引入
做过大数据或者接触过数仓的同学,相信都有听到过数据治理、血缘分析的专业术语。不知道大家有没有思考过以下几个问题:
1、什么是血缘分析?主要分析什么东西?
2、为什么要做血缘分析,主要是为了解决什么痛点?做出来之后有什么价值?如何衡量这些价值?
3、如何做血缘分析?
关于第1,2个问题是需要结合每个企业实际的情况来思考,当然分析其本质就是方便数据梳理。那么本篇主要侧重于第3个问题,通过工程+方法论的方式来为读者们揭开血缘分析功能的神秘面纱。
效果展示
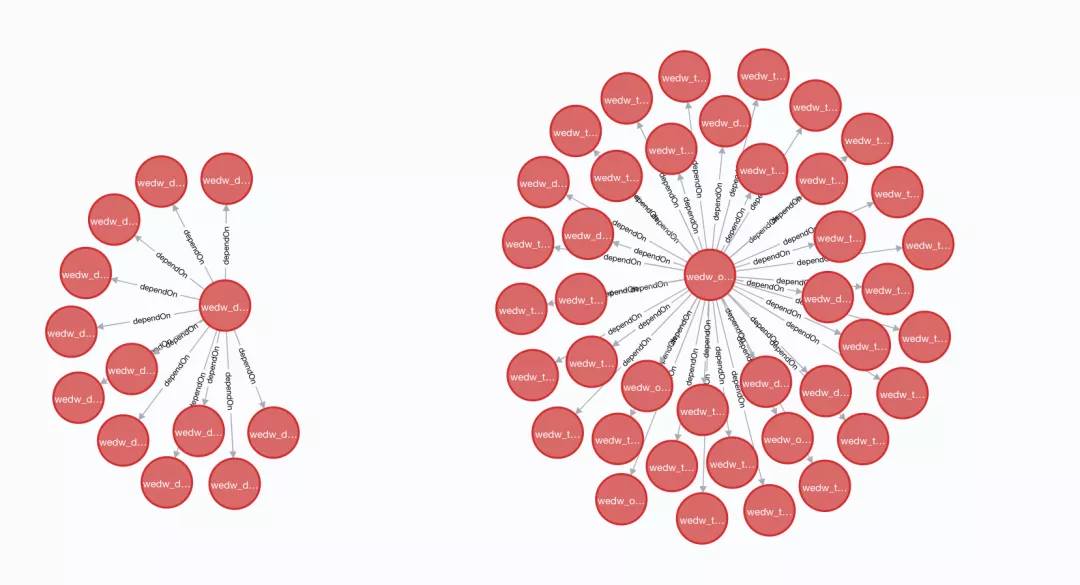
关于如何做血缘分析,其实每个企业的做法都大差不差,主要差别在于实现的深度。例如:有的企业是直接引用现有的开源工具,有的企业是结合自身的产品进行自研,有的企业可能只做到表级别,有的企业做到字段级别。那么本篇将会为读者们提供一种表级别粒度的分析功能,并通过可视化的方式为大家展示,当然本篇文章是属于抛砖引玉,主要是给大家提供一种思路。先为读者们展示最终效果图:
执行底层
在数仓工作职责内,大部分都是SQL化,因此血缘分析大多数都是基于SQL解析来做。当然也有非SQL的场景,不过其思想和做法都是一样的,只是API层面的调用不同而已。本篇就以Spa
本文链接:https://my.lmcjl.com/post/9760.html
展开阅读全文
4 评论