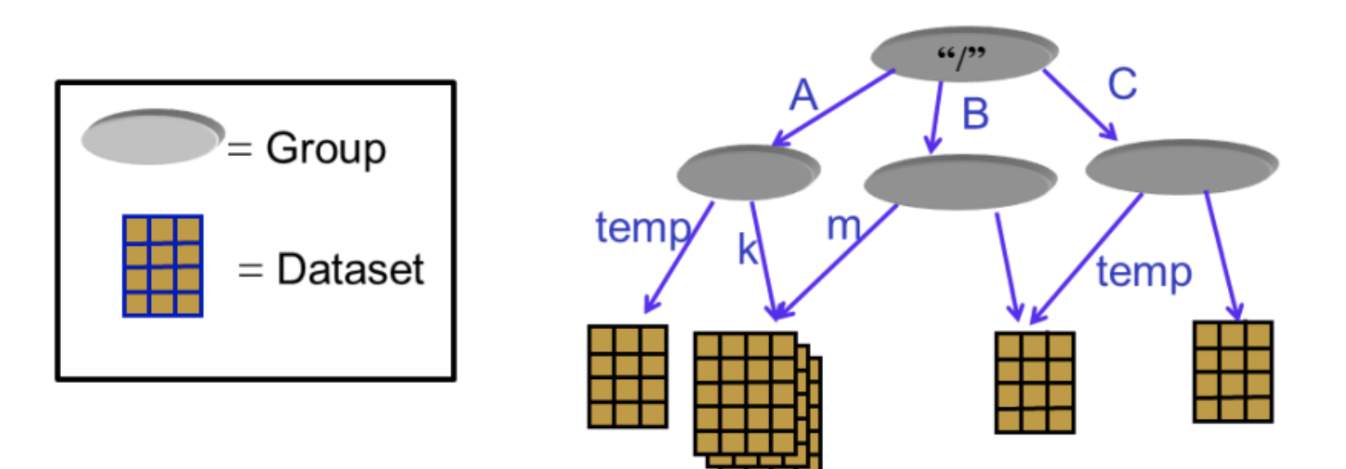
背景:h5文件详解 H5文件是层次数据格式第5代的版本(Hierarchical Data Format,HDF5),它是用于存储科学数据的一种文件格式和库文件。由美国超级计算中心与应用中心研发的文件格式,用以存储和组织大规模数据. H5将文件结构简化成两个主要的对象类型: 数据集dataset,就是同一类型数据的多维数组 组group,是一种容器结构,可以包含数据集和其他组, 继续阅读
h5文件格式详解及h5文件与图片文件之间的相互转换(python实现)