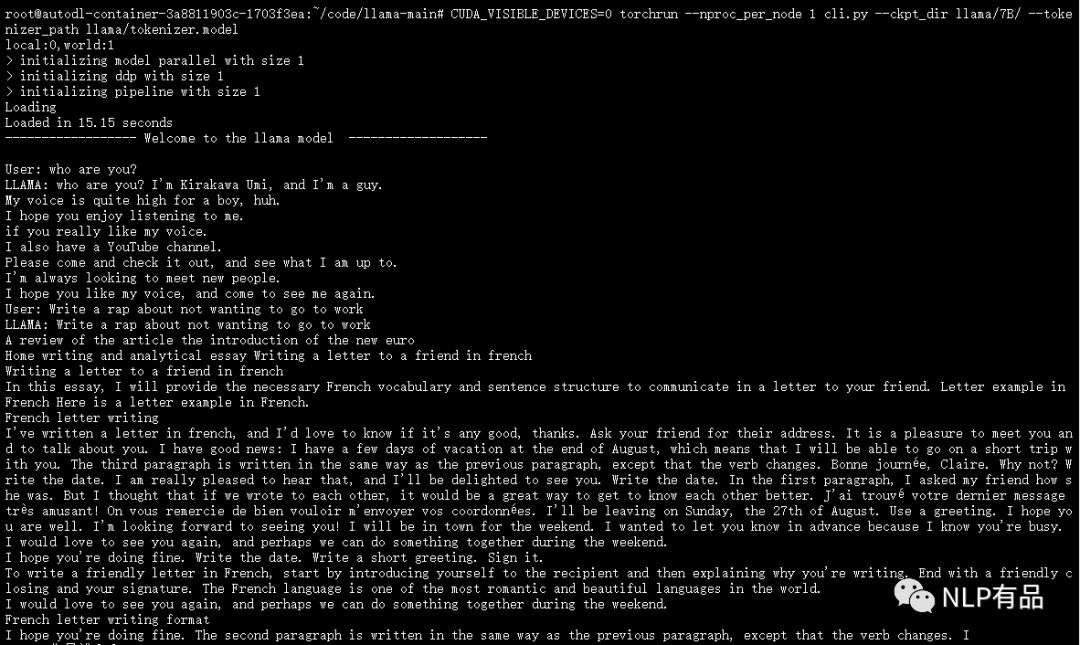
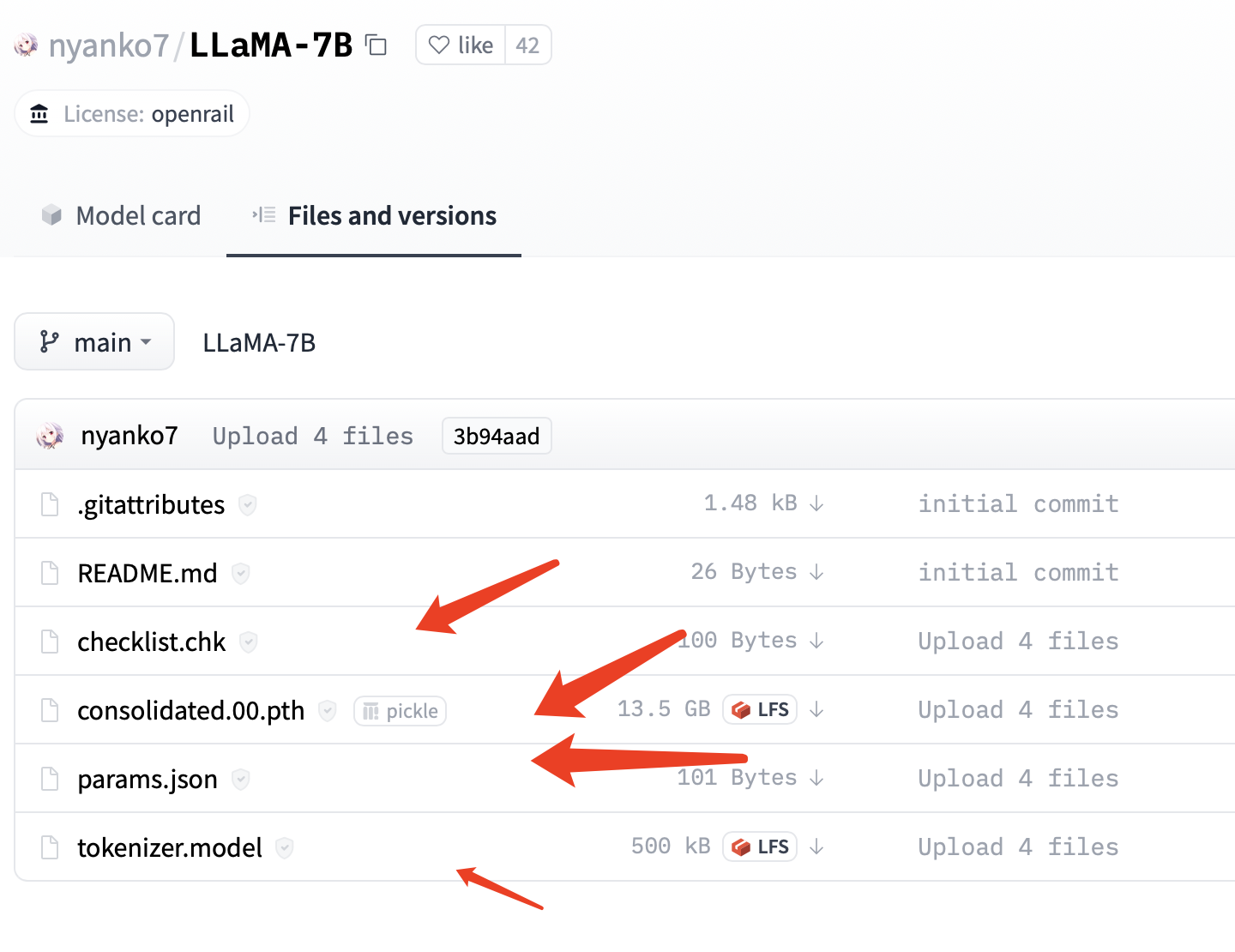
最近,FacebookResearch 开源了他们最新的大语言模型 LLaMA,训练使用多达14,000 tokens 语料,包含不同大小参数量的模型 7B、13B 、30B、 65B,研究者可以根据自身算力配置进行选择。 经过测试,(1)在算力要求上,7B的模型,需要19G显存要求,单卡3090可部署。(2& 继续阅读
ChatGPT开源平替(2)llama