我们做SEO的时候,为了提高收录量,肯定要进行各大搜索引擎的链接提交。今天介绍的就是一个抓取全站链接的链接抓取工具。如何抓取全站链接,该功能用处是什么等等。 继续阅读
Search Results for: 网站链接抓取
查询到最新的12条
原创如何抓取微信小程序的素材?
最近见到某个写电脑软件的技术,写了一款抓取微信小程序的素材软件,然后推广后,由于价格比他人便宜,遭受到了此类型的人恐吓威胁,然而,其实这个技术一点都不难,原理也都很简单,无非就是一个.... 继续阅读
如何使用 ChatGPT 完全自动化网页抓取
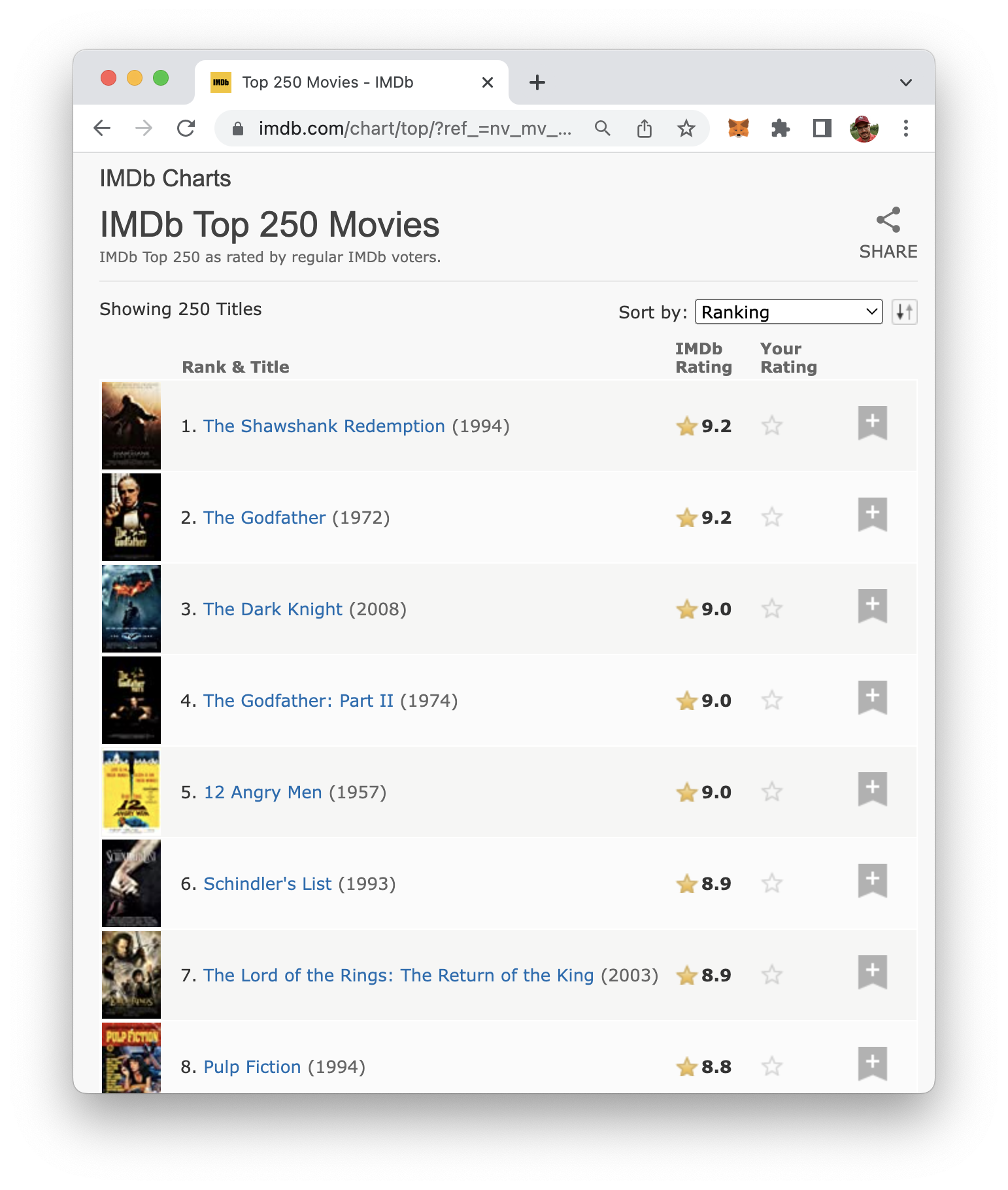
Web 抓取是使用脚本从网站自动提取数据的过程。ChatGPT 能够为您生成网络抓取脚本代码。让我们看看这是如何工作的……IMDb 是一个提供有关电影、电视节目和其他娱乐形式的信息的网站,包括评分最高的电影图表,该网站https://www.imdb.com/chart/top/?ref_=nv_mv_250显示 IMDb 上评分最高的 250 部电影的列表,包括它们的标题、演员、导演、和 IMDb 评级:假设我们想使用网络抓取通过 继续阅读
使用Python抓取模板之家的CSS模板
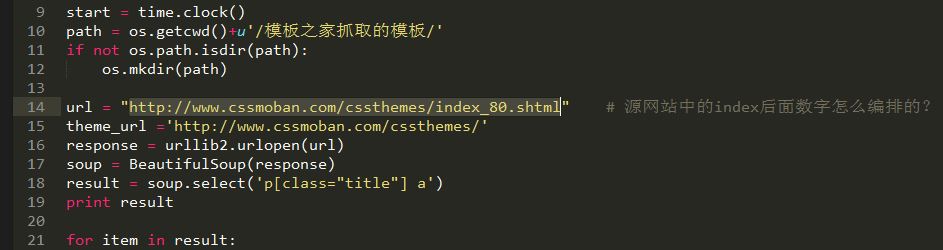
Python版本是2.7.9,在win8上测试成功,就是抓取有点慢,本来想用多线程的,有事就罢了。模板之家的网站上的url参数与页数不匹配,懒得去做分析了,就自己改代码中的url吧。大神勿喷! 复制代码代码如下: #!/usr/bin/env python # -*- coding: utf-8 -*- # by ustcwq # 2015-03-15 import urllib,urllib2,os,time fr 继续阅读
Python抓取PDF关键词后面的几个字的实现方法
Python是一种十分流行的编程语言,其强大的文本解析能力以及xml、html等标记语言的解析能力已得到广泛应用。在Python中,抓取PDF中关键词后面的几个字并不是一件困难的事情,下面我们就一步一步来看这个过程。 一、使用PyPDF2读取PDF文件 PyPDF2是Python中用于处理PDF格式文件的第三方库,它能够读取、写入、分析和修改PDF文件。我们可以使用PyPDF2读取需要处理的PDF文件。假设我们要抓取的PDF文件名为“example.pdf”, 继续阅读
火车头采集器采集多页内容的抓取教程
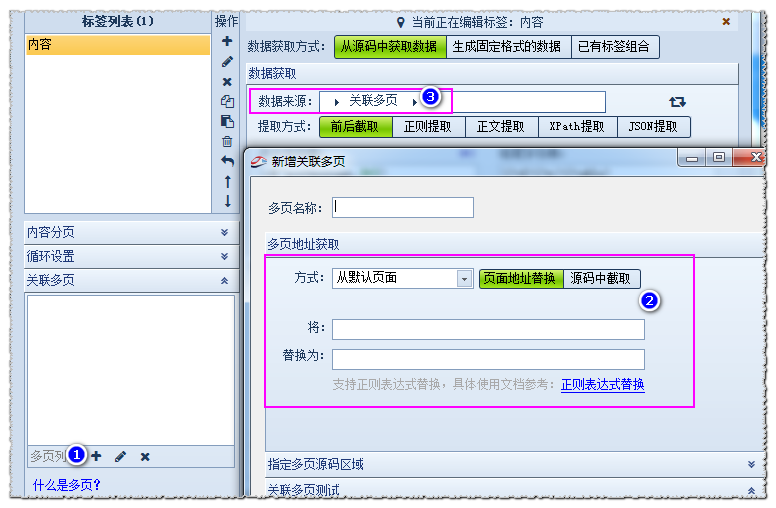
我们以内容页网址http://kimi201406.1688.com/page/creditdetail.htm为例,来获取它的公司介绍和联系方式页面的联系方式信息。 公司介绍在网址http://kimi201406.1688.com/page/creditdetail.htm里获取,而联系方式信息在网址http://kimi201406.1688.com/page/contactinfo.htm里获取。所以我们需要借助多页功能来实现。前者叫默认页地址,后者叫做多页地 继续阅读
用pywinauto抓取微信公众号
本文内容在于讨论用pywinauto 如何获取微信控件的问题,欢迎各位大牛指点迷津。 1 pywinauto pywinauto是个在PC端可以使用的自动化测试框架,感谢作者提供这么好的框架。 其中个人认为非常重要的一个函数就是print_control_identifiers(), 用来打印窗口的控件列表,打印【记事本】可以看到很多控件,知道了控件pid我们就可以采用pywinauto的属性方式操作它,真 继续阅读
老域名有什么好处?(高权重域名绑定新站)
现在很多企业都喜欢用老域名做新网站,这是什么原因呢?选择老域名有什么好处?又是如何选择老域名才不会出错呢?一起来看看吧! 选对老域名建新站真的非常多呢~ 网站收录更快 老域名在搜索引擎中存在时间较长,已经被搜索引擎记录,重新启用被收录所花费的时间比新站要少得多。 注册时间比较久, 比较老的域名,就算文章不是每天更新,一旦继续更新文章还是会被很快录入,快照的更新也会比较快! 考察期过的好处就是,百度抓取频率更高,百度快照释放更快,及时你修 继续阅读
Python爬虫 从小白到高手 Urllib
Urllib 1.什么是互联网爬虫? 如果我们把互联网比作一张大的蜘蛛网,那一台计算机上的数据便是蜘蛛网上的一个猎物,而爬虫程序就是一只小蜘蛛,沿着蜘蛛网抓取自己想要的数据 解释1:通过一个程序,根据Url(http://www.taobao.com)进行爬取网页,获取有用信息 解释2:使用程序模拟浏览器,去向服务器发送请求,获取响应信息 继续阅读
Python网络爬虫权威指南 第2版
推荐编程书籍:Python网络爬虫权威指南 第2版,由人民邮电出版社2019-04-01月出版发行,本书编译以及作者信息 为:瑞安·米切尔(Ryan Mitchell) 著,神烦小宝 译,此次为第2次发行, 国际标准书号为:9787115509260,品牌为人民邮电出版社, 这本书采用平装开本为16开,纸张采为胶版纸,全书共有241页字数万字,是本Python 编程相关非常不错的书。此书内容摘要 本书采用简洁强大的Python 语言,介绍了网页抓取,并为抓取新式网络 继续阅读
疫情前后的嫖客大数据对比,惊呆,,,

今日有瓜,传某明星嫖娼被抓;这样一个古老的话题,国人往往避而不谈,但终究要面对。今天分享几组数据,还请洁身自好。 近5年嫖娼价格上涨1倍,地点从酒店向小区甚至室外转移。 我们抓取了东部沿海某发达省份2016年-2021年10月13万条相关的行政处罚数据,对几个指标做了汇总: 时间 嫖娼案件最多发生在20点到22点,40%的案件发生在这个时间段。下午14点到16点是小高峰 继续阅读
每周AI大事件|国产大模型热战开启、AI监管规定来了、马斯克入局AIGC大战
Part1动态 「国内要闻」 其中提到利用AI生成内容应当真实准确,采取措施防止生成虚假信息;提供者应当对生成式人工智能产品的预训练数据、优化训练数据来源的合法性负责等。 知乎发布"知海图 AI" 中文大模 知乎和面壁科技合作的中文大模型“知海图AI”正式开启内测。同时,基于人工智能的“热榜摘要”开启内测,对知乎热榜上的问题回答进行抓取、整理和聚合,并把回答梗概展现给用户。 阿里所有产品将接入大模型全面升级 阿里 继续阅读