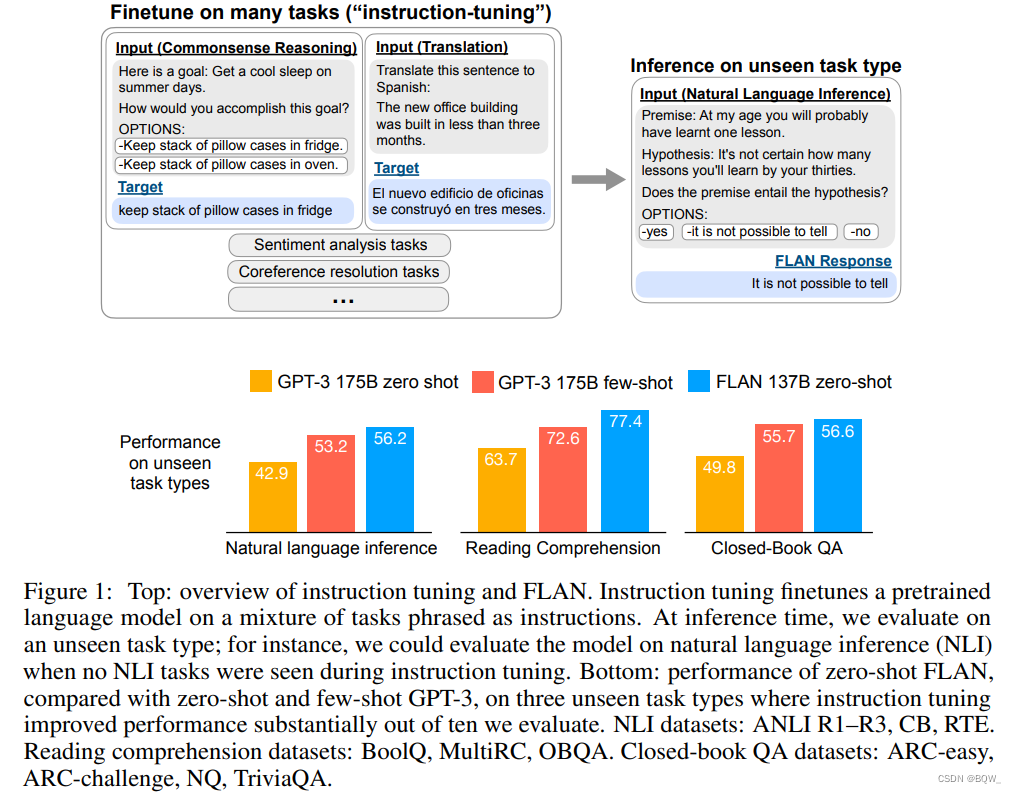
FLAN: 微调语言模型是Zero-Shot学习器 《Finetuned Language Models are Zero-shot Learners》 论文地址:https://arxiv.org/abs/2109.01652 一、简介 大语言模型(例如GPT-3\text{GPT-3}GPT-3)已经展现出了非常好的few-shot learning\text{few-shot learning}few-shot learning的能力。然而 继续阅读
【自然语言处理】【ChatGPT系列】FLAN:微调语言模型是Zero-Shot学习器