更新:$str = '这是中文';// 注意 php不支持\u写法preg_match('/[\x{4e00}-\x{9fa5}]+/u', $str, $matchs);print_r($matchs);==================以下忘了是写的什么玩意儿==================最近学习正则,在百度搜php常用正则,80%都是采集的。其中开头都介绍了个匹配中文的方法,试了一下,不能用(汗!!!)。这个方法也是搜集来的,可以正确匹 继续阅读
Search Results for: 正则
查询到最新的12条
【新星计划回顾】第七篇学习-正则表达式-邮箱解释
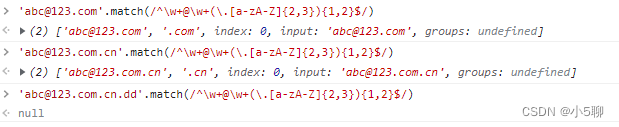
目录 1、邮箱表达式2、表达式解释3、不符合规则情况4、正则表达式知识点4.1、基本符号4.2、转义字符4.3、限定符4.4、分组和选择 1、邮箱表达式 /^\w+@\w+(\.[a-zA-Z]{2,3}){1,2}$/'test'.match(/^\w+@\w+(\.[a-zA-Z]{2,3}){1,2}$/) 2、表达式解释 1)符号^ 表示以什么开头 2) 继续阅读
Python 中的正则表达式
正则表达式这个术语通常被简称为正则表达式。正则表达式是定义搜索模式的字符序列,主要用于在搜索引擎和文本处理器中执行查找和替换操作。 Python 通过作为标准库的一部分捆绑的re模块提供正则表达式功能。 原始字符串 Python re 模块中的不同函数使用原始字符串作为参数。当前缀为“R”或“R”时,普通的字符串成为原始字符串。 Example: Raw String >>> rawstr = r'Hello! How are you?' 继续阅读
CentOS中的正则表达式
支持linux正则表达式的工具有:grep:实现查找,sed,awk:都是流式编辑器,可以实现查找和替换,并且把替换的文本输出到屏幕上。 grep工具 grep [-cinvABC] 'word' -c:打印符合要求的行数 -i:忽略大小写 -n:输出符合要求的行及行号。 -v:打印不符合要求的行 -A: 后面跟一个数字(有无空格都可以),-A2表示打印符合要求的行以及下面两行 -B:后面跟数字, 继续阅读
抓头 – 嵌套div的正则提取
很傻很天真的以为用正则可以轻易提取出div里的层层嵌套div,结果囧得厉害。div的开头通常都带有class或id,唯一,且容易辨认,但div的结尾,清一色的“/div”,真会搞死人。网络上流传的提取div版本貌似都不太可行。在一坨里提取一堆只是第一步,第二部还得把提取到的内容xml数组化。 其实呢,我也有想过一开始就对所有内容xml数组化,不过,信不信由你,从最开始那层到我要提取的那些内容少说也有15层,而且如果那些网页设计者好心加一层或减一层,我又得慢慢摸到底哪里出问题了。所以, 继续阅读
【牛客刷题专栏】0x20:JZ19 正则表达式匹配(C语言编程题)
前言 个人推荐在牛客网刷题(点击可以跳转),它登陆后会保存刷题记录进度,重新登录时写过的题目代码不会丢失。个人刷题练习系列专栏:个人CSDN牛客刷题专栏。 题目来自:牛客/题库 / 在线编程 / 剑指offer: 目录前言问题描述:举例:解法思路:代码结果:结束语 问题描述: 描述 请实现一个函数用来匹配包括’.‘和’‘的正则表达式。 继续阅读
正则表达式(全)

目录 单括号,双括号,中括号,双中括号,大括号 单括号: 双小括号: 中括号: 双中括号: 大括号: Echo的用法 正则表达式定义: 正则表达式组成 普通字符: 元字符 扩展元字符 使用grep匹配正则 示例: 总结:元字符 正则工具 Cut工具 Sort工具 Uniq工具 Tr工具 Sed工具& 继续阅读
python 正则匹配括号内的内容及删除括号内内容
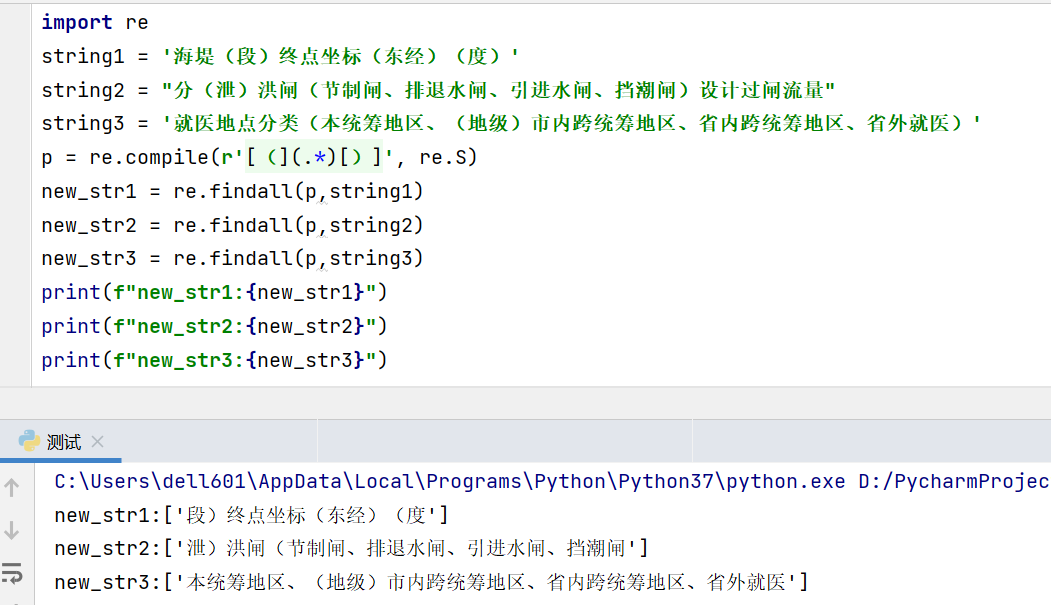
环境: python3.7 解析: ''' 1.正则匹配串前加了r就是为了使得里面的特殊符号不用写反斜杠了。2.[ ]具有去特殊符号的作用,也就是说[(]里的(只是平凡的括号3.正则匹配串里的()是为了提取整个正则串中符合括号里的正则的内容4. .是为了表示除了换行符的任一字符。*克林闭包,出现0次或无限次。5. 加了?是最小匹配,不加是贪婪匹配。6. re.S是为了让.表示除了换行符的任一字符。 '& 继续阅读
python正则匹配单引号和双引号里的内容
""" 正则练习测试 """ import re, os, json, pydash # 示例1 xx = '{"abc", "cdd"}' pattern = re.compile(r'\"(.*?)\"') result = pattern.findall(xx) print(result) # ====& 继续阅读
Python 正则匹配两个指定字符之间的字符方法
正则表达式太难了!!! 包含起始特定字符 result = re.findall(r'A.*C', s) print(result)>>['ABXC'] 不包含起始特定字符 s = "ABXCXXD" result = re.findall(r'A(.*)C', s)result = re.findall(r'(?<= 继续阅读
【深度学习】5-4 与学习相关的技巧 - 正则化解决过拟合(权值衰减,Dropout)

机器学习的问题中,过拟合是一个很常见的问题。过拟合指的是只能拟合训练数据,但不能很好地拟合不包含在训练数据中的其他数据的状态。机器学习的目标是提高泛化能力,即便是没有包含在训练数据里的未观测数据也希望模型可以进行正确的识别。 发生过拟合的原因,主要有以下两个: 模型拥有大量参数、表现力强。训练数据少。 那么如何来抑制过拟合 正则化是有效方法之一,它不仅可以有效降低高方差,还有利于降低偏差。何为 继续阅读
有一点用——python正则匹配
1. ^ 匹配以当前开始,$ 匹配以当前结束 2. *匹配0次或多次,+匹配1次或多次,?匹配0次或一次,.匹配除换行符意外的所有字符 3. [a-z]匹配a-z, [ ^a-z]不匹配a-z 4. (?=),限定规则的匹配,'Windows(?=95|98|NT|2000)能匹配’Windows2000中的Windows,不能匹配’Windows300中的’W 继续阅读