本文将从解答标题、CSV与pyspark的关系、异常处理、性能优化、数据可视化等多个方面详细阐述pyspark CSV 少数据处理。 一、CSV与pyspark的关系 CSV是一种常见的文件格式,是将数据按照逗号分隔的文本文件,在数据处理中占有很重要的地位。pyspark是一个分布式计算框架,是处理大规模数据的重要工具之一。pyspark提供了读取、处理和保存CSV文件的API,可以使用CSV文件进行pyspark数据分析。在使用CSV文件进行pyspark数 继续阅读
Search Results for: Spark
查询到最新的7条
Python+Spark 2.0+Hadoop机器学习与大数据实战
Python+Spark 2.0+Hadoop机器学习与大数据实战,由清华大学出版社在2017-12-01月出版发行,本书编译以及作者信息为: 林大贵 著,这是第1次发行, 国际标准书号为:9787302490739,品牌为清华大学, 这本书采用平装开本为16开,纸张采为胶版纸,全书共有519页,字数86万4000字,值得推荐。 此书内容摘要《Python+Spark 2.0+Hadoop机器学习与大数据实战》从浅显易懂的“大数据和机器学习”原理说明入手,讲述大数据和机器 继续阅读
Spark开源项目-大数据处理的新星
Spark是一款开源的大数据分布式计算框架,它能够高效地处理海量数据,并且具有快速、强大且易于使用的特点。本文将从以下几个方面阐述Spark的优点、特点及其相关使用技巧。 一、Spark的概述与优点 Spark的出现解决了Hadoop无法在实时和迭代计算方面的不足。相比于Hadoop,Spark有以下几个优点: 速度更快。Spark采用内存计算方式,执行速度比Hadoop快100倍。 支持实时计算。Spark的设计目标是在内存中对数据进行实时处理,它能够以秒 继续阅读
Spark SQL实战(08)-整合Hive
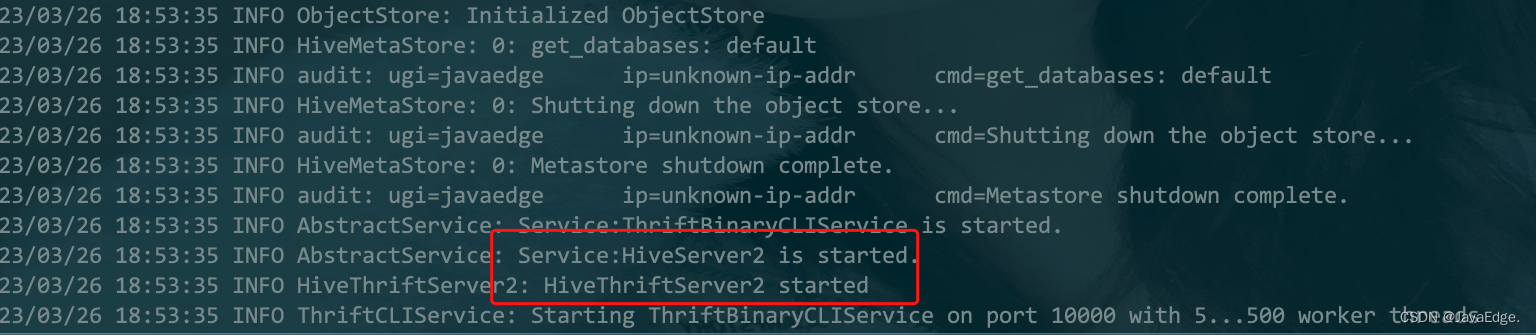
1 整合原理及使用 Apache Spark 是一个快速、可扩展的分布式计算引擎,而 Hive 则是一个数据仓库工具,它提供了数据存储和查询功能。在 Spark 中使用 Hive 可以提高数据处理和查询的效率。 场景 历史原因积累下来的,很多数据原先是采用Hive来进行处理的,现想改用Spark操作数据,须要求Spark能够无缝对接已有的Hive的数据,实现平滑过渡。 MetaStore Hive底层的元 继续阅读
Spark数据分析:基于Python语言(英文版)
编程书籍推荐:Spark数据分析:基于Python语言(英文版),由机械工业出版社2019-03-01月出版,本书发行作者信息: [澳] 杰夫瑞·艾文(Jeffrey Aven) 著此次为第1次发行, 国际标准书号为:9787111620037,品牌为机工出版, 这本书采用平装开本为16开,附件信息:未知,纸张采为胶版纸,全书共有277页字数万 字,值得推荐的Python Book。此书内容摘要 本书重点关注Spark项目的基本知识,从Spark核心开始,然后拓展到 继续阅读
hdfs读写流程_必须掌握的分布式文件存储系统—HDFS
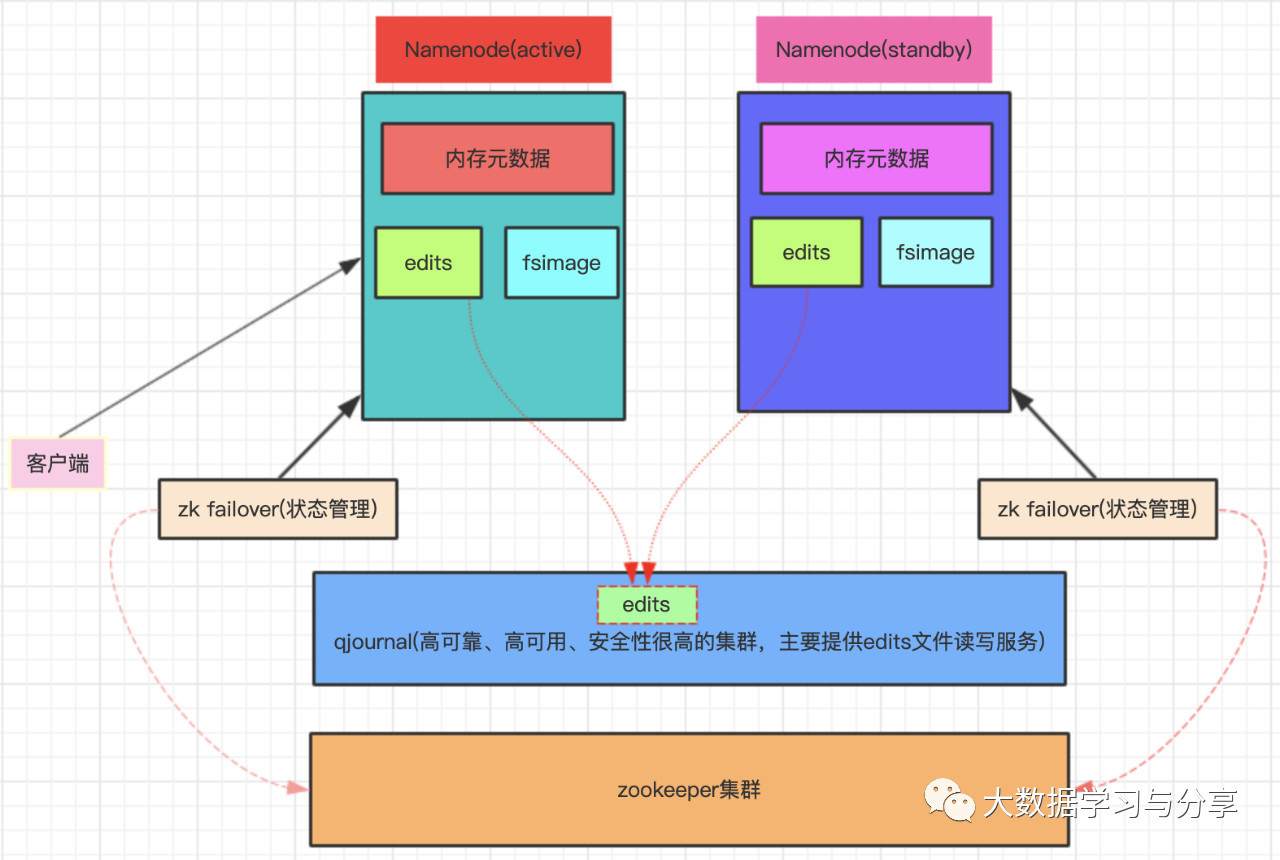
必须掌握的分布式文件存储系统—HDFSmp.weixin.qq.comHDFS(Hadoop Distributed File System)分布式文件存储系统,主要为各类分布式计算框架如Spark、MapReduce等提供海量数据存储服务,同时HBase、Hive底层存储也依赖于HDFS。HDFS提供一个统一的抽象目录树,客户端可通过路径来访问文件,如hdfs://namenode:port/dir-a/a. 继续阅读
践行之路
Scala IDE 搭建Spark 2开发环境 参考:http://blog.csdn.net/wengyupeng/article/details/52807655 详解基于maven管理-scala开发的spark项目开发环境的搭建 参考:http://blog.csdn.net/pengych_321/article/details/52014249 继续阅读