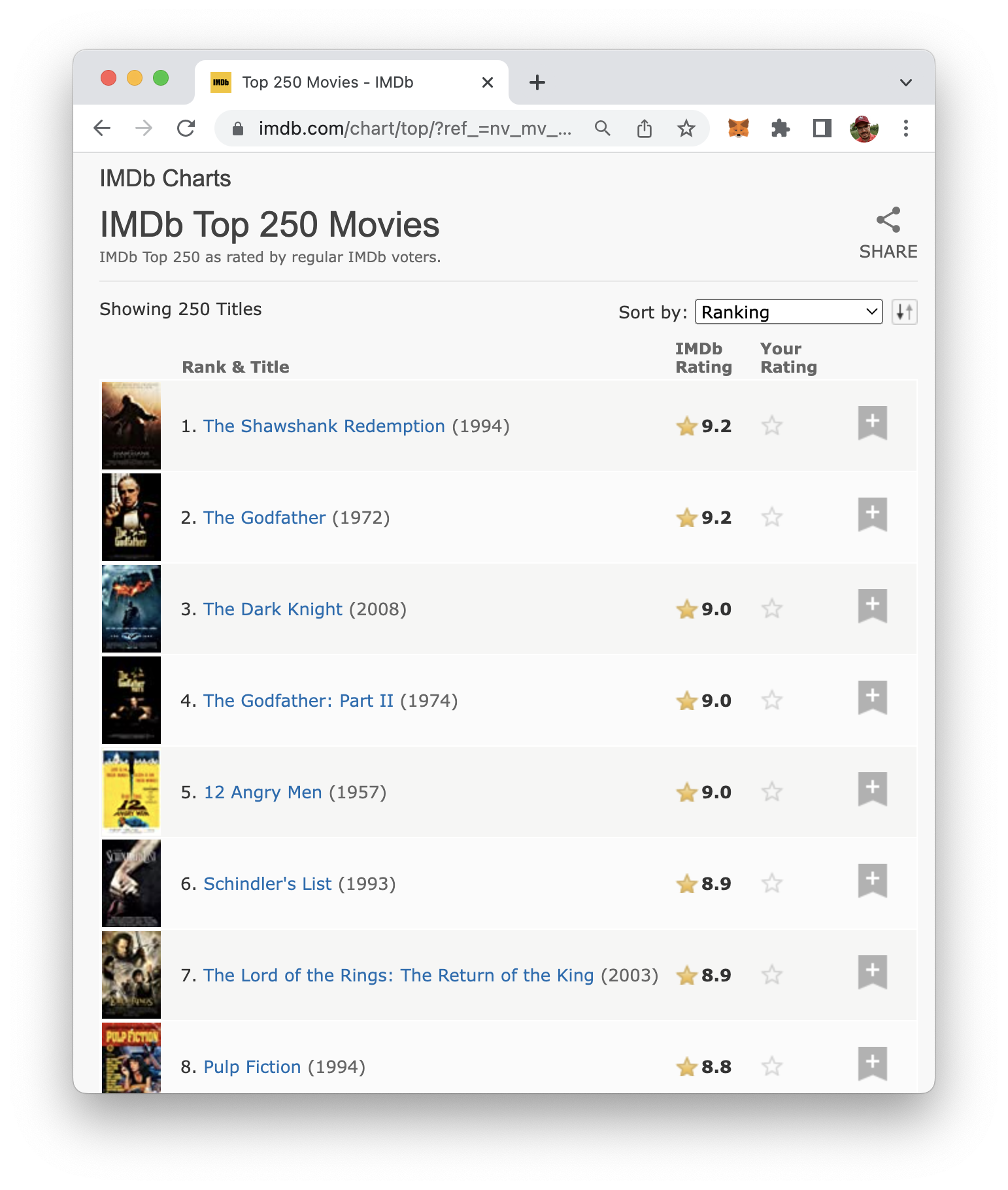
Web 抓取是使用脚本从网站自动提取数据的过程。ChatGPT 能够为您生成网络抓取脚本代码。让我们看看这是如何工作的……IMDb 是一个提供有关电影、电视节目和其他娱乐形式的信息的网站,包括评分最高的电影图表,该网站https://www.imdb.com/chart/top/?ref_=nv_mv_250显示 IMDb 上评分最高的 250 部电影的列表,包括它们的标题、演员、导演、和 IMDb 评级:假设我们想使用网络抓取通过 继续阅读
如何使用 ChatGPT 完全自动化网页抓取