

来源 | 清平の乐
来源 | CSDN博客,责编 | Carol
头图 | CSDN 下载自视觉中国

一、数据存储类型
一般情况下,我们将存储分成了4种类型,基于本机的DAS和网络的NAS存储、SAN存储、对象存储。对象存储是SAN存储和NAS存储结合后的产物,汲取了SAN存储和NAS存储的优点。
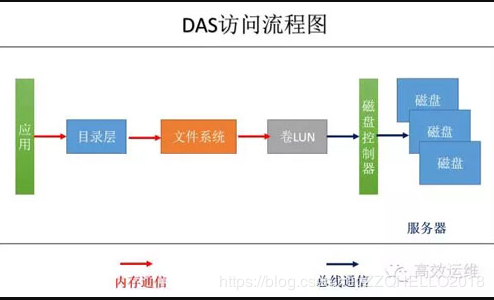
1.DAS
DAS将计算、存储能力一把抓,封装在一个服务器里。大家日常用的电脑,就是一个DAS系统。
2.NAS
如果将计算和存储分离了,存储成为一个独立的设备,并且存储有自己的文件系统,可以自己管理数据,就是NAS。所以NAS存储可以被不同的主机共享。服务器只要提需求,不需要进行大量的计算,将很多工作交给了存储完成,省下的CPU资源可以干更多服务器想干的事情,即计算密集型适合使用NAS。
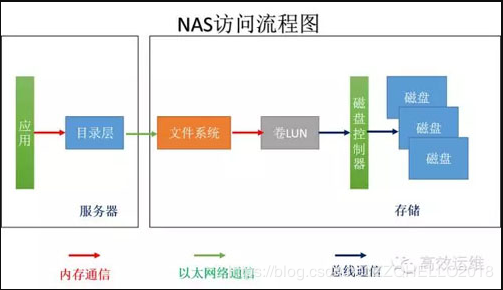
3.NAS
计算和存储分离了,存储成为一个独立的设备,存储只是接受命令不再做复杂的计算,只干读取或者写入文件2件事情,叫SAN。
因为不带文件系统,所以也叫“裸存储”,有些应用就需要裸设备,如数据库。存储只接受简单明了的命令,其他复杂的事情,有服务器端干了。再配合FC网络,这种存储数据读取/写入的速度很高。
但是每个服务器都有自己的文件系统进行管理,对于存储来说是不挑食的只要来数据我就存,不需要知道来的是什么,不管是英语还是法语,都忠实记录下来的。但是只有懂英语的才能看懂英语的数据,懂法语的看懂法语的数据。所以,一般服务器和SAN存储区域是一夫一妻制的,SAN的共享性不好。当然,有些装了集群文件系统的主机是可以共享同一个存储区域的。
4.对象存储
对象存储大量使用在互联网上,大家使用的网盘就是典型的对象存储。对象存储有很好的扩展性,可以线性扩容。并可以通过接口封装,还可以提供NAS存储服务和SAN存储服务。
VMware的vSAN本质就是一个对象存储。

二、分布式存储系统
普通存储方案:Rsync、DAS(IDE/SATA/SAS/SCSI等块)、NAS(NFS、CIFS、SAMBA等文件系统)、SAN(FibreChannel, iSCSI, FoE存储网络块),Openfiler、FreeNas(ZFS快照复制)由于生产环境中往往由于对存储数据量很大,而SAN存储价格又比较昂贵,因此大多会选择分布式存储
GFS、HDFS、Lustre 、Ceph 、GridFS 、mogileFS、TFS、FastDFS等。各自适用于不同的领域。它们都不是系统级的分布式文件系统,而是应用级的分布式文件存储服务。
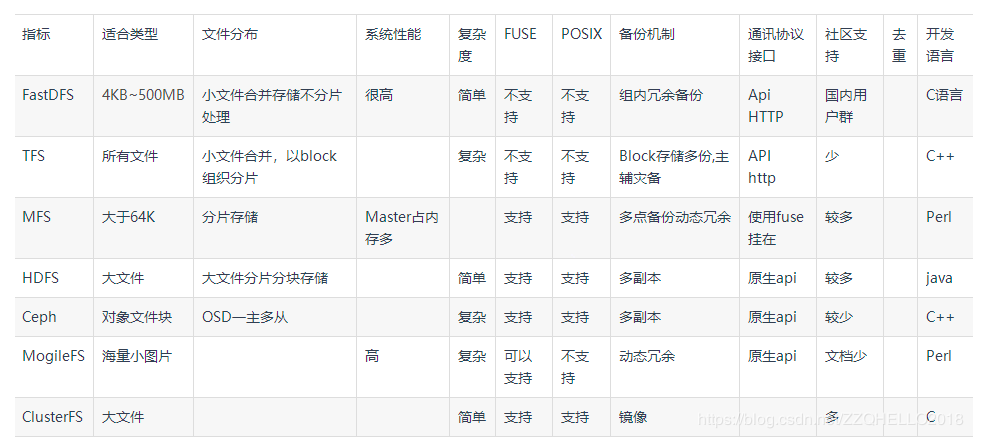
TFS
TFS(Taobao File System)是由淘宝开发的一个分布式文件系统,其内部经过特殊的优化处理,适用于海量的小文件存储,主要针对海量的非结构化数据,它构筑在普通的Linux机器 集群上,可为外部提供高可靠和高并发的存储访问。目前已经对外开源;
TFS采用自有的文件系统格式存储,因此需要专用的API接口去访问,目前官方提供的客户端版本有:C++/JAVA/PHP。
FastDFS
FastDFS是国人开发的一款分布式文件系统,目前社区比较活跃。如上图所示系统中存在三种节点:Client、Tracker、Storage,在底层存储上通过逻辑的分组概念,使得通过在同组内配置多个Storage,从而实现软RAID10,提升并发IO的性能、简单负载均衡及数据的冗余备份;同时通过线性的添加新的逻辑存储组,从容实现存储容量的线性扩容。
文件下载上,除了支持通过API方式,目前还提供了apache和nginx的插件支持,同时也可以不使用对应的插件,直接以Web静态资源方式对外提供下载。
目前FastDFS(V4.x)代码量大概6w多行,内部的网络模型使用比较成熟的libevent三方库,具备高并发的处理能力。
操作和部署过程:https://www.jianshu.com/p/b7c330a87855
HDFS
Hadoop 实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。Hadoop是Apache Lucene创始人Doug Cutting开发的使用广泛的文本搜索库。它起源于Apache Nutch,
后者是一个开源的网络搜索引擎,本身也是Luene项目的一部分。Aapche Hadoop架构是MapReduce算法的一种开源应用,是Google开创其帝国的重要基石。
GFS(Google File System)
Google公司为了满足本公司需求而开发的基于Linux的专有分布式文件系统。尽管Google公布了该系统的一些技术细节,但Google并没有将该系统的软件部分作为开源软件发布。
原文:https://blog.csdn.net/ZZQHELLO2018/article/details/105660628


推荐阅读
一文带你认识keepalived,再带你通关LVS+Keepalived!
那个分分钟处理 10 亿节点图计算的 Plato,现在怎么样了?
“谷歌杀手”发明者,科学天才 Wolfram
数据库激荡 40 年,深入解析 PostgreSQL、NewSQL 演进历程
超详细!一文告诉你 SparkStreaming 如何整合 Kafka !附代码可实践
5分钟!就能学会以太坊 JSON API 基础知识!
真香,朕在看了!
本文链接:https://my.lmcjl.com/post/8469.html
4 评论