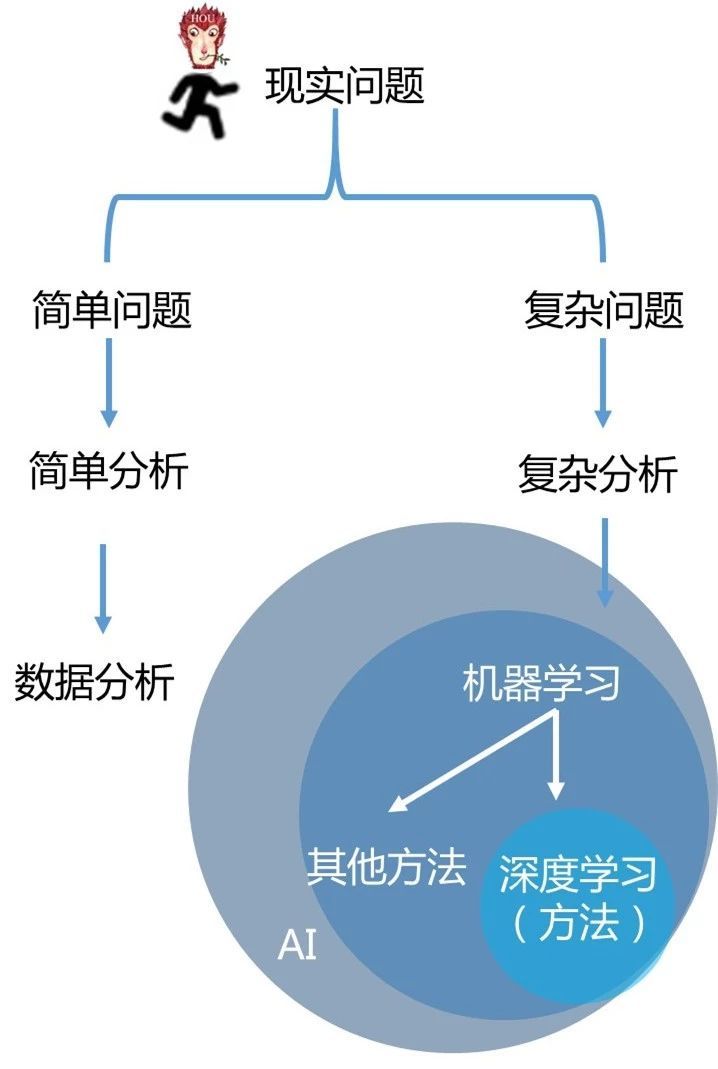
最近出现很多ChatGPT相关论文,但基本都是讨论其使用场景和伦理问题,至于其原理,ChatGPT在其主页上介绍,它使用来自人类反馈的强化学习训练模型,方法与InstructGPT相同,只在数据收集上有细微的差别。 那么,InstructGPT和ChatGPT为什么使用强化学习呢?先看个示例: 先不论答案是否正确,回答依赖之前的对话, 继续阅读
ChatGPT为什么使用强化学习