目录 导语: jdbc流式查询: mybatis流式查询: 导语: 有些时候我们所需要查询的数据量比较大,但是jvm内存又是有限制的,数据量过大会导致内存溢出。这个时候就可以使用流式查询,数据一条条的返回,处理完一条在拿下一条数据,这样每次在内存里面的数据其实很小,不会导致内存溢出。 本文里面会讲到jdbc的流式查询和mybatis的流式查询。 j 继续阅读
Search Results for: 大数值使用BitSet存储导致的内存溢出
查询到最新的12条
bitset的使用示例

std::bitset是STL的一个模板类,它的参数是整形的数值,使用位的方式和数组区别不大,相当于只能存一个位的数组。下面看一个例子bitset<20> b1(5); cout<<"the set bits in bitset<5> b1(5) is:" << b1 <<endl; 结果是 the set bits in bitset<5> b1(5) i 继续阅读
存储和服务器的三大件②
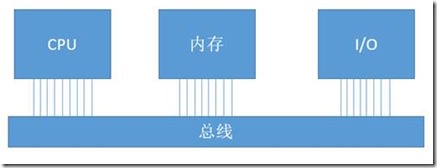
存储和服务器的三大件 从底层原理实现角度来看,存储和服务器的物理硬件本质都是三大件:CPU、内存和I/O的组合运用。 二、服务器对于三大件的组合运用 从电脑的角度看,服务器也是电脑,只是比普通的电脑更复杂更先进而已。服务器的诞生,是为了处理企业级的应用,使工作协同性变得更高。所以服务器和家用的电脑相比,最重要的一点就是要稳定、安全、少出错。服务器上面运行的应用程序、数据库对于企业来说是非常重要的 继续阅读
BitSet的应用

1.BitSet介绍 BitSet是用于存储二进制位和对二进制进行操作的Java数据结构,BitSet从jdk1.0开始就有了。它存储的是二进制位在BitSet中状态,根据对这些状态的判断,可以有很多应用。以前对数据的操作都是先把数据都是存储在内存中间的,现在可以通过设置BitSet的相应位达到存储数据信息的目的,极大的节省了内存空间。 2.BitSet应用 BitSet可以做的事情主要分为以下几类: & 继续阅读
存储和服务器的三大件(1)
上周末参加了冬瓜哥的存储和服务器底层原理架构培训课程,又重拾了存储和服务器的部分知识。个人言论不代表冬瓜哥及所在公司观点。 从底层原理实现角度来看,存储和服务器的物理硬件本质都是三大件:CPU、内存和I/O的组合运用。 一、三大件的主流趋势 在CPU芯片方面,CPU芯片从工艺设计到流程制造均是高精尖的科技硬实力体现,而我国在这一方面一直在投入重金进行技术研发、生态圈建设和技术追赶。现目前,我国在AI芯片的工艺 继续阅读
构造函数不能声明为虚函数的原因及分析
1. 从存储空间角度,虚函数对应一个指向vtable虚函数表的指针,这大家都知道,可是这个指向vtable的指针其实是存储在对象的内存空间的。问题出来了,如果构造函数是虚的,就需要通过 vtable来调用,可是对象还没有实例化,也就是内存空间还没有,怎么找vtable呢?所以构造函数不能是虚函数。 2. 从使用角度,虚函数主要用于在信息不全的情况下,能使重载的函数得到对应的调用。构造函数本身就是要初始化实例,那使用虚函数也没有实际意义呀。所以构造函数没有必要是虚函数。 继续阅读
c++ 读文件_python中文件的使用

在程序运行时,数据时保存在内存的变量里。内存中的数据在程序结束后或关机后就会消失。如果想要在下次开机运行程序时还想使用同样的数据,就需要把数据存储在不易失的存储介质中,比如硬盘、u盘。不易失存储介质上的数据保存在以路径命名的文件中。通过读/写,程序就可以在运行时保存数据。这次,我们一起学习下python中有关文件的创建、读写以及关闭等操作1. 文件简单的来说, 文件时由字节组成的信息,在逻辑上具有完 继续阅读
Spark开源项目-大数据处理的新星
Spark是一款开源的大数据分布式计算框架,它能够高效地处理海量数据,并且具有快速、强大且易于使用的特点。本文将从以下几个方面阐述Spark的优点、特点及其相关使用技巧。 一、Spark的概述与优点 Spark的出现解决了Hadoop无法在实时和迭代计算方面的不足。相比于Hadoop,Spark有以下几个优点: 速度更快。Spark采用内存计算方式,执行速度比Hadoop快100倍。 支持实时计算。Spark的设计目标是在内存中对数据进行实时处理,它能够以秒 继续阅读
内存不够用,那你的内存去哪了?

一、前言 近几年开发了一些大型的应用程序,在程序性能调优或者解决一些疑难杂症问题的过程中,遇到最多的还是与内存相关的一些问题。例如glibc内存分配器ptmalloc,google的内存分配器tcmalloc都存在“内存泄漏”,即内存不归还操作系统的问题;ptmalloc内存分配性能低下的问题;随着系统长时间运行,buffer/cache被某些应用大量使用,几乎完整占用系统内存&#x 继续阅读
多快好省地使用pandas分析大型数据集

1. 简介 pandas虽然是个非常流行的数据分析利器,但很多朋友在使用pandas处理较大规模的数据集的时候经常会反映pandas运算“慢”,且内存开销“大”。 特别是很多学生党在使用自己性能一般的笔记本尝试处理大型数据集时,往往会被捉襟见肘的算力所劝退。但其实只要掌握一定的pandas使用技巧,配置一般的机器也有能力hold住大型数据集的分析。 图1 本文就将以真实数据集和运存16G 继续阅读
bitset的使用

bitset 类简化了位集的处理,有些程序要使用二进制位的有序集来保存一组项或条件的标志位,可以考虑使用bitset。 需要的文件: #include <bitset> Using std::bitset l bitset 对象的定义和初始化 定义bitset时,要明确bitset有多少位: bitset<32> bitvec 继续阅读
Linux 中 ss 命令的使用实例
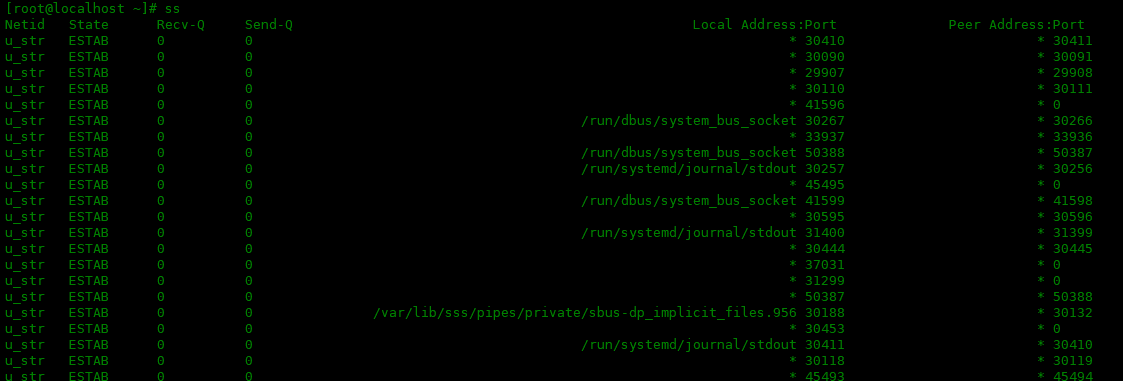
如果需要访问系统的socket相关信息,大多数人想到的第一个工具就是netstat。但是如果你想获得更多信息,你可以使用 ss 命令来达到这个目的。 显示所有已建立连接的套接字 ss命令不带任何选项,用来显示已建立连接的所有套接字的列表。 [root@localhost ~]# ss 抑制输出中的标题行 如果要取消命令输出中的标题行,可以使用-H选项。 [root@localhost ~]# ss -H 继续阅读