上传同时设置文件的权限(可以默认),恶可以选择存储的类别以及加密(默认即可)。

-
选择upload,可以看到该文件已经上传成功,进入该文件,可以看到文件相关属性
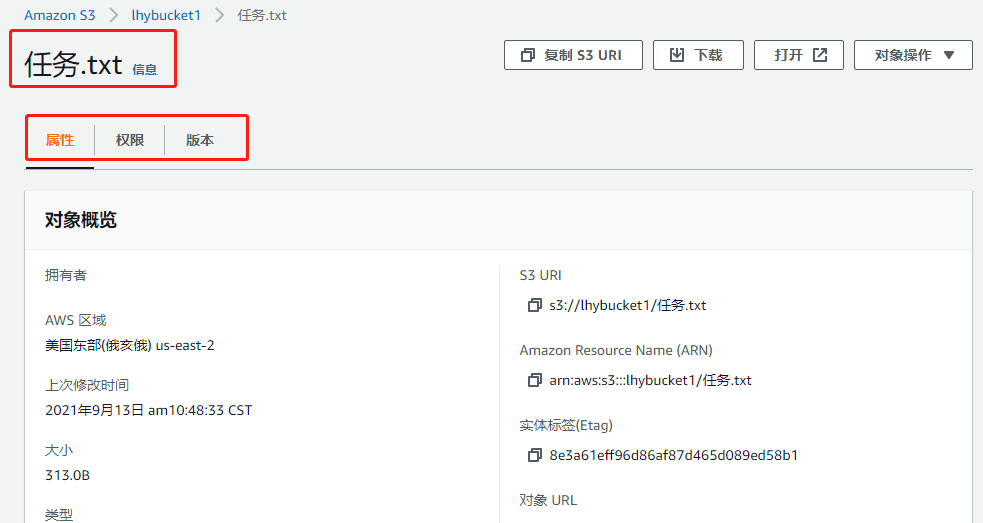
-
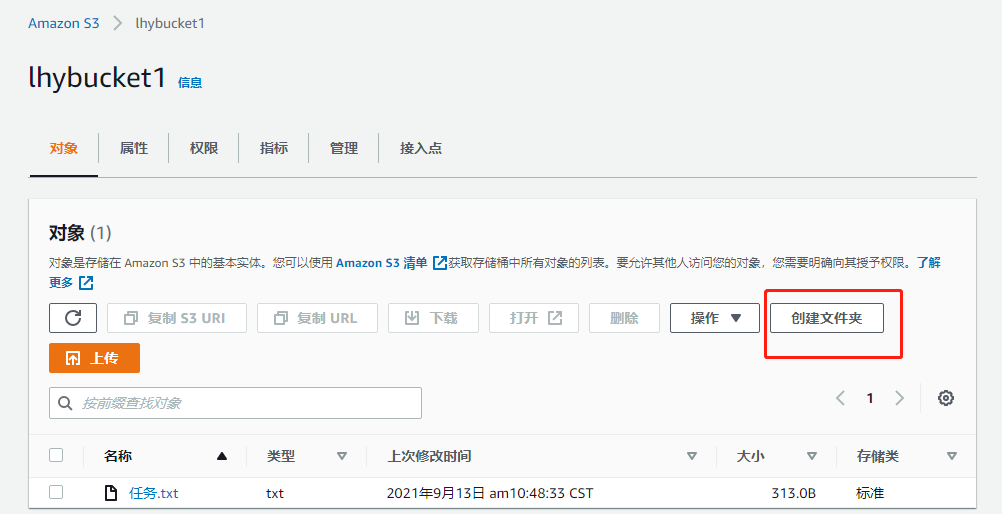
在该bucket中还可以点击create folder,也就是在bucket中创建一个虚拟的文件,该虚拟的文件中依旧可以上传图片等文件(注意对比两种方式上传的文件属性、url的不同等)
3 S3数据安全
- S3控制访问
- 基于资源:bucket和ACL(Access Control Lists,访问控制列表,是应用在路由器接口的指令列表。这些指令列表用来告诉路由器哪些数据包可以收、哪些数据包需要拒绝。至于数据包是被接收还是拒绝,可以由类似于源地址、目的地址、端口号等的特定指示条件来决定。)
- 基于用户:通过IAM用户的权限去控制访问
- 存储数据加密:包括server-Side和client-Side
- 传输数据加密:SSL/TLS
- 预签名URL:主要提供对S3的临时访问,尤其是对于某些非IAM得用户设定的临时访问(例如,生成一个临时的URL给非IAM用户,那么该用户就可以临时对S3的内容进行查看等其他操作)
- 多重验证删除:通过多重验证的方法防止人为的错误删除或者覆盖,这种方式只能通过命令行的方式启动
- 对象锁:相当于对s3里面的内容加锁,在该锁有效的时间内,不能将对象删除,以达到保护的目的
- 跨区域复制(CRR):s3的大部分存储类型会将数据复制三份及以上,存放在一个区域的不同数据中心。当开启CRR功能后,在前面的基础上还会把数据复制到别的区域,进一步保证数据冗余以及安全
- vpc终端节点:可以实现使用aws内部的骨干网络直接读取s3上的数据,而不是通过互联网传输,以此来进一步保证数据的安全
4 S3数据加密以及命令行CLI
4.1 S3加密工作原理
4.1.1 server端的加密
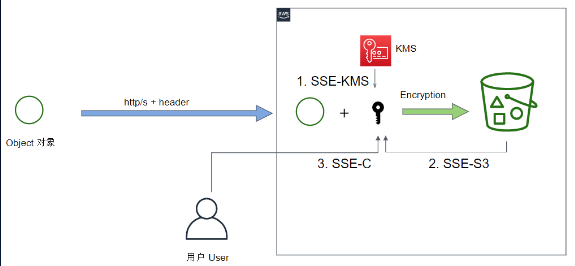
- server端的加密实际上是将数据传输到aws,由aws进行加密,知道用户请求读取数据时,再进行解密。根据加密秘钥存放位置的不同,有三种不同的加密方式,每次加密只能使用其中一种加密方法。
- 如下图所示,在对象传输到S3之前,用户必须在header处指明加密的方式,当数据进入到aws,可以使用KMS(秘钥管理工具)里面的key进行加密或者选择使用S3来管理key进行加密。当对安全性要求比较高时,比如用户希望由自己管理秘钥,那么用户就可以提供自己的秘钥再对数据进行加密,这种加密方法必须通过命令行的方式实现,而且通过这种方法加密,aws并不会记录秘钥以保证数据的安全性,秘钥需要用户自己进行管理。
4.1.2 client 端的加密
- 如下图所示,client端加密和解密都是在客户端完成的,S3收到的数据是已经加密过的。客户端的加密主要有两种方式,第一种是由KMS(秘钥管理工具)管理key;第二种方式是客户管理key,同样这个key是不会发送到aws上的,由客户自行保障。

4.2 图形化方式——使用aws内置功能加密
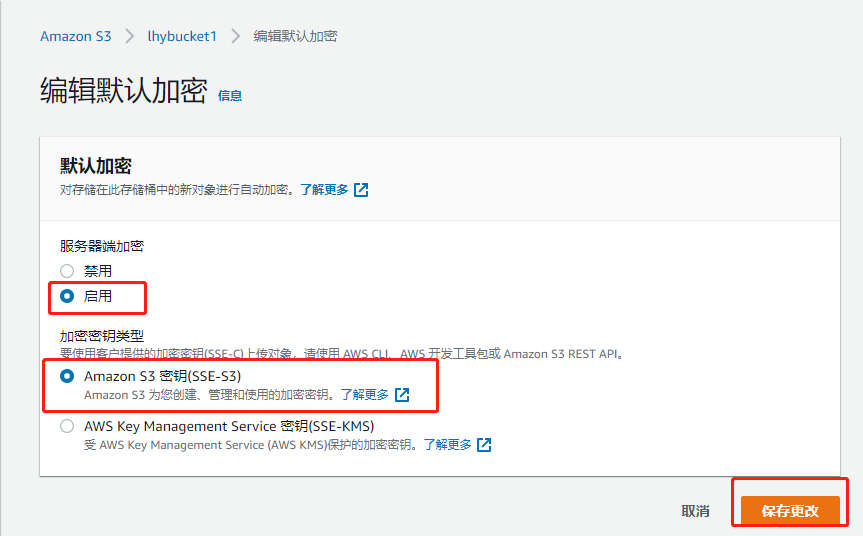
-
进入S3,开启默认加密选项,在Default encryption处勾选,随后选择下面的S3管理秘钥的方法。
-
进入该bucket上传文件,查看文件的属性,可以看到其加密方法(注意之前上传过的文件,其加密方式仍为修改前的)。如果需要修改桶的加密方式,使用上面的方法即可。注意第一个文件的加密方法即时在修改加密方式后也不会改变,依旧是首次加密时使用的方法。

4.3 命令行方式加密
4.3.1 SSE-S3
-
安装aws命令行的工具包(有一台虚拟机的前提下)
-
awxcli --version##检测安装情况 -
配置
awscli configure回车- 此时需要之前保存下来文件的ID和key、
- 当前文件的所在区,可以在其属性处的URL处查看,位于s3-后面
- 最后一行默认输出形式处直接回车即默认。
注意:这种方式实际上并不安全,输入ls -al可以查看到到隐藏文件 。cd .aws,ls可以看到credentials是存放在本地的,ls -al,cat config,cat credentials,就可以查看到密码。
-
配置完后生成几个文件进行加密
vi sse-s3.txt,在文件中任意写入内容即可,cp sse-s3.txt sse-kms.txt,cp sse-s3.txt sse-c.txt(在家目录生成即可) -
aws s3 cp sse-s3.txt s3://cloudlab-s3-encryption --sse,##表示 将sse-s3.txt文件上传到s3://cloudlab-s3-encryption位置,–sse表示默认就是使用s3管理秘钥。 -
回到web界面的bucket处刷新,发现文件上传成功,查看其属性,可以看到是由s3管理秘钥进行加密的
4.3.2 SSE-KMS
aws kms list-keys,查看当前kms中包含的key,虽然可以查看到,但是并不清楚这些key具体是用于做什么的;输入aws kms list-aliases,使用别名这种方式就可以看到每个key的使用方法。aws s3 cp sse-kms.txt s3://cloudlab-s3-encryption --sse aws:kms --sse-kms-key-id "查看的key的id",回车后可以看到文件上传成功- 回到界面刷新,可以看到sse-kms.txt文件上传成功,此时查看文件属性,可以看到其加密方式是AWS-KMS,并且其秘钥是存放在kms里面的
4.3.3 SSE-C
- 首先使用OpenSSL生成新的秘钥
openssl enc -aes-128-cbc -k secret -P aws s3 cp sse-c.txt s3://cloudlab-s3-encryption --sse-c --sse-c-key"上面生成的key的id",回车即可- 刷新界面可以看到sse-c.txt文件已经上传成功,查看其属性,可以看到其加密方式是SSE-C,当尝试打开该文件是,由于秘钥由用户自行保存,所以无法查看内容
- 此时其他方式加密的文件是可以打开查看的
5 S3对象锁
-
进入s3的管理界面,创建一个新bucket,创建时勾选Advanced setting处的permanently alow objects in this bucket to be locked即可。

-
上传一个文本文件,点击该上传好的文本文件,点击上面的属性,进入后找到 object lock,点击进入,enable governance mode (表示当操作的用户由权限时,那么这个锁的功能时不起作用的),enable compliance mode (表示任何用户都不可以再操作 )选择这一项即可。


-
在下面弹出的 confirm compliance mode出输入confirm,确定一下
-
查看刚才上传文件的属性,可以看到其当前的object lock变为了enabled的状态,此时删除该文件,可以看到改文件后面多了一个delete marker。如果再选中原文件进行删除,会有错误提示,警告删除的操作被拒绝。但是如果对标有delete marker的文件进行删除操作是可以成功的。也就是起到了文件的保护作用,只有到文件的期限到期后,才能进行删除的操作
6 s3版本控制及生命周期管理
-
概念:版本控制就是指当一个对象有多个版本时,可以将其产生的所有版本保存到一个bucket里。
-
如果将版本控制功能和Object Lifecycle Management结合使用,可以达到将老旧的版本转移到费用较低的存储上面达到节省费用以及数据归档的目的。值得注意的是启用S3生命周期管理,现在已经不需要先启动S3版本控制就可以直接开启生命周期管理了。可以同时对文件当前的版本和历史版本进行生命周期管理
-
还可以启用MFA Delete功能,在删除某个文件时需要不同的拥有者才能达到文件删除或版本更改的目的
-
工作原理
- 将某个文件保存后,其之前的版本都会存在,不过版本号不同;在delete操作时,没有写删除哪一个版本时,会生成一层带有delete marker的版本;此时如果执行get操作,获取这个删除版本,就会得到一个错误;当精确到某个版本时,则会将该版本直接删除,而不是生成一个delete marker版本层

-
实验操作
-
创建一个新的bucket,勾选versloning,其他默认即可,此时该bucket就是一个带有版本控制功能的bucket
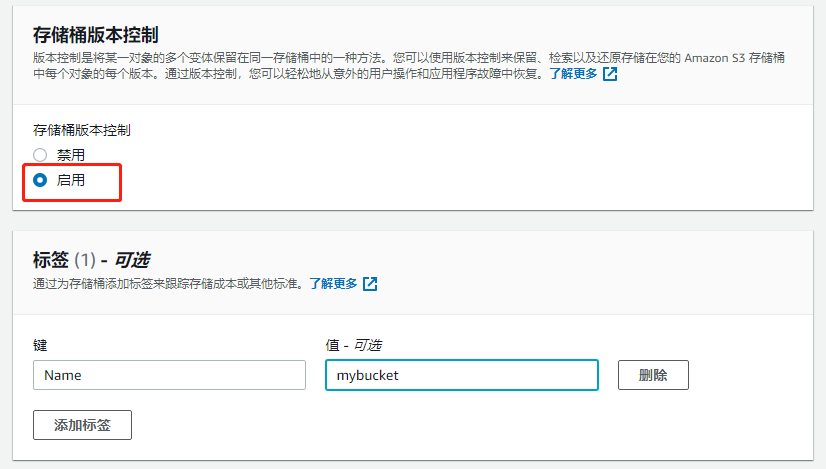
-
上传文件,看到上传成功。此时打开该本地文件,添加新的内容并保存,此时在上传该文件,可以看到文件的size发生变化,此时没有看到之前的版本,需要点击 显示版本 来查看,此时就可以查看到历史版本。注意有的版本被删除后,会产生 删除标记 ,实际上查看版本后发现源文件并未被删除,只有再次删除后才会彻底删除生效
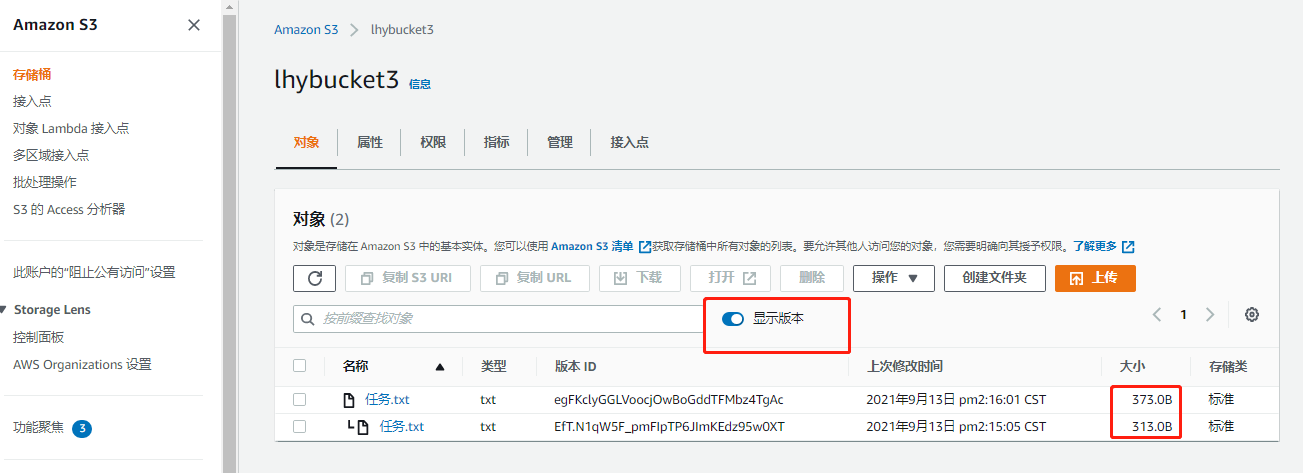
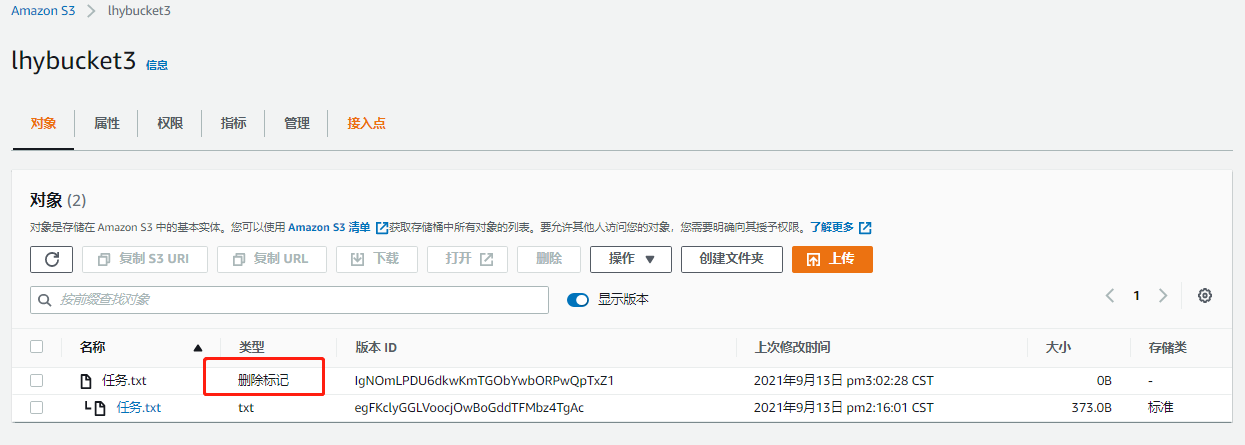
-
-
与生命周期管理功能结合使用
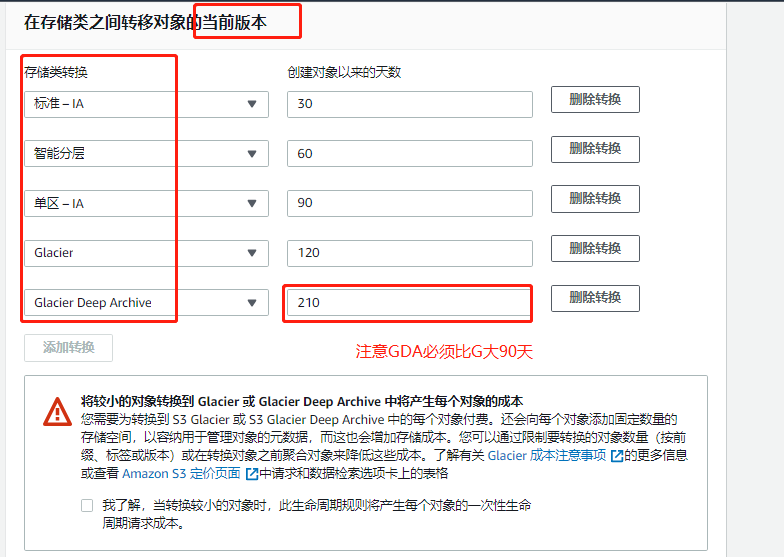
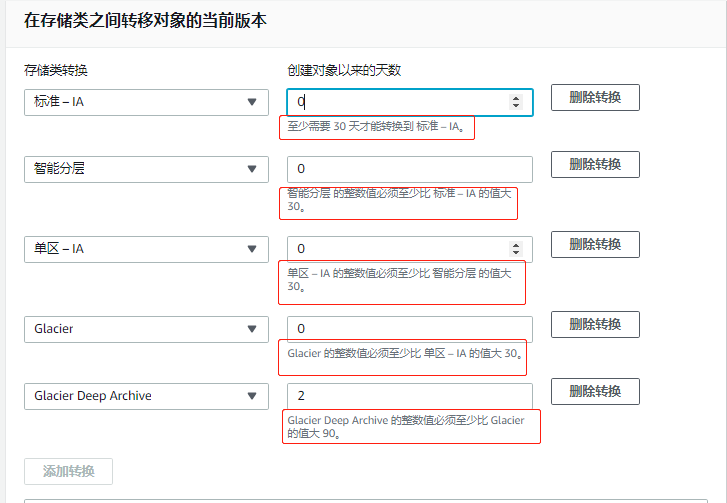
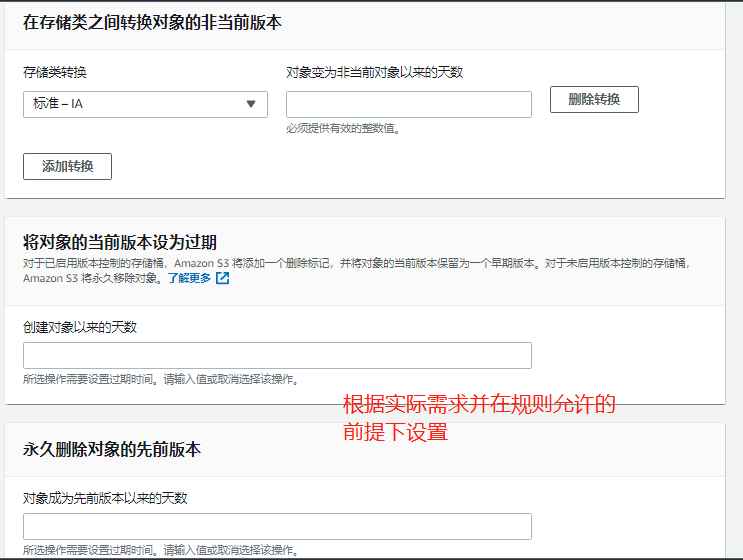
- 进入bucket管理界面,下面有一个lifecycle,点击add lifecycle rule,自定义名称,下面是策略,默认下一步即可,勾选previous版本。点击下面的add处,在下拉菜单路里选择 “移动到是s……IA”,右边写入30,表示在30天后,将之前的版本移动;可以点add再添加一层策略,选择“移动到G……”,右边写180,表示180天后移动到G……这个区域;可以点add再添加一层策略,选择“移动到D……A”,右边写365,表示365天后移动到D……A这个区域;next,选previous(表示多久后将这些版本自动永久删除),next,保存即可
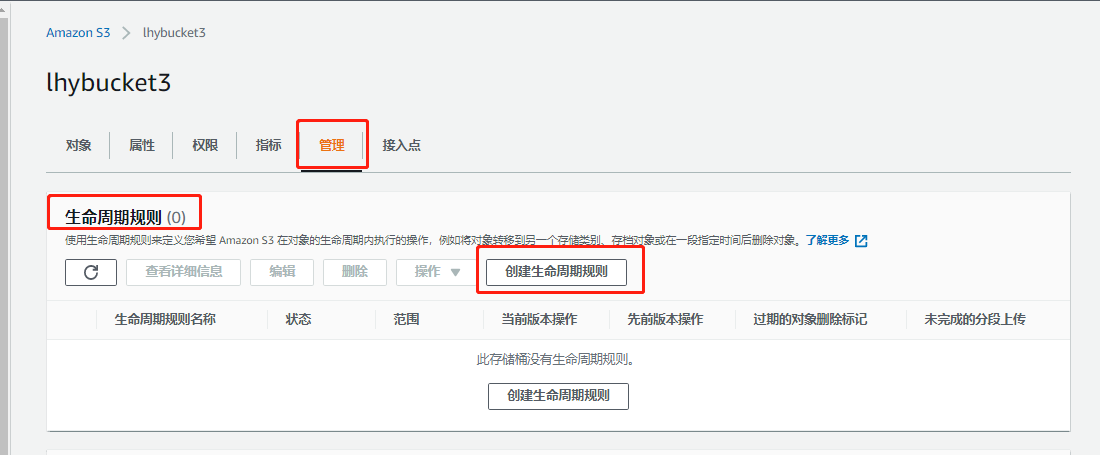
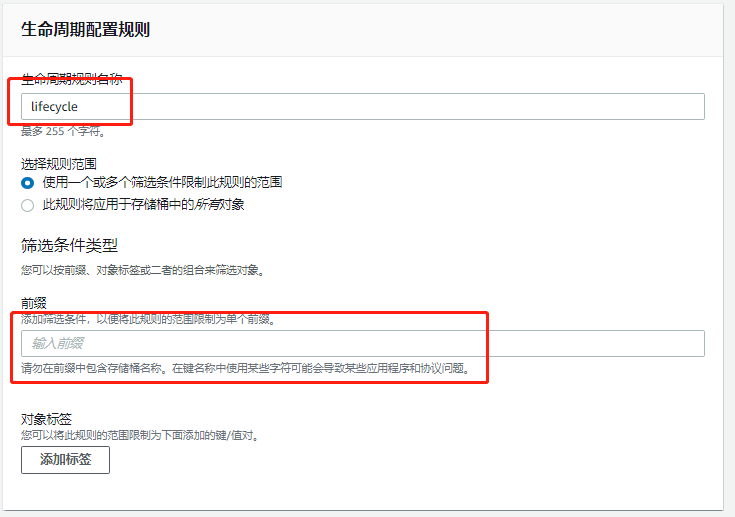

- 进入bucket管理界面,下面有一个lifecycle,点击add lifecycle rule,自定义名称,下面是策略,默认下一步即可,勾选previous版本。点击下面的add处,在下拉菜单路里选择 “移动到是s……IA”,右边写入30,表示在30天后,将之前的版本移动;可以点add再添加一层策略,选择“移动到G……”,右边写180,表示180天后移动到G……这个区域;可以点add再添加一层策略,选择“移动到D……A”,右边写365,表示365天后移动到D……A这个区域;next,选previous(表示多久后将这些版本自动永久删除),next,保存即可

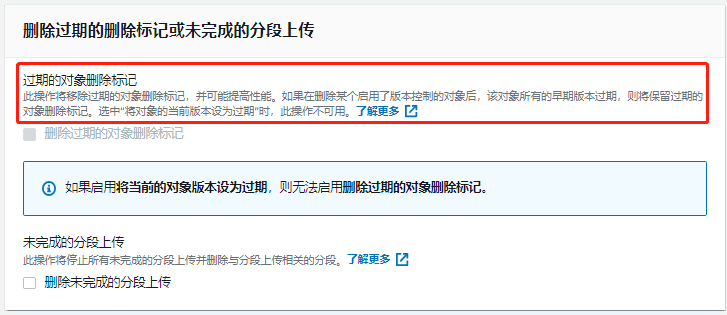
7 s3网站托管
- 特点:
- 该功能只服务静态网页
- 网页的内容是放在s3的bucket里的,bucket必须可公开访问
- s3 url不支持https,其托管的静态网站url(url的形式:[bucket-name].s3-website-[AWS-region].amazonaws.com)。注意区分与普通S3的url的区别,普通s3的url以https开头(https://s3.区域.amazonaws.com/其他内容)
- 支持客户化域名
- 实验:
-
准备一个html文件,创建一个bucket,注意取消组织所有公开访问选项,否则无法通过网页访问,将网页文件上传
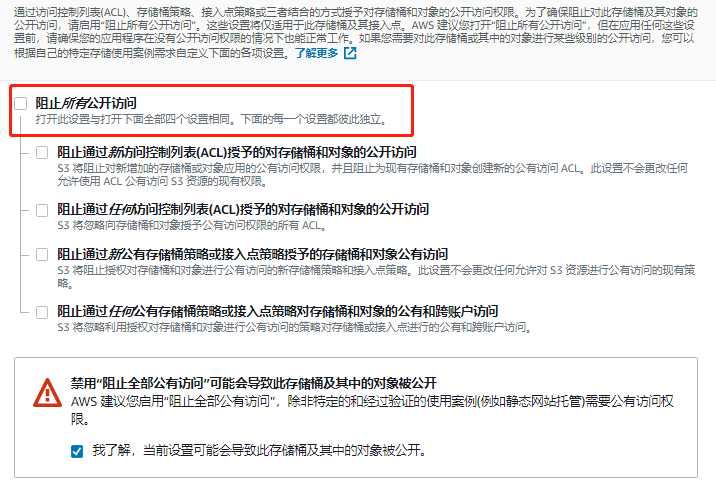
注意上传文件时,需要授予其被公开访问的权限


-
在bucket的属性里打开网站托管功能
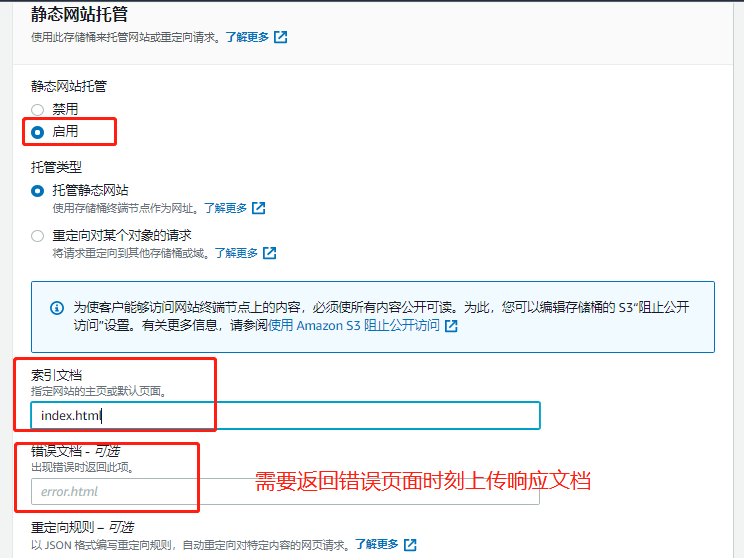
-
此时进入该bucket的属性中的静态网站托管处中,复制url,将其在网页中打开,就可以看到刚才上传的页面


-
8 s3跨域资源共享(CORS)
- 同源策略:在该策略下某个网页文档只能调用和它在同一个服务器上的网页资源
- 跨域资源共享:控制跨不同域资源的访问,比如网站A的网页请求网站B的图片,字体等
- CORS的特点
- 绝大部分浏览器支持CORS
- 服务端和客户端浏览器共同使用http头信息来完成验证
- 浏览器根据header决定是否发出请求
- 服务器端根据header决定是否给予访问
9 CloudFront内容分发网络(CDN)
- 特征:
- 支持将静态或动态的部分内容分发到全球 216 个节点(205 个边缘站点和 11 个区域性边缘缓存)的全球网络,以达到减少用户访问延迟的目的
- 边缘站点:边缘站点是内容缓存的地方,它存在于多个网络服务提供商的机房,它和AWS区域和可用区是完全不一样的概念
- 源(origin):这是CDN缓存的内容所使用的源,源可以是一个S3存储桶,可以是一个EC2实例,一个弹性负载均衡器(ELB),API网关
- 或Route53,甚至可以是AWS之外的资源
- 分配:这是 AWS cloudfront创建后的名字,分配分为两种类型,分别是 一般的网站应用和媒体流
- 不只是可以从边缘站点读取数据,你还可以往边缘站点写入数据(比如上传一个文件),边缘站点会将你写入的数据同步到源上
- 在CloudFront上的文件会被缓存在边缘节点,缓存的时间是TTL(Time To Live)。文件存在超过这个时间,缓存会被自动清除
- 如果在到达TTL时间之前,你希望更新文件,那么你也可以手动清除缓存,但你将会被AWS收取一定的费用
- 支持SSL/TLS协议
- 可以和s3、EC2、Lambda等其他服务一起使用(前面所说道的网站托管不支持https协议,结合CDN使用则可以实现)
- 实验:
-
进入s3界面,创建一个默认bucket即可,将网页内容上传,此时是无法访问该文件的
-
进入services,寻找CloudFront,进入界面,点击创建,选择web处的按钮,会进入一个界面,在odn处,选择创建的bucket的名称,rba选yes,oai处选第一个,在comment处自定义名称,grpob选yes,下面的vpp处选择rhth(将http重定向到https),其他选项均默认即可,create即可
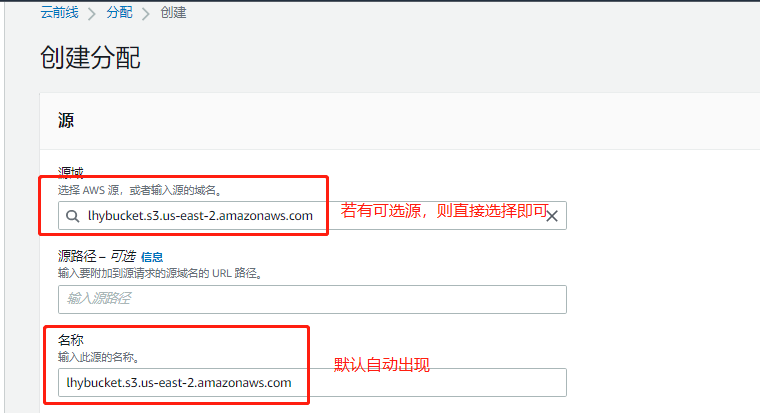


-
点击左侧导航栏的distributions,等待status处状态更新完成。点击左侧导航栏的origin access identify 就可以看到刚才创建的用户id等内容
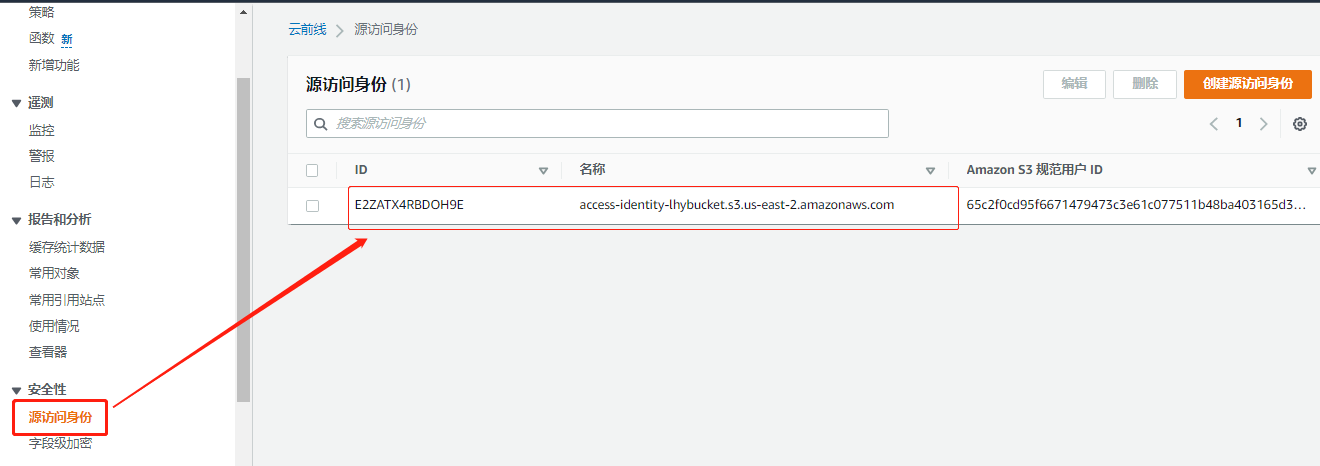
-
回到s3界面,进入bucket的permission,进入存储桶策略处,就可以看到自动生成了规则,注意下面的OAI id 与在cloudfront处生成的一致
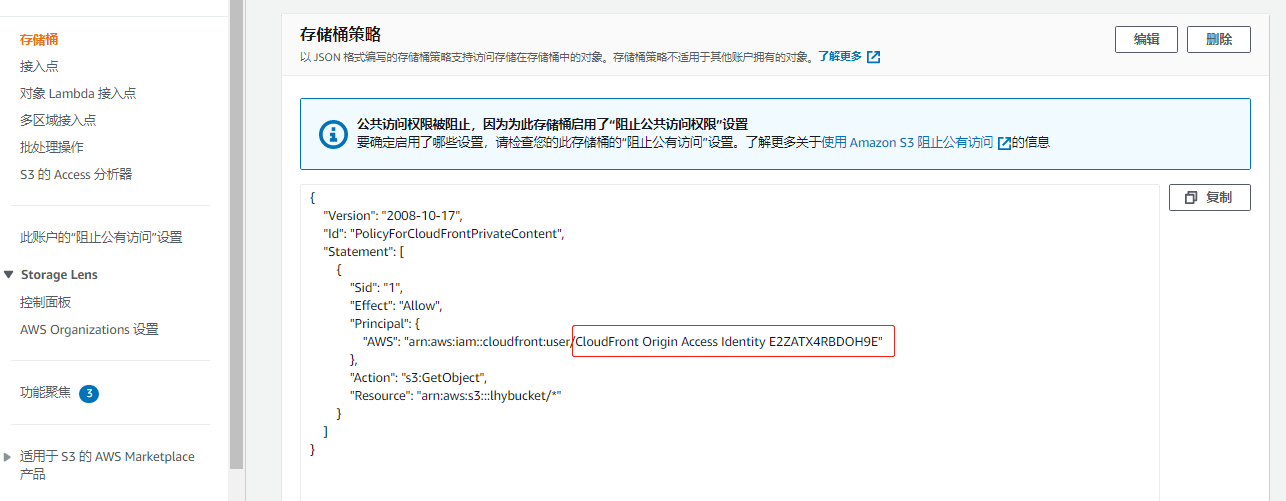
-
当distributions的状态完成后,表头里面会有一个domain name,这是自动分配的域名。在网址处输入“https://生成的域名/index.html",即可访问到该网页


-
此时回到s3依然无法打开该文件,该文件依旧是私有的状态,如此便实现了s3网站托管与CDN结合实现https访问的目的

-
清理实验环境,避免收取费用。进入CloudFront,勾选需要清理的设置,点击disable。disable后等待一会
-
再次勾选点击删除即可
-
10 CloudFront发布私有内容
- 限制对源服务器的访问:
- 签名URL
- 工作原理:当客户对私有内容发起请求时,首先应用服务器需要验证用户的合法性,之后对用户的请求url进行签名,再将签名后的url返回给用户,用户拿到后再次去请求私有内容,CloudFront在收到url后会对签名进行验证,确认有效后,再将私有内容发送给客户。这一系列法人过程对用户是透明的
- 使用场景:使用RTMP协议的(该协议是Adobe的流媒体传输协议)、用户请求的是单个文件、用户使用的客户端不是一个标准的浏览器而是定制化的客户端
- 签名cookies
- 工作原理:用户登录网站,在还没有发起内容请求时,应用服务器会先判断用户的权限,然后给用户发三个cookies的头部信息,之后用户对私有的内容发起请求,浏览器会自动将用户的请求添加到cookies的头部信息里,CloudFront对用户的cookies进行验证,有效后才会将内容发送给用户
- 使用场景:用于限制多个文件(比如限制整个网站访问)、不想更改当前url
- 签名URL
11 S3传输加速,跨区域复制以归档数据还原
11.1 传输加速
-
概念:用于对长距离的文件传输进行加速,可用于下载或上传,传输加速是以bucket为单位进行配置的,注意bucket有一个限制(bucket的名字不可以包含‘.’)。一般来说,在上传文件到S3存储桶的时候,是直接通过Internet将数据传输到位于某一个区域的S3存储桶。但如果存储桶位于一个离用户比较远的区域(比如说S3存储桶位于东京区域,而我们的用户位于中国),那么基于Internet的传输速度就会非常慢。这个时候使用S3传输加速 ,可以利用AWS CloudFront CDN网络的边缘节点(Edge Locations)加速传输的过程。我们可以将数据上传到离我们最近的边缘节点(比如说香港),然后再通过AWS内部网络(更高速,更稳定)传输到东京区域的S3存储桶。
-
使用场景
- 您位于全球各地的客户需要上传到集中式存储桶
- 您定期跨大洲传输数 GB 至数 TB 数据
- 您在上传到 Amazon S3 时未充分利用 Internet 上的可用带宽
-
实验:
- 首先进入到s3的界面,创建一个默认的bucket,在其属性里,有transfer acceleration,选择enabled,下面有一个加速终端节点,上传数据时,通过它进行上传。
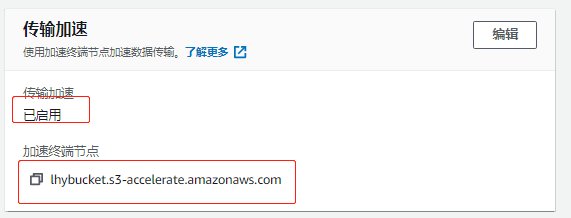
- 首先进入到s3的界面,创建一个默认的bucket,在其属性里,有transfer acceleration,选择enabled,下面有一个加速终端节点,上传数据时,通过它进行上传。
11.2 跨区域复制
- 概念:这是一种自动、异步的跨区域数据复制。注意源和目的的桶(bucket)必须在不同区域;源和目的的桶都必须启用版本控制功能;如果源桶启用了对象锁,目的桶也必须启用
- 特点
- 启用S3跨区域复制首先需要在源S3存储桶和目标S3存储桶都开启S3版本控制功能,并且源S3存储桶和目标S3存储桶不能位于同一个区域
- 在开启跨区域复制前的已存在的文件不会被自动同步,开启跨区域复制之后,新增加的文件会被自动同步
- 跨区域复制不能叠加,意味着数据不可以从A同步到B,然后再同步到C
- 删除文件,文件的某一个版本或者删除删除标记(Delete Marker)是不会被同步的
- 实验
-
开启bucket的版本控制,再创建一个另外区域的bucket,其他选项默认即可
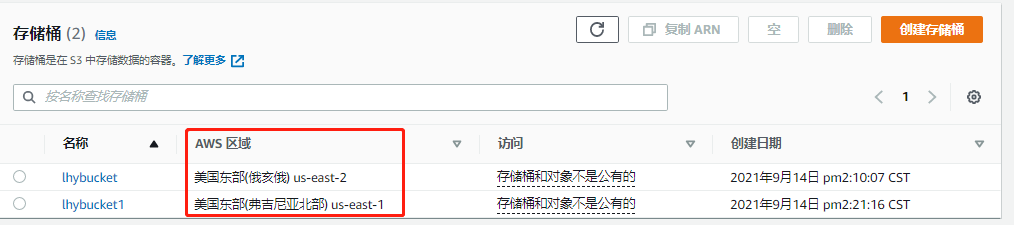
-
创建复制规则。此时再重新进入management中的replication,就可以看到一条复制规则



-
上传一个文件,再进入目的桶查看,可以看到文件同时也复制到了这个桶

-
将源桶中的文件删除,可以看到该文件被标记为delete marker。此时去目的桶中查看,该被标记的文件并不会被同步


-
11.3 归档数据的还原
- 概念:s3中不常用的数据就可以将其归档在Glacier的存户类型里,当需要拿回已经归档好的数据时,有几种常用的方法
- 加速的归档数据还原:除了最大归档,归档数据一般5分钟内就可以被访问,这种方法收费是最高的
- 标准归档数据还原:该方法一般是默认的还原选项,一般会在3-5个小时内完成还原
- 批量数据还原:该方法用于还原大量数据的低成本选项,一般在5-12小时内完成
12 Snow Family数据导入导出服务
-
Snowball 是一种 PB 级【k–> M–>G–>T–>P】数据传输解决方案,旨在使用安全设备将大量数据传入和传出亚马逊 AWS。通过使用 Snowball 服务,你可以将 PB 级别的分析数据、基因组数据、视频库等数据简单地、快速地、安全地传送到 AWS 的数据中心去,并且花费低至使用高速互联网的五分之一
-
数据的导入导出有几种不同类型的设备。
- aws的snowball设备,有50/80T两种规格,数据时加密的,传输完成后数据会被清除
- aws的snowbaal edge设备,最多可以达到100T的使用空间,可单纯用于存储、计算优化(可以运行虚拟机)、有GPU功能(可以做人工只能计算等)。它与snowball很类似,只是它还另外提供了计算的功能,它除了能提供 100TB 的数据传输能力外,还有 AWS Lambda 的计算能力。
- aws的snowmobile,最高可存放100PB的数据,有GPS追踪功能。AWS Snowmobile 是一种用于将海量数据移动到 AWS 中的 EB 级数据传输服务
-
snowball的特点
- 可以在本地数据中心和 Amazon S3 之间进行数据的导入和导出
- 可以同时使用多个 Snowball 并行传输数据
- 事实上,Snowball 是一个重21公斤的大盒子,里面配置了16核的 CPU 和 16G 的内存,并且有RJ45,SFP+ 网络接口,最高支持 10Gbps 网络。使用 AWS Snowball,你需要到 AWS 管理控制台申请,AWS 会邮寄一个物理 Snowball 给你,然后你需要通过以太网和客户端软件把数据从本地传输到 Snowball上,最后将 Snowball 邮寄给 AWS 即可。AWS 会负责将 Snowball 内的数据导入到你所需要的 S3 存储桶上。
-
使用场景
- 云迁移、灾难恢复、数据中心停用、内容分配
- 如果您需要更加安全快速地将数 TB 到数 PB 数据传输到 AWS,那么 Snowball 是数据传输的一个有效选择。如果您不希望对网络基础设施进行昂贵的升级、您经常遇到大量数据积压的情况、您在物理隔绝环境下工作,或者您所在的区域没有高速 Internet 连接或这种高速连接的成本过高,Snowball 同样是正确的选择。
-
申请步骤:
- 进入aws的snowball界面,可以直接在services处搜索即可,进入后点击create,进入后有三个选项,选择第一个导入到s3,next
- 如果是第一次使用,可以选择添加一个新的地址,带*的必填即可
- 进入后先自定义一个名称,然后在设备导入处选择第一个snowball,在最下面的bucket name处选择一个bucket,也就是数据存储在哪一个桶中,next
- 在permission处选择create/select IAM role,也就是选择一个可以对该bucket进行操作的role,进入后在policy name处选择即可
- 在encryption处的kms里选择一个秘钥(可以选择默认的),next
- 结束后可以提交,提交完申请后,AWS会寄发设备过来帮助你进行数据导入
13 存储网关
-
AWS Storage Gateway 是一种具有无缝本地集成和优化数据传输的混合云存储方案。你本地数据中心内的服务器可以通过 AWS Storage Gateway 连接访问 Amazon S3、Amazon Glacier、Amazon EBS 等 AWS
存储服务来进行备份、存档、灾难恢复、数据迁移等等。在任何类型的网关设备与 AWS 存储之间传输的所有数据均已使用 SSL 进行了加密。AWS Storage Gateway 已作为硬件设备提供 -
概念:用于整合本地IT环境和AWS存储的一项服务,该服务的关键就是一台虚拟的存储网关,可将本地的存储与aws的存储打通,使得客户可以使用s3的功能达到数据可靠的预期,如下图所示

-
存储网关的三种形式
-
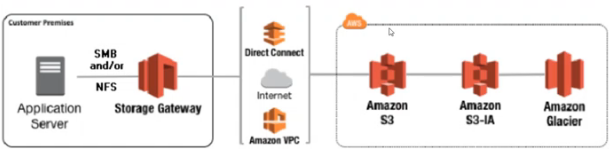
文件网关:通过nfs/smb协议将文件系统分享给应用服务器的虚拟设备。当存储网关将数据分享给服务器后,服务器会读写数据,存储网关再将数据传输到S3的bucket中,下图是文件网关的架构。注意不能使用文件网关将文件写入EFS
-
卷网关:其存储设备是以块存储的形式分享给服务器使用,使用 iSCSI 作为本地磁盘连接到本地服务器上,让本地服务器可以访问到 Amazon S3 内的文件(iscsi同nfs一样,都是为实现共享),它主要有两种不同形式的架构
-
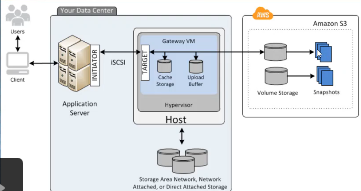
缓存卷架构:在这种架构中,S3是主要的存储,本地的存储网关挂载的卷来自于本地的存储设备,主要是作为一个缓存设备(缓存s3中常用的数据到本地挂载的卷中),本地卷最大是32T,并通过ISCSI协议分享给本地服务器,当服务器对数据卷进行读写后,将数据缓存同时通过upload buffer传到s3上,s3做好快照后,再传到s3上。也就是说,所有的数据都会保存到S3,但是会将最经常访问的数据缓存到本地
-
存储卷架构:它与缓存卷架构最大的区别在于s3处主要是用来备份数据的存储设备,主要的存储是本地的卷,本地的存储会传输到存储网关,然后通过ISCSI协议发送到服务器。而数据的读写主要发生在存储网关,在本地快照好后,传到s3中存储快照。也就是说所有的数据都将保存到本地,但是会异步地将数据备份到AWS S3上
-
-
磁带网关:在这种模式的架构中,虚拟网关主要是作为虚拟磁带库使用,每个网关预配置虚拟机械手和磁带机
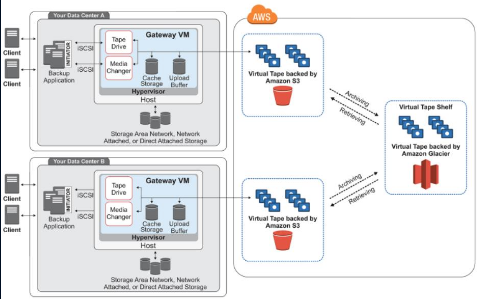
-
14 S3数据查询Athena服务
- 概念:Athena是一种交互式查询服务,可以使得我们使用标准SQL直接在S3中轻松分析数据
- 特点:
- 无需管理底层架构
- 仅为查询付费
- 自动扩展,并行查询
本文链接:https://my.lmcjl.com/post/7194.html
4 评论