要测试sql loader 以及快速产生大量测试数据生成大量测试数据思路。一,用plsql developer 生成csv 文件二,用>>输出重定向,追加到一个cvs 文件里。三,再用sql loader 快速载入。在plsql developer 执行Sql代码 SELECTobject_id,object_nameFROMdba_objects;SELECT object_id,object_name FROM dba_ob 继续阅读
Search Results for: 大数据量
查询到最新的12条
大流量采集站进阶课程已发布

2022.9.10日更新大流量进阶课程。 录制这套课程之前就已经做好了录制计划,因为网站涉及的东西非常多,所以咱们这套大流量采集站采用阶段性录制。 第一套课程重点讲的是稍微基础东西,比如做站前的准备工作,网站布局,关键词设置,关键词挖掘整理,网站数据填充等。 进阶课程主要是讲,新上线的站点如何快速起站,网站优化逻辑,以及变现优化方面的问题。 比如常见的网站上线没有蜘蛛抓取,网站页面优化逻辑,以及如何大批量为网站制作高质量页面,以及网 继续阅读
Python处理大数据折线图
折线图是一种常见的数据可视化方式,可以直观地展示数据随时间或其他变量的变化趋势。在处理大量数据时,Python提供了丰富的库和技术,可以高效地生成折线图。 一、安装必要的库 在生成折线图之前,我们首先需要安装必要的库。Python中处理数据和绘制图表最常用的库是matplotlib和pandas。 pip install matplotlib pip install pandas 二、准备数据 在处理大量数据时,通常我们会从外部文件或数据库中读取数据。以CS 继续阅读
经济金融数据分析及其Python应用(数量经济学系列丛书)
经济金融数据分析及其Python应用(数量经济学系列丛书)这本书,是由清华大学出版社在2019-01-01月出版的,本书著作者是 朱顺泉 著,此次本版是第1次印刷发行, 国际标准书号(ISBN):9787302497431,品牌为清华大学出版社(TSINGHUA UNIVERSITY PRESS), 这本书的包装是16平装,所用纸张为胶版纸,全书共有232页字数34万6000字, 是一本非常不错的Python编程书籍。此书内容摘要 Python是一款非常优秀的数据分析、图 继续阅读
大数据和人工智能概念全面解析
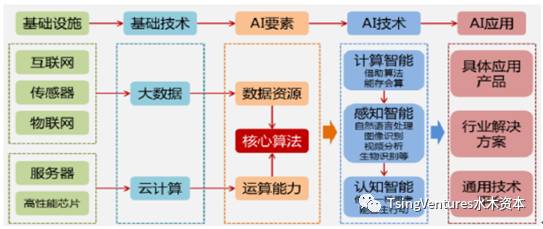
一、大数据和人工智能 大数据是伴随着信息数据爆炸式增长和网络计算技术迅速发展而兴起的一个新型概念。根据麦肯锡全球研究所的定义,大数据是一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型和价值密度低四大特征。大数据能够帮助各行各业的企业从原本毫无价值的海量数据中挖掘出用户的需求,使数据能够从量变到质变,真正产生价值。随着大数据的发展 继续阅读
网站怎么才有alexa排名(如何统计网站的流量和Alexa排名数据)

很多站长都会提出这样的问题:是不是网站的流量越大,alexa排名就越高? 一般情况下说是这样的,但相同流量的网站排名差别却是非常大的,出现这样的问题跟两种统计的数据获取方式有关:流量统计一般是采用嵌入式统计,这样通过在页面中放入统计代码来获取统计数据,准确性相当高,但由于一般网站统计大家都不公开,所以无法进行相应的比较。 Alexa综合排名:即特定的一个网站在所有网站中的名次。Alexa每三个月公布一次新的网站综合排名。此排名 继续阅读
java调sqlloader,Java调用SqlLoader将大文本数据导入数据库
项目描述将一千万条数据,大约500M的文本文档的数据导入到数据库分析:通过Java的IO流解析txt文本文档,拼接动态sql实现insert入库,可以实现,缺点如下第一:IO流解析大文本文件对机器性能要求较高,测试大约消耗2G左右的内存第二:拼接sql语句insert一千万条数据大约需要2小时时间,长时间insert会锁表,如果是核心业务表,例如订单表,会造成大量用户无法 继续阅读
分布式计算之数据质量漫谈

一 概述 1 数据质量问题无处不在 基本上每个用数据的同学,都遇到过以下类似的问题。 表没有按时产出,影响下游,严重的甚至可能影响线上效果。 打点缺失,看了报表才发现数据对不上。 数据统计出来,uv大于pv,很尴尬。 数据产出暴增,本来1000万的数据变成了3000万。 字段里面的枚举值和注释里面 继续阅读
运营商大数据是什么?

1.以联通大数据为代表的运营商大数据,可以通过网站,网页(同行的网站,自己的竞价推广网站,网页均可)手机APP,400电话/固话,可以通过建模进行用户画像建立和分析,分析使用在手机和使用手机流量下对网站,网页,手机APP进行访问,产生了上网行为,和浏览行为的用户数据信息。和在手机下拨打了400电话/固话产生了通话行 继续阅读
大数据运营

大数据运用与营销 大数据 大数据在互联网诞生时就已出现,但没有人去关注使用互联网后留下使用后再互联网中存储的信息,一个用户的浏览使用信息可能不多,但几千几万几亿人乃至十亿百亿千亿的人使用互联网使用后的信息就是巨大的信息,这么巨量的信息在20世纪被称之为大数据,而如果将这些大数据用特定的程序进行整理,分析,分类就会出现很多可以了解的分类,比如用户的地区,年龄, 继续阅读
Spark开源项目-大数据处理的新星
Spark是一款开源的大数据分布式计算框架,它能够高效地处理海量数据,并且具有快速、强大且易于使用的特点。本文将从以下几个方面阐述Spark的优点、特点及其相关使用技巧。 一、Spark的概述与优点 Spark的出现解决了Hadoop无法在实时和迭代计算方面的不足。相比于Hadoop,Spark有以下几个优点: 速度更快。Spark采用内存计算方式,执行速度比Hadoop快100倍。 支持实时计算。Spark的设计目标是在内存中对数据进行实时处理,它能够以秒 继续阅读
BloombergGPT: 首个金融垂直领域大语言模型

BloombergGPT: 首个金融垂直领域大语言模型 Bloomberg 刚刚发布了一篇研究论文,详细介绍了他们最新的突破性技术 BloombergGPT。BloombergGPT是一个大型生成式人工智能模型,专门使用大量金融数据进行了训练,以支持金融行业自然语言处理 (NLP) 任务。 随着ChatGPT的发布,人工智能取得了长足进步。但金融领域相当复杂且独特的领域,它往往受着严厉的合规监管,对事实正确 继续阅读