什么是让ChatGPT爆火的大语言模型(LLM) 更多精彩内容: https://www.nvidia.cn/gtc-global/?ncid=ref-dev-876561 文章目录什么是让ChatGPT爆火的大语言模型(LLM)大型语言模型有什么用?大型语言模型如何工作?大型语言模型的热门应用在哪里可以找到大型语言模型大型语言模型的挑战 AI 应用程序正在总结文章、撰写故事和进行长时间对话——而大型语言模型正在承担繁重的工作。 大型语言模型或 继续阅读
Search Results for: 内容模型
查询到最新的12条
每周AI大事件|国产大模型热战开启、AI监管规定来了、马斯克入局AIGC大战
Part1动态 「国内要闻」 其中提到利用AI生成内容应当真实准确,采取措施防止生成虚假信息;提供者应当对生成式人工智能产品的预训练数据、优化训练数据来源的合法性负责等。 知乎发布"知海图 AI" 中文大模 知乎和面壁科技合作的中文大模型“知海图AI”正式开启内测。同时,基于人工智能的“热榜摘要”开启内测,对知乎热榜上的问题回答进行抓取、整理和聚合,并把回答梗概展现给用户。 阿里所有产品将接入大模型全面升级 阿里 继续阅读
探索安卓内容提供者:构建、访问和管理数据【复习】
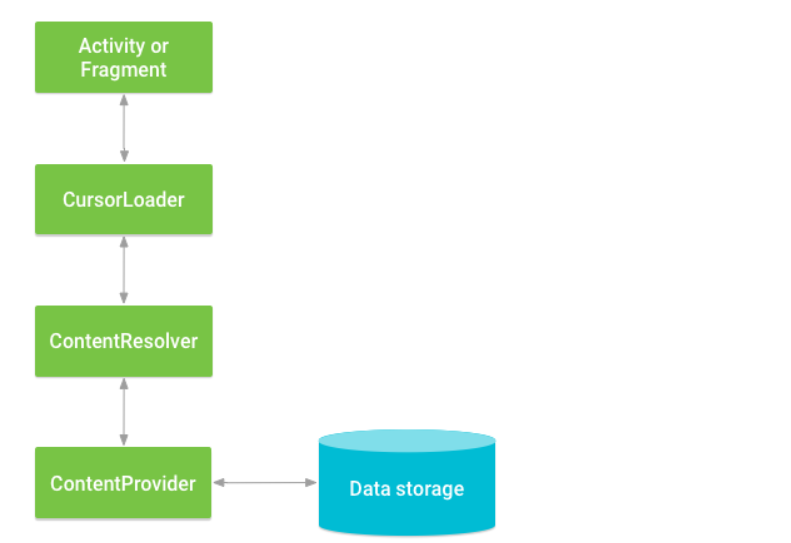
文章目录 一 ContentProvider1.1 数据模型- **ContentProvider 使用基于数据库模型的简单表格来提供需要共享的数据**,在该表格中,每一表示一条记录,而每一列代表特定类型和含义的数据,并且其中每一条数据记录都包含一个名为“_ID”的字段类标识每条数据。1.2 Uri(统一资源标识符)1.3 创建内容提供者1.4 清单文件1.5 访问其他程序的数据1.5.1 访问提供者【了解 继续阅读
chatgpt如何解决模型训练过程中一些未知错误:以xgboot devices_.IsEmpty为例

本文尝试用现在最火的chatGPT在工作中提高生产力。 具体背景如下:在训练模型过程中,为了避免资源抢占,我指定了其他的gpu来提高模型训练效率,但是发现训练的时候模型正常,但是在模型预测的时候一直报错,尝试gpu=1,2,3都报错。gpu=0,或者是不设置都不会出错。 预测的时候具体报错内容如下: XGBoostError: b' 继续阅读
【AI项目实战】某语言模型-stable diffusion-vits-cqhttp 实现能对话能语音能绘画的

好久没写文章了,终于想起来我有个博客账号系列。。 项目已开源在github上。 文章已滤敏,一切涉及语言模型名字的内容都以某语言模型代替 cqhttp 用于接收群友消息,并回复消息。 某语言模型 基于这种对话式的语言模型,可以对用户的聊天进行响应。 目前已额外支持glm离线模型 某语言模型 + stable diffusion 从用户的聊天信息中提取绘画所需的关键词。 SD 衍生功能 权重更换, 继续阅读
【AI项目实战】某语言模型-stable diffusion-vits-cqhttp 实现能对话能语音能绘画的

好久没写文章了,终于想起来我有个博客账号系列。。 项目已开源在github上。 文章已滤敏,一切涉及语言模型名字的内容都以某语言模型代替 cqhttp 用于接收群友消息,并回复消息。 某语言模型 基于这种对话式的语言模型,可以对用户的聊天进行响应。 目前已额外支持glm离线模型 某语言模型 + stable diffusion 从用户的聊天信息中提取绘画所需的关键词。 SD 衍生功能 权重更换, 继续阅读
ChatGPT国产化:ChatYuan元语对话大模型升级
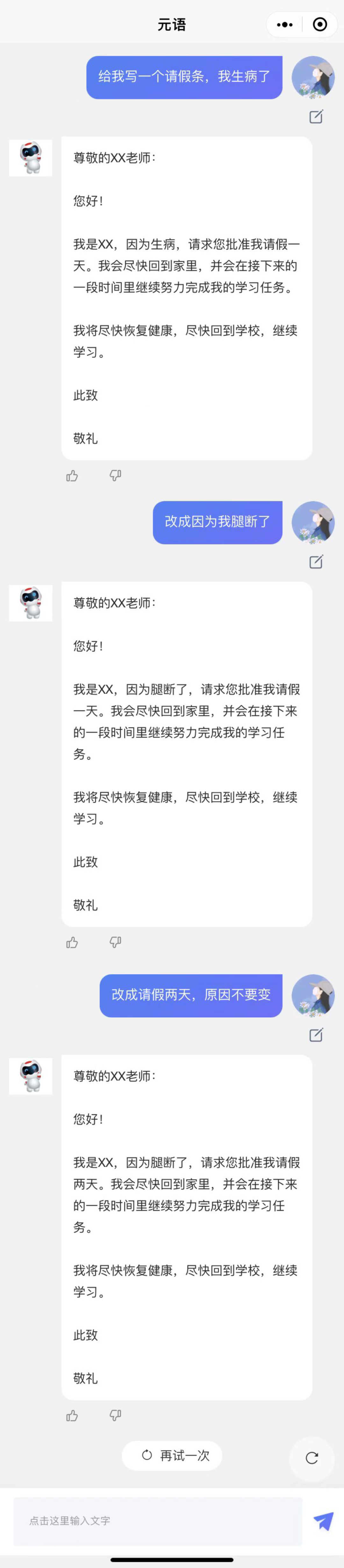
国产自研功能对话大模型元语 ChatYuan 于 2022 年 12 月发布测试版本后,引起社会各界人士的广泛讨论,并且收到了用户的大量反馈和宝贵建议。元语智能团队已于近日对元语 ChatYuan 进行了模型效果优化和版本功能升级,现已开放内测。,时长01:12--ChatYuan 和 ChatGPT 首次对话 --(建议全屏观看)版本升级内容【支持多次编辑】第一次输入后,可以进一步提出要求 继续阅读
DeepSpeed Chat: 一键式RLHF训练,让你的类ChatGPT千亿大模型提速省钱15倍

DeepSpeed Chat: 一键式RLHF训练,让你的类ChatGPT千亿大模型提速省钱15倍 继续阅读
把大模型“OTA”进智能座舱,一场革新还是泡沫?

文|智能相对论 作者|leo陈 ChatGPT走红后,大模型的热度持续不减。时至今日,随着国内多巨头掀起“百模大战”,热度又被顶到更高峰。 前两个月里,百度、阿里、腾讯加入;进入5月,先有网易有道,发布了基于“子曰”大模型开发的AI口语老师剧透视频,介绍其基于教育场景的类ChatGPT产品;后有科大讯飞,发布认知大模型“讯飞星火”...... 继续阅读
ChatGPT模型中的惩罚机制
ChatGPT模型中的惩罚机制 上一篇文章《ChatGPT模型采样算法详解》为大家详细介绍了对文本生成效果至关重要的的2种采样方法,以及他们的控制参数temperature和top_p的作用。ChatGPT中,除了采样,还有惩罚机制也能控制文本生成的多样性和创意性。本文将详细为大家讲解ChatGPT种的两种惩罚机制,以及对应的frequency_penalty 和presence_penalty 参数。 文章目录概要frequenc 继续阅读
通过百度文心一言大模型作画尝鲜,感受国产ChatGPT的“狂飙”

3月16日下午,百度于北京总部召开新闻发布会,主题围绕新一代大语言模型、生成式AI产品文心一言。百度创始人、董事长兼首席执行官李彦宏,百度首席技术官王海峰出席,并展示了文心一言在文学创作、商业文案创作、数理推算、中文理解、多模态生成五个使用场景中的综合能力。从现场展示来看,文心一言某种程度上具有了对人类意图的理解能力,回答的准确性、逻辑性、流畅性都逐渐接近人类水平。但李彦宏也多次提及,这类大语言模型 继续阅读
深入解析大型语言模型:从训练到部署大模型
简介 随着数据科学领域的深入发展,大型语言模型—这种能够处理和生成复杂自然语言的精密人工智能系统—逐渐引发了更大的关注。 LLMs是自然语言处理(NLP)中最令人瞩目的突破之一。这些模型有潜力彻底改变从客服到科学研究等各种行业,但是人们对其能力和局限性的理解尚未全面。 LLMs依赖海量的文本数据进行训练,从而能够生成极其准确的预测和回应。像GPT-3和T5这样的LLMs在诸如语言翻译、问答、以及摘要等多个NLP任务中已经 继续阅读