
文章目录
- 零、Rust 好用的资源
- 一、概述
- 1.1 安全性
- 1.1.1 垂悬指针
- 1.1.2 数据竞争
- 1.1.3 迭代器失效
- 1.2 性能
- 1.3 vscode 設置
- 二、基础语法
- 2.1 循环
- 2.2 引用
- 2.3 生命周期
- 2.4 泛型
- 2.5 实战grep项目
- 2.6 数组
- 2.6.1 数组和切片
- 2.6.2 动态数组
- 2.6.3 初始化
- 2.7 包含第三方库
- 2.8 命令行参数
- 2.9 读文件
- 2.9.1 手动循环读文件
- 2.9.2 迭代器读文件
- 2.9.3 配合命令行参数读文件
- 2.10 读 stdin
- 三、复合数据结构
- 3.1 普通函数
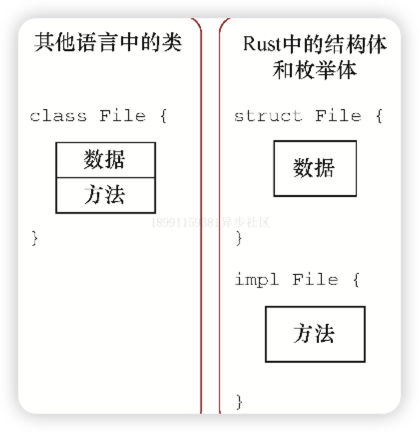
- 3.2 struct
- 3.3 用 impl 为 struct 添加方法
- 3.4 返回错误信息
- 3.4.1 unsafe 读写全局变量
- 3.4.2 Result<T, E>
- 3.5 enum
- 3.6 trait
- 3.6.1 创建名为 read 的 trait
- 3.6.2 为类型实现 std::fmt::Display
- 四、生命周期-所有权-借用
- 4.5 所有权
- 4.5.2 引用
- 4.5.3 Copy 和 Clone
- 五、深入理解数据
- 5.1 位模式和类型
- 5.2 整数的生存范围
- 5.2.1 字节序
- 5.4 浮点数
- 5.4.1 观察 f32 的内部
- 5.4.2 分离出符号位
- 5.4.3 分离出指数
- 5.4.4 分离出尾数
- 5.4.5 剖析一个浮点数
- 5.5 定点数格式
- 5.6 从随机字节中生成随机概率
- 5.7 实现一个 CPU 模拟器
- 5.7.1 CPU 原型1:加法器
- 5.7.3 CPU 原型2:累加器
- 5.7.3.1 使 CPU 支持内存访问
- 5.7.3.2 从内存中读取操作码
- 5.7.3.3 处理整数溢出
- 5.7.3.4 完整代码
- 5.7.4 CPU 原型3:调用函数
- 5.7.4.1 给 CPU 扩展出 支持栈 的能力
- 5.7.4.2 定义一个函数并把它加载到内存中
- 5.7.4.3 实现 CALL 和 RETURN 操作码
- 5.7.4.4 完整代码
- 5.7.5 CPU4:添加额外功能
- 六、内存
- 6.2 指针
- 6.2.1 原始指针
- 6.2.2 Rust 指针的生态系统
- 6.2.3 智能指针块构建
- 6.3 为程序提供存储数据的内存
- 6.3.1 栈
- 6.3.2 堆
- 6.3.4 分析【堆】分配动态内存的速度
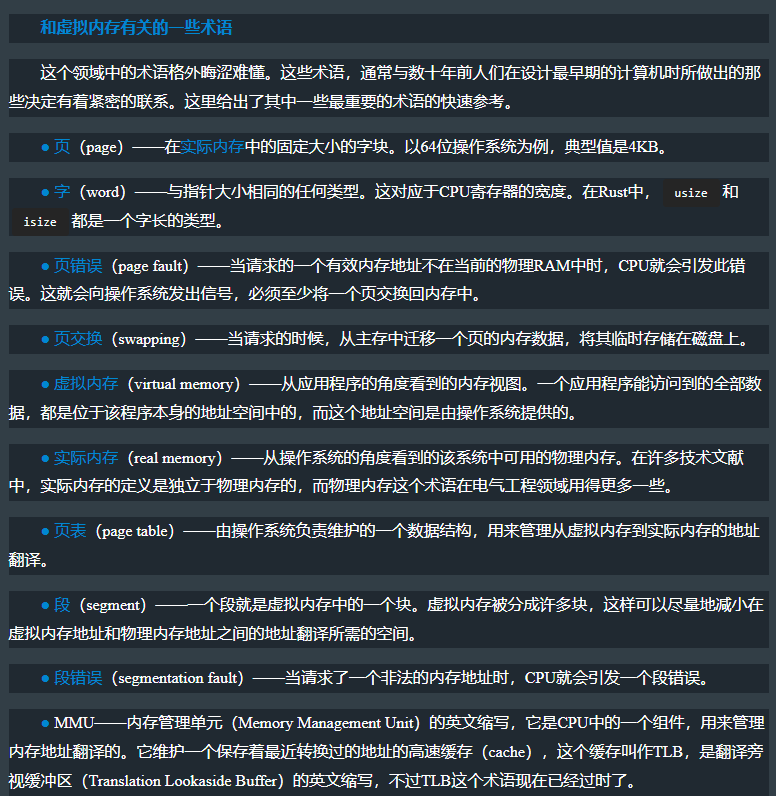
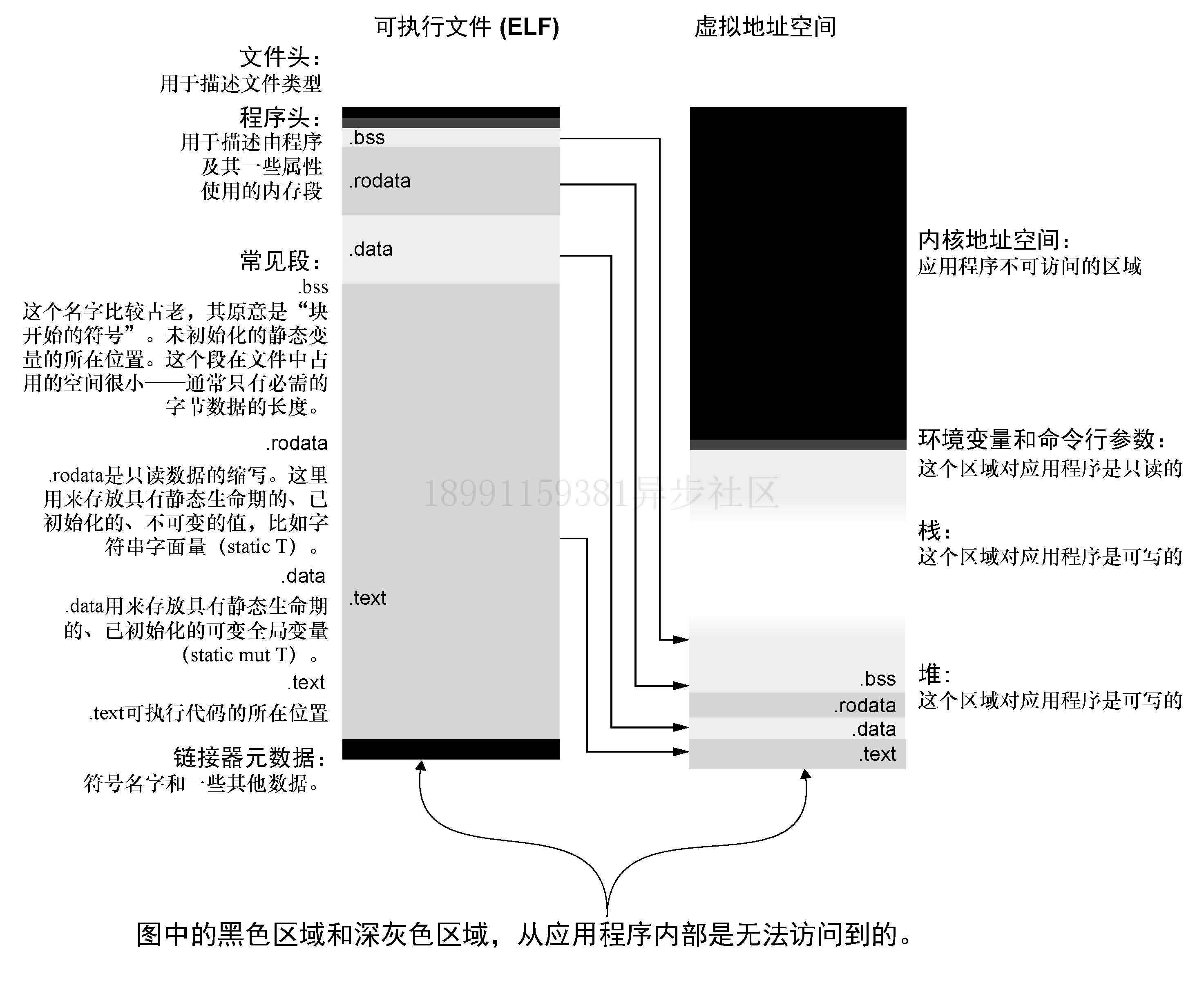
- 6.4 虚拟内存
- 6.4.2 第一步:让一个进程扫描它自己的内存
- 6.4.3 把虚拟地址 翻译为 物理地址
- 6.4.4 第二步:通过操作系统来扫描地址空间
- 6.4.5 第三步:读取和写入进程内存中的字节数据
- 七、文件和存储
- 7.2 serde 与 bincode 序列化
- 7.3 实现一个 hexdump
- 7.4 操作文件
- 7.4.1 打开文件
- 7.4.2 用 std::fs::Path 交互
- 7.5 基于 append 模式实现 kv数据库
- 7.5.1 kv 模型
- 7.5.2 命令行接口
- 7.6 前端代码
- 7.6.1 用条件编译定制要编译的内容
- 7.7 核心:LIBACTIONKV 包
- 7.7.1 初始化 ActionKV 结构体
- 7.7.2 处理单条记录
- 7.7.3 以确定的字节顺序将多字节二进制数据写入磁盘
- 7.7.4 用校验和验证 I/O 错误
- 7.7.8 创建 HashMap 和写入
- 7.7.9 查询 HashMap
- 7.7.10 HashMap 和 BTreeMap 对比
- 7.7.11 添加数据库索引
零、Rust 好用的资源
- 刷题与学习
- rustlings: https://github.com/rust-lang/rustlings
- https://leetcode-cn.com/
- https://leetcode.com/
- https://codewars.com/
- https://exercism.org/
- Rust 书籍和在线资源 2021/10/20 20:26:31
- 一站式中文资料汇总 https://rustwiki.org
- 作弊抄 https://cheats.rs/ 中文版 http://cheats.rs.kingfree.moe/
- 手册 https://doc.rust-lang.org/stable/reference/
- 手册中文版 https://minstrel1977.gitee.io/rust-reference/
- The book 或称 trpl https://doc.rust-lang.org/stable/book/
- The book 中文版 https://kaisery.github.io/trpl-zh-cn/
- The Cargo Book https://doc.rust-lang.org/cargo/index.html
- Cargo Book 中文版 https://cargo.budshome.com/
- 通过例子学 https://doc.rust-lang.org/stable/rust-by-example/
- 通过例子学(中文) https://rustwiki.org/zh-CN//rust-by-example/hello.html
- 标准库的文档 https://doc.rust-lang.org/std/index.html
- 标准库文档中文版 https://rust.ffactory.org/std/index.html
- Rust 中文网 https://rust.ffactory.org
- CookBook https://rust-lang-nursery.github.io/rust-cookbook/intro.html
- CookBook 中文版 https://rust-cookbook.budshome.com
- Nomicon(秘典,死灵书)https://doc.rust-lang.org/nightly/nomicon/
- 死灵书中文版 https://nomicon.purewhite.io
- Rust 入门中文版 https://www.bookstack.cn/read/RustPrimer/README.md
- Rust 主题系列分享 https://siciarz.net/24-days-of-rust-hyper/
- async Book https://rust-lang.github.io/async-book/
- The Embedded Rust Book https://docs.rust-embedded.org/book/intro/index.html
- 找库的地方
- https://rust.libhunt.com
- https://awesome-rust.com
- 官方找库、文档、仓库三连: https://lib.rs https://docs.rs https://crates.io
- 分享代码
- Playground https://play.rust-lang.org
一、概述
fn greet_world() {println!("Hello, world!"); // 这里的第一个感叹号表示这是一个宏,这个我们稍后会讨论。let southern_germany = "Grüß Gott!"; // Rust中的赋值,更恰当的说法叫作变量绑定,使用let关键字。let japan = "ハロー・ワールド"; // 对Unicode的支持,是“开箱即用”的。let regions = [southern_germany, japan]; // 数组字面量使用方括号。for region in regions.iter() {// 很多类型都有iter()方法,此方法会返回一个迭代器。println!("{}", ®ion); // 此处的和符号(&)表示“借用”region的值,用于只读的访问。}
}fn main() {greet_world(); // 调用一个函数。要注意紧跟在函数名后面的圆括号。
}println!是宏, 因为在底层做了大量类型检测, 所以才支持任意类型数据类型
fn main() {// <1> <2>跳过表头行和只含有空白符的行let penguin_data = "\common name,length (cm)Little penguin,33Yellow-eyed penguin,65Fiordland penguin,60Invalid,data";let records = penguin_data.lines();for (i, record) in records.enumerate() {if i == 0 || record.trim().len() == 0 {// 跳过表头行和只含有空白符的行continue;}let fields: Vec<_> = record // 从一行文本开始.split(',') // <5>将record分割(split)为多个子字符串.map(|field| field.trim()) // <6>修剪(trim)掉每个字段中两端的空白符.collect(); // <7>构建具有多个字段的集合// 条件编译: 如果cargo run 添加了--release参数, 则不满足此条件if cfg!(debug_assertions) {// <8>cfg!用于在编译时检查配置eprintln!("debug: {:?} -> {:?}", record, fields); // <9>eprintln!用于输出到标准错误(stderr)}let name = fields[0];// 如果无法从上下文推断出类型, 就需要人为指定类型(如下文的f32)if let Ok(length) = fields[1].parse::<f32>() {// <10>试图把该字段解析为一个浮点数println!("{}, {}cm", name, length); // <11>println!用于输出到标准输出(stdout)}}
}
debug: " Little penguin,33" -> ["Little penguin", "33"]
Little penguin, 33cm
debug: " Yellow-eyed penguin,65" -> ["Yellow-eyed penguin", "65"]
Yellow-eyed penguin, 65cm
debug: " Fiordland penguin,60" -> ["Fiordland penguin", "60"]
Fiordland penguin, 60cm
debug: " Invalid,data" -> ["Invalid", "data"]
1.1 安全性
1.1.1 垂悬指针
#[derive(Debug)] // 允许使用println! 宏来输出枚举体Cereal(谷类)。
enum Cereal {// enum(枚举体,是enumeration的缩写)是一个具有固定数量的合法变体的类型。Barley,Millet,Rice,Rye,Spelt,Wheat,
}fn main() {let mut grains: Vec<Cereal> = vec![]; // 初始化一个空的动态数组,其元素类型为Cereal。grains.push(Cereal::Rye); // 向动态数组grains(粮食)中添加一个元素。drop(grains); // 删除grains和其中的数据。println!("{:?}", grains); // 试图访问已删除的值。
}
error[E0382]: borrow of moved value: `grains`--> src/main.rs:16:22|
13 | let mut grains: Vec<Cereal> = vec![]; // 初始化一个空的动态数组,其元素类型为Cereal。| ---------- move occurs because `grains` has type `Vec<Cereal>`, which does not implement the `Copy` trait
14 | grains.push(Cereal::Rye); // 向动态数组grains(粮食)中添加一个元素。
15 | drop(grains); // 删除grains和其中的数据。| ------ value moved here
16 | println!("{:?}", grains); // 试图访问已删除的值。| ^^^^^^ value borrowed here after move|
1.1.2 数据竞争
运行结果不确定, 即main退出时data的值不确定, 因为线程是os调度的故无法保证顺序
use std::thread; // 把多线程的能力导入当前的局部作用域。
fn main() {let mut data = 100;thread::spawn(|| { data = 500; }); // thread::spawn() 接收一个闭包作为参数。thread::spawn(|| { data = 1000; });println!("{}", data);
}
1.1.3 迭代器失效
fn main() {let fruit = vec!['🥝', '🍌', '🍇'];let buffer_overflow = fruit[4]; // <1>Rust会让程序崩溃,而不会把一个无效的内存位置赋值给一个变量assert_eq!(buffer_overflow, '🍉') // <2>
}
fn main() {let mut letters = vec![ // <1>"a", "b", "c"];for letter in letters {println!("{}", letter);letters.push(letter.clone()); // <2>}
}
error[E0382]: borrow of moved value: `letters`--> src/main.rs:9:9|
2 | let mut letters = vec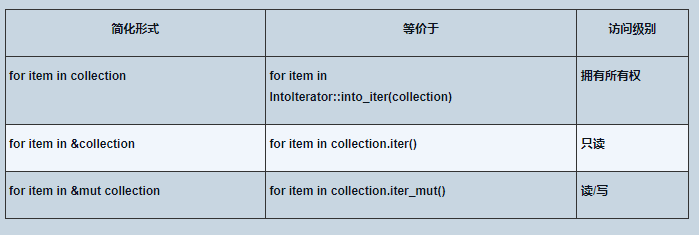
匿名循环
fn main() {for _ in 0..10 {print!("a")}
}
尽量避免手动管理索引变量, 下例不推荐
- 从性能角度, 每次
collection[i]都需要编译器检查越界 - 从安全角度, 周期性地访问
collection会引入使其改变的可能性
let collection = [1, 2, 3, 4, 5];
for i in 0..collection.len() {let item = collection[i];// ...
}
continue跳出循环
fn main() {for n in 0..10 {if n % 2 == 0 {continue;}print!("{}", n)}
}
通过循环, 测试1s能执行多少次加法运算
use std::time::{Duration, Instant}; //<1>fn main() {let mut count = 0;let time_limit = Duration::new(1, 0); //<2>let start = Instant::now(); //<3>while (Instant::now() - start) < time_limit {//<4>count += 1;}println!("{}", count);
}
如果无限循环, 用loop替代while, 当遇到break会停止
loop {println!("a")
}
可用标签退出循环, 在for关键词之前加了'outer'标签即可
fn main() {'outer: for x in 0.. {for y in 0.. {for z in 0.. {if x + y + z > 1000 {break 'outer;}println!("{}, {}, {}", x, y, z)}}}
}
break可在退出循环的同时, 返回值
fn main() {let n = loop {break 123;};println!("{}", n); // 输出“123”。
}
rust大部分都是表达式, 不返回值的才不是表达式, 具体有以下3种情况不是表达式
- 以分号
;结尾的是表达式语句 - 用赋值操作符
=绑定一个名字到一个值上, 是声明语句 - 类型声明, 包括函数
fn和用struct或enum声明的数据类型, 是声明语句
rust中, 没有返回值, 则返回()类型
match可匹配范围类型
match item {0 => {}, ⇽--- 匹配一个单值。这时是不需要任何运算符的。10 ..= 20 => {}, ⇽--- ..= 语法匹配一个包含范围(inclusive range)。40 | 80 => {}, ⇽--- 竖线(|)表示匹配其中任意一个值的情况。_ => {}, ⇽--- 下画线(_)在这里代表匹配所有值。
}
2.2 引用
如果一个变量a是一个大数组, 则r就是变量a的引用, 其实就是存储了变量a的地址.
fn main() {let a = 42; ⇽--- r是对a的引用let r = &a; ⇽--- 实现a与a相加(通过解除引用),并将结果赋值给6let b = a + *r;println!("a + a = {}", b); ⇽--- 输出"a + a = 84"
}
1 fn main() {2 let needle = 0o204;3 let haystack = [1, 1, 2, 5, 15, 52, 203, 877, 4140, 21147];45 for item in &haystack { ⇽--- 在数组haystack中遍历数组元素的引用。6 if *item == needle { ⇽--- *item,这个语法解引用item,返回它所指向的对象。7 println!("{}", item);8 }9 }
10 }
2.3 生命周期
在rust无法推断出引用的生命周期时, 就需要手动指明生命周期
fn add_with_lifetimes<'a, 'b>(i: &'a i32, j: &'b i32) -> i32 {*i + *j // 加法运算的两个操作数是i和j所指向的值
}fn main() {let a = 10;let b = 20;let res = add_with_lifetimes(&a, &b); // &a是对值10的引用,&b是对值20的引用println!("{}", res);
}// 输出30
2.4 泛型
rust的操作符均是trait方法的语法糖, rust用此支持操作符重载, a+b会转换为a.add(b)
use std::ops::Add; // 从std::ops中导入Add这个trait到当前的局部作用域中。
use std::time::Duration; // 从std::time中导入Duration类型到当前的局部作用域中。
fn add<T: Add<Output = T>>(i: T, j: T) -> T {// add() 函数的参数能接收实现了std::ops::Add的任何类型。i + j
}
fn main() {let floats = add(1.2, 3.4); // 使用浮点数作为参数调用add()。let ints = add(10, 20); // 使用整数作为参数调用add()。let durations = add(Duration::new(5, 0), Duration::new(10, 0));// 使用Duration类型的值作为参数调用add(),Duration类型表示两个时间点之间的时间间隔。println!("{}", floats);println!("{}", ints);println!("{:?}", durations); // std::time::Duration没有实现std::fmt::Display这个trait,所以我们退一步使用Std::fmt::Debug这个trait。
}
2.5 实战grep项目
rust有很多类型的字符串, 例如String, str
- 如果初学者分不清就都先用
String即可, 它最接近其他语言你认识的字符串类型, 有很多methods str高性能, 但功能较少, 一旦被创建就不能扩大缩小, 比原始内存数组多保证了所有字符都是UTF-8, 通常以&str的引用形式存在, 其内部包含指向str数据的引用和长度.- 因为rust编译器需在栈中存固定大小的变量, 而一个
str的值可为任意长度, 故只能通过引用来将其存储为局部变量
- 因为rust编译器需在栈中存固定大小的变量, 而一个
String是有所有权的类型, 可对数据读/写, 且负责在离开作用域时删除其拥有的值
&str只是一个借用的类型, 只是只读
fn main() {let search_term = "picture";let quote = "\
Every face, every shop, bedroom window, public-house, and
dark square is a picture feverishly turned--in search of what?
It is the same with books. What do we seek through millions of pages?";for (i, line) in quote.lines().enumerate() {// <1>if line.contains(search_term) {let line_num = i + 1; // <2>println!("{}: {}", line_num, line);}}
}
运行结果输出如下
2: dark square is a picture feverishly turned--in search of what?
2.6 数组
2.6.1 数组和切片
数组类型[T: n]有编译期长度, 切片类型[T]没有
因数组长度不同, [u8; 3]和[u8; 4]是不同类型, 而为每个数组类型都实现一套方法就太笨重繁琐了, 所以实际使用中, 大多数数组操作都是通过切片类型T执行的, 且常用切片的引用形式&[T]
fn main() {let one = [1, 2, 3];let two: [u8; 3] = [1, 2, 3];let blank1 = [0; 3];let blank2: [u8; 3] = [0; 3];let arrays = [one, two, blank1, blank2];for a in &arrays {print!("{:?}: ", a);for n in a.iter() {print!("\t{} + 10 = {}", n, n + 10);}let mut sum = 0;for i in 0..a.len() {sum += a[i];}println!("\t(Σ{:?} = {})", a, sum);}
}
2.6.2 动态数组
fn main() {let ctx_lines = 2;let needle = "oo";let haystack = "\
Every face, every shop,
bedroom window, public-house, and
dark square is a picture
feverishly turned--in search of what?
It is the same with books.
What do we seek
through millions of pages?";let mut tags: Vec<usize> = vec![]; // <1>let mut ctx: Vec<Vec<(usize, String)>> = vec![]; // <2>for (i, line) in haystack.lines().enumerate() { // <3>if line.contains(needle) {tags.push(i);let v = Vec::with_capacity(2*ctx_lines + 1); // <4>ctx.push(v);println!("{}, {}, {:?}, {:?}", line, i, tags, ctx)}}if tags.is_empty() { // <5>return;}for (i, line) in haystack.lines().enumerate() { // <6>for (j, tag) in tags.iter().enumerate() {let lower_bound =tag.saturating_sub(ctx_lines); // <7>let upper_bound =tag + ctx_lines;if (i >= lower_bound) && (i <= upper_bound) {let line_as_string = String::from(line); // <8>let local_ctx = (i, line_as_string);ctx[j].push(local_ctx);}}}println!("{}", ctx);for local_ctx in ctx.iter() {for &(i, ref line) in local_ctx.iter() { // <9>let line_num = i + 1;println!("{}: {}", line_num, line);}}
}
输出如下
bedroom window, public-house, and, 1, [1], [[]]
It is the same with books., 4, [1, 4], [[], []]
[[(0, "Every face, every shop,"), (1, "bedroom window, public-house, and"), (2, "dark square is a picture"), (3, "feverishly turned--in search of what?")], [(2, "dark square is a picture"), (3, "feverishly turned--in search of what?"), (4, "It is the same with books."), (5, "What do we seek"), (6, "through millions of pages?")]]
1: Every face, every shop,
2: bedroom window, public-house, and
3: dark square is a picture
4: feverishly turned--in search of what?
3: dark square is a picture
4: feverishly turned--in search of what?
5: It is the same with books.
6: What do we seek
7: through millions of pages?
2.6.3 初始化
Vec<String>
vec!["gta".to_string(),"gta(1)".to_string(),"gta".to_string(),"gta(2)".to_string(),]let mut grid: [[i32; 3]; 3] = [[1, 3, 1], [1, 5, 1], [4, 2, 1]]; // 初始化 3*3 的数组
2.7 包含第三方库
cargo new grep-lite --vcs none, 其中--vcs none是不进行git init的意思
use regex::Regex; // <1>fn main() {let re = Regex::new("picture").unwrap(); // <2>用unwrap() 解包装一个Resultlet quote = "Every face, every shop, bedroom window, public-house, and
dark square is a picture feverishly turned--in search of what?
It is the same with books. What do we seek through millions of pages?";for line in quote.lines() {let contains_substring = re.find(line);match contains_substring {// <3>Some(_) => println!("{}", line), // <4>这里的下画线是通配符,匹配所有值None => (), // <5>}}
}
cargo doc可生成本地文档, cargo doc --open可浏览器查看文档
(base) tree -d -L 1 target/doc
target/doc
├── aho_corasick
├── grep_lite
├── implementors
├── memchr
├── regex
├── regex_syntax
└── src
rustup doc会在本地打开rust文档
2.8 命令行参数
cargo add clap@2添加依赖库
use clap::{App, Arg};
use regex::Regex; // 导入clap::App和clap::Arg对象到当前的局部作用域。
fn main() {let args = App::new("grep-lite") // 逐步构建命令行参数解析器。每个参数对应一个Arg。在本例中,我们只需要一个参数。.version("0.1").about("searches for patterns").arg(// 必备的参数Arg::with_name("pattern").help("The pattern to search for").takes_value(true).required(true),).get_matches();let pattern = args.value_of("pattern").unwrap(); // 提取pattern参数。let re = Regex::new(pattern).unwrap();let quote = "Every face, every shop, bedroom window, public-house, and
dark square is a picture feverishly turned--in search of what?
It is the same with books. What do we seek through millions of pages?";for line in quote.lines() {match re.find(line) {Some(_) => println!("{}", line),None => (),}}
}
输出结果如下
cargo run
error: The following required arguments were not provided:<pattern>USAGE:grep-lite <pattern>For more information try --help
./target/debug/grep-lite --help
grep-lite 0.1
searches for patternsUSAGE:grep-lite <pattern>FLAGS:-h, --help Prints help information-V, --version Prints version informationARGS:<pattern> The pattern to search for
➜ grep-lite cargo run -- pictureFinished dev [unoptimized + debuginfo] target(s) in 0.01sRunning `target/debug/grep-lite picture`
pattern is picture
dark square is a picture feverishly turned--in search of what?➜ grep-lite cargo run -- oFinished dev [unoptimized + debuginfo] target(s) in 0.01sRunning `target/debug/grep-lite o`
pattern is o
Every face, every shop, bedroom window, public-house, and
dark square is a picture feverishly turned--in search of what?
It is the same with books. What do we seek through millions of pages?
2.9 读文件
2.9.1 手动循环读文件
use std::fs::File;
use std::io::prelude::*;
use std::io::BufReader;
fn main() {let f = File::open("readme.md").unwrap(); // 创建一个文件需要一个path(路径)参数,并且还需要处理当文件不存在时的错误情况。本例中如果readme.md不存在,程序会崩溃。let mut reader = BufReader::new(f);let mut line = String::new(); // 在整个程序的生命周期中,我们将反复重用这个String对象。loop {let len = reader.read_line(&mut line).unwrap(); // 从磁盘中读取可能会失败,所以我们需要显式地处理错误情况。在本例中,遇到错误情况时程序直接崩溃。if len == 0 {break;}println!("{} ({} bytes long)", line, len);line.truncate(0); // 将String收缩到长度为0,防止有之前行的内容遗留下来。}
}// 运行效果如下:
➜ grep-lite cat readme.md
a
bc
def
➜ grep-lite cargo run -q
a(2 bytes long)
bc(3 bytes long)
def(4 bytes long)
2.9.2 迭代器读文件
use std::fs::File;
use std::io::prelude::*;
use std::io::BufReader;fn main() {let f = File::open("readme.md").unwrap();let reader = BufReader::new(f);for line_ in reader.lines() {// <1>let line = line_.unwrap(); // <2>println!("{} ({} bytes long)", line, line.len());}
}// 运行效果如下:
➜ grep-lite cat readme.md
a
bc
def
➜ grep-lite cargo run -q
a (1 bytes long)
bc (2 bytes long)
def (3 bytes long)
2.9.3 配合命令行参数读文件
use clap::{App, Arg};
use regex::Regex;
use std::fs::File;
use std::io::prelude::*;
use std::io::BufReader;
fn main() {let args = App::new("grep-lite").version("0.1").about("searches for patterns").arg(Arg::with_name("pattern").help("The pattern to search for").takes_value(true).required(true),).arg(Arg::with_name("input").help("File to search").takes_value(true).required(true),).get_matches();let pattern = args.value_of("pattern").unwrap();let re = Regex::new(pattern).unwrap();let input = args.value_of("input").unwrap();let f = File::open(input).unwrap();let reader = BufReader::new(f);for line_ in reader.lines() {let line = line_.unwrap();match re.find(&line) {// line是String类型,但是re.find() 方法需要 &str类型作为参数。Some(_) => println!("{}", line),None => (),}}
}// 运行效果如下:
➜ grep-lite cat readme.md
a
bc
def➜ grep-lite cargo run -q
error: The following required arguments were not provided:<pattern><input>USAGE:grep-lite <pattern> <input>For more information try --help
➜ grep-lite cargo run -q -- picture readme.md
➜ grep-lite cargo run -q -- a readme.md
a
➜ grep-lite cargo run -q -- b readme.md
bc
➜ grep-lite cargo run -q -- f readme.md
def
2.10 读 stdin
use clap::{App, Arg};
use regex::Regex;
use std::fs::File;
use std::io;
use std::io::prelude::*;
use std::io::BufReader;
fn process_lines<T: BufRead + Sized>(reader: T, re: Regex) {for line_ in reader.lines() {let line = line_.unwrap();match re.find(&line) {// line是String类型,但是re.find() 接收类型为 &str的参数。Some(_) => println!("{}", line),None => (),}}
}
fn main() {let args = App::new("grep-lite").version("0.1").about("searches for patterns").arg(Arg::with_name("pattern").help("The pattern to search for").takes_value(true).required(true),).arg(Arg::with_name("input").help("File to search").takes_value(true).required(false),).get_matches();let pattern = args.value_of("pattern").unwrap();let re = Regex::new(pattern).unwrap();let input = args.value_of("input").unwrap_or("-");if input == "-" {let stdin = io::stdin();let reader = stdin.lock();process_lines(reader, re);} else {let f = File::open(input).unwrap();let reader = BufReader::new(f);process_lines(reader, re);}
}// 运行效果如下:
➜ grep-lite cargo run -q
error: The following required arguments were not provided:<pattern>USAGE:grep-lite <pattern> [input]For more information try --help
➜ grep-lite cargo run -q -- picture
a picture is good, is it?
a picture is good, is it?
^C
三、复合数据结构
3.1 普通函数
用#![allow(unused_variables)]可在编码时放宽编译器警告
!是Never类型, 表示函数永不返回, 如下
#[allow(dead_code)] // <4>放宽一个未使用函数的编译器警告。
fn read(f: &mut File, save_to: &mut Vec<u8>) -> ! { // <5>返回类型会告知Rust编译器,此函数永不返回unimplemented!() // <6>如果执行到这个宏,那么程序会崩溃。
}
若忘记在loop中加break, 则编译器会报错: 不应返回Never类型
fn forever() -> ! {loop { // 除非包含一个break,否则loop将永远不会结束循环。这阻止了此函数返回。//...};
}
3.2 struct
#[derive(Debug)] // <1>
struct File {name: String,data: Vec<u8>, // <2>
}fn main() {let f1 = File {name: String::from("f1.txt"), // <3>data: Vec::new(), // <4>};let f1_name = &f1.name; // <5>let f1_length = &f1.data.len(); // <5>println!("{:?}", f1);println!("{} is {} bytes long", f1_name, f1_length);
}
#![allow(unused_variables)] // <1>#[derive(Debug)] // <2>
struct File {name: String,data: Vec<u8>,
}fn open(f: &mut File) -> bool { // <3>true
}fn close(f: &mut File) -> bool { // <3>true
}fn read(f: &File,save_to: &mut Vec<u8>,
) -> usize { // <4>let mut tmp = f.data.clone(); // <5>let read_length = tmp.len();save_to.reserve(read_length); // <6>save_to.append(&mut tmp); // <7>read_length
}fn main() {let mut f2 = File {name: String::from("2.txt"),data: vec![114, 117, 115, 116, 33],};let mut buffer: Vec<u8> = vec![];open(&mut f2); // <8>let f2_length = read(&f2, &mut buffer); // <8>close(&mut f2); // <8>let text = String::from_utf8_lossy(&buffer); // <9>println!("{:?}", f2);println!("{} is {} bytes long", &f2.name, f2_length);println!("{}", text) // <10>
}
3.3 用 impl 为 struct 添加方法
Rust 约定用 new() 初始化,虽然 new() 并不是关键字。
#[derive(Debug)]
struct File {name: String,data: Vec<u8>,
}impl File {fn new(name: &str) -> File { // <1> As `File::new()` is a completely normal function--rather than something blessed by the language--we need to tell Rust that it will be returning a `File` from this functionFile { // <2>name: String::from(name), // <2> `File::new()` does little more than encapsulate the object creation syntaxdata: Vec::new(), // <2>}}// fn len(&self) -> usize { // <3> `File::len()` takes an implicit argument `self`. You'll notice that there is no explicit argument provided on line 25.// self.data.len() // <4> `usize` is the type returned by `Vec<T>::len()`, which is sent directly through to the caller// }
}fn main() {let f3 = File::new("f3.txt");let f3_name = &f3.name; // <5> Fields are private by default, but can be accessed within the module that defines the struct. The module system is discussed further on in the chapter.//let f3_length = f3.len();let f3_length = f3.data.len();println!("{:?}", f3);println!("{} is {} bytes long", f3_name, f3_length);
}
配合读取文件的代码如下:
#![allow(unused_variables)]#[derive(Debug)]
struct File {name: String,data: Vec<u8>,
}impl File {fn new(name: &str) -> File {File {name: String::from(name),data: Vec::new(),}}fn new_with_data(name: &str,data: &Vec<u8>,) -> File { // <1>let mut f = File::new(name);f.data = data.clone();f}fn read(self: &File,save_to: &mut Vec<u8>,) -> usize { // <2>let mut tmp = self.data.clone();let read_length = tmp.len();save_to.reserve(read_length);save_to.append(&mut tmp);read_length}
}fn open(f: &mut File) -> bool { // <3>true
}fn close(f: &mut File) -> bool {true
}fn main() {let f3_data: Vec<u8> = vec![ // <3>114, 117, 115, 116, 33];let mut f3 = File::new_with_data("2.txt", &f3_data);let mut buffer: Vec<u8> = vec![];open(&mut f3);let f3_length = f3.read(&mut buffer); // <4>close(&mut f3);let text = String::from_utf8_lossy(&buffer);println!("{:?}", f3);println!("{} is {} bytes long", &f3.name, f3_length);println!("{}", text);
}// 输出效果如下:
➜ grep-lite cargo run -q
File { name: "2.txt", data: [114, 117, 115, 116, 33] }
2.txt is 5 bytes long
rust!
3.4 返回错误信息
3.4.1 unsafe 读写全局变量
use rand::{random}; // <1>static mut ERROR: isize = 0; // <2>struct File; // <3>#[allow(unused_variables)]
fn read(f: &File, save_to: &mut Vec<u8>) -> usize {if random() && random() && random() { // <4>unsafe {ERROR = 1; // <5>}}0 // <6>
}#[allow(unused_mut)] // <7>
fn main() {let mut f = File;let mut buffer = vec![];read(&f, &mut buffer);unsafe { // <8>if ERROR != 0 {panic!("An error has occurred!")}}
}
3.4.2 Result<T, E>
use rand::prelude::*; // <1>fn one_in(denominator: u32) -> bool { // <2>thread_rng().gen_ratio(1, denominator) // <3>
}#[derive(Debug)]
struct File {name: String,data: Vec<u8>,
}impl File {fn new(name: &str) -> File {File {name: String::from(name),data: Vec::new()} // <4>}fn new_with_data(name: &str, data: &Vec<u8>) -> File {let mut f = File::new(name);f.data = data.clone();f}fn read(self: &File,save_to: &mut Vec<u8>,) -> Result<usize, String> { // <5>let mut tmp = self.data.clone();let read_length = tmp.len();save_to.reserve(read_length);save_to.append(&mut tmp);Ok(read_length) // <6>}
}fn open(f: File) -> Result<File, String> {if one_in(10_000) { // <7>let err_msg = String::from("Permission denied");return Err(err_msg);}Ok(f)
}fn close(f: File) -> Result<File, String> {if one_in(100_000) { // <8>let err_msg = String::from("Interrupted by signal!");return Err(err_msg);}Ok(f)
}fn main() {let f4_data: Vec<u8> = vec![114, 117, 115, 116, 33];let mut f4 = File::new_with_data("4.txt", &f4_data);let mut buffer: Vec<u8> = vec![];f4 = open(f4).unwrap(); // <9>let f4_length = f4.read(&mut buffer).unwrap(); // <9>f4 = close(f4).unwrap(); // <9>let text = String::from_utf8_lossy(&buffer);println!("{:?}", f4);println!("{} is {} bytes long", &f4.name, f4_length);println!("{}", text);
}
3.5 enum
#[derive(Debug)] // <1>
enum Event {Update, // <2>Delete, // <2>Unknown, // <2>
}type Message = String; // <3>fn parse_log(line: &str) -> (Event, Message) { // <4>let parts: Vec<_> = line // <5>.splitn(2, ' ').collect(); // <6>if parts.len() == 1 { // <7>return (Event::Unknown, String::from(line))}let event = parts[0]; // <8>let rest = String::from(parts[1]); // <8>match event {"UPDATE" | "update" => (Event::Update, rest), // <9>"DELETE" | "delete" => (Event::Delete, rest), // <9>_ => (Event::Unknown, String::from(line)), // <10>}
}fn main() {let log = "BEGIN Transaction XK342
UPDATE 234:LS/32231 {\"price\": 31.00} -> {\"price\": 40.00}
DELETE 342:LO/22111";for line in log.lines() {let parse_result = parse_log(line);println!("{:?}", parse_result);}
}// 运行效果如下:
➜ grep-lite cargo run -q
(Unknown, "BEGIN Transaction XK342")
(Update, "234:LS/32231 {\"price\": 31.00} -> {\"price\": 40.00}")
(Delete, "342:LO/22111")
enum 可带参数,如下:
enum Suit {Clubs,Spades,Diamonds,Hearts, ⇽--- 枚举体中的最后一个元素也可以用逗号结尾,方便以后对代码重构。
}enum Card {King(Suit), ⇽--- 人头牌(通常指扑克牌中的K、Q和J)有花色。Queen(Suit),Jack(Suit),Ace(Suit),Pip(Suit, usize), ⇽--- 点数牌有花色和点数。
}
用枚举管理内部状态:
#[derive(Debug,PartialEq)]
enum FileState {Open,Closed,
}#[derive(Debug)]
struct File {name: String,data: Vec<u8>,state: FileState,
}impl File {fn new(name: &str) -> File {File {name: String::from(name),data: Vec::new(),state: FileState::Closed,}}fn read(self: &File,save_to: &mut Vec<u8>,) -> Result<usize, String> {if self.state != FileState::Open {return Err(String::from("File must be open for reading"));}let mut tmp = self.data.clone();let read_length = tmp.len();save_to.reserve(read_length);save_to.append(&mut tmp);Ok(read_length)}
}fn open(mut f: File) -> Result<File, String> {f.state = FileState::Open;Ok(f)
}fn close(mut f: File) -> Result<File, String> {f.state = FileState::Closed;Ok(f)
}fn main() {let mut f5 = File::new("5.txt");let mut buffer: Vec<u8> = vec![];if f5.read(&mut buffer).is_err() {println!("Error checking is working");}f5 = open(f5).unwrap();let f5_length = f5.read(&mut buffer).unwrap();f5 = close(f5).unwrap();let text = String::from_utf8_lossy(&buffer);println!("{:?}", f5);println!("{} is {} bytes long", &f5.name, f5_length);println!("{}", text);
}// 运行效果如下:
➜ grep-lite cargo run -q
Error checking is working
File { name: "5.txt", data: [], state: Closed }
5.txt is 0 bytes long
3.6 trait
3.6.1 创建名为 read 的 trait
#![allow(unused_variables)] // <1>#[derive(Debug)]
struct File; // <2>trait Read { // <3>fn read(self: &Self,save_to: &mut Vec<u8>,) -> Result<usize, String>; // <4>
}impl Read for File {fn read(self: &File, save_to: &mut Vec<u8>) -> Result<usize, String> {Ok(0) // <5>}
}fn main() {let f = File{};let mut buffer = vec!();let n_bytes = f.read(&mut buffer).unwrap();println!("{} byte(s) read from {:?}", n_bytes, f);
}// 运行效果如下:
➜ grep-lite cargo run -q
0 byte(s) read from File
3.6.2 为类型实现 std::fmt::Display
#![allow(dead_code)] // <1>use std::fmt; // <2>
use std::fmt::{Display}; // <3>#[derive(Debug,PartialEq)]
enum FileState {Open,Closed,
}#[derive(Debug)]
struct File {name: String,data: Vec<u8>,state: FileState,
}impl Display for FileState {fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {match *self {FileState::Open => write!(f, "OPEN"), // <4>FileState::Closed => write!(f, "CLOSED"), // <4>}}
}impl Display for File {fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {write!(f, "<{} ({})>",self.name, self.state) // <5>}
}impl File {fn new(name: &str) -> File {File {name: String::from(name),data: Vec::new(),state: FileState::Closed,}}
}fn main() {let f6 = File::new("f6.txt");//...println!("{:?}", f6); // <6>println!("{}", f6); // <7>
}// 运行结果如下:
➜ grep-lite cargo run -q
File { name: "f6.txt", data: [], state: Closed }
<f6.txt (CLOSED)>
四、生命周期-所有权-借用
- 基本类型默认实现了 copy trait,则按如下正常运行:
#![allow(unused_variables)]#[derive(Debug)]
enum StatusMessage {Ok,
}fn check_status(sat_id: u64) -> StatusMessage {StatusMessage::Ok
}fn main () {let sat_a = 0; // <1>let sat_b = 1; // <1>let sat_c = 2; // <1>let a_status = check_status(sat_a);let b_status = check_status(sat_b);let c_status = check_status(sat_c);println!("a: {:?}, b: {:?}, c: {:?}", a_status, b_status, c_status);// "waiting" ...let a_status = check_status(sat_a);let b_status = check_status(sat_b);let c_status = check_status(sat_c);println!("a: {:?}, b: {:?}, c: {:?}", a_status, b_status, c_status);
}
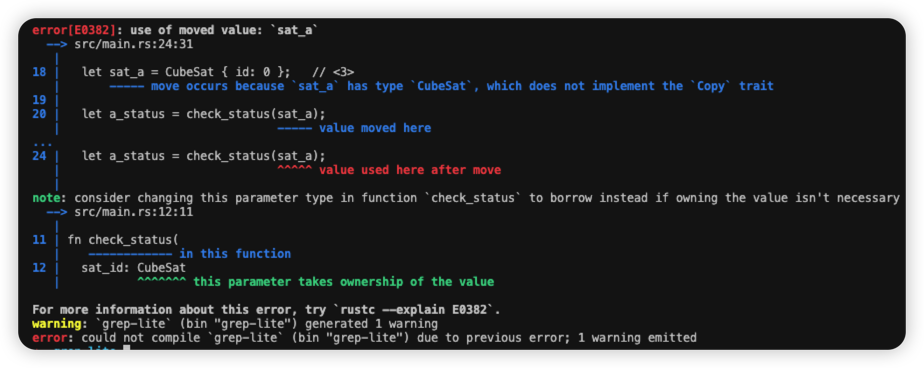
- 复合类型如 struct 默认未实现 copy trait,则不会正常运行:
#[derive(Debug)] // <1>
struct CubeSat {id: u64,
}#[derive(Debug)]
enum StatusMessage {Ok,
}fn check_status(sat_id: CubeSat
) -> StatusMessage { // <2>StatusMessage::Ok
}fn main() {let sat_a = CubeSat { id: 0 }; // <3>let a_status = check_status(sat_a);println!("a: {:?}", a_status);// "waiting" ...let a_status = check_status(sat_a);println!("a: {:?}", a_status);
}
报错信息如下:
- 另一个例子如下:
fn use_value(_val: Demo) {}struct Demo {a: i32,
}fn main() {let demo = Demo {a: 123};use_value(demo);println!("{}", demo.a);
}

4.5 所有权
#[derive(Debug)]
struct CubeSat {id: u64,mailbox: Mailbox,
}#[derive(Debug)]
struct Mailbox {messages: Vec<Message>,
}type Message = String;struct GroundStation;impl GroundStation {fn send(&self, to: &mut CubeSat, msg: Message) {to.mailbox.messages.push(msg);}
}impl CubeSat {fn recv(&mut self) -> Option<Message> {self.mailbox.messages.pop()}
}fn main() {let base = GroundStation {};let mut sat_a = CubeSat {id: 0,mailbox: Mailbox {messages: vec![],},};println!("t0: {:?}", sat_a);base.send(&mut sat_a,Message::from("hello there!")); // <1>println!("t1: {:?}", sat_a);let msg = sat_a.recv();println!("t2: {:?}", sat_a);println!("msg: {:?}", msg);
}// 程序输出如下:
t0: CubeSat { id: 0, mailbox: Mailbox { messages: [] } }
t1: CubeSat { id: 0, mailbox: Mailbox { messages: ["hello there!"] } }
t2: CubeSat { id: 0, mailbox: Mailbox { messages: [] } }
4.5.2 引用
#![allow(unused_variables)]#[derive(Debug)]
struct CubeSat {id: u64,
}#[derive(Debug)]
struct Mailbox {messages: Vec<Message>,
}#[derive(Debug)]
struct Message {to: u64,content: String,
}struct GroundStation {}impl Mailbox {fn post(&mut self, msg: Message) {self.messages.push(msg);}fn deliver(&mut self, recipient: &CubeSat) -> Option<Message> {for i in 0..self.messages.len() {if self.messages[i].to == recipient.id {let msg = self.messages.remove(i);return Some(msg);}}None}
}impl GroundStation {fn connect(&self, sat_id: u64) -> CubeSat {CubeSat {id: sat_id,}}fn send(&self, mailbox: &mut Mailbox, msg: Message) {mailbox.post(msg);}
}impl CubeSat {fn recv(&self, mailbox: &mut Mailbox) -> Option<Message> {mailbox.deliver(&self)}
}fn fetch_sat_ids() -> Vec<u64> {vec![1,2,3]
}fn main() {let mut mail = Mailbox { messages: vec![] };let base = GroundStation {};let sat_ids = fetch_sat_ids();for sat_id in sat_ids {// let sat = base.connect(sat_id);let msg = Message { to: sat_id, content: String::from("hello") };base.send(&mut mail, msg);}let sat_ids = fetch_sat_ids();for sat_id in sat_ids {let sat = base.connect(sat_id);let msg = sat.recv(&mut mail);println!("{:?}: {:?}", sat, msg);}
}// 输出效果如下:
CubeSat { id: 1 }: Some(Message { to: 1, content: "hello" })
CubeSat { id: 2 }: Some(Message { to: 2, content: "hello" })
CubeSat { id: 3 }: Some(Message { to: 3, content: "hello" })
4.5.3 Copy 和 Clone
#[derive(Debug,Clone,Copy)] // <1>
struct CubeSat {id: u64,
}#[derive(Debug,Clone,Copy)] // <1>
enum StatusMessage {Ok,
}fn check_status(sat_id: CubeSat) -> StatusMessage {StatusMessage::Ok
}fn main () {let sat_a = CubeSat { id: 0 };let a_status = check_status(sat_a.clone()); // <2>println!("a: {:?}", a_status.clone()); // <2>let a_status = check_status(sat_a); // <3>println!("a: {:?}", a_status); // <3>
}// 程序输出如下:
a: Ok
a: Ok
五、深入理解数据
5.1 位模式和类型
如下例,同样的二进制位,若用不同的数据类型解释,则会有不同的值。
fn main() {let a: u16 = 50115;let b: i16 = -15421;println!("a {:016b} {}", a, a);println!("b {:016b} {}", b, b);
}// 运行效果如下:
a 1100001111000011 50115
b 1100001111000011 -15421
下例更进一步说明:
fn main() {let a: f32 = 42.42;let frankentype: u32 = unsafe {std::mem::transmute(a) // <1>};println!("{}", frankentype); // <2>println!("{:032b}", frankentype); // <3>let b: f32 = unsafe {std::mem::transmute(frankentype)};println!("{}", b);assert_eq!(a, b); // <4>
}// 运行效果如下:
1110027796
01000010001010011010111000010100
42.42
5.2 整数的生存范围
每个类型都存在数据范围,如无符号16位整数是0~65535,若超过上限即为溢出。如下例
fn main() {let mut i: u16 = 0;println!("{}..", i);loop {i += 1000;print!("{}..", i);if i % 10000 == 0 {print!("\n")}}
}// 程序输出如下:
0..
1000..2000..3000..4000..5000..6000..7000..8000..9000..10000..
11000..12000..13000..14000..15000..16000..17000..18000..19000..20000..
21000..22000..23000..24000..25000..26000..27000..28000..29000..30000..
31000..32000..33000..34000..35000..36000..37000..38000..39000..40000..
41000..42000..43000..44000..45000..46000..47000..48000..49000..50000..
51000..52000..53000..54000..55000..56000..57000..58000..59000..60000..
thread 'main' panicked at 'attempt to add with overflow', src/main.rs:5:5
stack backtrace:0: rust_begin_unwindat /rustc/90c541806f23a127002de5b4038be731ba1458ca/library/std/src/panicking.rs:578:51: core::panicking::panic_fmtat /rustc/90c541806f23a127002de5b4038be731ba1458ca/library/core/src/panicking.rs:67:142: core::panicking::panicat /rustc/90c541806f23a127002de5b4038be731ba1458ca/library/core/src/panicking.rs:117:53: mandelbrot::mainat ./src/main.rs:5:54: core::ops::function::FnOnce::call_onceat /rustc/90c541806f23a127002de5b4038be731ba1458ca/library/core/src/ops/function.rs:250:5
note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.
61000..62000..63000..64000..65000..
下例展示了65535的上界:
fn main() {let zero: u16 = 0b0000_0000_0000_0000;let one: u16 = 0b0000_0000_0000_0001;let two: u16 = 0b0000_0000_0000_0010;// ...let sixtyfivethousand_533: u16 = 0b1111_1111_1111_1101;let sixtyfivethousand_534: u16 = 0b1111_1111_1111_1110;let sixtyfivethousand_535: u16 = 0b1111_1111_1111_1111;print!("{}, {}, {}, ..., ", zero, one, two);println!("{}, {}, {}", sixtyfivethousand_533, sixtyfivethousand_534, sixtyfivethousand_535);
}// code result:
0, 1, 2, ..., 65533, 65534, 65535
下例允许溢出,可观测到溢出效果:
#[allow(arithmetic_overflow)]
fn main() {let (a, b) = (200, 200);let c: u8 = a + b;println!("200 + 200 = {}", c);
}// code result:
thread 'main' panicked at 'attempt to add with overflow', src/main.rs:4:15
stack backtrace:0: rust_begin_unwindat /rustc/90c541806f23a127002de5b4038be731ba1458ca/library/std/src/panicking.rs:578:51: core::panicking::panic_fmtat /rustc/90c541806f23a127002de5b4038be731ba1458ca/library/core/src/panicking.rs:67:142: core::panicking::panicat /rustc/90c541806f23a127002de5b4038be731ba1458ca/library/core/src/panicking.rs:117:53: mandelbrot::mainat ./src/main.rs:4:154: core::ops::function::FnOnce::call_onceat /rustc/90c541806f23a127002de5b4038be731ba1458ca/library/core/src/ops/function.rs:250:5
note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.
通过上例,我们知道尽管 Rust 有很多优点,但 Rust 编写的程序仍有可能崩溃。
5.2.1 字节序
下例可知,同样的二进制位,用大端序 or 小端序解释,有不同的结果:
use std::mem::transmute;fn main() {let big_endian: [u8; 4] = [0xAA, 0xBB, 0xCC, 0xDD];let little_endian: [u8; 4] = [0xDD, 0xCC, 0xBB, 0xAA];let a: i32 = unsafe { transmute(big_endian) };let b: i32 = unsafe { transmute(little_endian) };println!("{} vs {}", a, b);
}// code result:
-573785174 vs -1430532899
- 字节之间的布局:20世纪90年代,不同厂商有不同的字节序实现,Inter 选择的小端占了绝大部分市场。
- 字节内部的布局:称为 位编号(bit numbering)或 位端序(bit endianness),并不影响日常编程,可查自己的计算机平台的最高有效位(most significiant byte)究竟属于哪一端。
5.4 浮点数
浮点数,在计算机中,用科学计数法表示。科学计数法由符号(sign)、尾数(mantissa)、基数(radix)、指数(exponent)组成。
5.4.1 观察 f32 的内部
f32 类型的 42.42 编码后的位模式是 01000010001010011010111000010100,即 0x4229AE14,如下图所示:

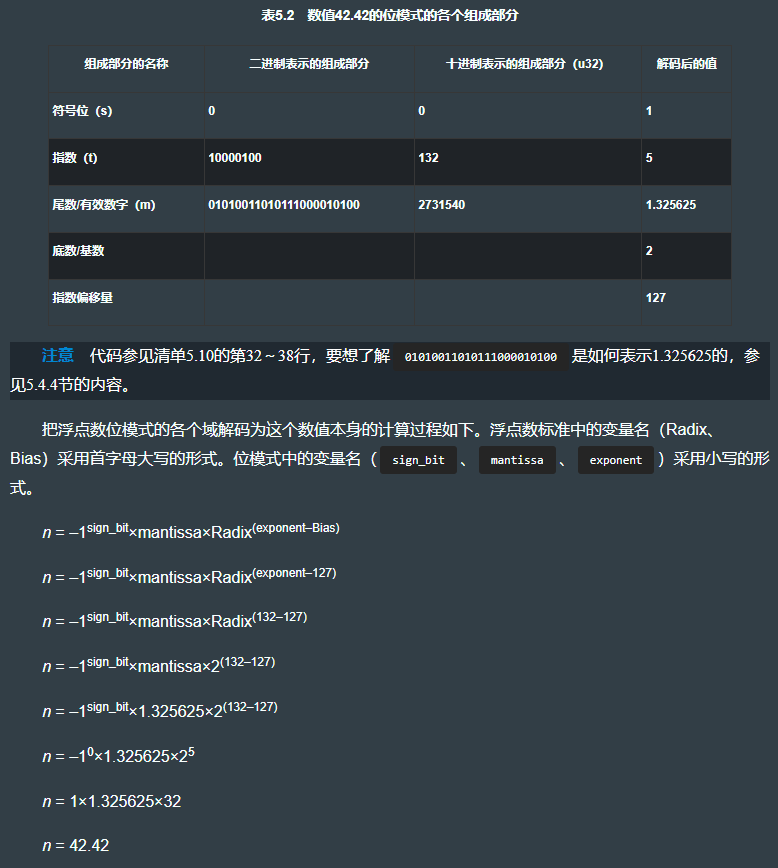
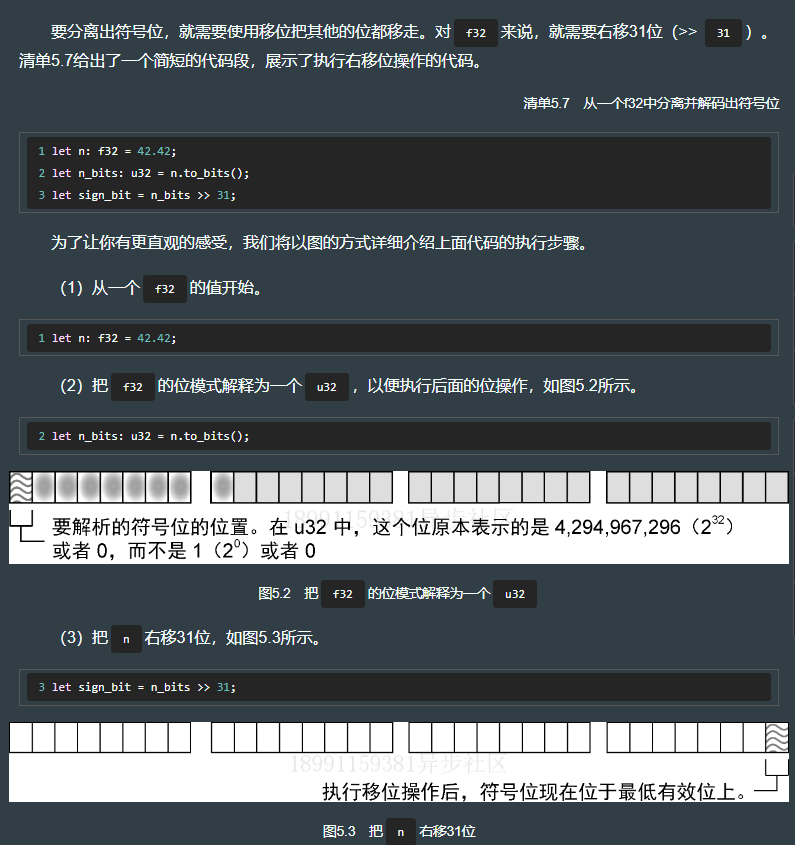
5.4.2 分离出符号位
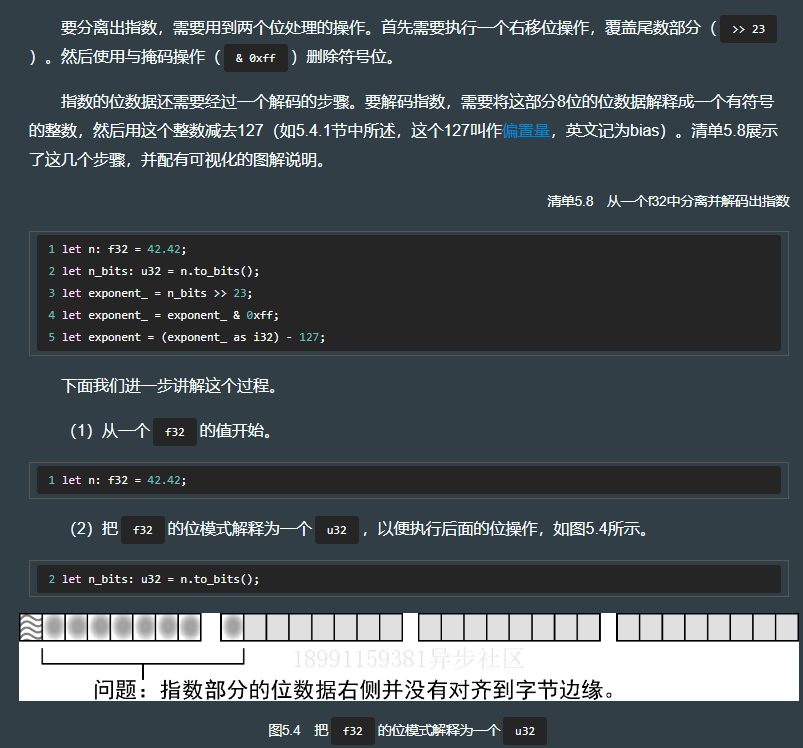
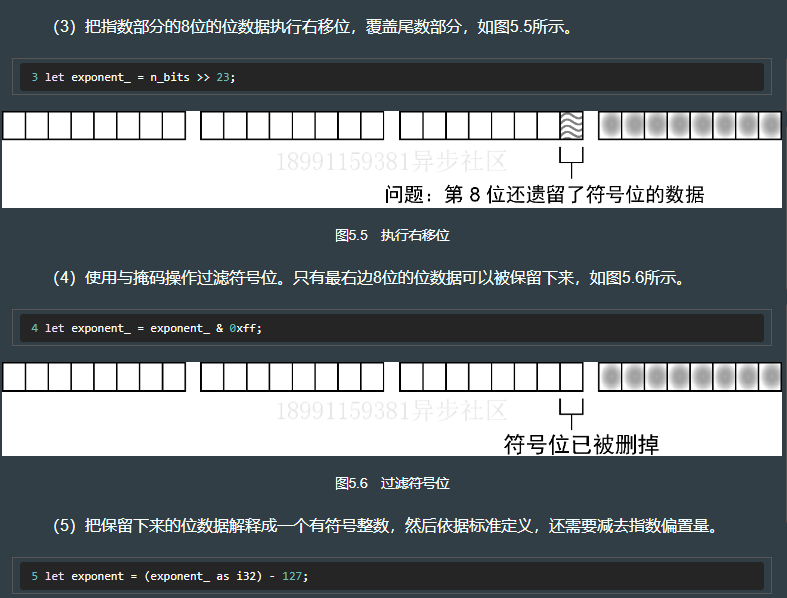
5.4.3 分离出指数
5.4.4 分离出尾数
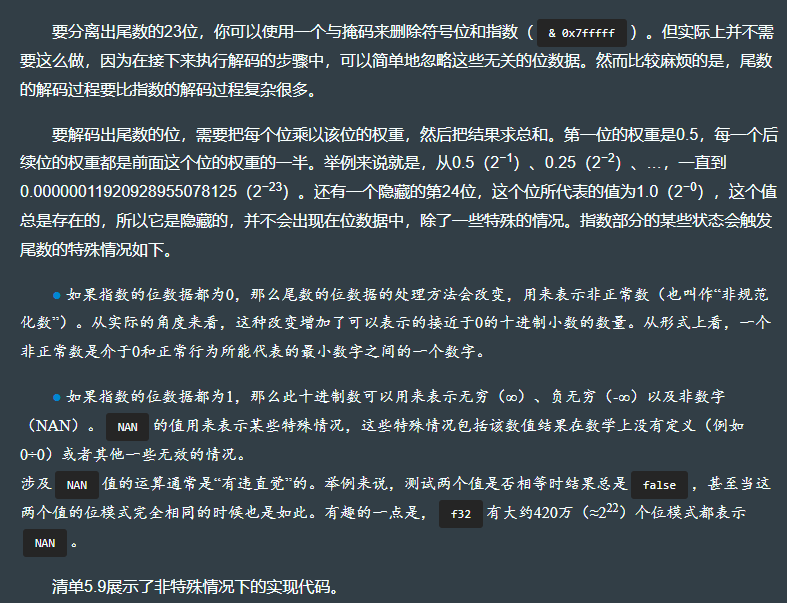
5.4.5 剖析一个浮点数
const BIAS: i32 = 127; // <1>
const RADIX: f32 = 2.0; // <1>fn main() { // <2>let n: f32 = 42.42;let (sign, exp, frac) = to_parts(n); // 0 132 2731540let (sign_, exp_, mant) = decode(sign, exp, frac); // 1 32 1.32562494let n_ = from_parts(sign_, exp_, mant); // 42.4199982println!("{} -> {}", n, n_);println!("field | as bits | as real number");println!("sign | {:01b} | {}", sign, sign_);println!("exponent | {:08b} | {}", exp, exp_);println!("mantissa | {:023b} | {}", frac, mant);
}fn to_parts(n: f32) -> (u32, u32, u32) {let bits = n.to_bits();let sign = (bits >> 31) & 1; // 使用移位操作移除不需要的31个位数据,只保留符号位let exponent = (bits >> 23) & 0xff; // 先移除23个不需要的位数据,然后使用逻辑与掩码操作过滤高位的数据let fraction = bits & 0x7fffff ; // 使用一个与掩码操作,只保留23个最低有效位(sign, exponent, fraction) // 尾数部分在这里叫作fraction(分数),执行了解码操作后,才管这部分数据叫作尾数
}fn decode(sign: u32,exponent: u32,fraction: u32
) -> (f32, f32, f32) {let signed_1 = (-1.0_f32).powf(sign as f32); // 把符号位转换成1.0或者-1.0。在这里,−1.0_f32需要用括号括起来,用于表明运算的优先级,这是因为方法调用的优先级高于单目减号运算符的let exponent = (exponent as i32) - BIAS; // 指数必须先转为i32,因为减去BIAS以后的结果有可能是负数。接下来,还需要把它转换为f32,这样才能把它用于指数幂的运算中let exponent = RADIX.powf(exponent as f32); // <8>let mut mantissa: f32 = 1.0;for i in 0..23 { // 用5.4.4节中描述的逻辑来解码尾数let mask = 1 << i; // <9>let one_at_bit_i = fraction & mask; // <9>if one_at_bit_i != 0 { // <9>let i_ = i as f32; // <9>let weight = 2_f32.powf( i_ - 23.0 ); // <9>mantissa += weight; / ·/ <9>} // <9>} // <9>(signed_1, exponent, mantissa)
}fn from_parts( // 在中间步骤中直接使用了f32的值,有一些“作弊”的意思。希望这个“作弊”行为是可以被原谅的sign: f32,exponent: f32,mantissa: f32,
) -> f32 {sign * exponent * mantissa
}// code result:
42.42 -> 42.42
field | as bits | as real number
sign | 0 | 1
exponent | 10000100 | 32
mantissa | 01010011010111000010100 | 1.325625
5.5 定点数格式
#[derive(Debug,Clone,Copy,PartialEq,Eq)]
pub struct Q7(i8);impl From<f64> for Q7 {fn from (n: f64) -> Self {if n >= 1.0 {Q7(127)} else if n <= -1.0 {Q7(-128)} else {Q7((n * 128.0) as i8)}}
}impl From<Q7> for f64 {fn from(n: Q7) -> f64 {(n.0 as f64) * 2f64.powf(-7.0)}
}impl From<f32> for Q7 {fn from (n: f32) -> Self {Q7::from(n as f64)}
}impl From<Q7> for f32 {fn from(n: Q7) -> f32 {f64::from(n) as f32}
}#[cfg(test)]
mod tests { // <1>use super::*; // <2>#[test]fn out_of_bounds() {assert_eq!(Q7::from(10.), Q7::from(1.));assert_eq!(Q7::from(-10.), Q7::from(-1.));}#[test]fn f32_to_q7() {let n1: f32 = 0.7;let q1 = Q7::from(n1);let n2 = -0.4;let q2 = Q7::from(n2);let n3 = 123.0;let q3 = Q7::from(n3);assert_eq!(q1, Q7(89));assert_eq!(q2, Q7(-51));assert_eq!(q3, Q7(127));}#[test]fn q7_to_f32() {let q1 = Q7::from(0.7);let n1 = f32::from(q1);assert_eq!(n1, 0.6953125);let q2 = Q7::from(n1);let n2 = f32::from(q2);assert_eq!(n1, n2);}
}// code result:
running 3 tests
test tests::f32_to_q7 ... ok
test tests::out_of_bounds ... ok
test tests::q7_to_f32 ... oktest result: ok. 3 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
5.6 从随机字节中生成随机概率
fn mock_rand(n: u8) -> f32 {let base: u32 = 0b0_01111110_00000000000000000000000;let large_n = (n as u32) << 15;let f32_bits = base | large_n;let m = f32::from_bits(f32_bits);2.0 * ( m - 0.5 )
}fn main() {println!("max of input range: {:08b} -> {:?}", 0xff, mock_rand(0xff));println!("mid of input range: {:08b} -> {:?}", 0x7f, mock_rand(0x7f));println!("min of input range: {:08b} -> {:?}", 0x00, mock_rand(0x00));
}// code result:
max of input range: 11111111 -> 0.99609375
mid of input range: 01111111 -> 0.49609375
min of input range: 00000000 -> 0.0
5.7 实现一个 CPU 模拟器
我们可以通过程序,模拟 CPU 的工作方式,了解计算机如何在基础层面运行的。我们将实现一个 CHIP-8 系统的子集。
5.7.1 CPU 原型1:加法器
CPU 需要把数据从内存加载到寄存器,并和 操作码 做运算。
struct CPU {current_operation: u16,registers: [u8; 2],
}impl CPU {fn read_opcode(&self) -> u16 {self.current_operation // 如果引入了从内存中读取的功能,read_opcode() 会变得更复杂}fn run(&mut self) {// loop {let opcode = self.read_opcode(); // 0x8014即32788// 操作码的解码过程let c = ((opcode & 0xF000) >> 12) as u8; // 8let x = ((opcode & 0x0F00) >> 8) as u8; // 0let y = ((opcode & 0x00F0) >> 4) as u8; // 1let d = ((opcode & 0x000F) >> 0) as u8; // 4match (c, x, y, d) {(0x8, _, _, 0x4) => self.add_xy(x, y), // 把真正执行此操作的任务,分配到负责执行该操作的“硬件电路”上_ => todo!("opcode {:04x}", opcode), // 一个全功能的模拟器,包含许多不同的操作任务}// }}fn add_xy(&mut self, x: u8, y: u8) {self.registers[x as usize] += self.registers[y as usize];}
}fn main() {let mut cpu = CPU {current_operation: 0,registers: [0; 2],};cpu.current_operation = 0x8014;cpu.registers[0] = 5;cpu.registers[1] = 10;cpu.run();assert_eq!(cpu.registers[0], 15);println!("5 + 10 = {}", cpu.registers[0]);
}// code result:
5 + 10 = 15
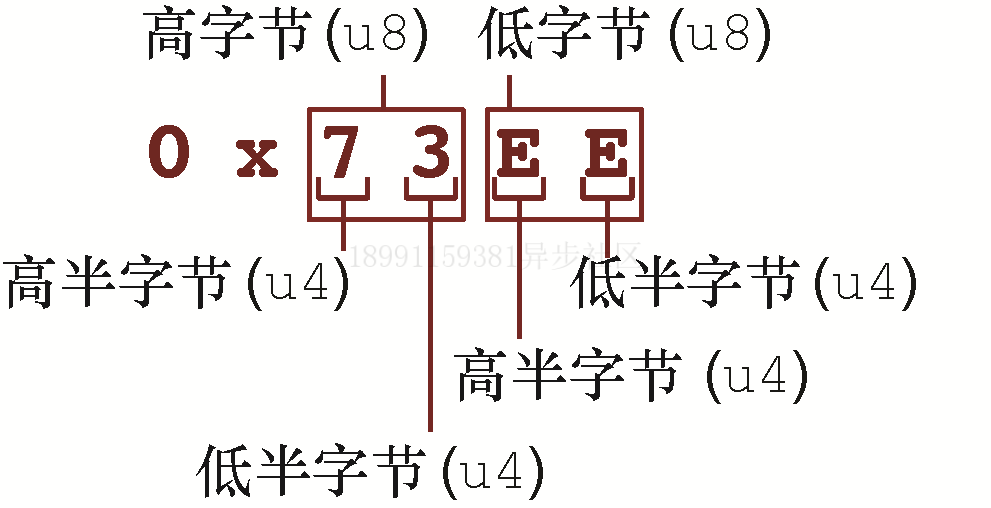
CHIP-8 操作码各组成部分如下图:
操作码解码过程如下:
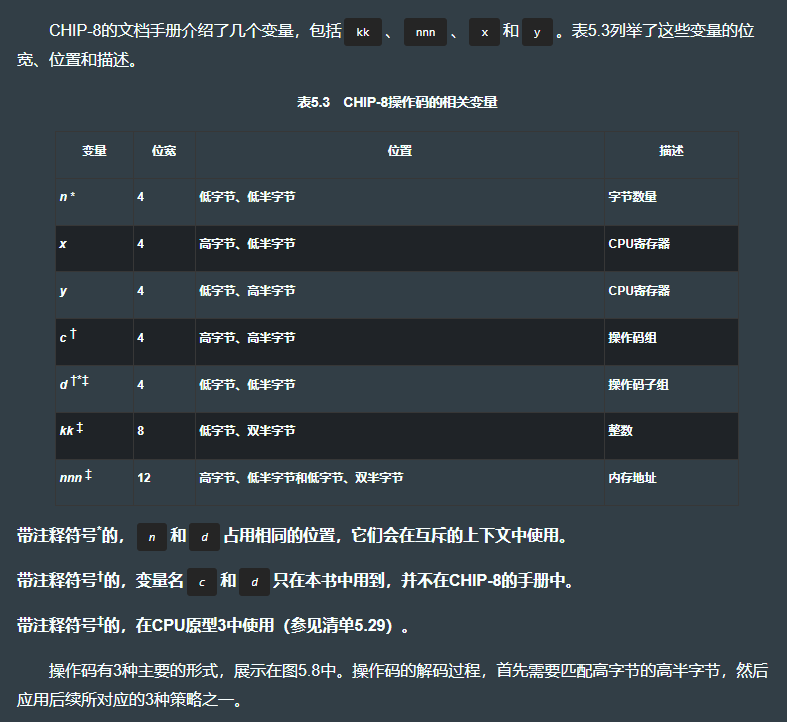

fn main() {let opcode: u16 = 0x71E4;let c = (opcode & 0xF000) >> 12; // 先使用与(&)操作进行过滤,把想要的那个半字节保留下来,然后把这个半字节的位数据右移位到最低有效位的位置上。使用十六进制表示只是出于方便,每个十六进制的数字位表示二进制的4个位。一个0xF的值就选中了单个半字节所有的位数据。let x = (opcode & 0x0F00) >> 8;let y = (opcode & 0x00F0) >> 4;let d = (opcode & 0x000F) >> 0;assert_eq!(c, 0x7); // opcode中的这4个半字节,在处理以后会拆分出4个独立的变量。assert_eq!(x, 0x1);assert_eq!(y, 0xE);assert_eq!(d, 0x4);let nnn = opcode & 0x0FFF; // 若想要多个半字节,可以通过增加过滤器的宽度来一次性选中更多的半字节。为此,在这里向右移位就不是必需的了。let kk = opcode & 0x00FF;assert_eq!(nnn, 0x1E4);assert_eq!(kk, 0xE4);
}
5.7.3 CPU 原型2:累加器
5.7.3.1 使 CPU 支持内存访问
计算机是需要内存的,代码如下:
struct CPU {registers: [u8; 16],position_in_memory: usize, // 用usize而不是u16与最初的规范是不同的,但我们用usize,因为Rust允许此类型被用于索引。memory: [u8; 0x1000],
}

5.7.3.2 从内存中读取操作码
从内存读出两个 u8,并合并为一个 u16。
fn read_opcode(&self) -> u16 {let p = self.position_in_memory;let op_byte1 = self.memory[p] as u16;let op_byte2 = self.memory[p + 1] as u16;op_byte1 << 8 | op_byte2 // 要创建一个u16类型的操作码,我们使用逻辑或操作,把内存中的两个值合并到一起。这两个值需要先转换为u16,如果不先做这个转换,左移位会将所有的位数据都设为0。
}
5.7.3.3 处理整数溢出
CHIP-8 中,最后一个寄存器被用作 进位标志,若其被设置,说明有一个操作在 u8 大小的寄存器中产生了溢出。
fn add_xy(&mut self, x: u8, y: u8) {let arg1 = self.registers[x as usize];let arg2 = self.registers[y as usize];let (val, overflow) = arg1.overflowing_add(arg2); ⇽---- 对于u8类型来说,overflowing_add() 方法的返回类型为 (u8, bool)。如果检测到溢出则返回值中这个布尔类型的值为true。self.registers[x as usize] = val;if overflow {self.registers[0xF] = 1;} else {self.registers[0xF] = 0;}
}
5.7.3.4 完整代码
struct CPU {registers: [u8; 16],position_in_memory: usize,memory: [u8; 0x1000],
}impl CPU {fn read_opcode(&self) -> u16 {let p = self.position_in_memory;let op_byte1 = self.memory[p] as u16;let op_byte2 = self.memory[p + 1] as u16;op_byte1 << 8 | op_byte2}fn run(&mut self) {loop { // <1>let opcode = self.read_opcode();self.position_in_memory += 2; // 自增position_in_memory,指向下一条指令let c = ((opcode & 0xF000) >> 12) as u8;let x = ((opcode & 0x0F00) >> 8) as u8;let y = ((opcode & 0x00F0) >> 4) as u8;let d = ((opcode & 0x000F) >> 0) as u8;match (c, x, y, d) {(0, 0, 0, 0) => { return; }, // 当遇到的操作码为0x0000时,此处的短路功能会终止函数的执行(0x8, _, _, 0x4) => self.add_xy(x, y),_ => todo!("opcode {:04x}", opcode),}}}fn add_xy(&mut self, x: u8, y: u8) {let arg1 = self.registers[x as usize];let arg2 = self.registers[y as usize];let (val, overflow) = arg1.overflowing_add(arg2);self.registers[x as usize] = val;if overflow {self.registers[0xF] = 1;} else {self.registers[0xF] = 0;}}
}fn main() {let mut cpu = CPU {registers: [0; 16],memory: [0; 4096],position_in_memory: 0,};cpu.registers[0] = 5;cpu.registers[1] = 10;cpu.registers[2] = 10; // 使用值来初始化几个寄存器cpu.registers[3] = 10; // <4>let mem = &mut cpu.memory;mem[0] = 0x80; mem[1] = 0x14; // 加载操作码0x8014,0x8014的意思是把寄存器1的值加到寄存器0上mem[2] = 0x80; mem[3] = 0x24; // 加载操作码0x8024,0x8024的意思是把寄存器2的值加到寄存器0上mem[4] = 0x80; mem[5] = 0x34; // 加载操作码0x8034,0x8034的意思是把寄存器3的值加到寄存器0上cpu.run();assert_eq!(cpu.registers[0], 35);println!("5 + 10 + 10 + 10 = {}", cpu.registers[0]);
}// code result:
5 + 10 + 10 + 10 = 35
5.7.4 CPU 原型3:调用函数
我们几乎快要构建完成模拟器的全部机制了,本节增加调用函数的能力。
5.7.4.1 给 CPU 扩展出 支持栈 的能力
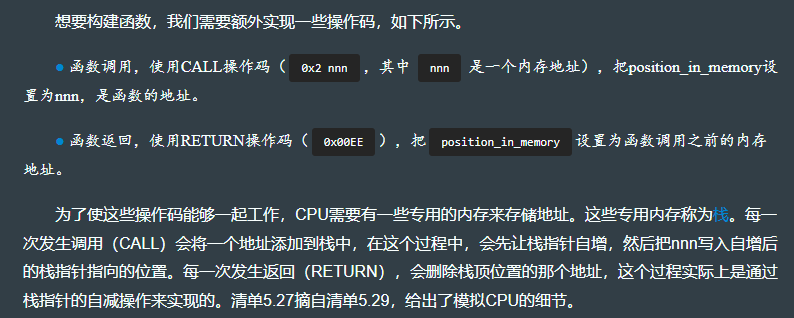
struct CPU {registers: [u8; 16],position_in_memory: usize,memory: [u8; 4096],stack: [u16; 16], // 栈的最大高度是16。在16次嵌套的函数调用后,此程序将会发生栈溢出。stack_pointer: usize, // 把stack_pointer(栈指针)的类型设为usize,可以让在stack(栈)中索引值的操作变得更容易。
}
5.7.4.2 定义一个函数并把它加载到内存中
fn main() {let mut memory: [u8; 4096] = [0; 4096];let mem = &mut memory;mem[0x100] = 0x80; mem[0x101] = 0x14;mem[0x102] = 0x80; mem[0x103] = 0x14;mem[0x104] = 0x00; mem[0x105] = 0xEE;println!("{:?}", &mem[0x100..0x106]); // 输出[128, 20, 128, 20, 0, 238]。
}
5.7.4.3 实现 CALL 和 RETURN 操作码
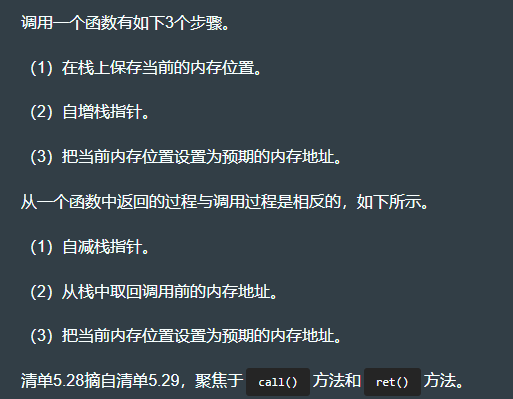
fn call(&mut self, addr: u16) {let sp = self.stack_pointer;let stack = &mut self.stack;if sp > stack.len() {panic!("Stack overflow!")}stack[sp] = self.position_in_memory as u16; // 把当前position_in_memory的值加入栈。此内存地址比调用位置高两个字节,因为它已在run()方法的方法体中执行了自增。self.stack_pointer += 1; // 自增self.stack_pointer。这个操作能防止在栈中已保存的self.position_in_memory被覆盖,在后面函数返回时还需要用到这个值。self.position_in_memory = addr as usize; // 修改self.position_in_ memory的值,其作用是跳转到修改后的地址。
}fn ret(&mut self) {if self.stack_pointer == 0 {panic!("Stack underflow");}self.stack_pointer -= 1; let call_addr = self.stack[self.stack_pointer]; // 跳转到调用之前的地址,也就是在前面函数调用时保存的那个地址。self.position_in_memory = call_addr as usize;
}
5.7.4.4 完整代码
struct CPU {registers: [u8; 16],position_in_memory: usize,memory: [u8; 4096],stack: [u16; 16],stack_pointer: usize,}impl CPU {fn read_opcode(&self) -> u16 {let p = self.position_in_memory;let op_byte1 = self.memory[p] as u16;let op_byte2 = self.memory[p + 1] as u16;op_byte1 << 8 | op_byte2}fn run(&mut self) {loop {let opcode = self.read_opcode();self.position_in_memory += 2;let c = ((opcode & 0xF000) >> 12) as u8;let x = ((opcode & 0x0F00) >> 8) as u8;let y = ((opcode & 0x00F0) >> 4) as u8;let d = ((opcode & 0x000F) >> 0) as u8;let nnn = opcode & 0x0FFF;// let kk = (opcode & 0x00FF) as u8;match (c, x, y, d) {( 0, 0, 0, 0) => { return; },( 0, 0, 0xE, 0xE) => self.ret(),(0x2, _, _, _) => self.call(nnn),(0x8, _, _, 0x4) => self.add_xy(x, y),_ => todo!("opcode {:04x}", opcode),}}}fn call(&mut self, addr: u16) {let sp = self.stack_pointer;let stack = &mut self.stack;if sp >= stack.len() {panic!("Stack overflow!")}stack[sp] = self.position_in_memory as u16;self.stack_pointer += 1;self.position_in_memory = addr as usize;}fn ret(&mut self) {if self.stack_pointer == 0 {panic!("Stack underflow");}self.stack_pointer -= 1;let addr = self.stack[self.stack_pointer];self.position_in_memory = addr as usize;}fn add_xy(&mut self, x: u8, y: u8) {let arg1 = self.registers[x as usize];let arg2 = self.registers[y as usize];let (val, overflow_detected) = arg1.overflowing_add(arg2);self.registers[x as usize] = val;if overflow_detected {self.registers[0xF] = 1;} else {self.registers[0xF] = 0;}}}fn main() {let mut cpu = CPU {registers: [0; 16],memory: [0; 4096],position_in_memory: 0,stack: [0; 16],stack_pointer: 0,};cpu.registers[0] = 5;cpu.registers[1] = 10;let mem = &mut cpu.memory;mem[0x000] = 0x21; mem[0x001] = 0x00; // 设置操作码0x2100:在0x100处调用函数mem[0x002] = 0x21; mem[0x003] = 0x00; // 设置操作码0x2100:同样是在0x100处调用函数mem[0x004] = 0x00; mem[0x005] = 0x00; // 设置操作码0x0000:停止执行(严格意义上并非是必要的,因为cpu.memory是用空字节初始化的)mem[0x100] = 0x80; mem[0x101] = 0x14; // 设置操作码0x8014:把寄存器1的值加到寄存器0上mem[0x102] = 0x80; mem[0x103] = 0x14; // 设置操作码0x8014:把寄存器1的值加到寄存器0上mem[0x104] = 0x00; mem[0x105] = 0xEE; // 设置操作码0x00EE:函数返回cpu.run();assert_eq!(cpu.registers[0], 45);println!("5 + (10 * 2) + (10 * 2) = {}", cpu.registers[0]);
}// code result:
5 + (10 * 2) + (10 * 2) = 45
下图展示了当运行 cpu.run() 时,CPU 内部发生了什么,其中箭头反映了执行程序时 cpu.position_in_memory 的状态变化:
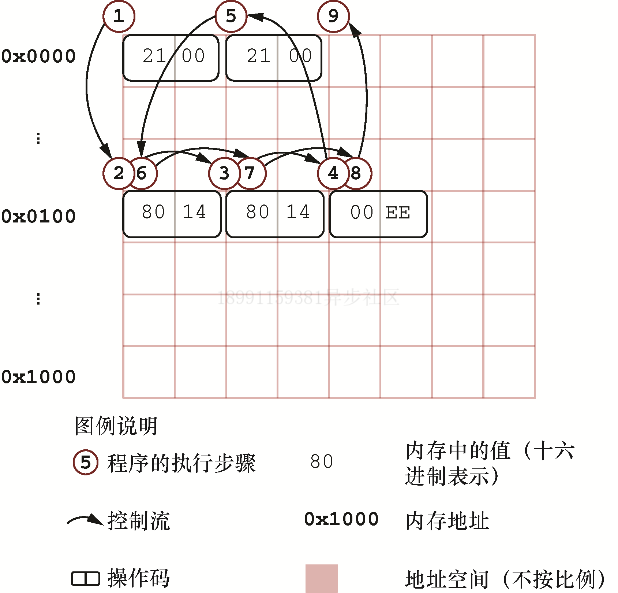
如果你研究此系统的原始文档,就会发现比起简单跳转到一个预定义的内存位置,真实的函数要更复杂。不同的操作系统和CPU体系结构,在函数调用的约定以及函数的具体能力方面会有所不同。有的约定会要求把操作数加入栈,而有的则会要求把操作数插入已定义的寄存器。尽管某个特定系统的机制可能会有所不同,然而大致的过程与你刚刚看到过的这个过程是类似的。
5.7.5 CPU4:添加额外功能
额外的操作码实现如下:
struct CPU {registers: [u8; 16],position_in_memory: usize, // program counter ("PC")memory: [u8; 4096],stack: [u16; 16],stack_pointer: usize,
}impl CPU {fn run(&mut self) {loop {let op_byte1 = self.memory[self.position_in_memory] as u16;let op_byte2 = self.memory[self.position_in_memory + 1] as u16;let opcode: u16 = op_byte1 << 8 | op_byte2;let x = ((opcode & 0x0F00) >> 8) as u8;let y = ((opcode & 0x00F0) >> 4) as u8;// let n = ((opcode & 0x000F) >> 4) as u8;let kk = (opcode & 0x00FF) as u8;let op_minor = (opcode & 0x000F) as u8;let addr = opcode & 0x0FFF;self.position_in_memory += 2;match opcode {0x0000 => {return;}0x00E0 => { /* CLEAR SCREEN */ }0x00EE => {self.ret();}0x1000..=0x1FFF => {self.jmp(addr);}0x2000..=0x2FFF => {self.call(addr);}0x3000..=0x3FFF => {self.se(x, kk);}0x4000..=0x4FFF => {self.sne(x, kk);}0x5000..=0x5FFF => {self.se(x, y);}0x6000..=0x6FFF => {self.ld(x, kk);}0x7000..=0x7FFF => {self.add(x, kk);}0x8000..=0x8FFF => match op_minor {0 => self.ld(x, self.registers[y as usize]),1 => self.or_xy(x, y),2 => self.and_xy(x, y),3 => self.xor_xy(x, y),4 => {self.add_xy(x, y);}_ => {todo!("opcode: {:04x}", opcode);}},_ => todo!("opcode {:04x}", opcode),}}}/// (6xkk) LD sets the value `kk` into register `vx`fn ld(&mut self, vx: u8, kk: u8) {self.registers[vx as usize] = kk;}/// (7xkk) Add sets the value `kk` into register `vx`fn add(&mut self, vx: u8, kk: u8) {self.registers[vx as usize] += kk;}fn se(&mut self, vx: u8, kk: u8) {if vx == kk {self.position_in_memory += 2;}}/// () SNE **S**tore if **n**ot **e**qualfn sne(&mut self, vx: u8, kk: u8) {if vx != kk {self.position_in_memory += 2;}}/// (1nnn) JUMP to `addr`fn jmp(&mut self, addr: u16) {self.position_in_memory = addr as usize;}/// (2nnn) CALL sub-routine at `addr`fn call(&mut self, addr: u16) {let sp = self.stack_pointer;let stack = &mut self.stack;if sp >= stack.len() {panic!("Stack overflow!")}stack[sp] = self.position_in_memory as u16;self.stack_pointer += 1;self.position_in_memory = addr as usize;}/// (00ee) RET return from the current sub-routinefn ret(&mut self) {if self.stack_pointer == 0 {panic!("Stack underflow");}self.stack_pointer -= 1;self.position_in_memory = self.stack[self.stack_pointer] as usize;}// (7xkk)fn add_xy(&mut self, x: u8, y: u8) {self.registers[x as usize] += self.registers[y as usize];// TODO: SET CARRY FLAG!!!!}fn and_xy(&mut self, x: u8, y: u8) {let x_ = self.registers[x as usize];let y_ = self.registers[y as usize];self.registers[x as usize] = x_ & y_;}fn or_xy(&mut self, x: u8, y: u8) {let x_ = self.registers[x as usize];let y_ = self.registers[y as usize];self.registers[x as usize] = x_ | y_;}fn xor_xy(&mut self, x: u8, y: u8) {let x_ = self.registers[x as usize];let y_ = self.registers[y as usize];self.registers[x as usize] = x_ ^ y_;}
}fn main() {let mut cpu = CPU {registers: [0; 16],memory: [0; 4096],position_in_memory: 0,stack: [0; 16],stack_pointer: 0,};cpu.registers[0] = 5;cpu.registers[1] = 10;//cpu.memory[0x000] = 0x21;cpu.memory[0x001] = 0x00;cpu.memory[0x002] = 0x21;cpu.memory[0x003] = 0x00;cpu.memory[0x100] = 0x80;cpu.memory[0x101] = 0x14;cpu.memory[0x102] = 0x80;cpu.memory[0x103] = 0x14;cpu.memory[0x104] = 0x00;cpu.memory[0x105] = 0xEE;cpu.run();assert_eq!(cpu.registers[0], 45);println!("5 + (10 * 2) + (10 * 2) = {}", cpu.registers[0]);
}// code result:
5 + (10 * 2) + (10 * 2) = 45
学习有关CPU和数据的最后一步是了解控制流的工作方式。在CHIP-8中,控制流的工作方式是比较寄存器中的值,然后依据结果的不同来修改 position_in_memory的值。在CPU里是没有 while 循环或 for 循环的,在编程语言中创建出这些控制流的机制是编译器开发者的艺术。
六、内存
6.2 指针

static B: [u8; 10] = [99, 97, 114, 114, 121, 116, 111, 119, 101, 108];
static C: [u8; 11] = [116, 104, 97, 110, 107, 115, 102, 105, 115, 104, 0];fn main() {let a = 42;let b = &B; let c = &C; println!("a: {}, b: {:p}, c: {:p}", a, b, c);
}
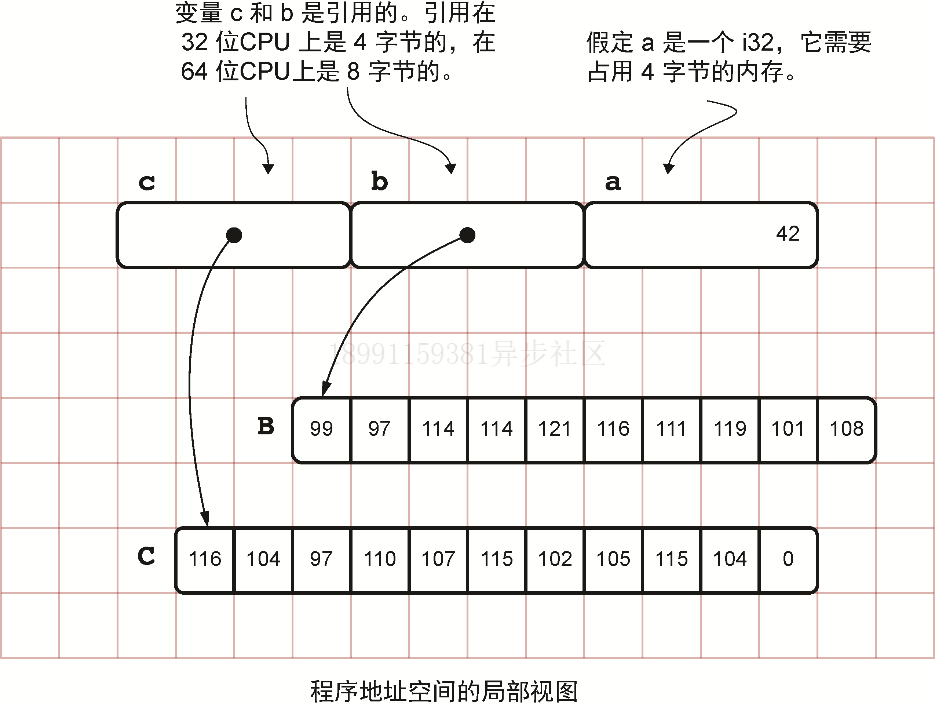
代码如下:
use std::mem::size_of;static B: [u8; 10] = [99, 97, 114, 114, 121, 116, 111, 119, 101, 108];
static C: [u8; 11] = [116, 104, 97, 110, 107, 115, 102, 105, 115, 104, 0];fn main() {let a: usize = 42; // usize的实际大小就是内存地址的宽度,而内存地址的宽度取决于编译代码时使用的CPU。所以此CPU又叫作编译目标。let b: &[u8; 10] = &B;// &[u8; 10]读作“一个10字节的数组的引用”。此数组存放在内存的静态区域中,而该引用本身(一个宽度为usize字节的指针)是存放在栈上的。let c: Box<[u8]> = Box::new(C); // Box<[u8]>类型是一个装箱的字节切片。当程序员把某个值装入一个箱子(box)中后,该值的所有权就被转移给了箱子的所有者。println!("a (an unsigned integer):");println!(" location: {:p}", &a);println!(" size: {:?} bytes", size_of::<usize>());println!(" value: {:?}", a);println!();println!("b (a reference to B):");println!(" location: {:p}", &b);println!(" size: {:?} bytes", size_of::<&[u8; 10]>());println!(" points to: {:p}", b);println!();println!("c (a box for C):");println!(" location: {:p}", &c);println!(" size: {:?} bytes", size_of::<Box<[u8]>>());println!(" points to: {:p}", c);println!();println!("B (an array of 10 bytes):");println!(" location: {:p}", &B);println!(" size: {:?} bytes", size_of::<[u8; 10]>());println!(" value: {:?}", B);println!();println!("C (an array of 11 bytes):");println!(" location: {:p}", &C);println!(" size: {:?} bytes", size_of::<[u8; 11]>());println!(" value: {:?}", C);
}// code result:
a (an unsigned integer):location: 0x7ffc7332f0f0size: 8 bytesvalue: 42b (a reference to B):location: 0x7ffc7332f0f8size: 8 bytespoints to: 0x55892149804dc (a box for C):location: 0x7ffc7332f100size: 16 bytespoints to: 0x558922f9cad0B (an array of 10 bytes):location: 0x55892149804dsize: 10 bytesvalue: [99, 97, 114, 114, 121, 116, 111, 119, 101, 108]C (an array of 11 bytes):location: 0x558921498057size: 11 bytesvalue: [116, 104, 97, 110, 107, 115, 102, 105, 115, 104, 0]
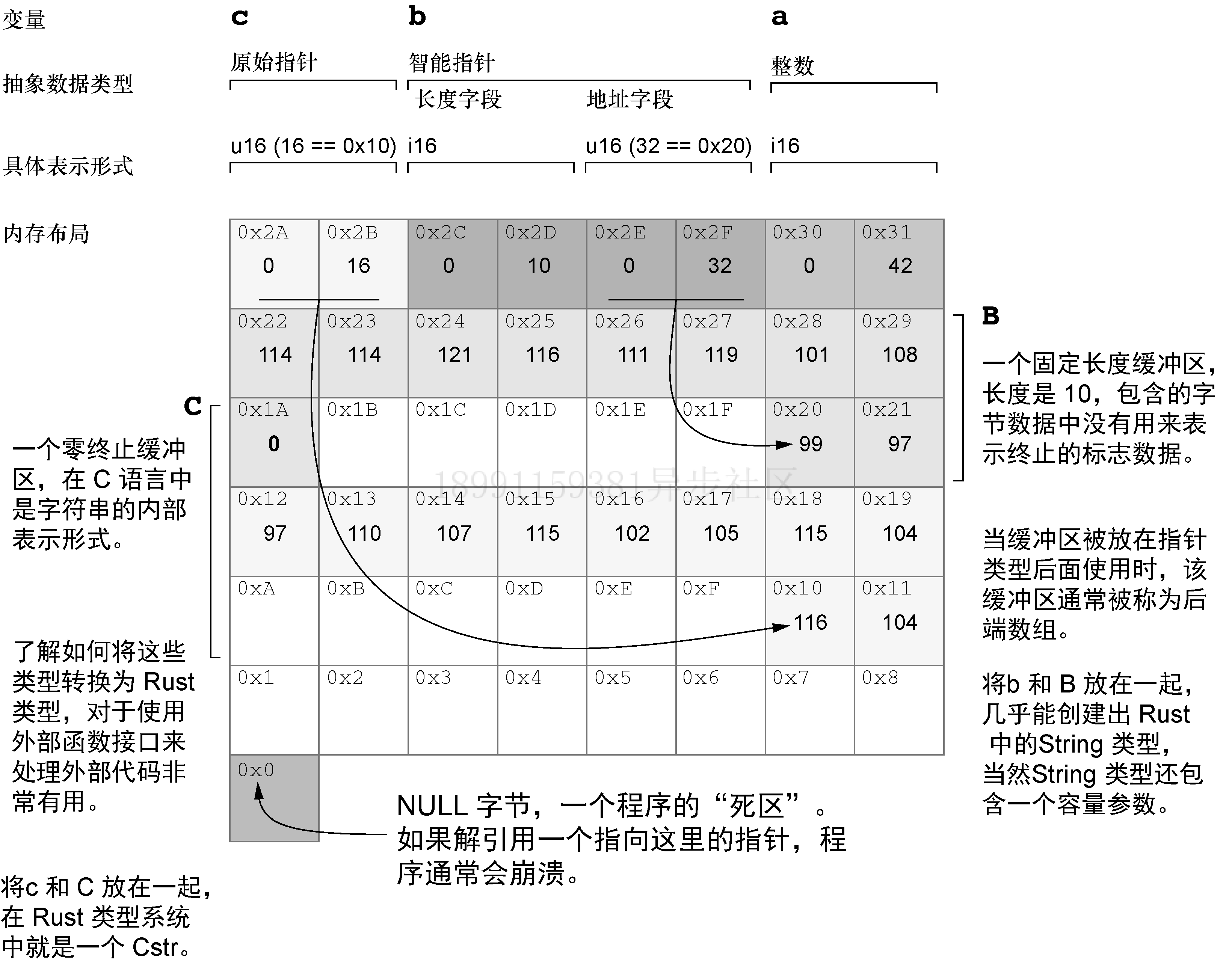
下文是智能指针 Cow 的用法:
use std::borrow::Cow; // 一种智能指针类型,能够从其指针位置读取数据而无须先复制它。
use std::ffi::CStr; // CStr是一个类似于C字符串的类型,它让Rust能够读取以0作为结束标志的字符串。
use std::os::raw::c_char; // c_char是Rust中i8类型的别名,但对于特定的平台,它可能会存在一些细微的差别。static B: [u8; 10] = [99, 97, 114, 114, 121, 116, 111, 119, 101, 108];
static C: [u8; 11] = [116, 104, 97, 110, 107, 115, 102, 105, 115, 104, 0];
fn main() {let a = 42; // 在这里引入了每个变量,在后面的println! 中才能够访问到。假如把创建b和c的两行代码放到下面的unsafe块中,那么在后面超出了作用域后,输出语句那里就访问不到了。let b: String; // String是一种智能指针类型。它包含一个指向后端数组的指针和一个用于存储其大小的字段。let c: Cow<str>; // Cow接收一个类型参数,即它所指向的数据类型。str是CStr.to_string_lossy() 的返回类型,所以放在这里是合适的。unsafe {let b_ptr = &B as *const u8 as *mut u8; // 引用不能直接转换为*mut T,而后者正是String::from_raw_parts()所需要的类型。但是,*const T可以转换为*mut T,所以就有了这个二次类型转换的语法。b = String::from_raw_parts(b_ptr, 10, 10); // String::from_raw_parts()接收3个参数,一个参数是指向字节数组的指针(*mut T),另两个是大小和容量参数。let c_ptr = &C as *const u8 as *const c_char; // 我们把一个*const u8转换为*const i8,后者就是c_char的别名。在这里,转换到i8之所以能够成功,是因为依据ASCII标准,数据一定都是小于128的。c = CStr::from_ptr(c_ptr).to_string_lossy(); // 从概念上讲,CStr::from_ptr()负责读取指针指向的数据,直到遇到0为止,然后利用读取到的结果数据生成一个Cow<str>。println!("a: {}, b: {}, c: {}", a, b, c);}
}// code result:
a: 42, b: carrytowel, c: thanksfish
free(): invalid pointer
6.2.1 原始指针
原始指针是不安全的(因为可为 NULL),其有两种:* const T 和 * mut T,彼此可自由转换。
引用(& mut T 和 &T)会被向下编译为原始指针,即不需通过 unsafe 块即可获得原始指针的性能。
fn main() {let a: i64 = 42;let a_ptr = &a as *const i64; // 将a的引用(&a) 转换为 指向i64的常量原始指针(*const i64)println!("a: {} ({:p})", a, a_ptr); // 输出a的值(42)以及它在内存中的地址
}// code result:
a: 42 (0x7fff07f217c8)
【指针】和【内存地址】有时可互换使用:
- 共同点:都是整数,用于表示虚拟内存中的位置。
- 不同点:
- 指针:总是指向 T 的起始字节,且其知道 T 类型的字节宽度。
- 内存地址:可引用内存中的任意位置。
一个 i64 是 8 bytes(64 bit,即(64/8) bytes),代码如下:
fn main() {let a: i64 = 42;let a_ptr = &a as *const i64;let a_addr: usize = unsafe {std::mem::transmute(a_ptr) // 把*const i64解释为usize类型。使用transmute()是非常不安全的,但是这让我们可以暂缓引入更多的语法。};println!("a: {} ({:p}...0x{:x})", a, a_ptr, a_addr + 7);
}// code result:
a: 42 (0x7ffd5693e388...0x7ffd5693e38f)
从底层实现上来看,引用(&T 和 &mut T)是被实现为原始指针的,但是引用有额外的保证,故应被优先考虑使用。
下文展示了原始指针的不稳定性:
fn main() {let ptr = 42 as *const Vec<String>; // 你可以安全地从任何整数值中创建出指针。很显然,一个i32不是一个Vec<String>,但在这里,Rust很乐意忽略这一点。unsafe {let new_addr = ptr.offset(4);println!("{:p} -> {:p}", ptr, new_addr);}
}// code result:
0x2a -> 0x8a

6.2.2 Rust 指针的生态系统
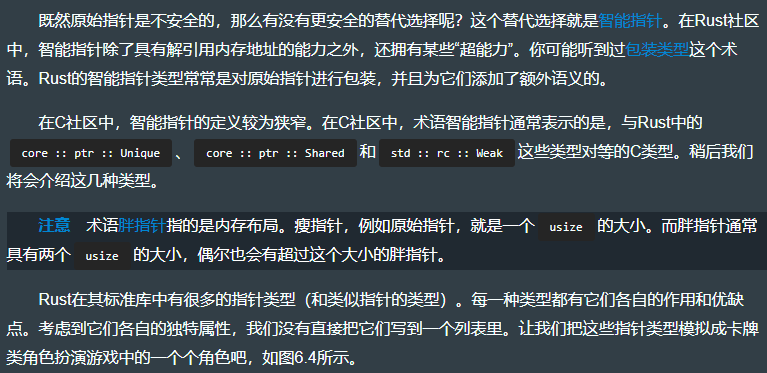
英文版如下:

中文版如下:


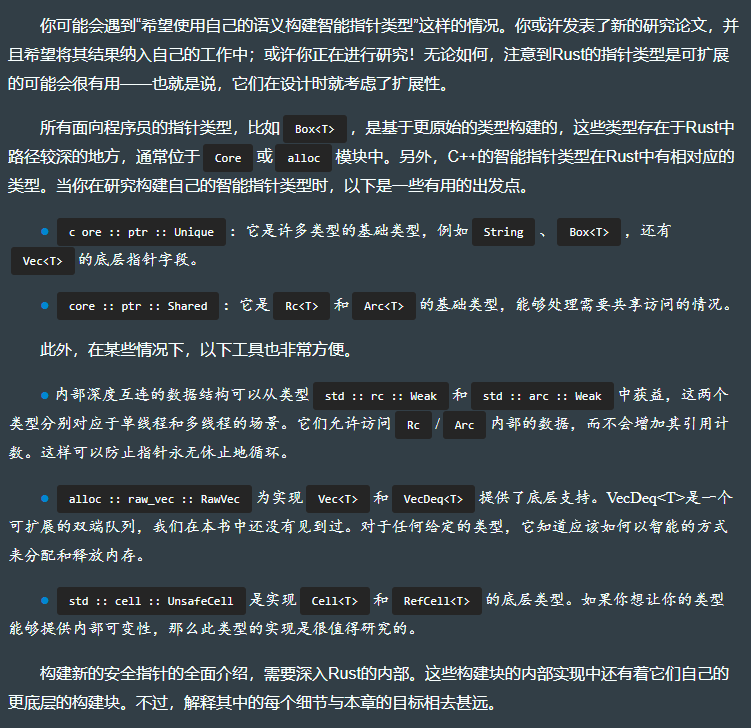
6.2.3 智能指针块构建
6.3 为程序提供存储数据的内存

6.3.1 栈


6.3.2 堆
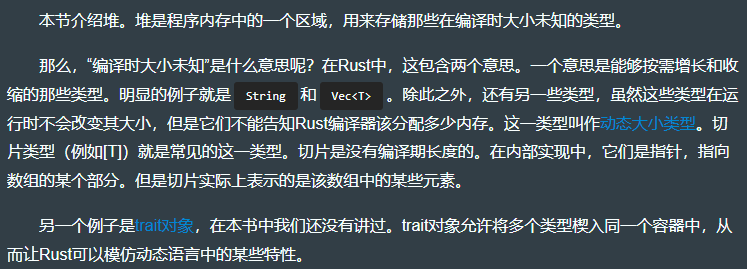
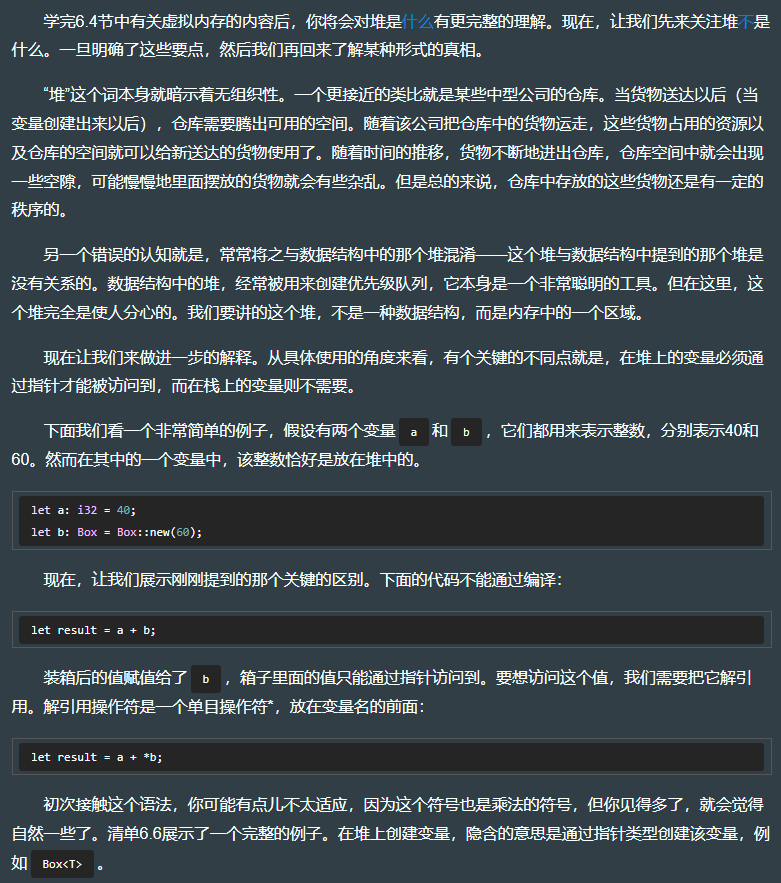
use std::mem::drop; // 手动导入drop() 到局部作用域。fn main() {let a = Box::new(1); // 在堆上分配值。let b = Box::new(1);let c = Box::new(1);let result1 = *a + *b + *c; // 单目操作符*叫作解引用操作符,它会返回箱子里面的值,result1的值为3。drop(a); // 调用drop(),会释放出这部分内存,以便留作他用。let d = Box::new(1);let result2 = *b + *c + *d;println!("{} {}", result1, result2);
}// code result:
3 3
上述代码的内存布局如下图所示:
- 其中【栈上的变量 a】其实是一个指向 Box 的指针,其占 64 bit(因为现在大多数人的电脑都是 64 bit的)即 8Bytes。而 8 Bytes(十进制) = 0x08(十六进制)。
- 则若 变量 a 的地址为 0xFFF,且 指针 a 指向的【堆上 A】的地址是 0x100。的话
- 则【栈上的变量 b】的地址是 0xFFF - 0x008 = 0xFF7。且 指针 b 指向的【堆上 B】的地址是 0x100 + 0x008 = 0x108。
- 则【栈上的变量 c】的地址是 0xFF7 - 0x008 = 0xFEF。且 指针 c 指向的【堆上 C】的地址是 0x108 + 0x008 = 0x110。
- 则【栈上的变量 result1】的地址是 0xFEF - 0x008 = 0xFE7。且 变量 result1 的值为 3。
- drop(a) 会标记栈上的 a 无效,并标记堆上的 A 无效。即变量a 的生命周期在此时结束。
- 则【栈上的变量 d】的地址是 0xFE7- 0x008 = 0xFDF。【堆上 d】的地址是重用了 【原堆上 a 的地址 0x100】。
- PS:下图左下角的地址空间范围推导过程为:因下图中最大地址是 0xFFF,故地址空间是 0xFFF - 0x000 + 1(B) = 0xF000 = 15 * 16 ^ 3 = 4096 Bytes。
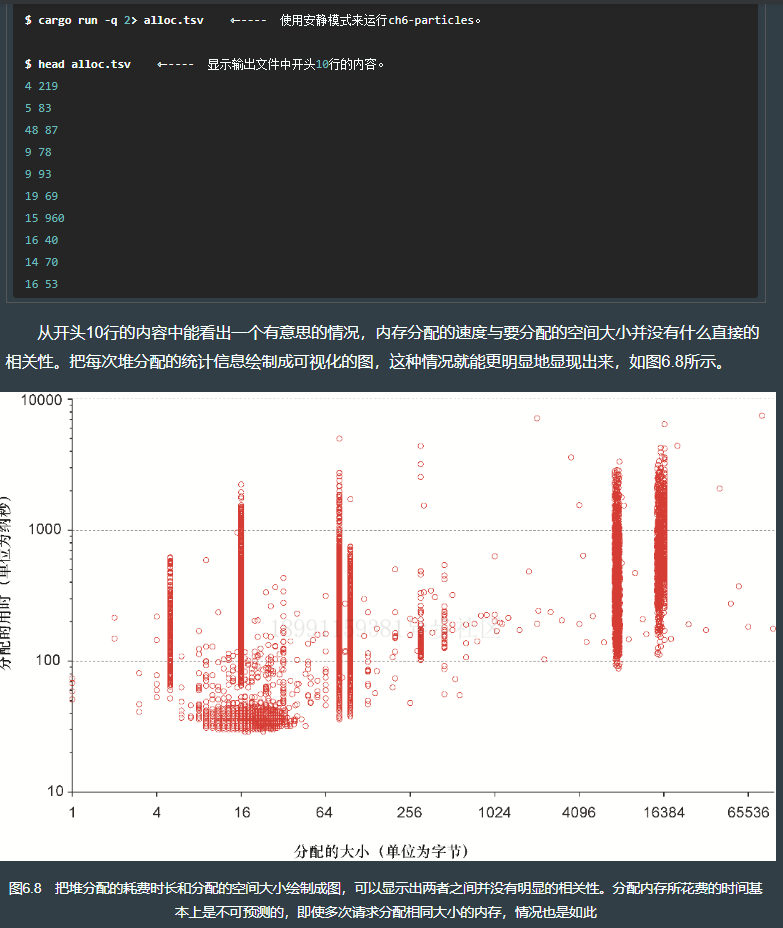
6.3.4 分析【堆】分配动态内存的速度
cd ch6/ch6-particles && cargo run 运行下述代码,得到如下效果:

6.4 虚拟内存
6.4.2 第一步:让一个进程扫描它自己的内存
从直观上来说,一个程序的内存就是一系列的字节,从O的位置开始到n的位置结束。如果一个程序使用了100 KB的RAM,那么n的值大概是100000。接下来,让我们使用示例来进行测试。
我们会创建一个小命令行程序来查看内存,开始位置为0,结束位置为10000。因为这是个很小的程序,所以它占用的内存不会超过10000字节。下面给出的这个示例程序,并不会如预期那样去执行,而会崩溃。学完本节内容后,你就会知道这个程序为什么会发生崩溃了。
fn main() {let mut n_nonzero = 0;for i in 0..10000 {let ptr = i as *const u8; // 把i转换为 *const T类型,一个u8类型的原始指针。原始指针允许程序员去查看原始内存地址。在这里,我们把每个地址视为一个单元,而不考虑实际上大部分的值都是跨越多个字节的。let byte_at_addr = unsafe { *ptr }; // 解引用指针,也就是读取地址i处的值。另一种说法是“读取此指针所指向的值”。if byte_at_addr != 0 {n_nonzero += 1;}}println!("non-zero bytes in memory: {}", n_nonzero);
}// code result:
segmentation fault
清单6.12所示程序崩溃的原因是试图去解引用一个 NULL(空)指针。当 i 的值等于 0 时,ptr 根本不可能解引用成功。顺便说一下,这也是所有原始指针解引用的操作必须放在 unsafe 块中的原因。然而 for i in 1…10000 还是会引发 segmentation fault 的错误。
static GLOBAL: i32 = 1000; // <1>fn noop() -> *const i32 {let noop_local = 12345; // <2>&noop_local as *const i32 // <3>
}fn main() {let local_str = "a"; // <4>let local_int = 123; // <4>let boxed_str = Box::new('b'); // <4>let boxed_int = Box::new(789); // <4>let fn_int = noop(); // <4>println!("GLOBAL: {:p}", &GLOBAL as *const i32);println!("local_str: {:p}", local_str as *const str);println!("local_int: {:p}", &local_int as *const i32);println!("boxed_int: {:p}", Box::into_raw(boxed_int));println!("boxed_str: {:p}", Box::into_raw(boxed_str));println!("fn_int: {:p}", fn_int);
}// code result:
GLOBAL: 0x7ff6d6ec9310
local_str: 0x7ff6d6ec9314
local_int: 0x23d492f91c
boxed_int: 0x18361b78320
boxed_str: 0x18361b78070
fn_int: 0x23d492f8ec
6.4.3 把虚拟地址 翻译为 物理地址

6.4.4 第二步:通过操作系统来扫描地址空间
在 windows 上安装 rust,cargo new ch6-meminfo-win 新建项目,设置 Cargo.toml 如下:
[package]
name = "meminfo"
version = "0.1.0"
authors = ["Tim McNamara <author@rustinaction.com>"]
edition = "2018"[dependencies]
winapi = "0.2" # 定义了一些有用的类型别名。
kernel32-sys = "0.2" # 提供了使用KERNEL.DLL来与Windows API进行交互的功能。
main.rs 如下:
use kernel32;
use winapi;use winapi::{DWORD, // 在Rust里,这个类型叫作u32。HANDLE, // 多个内部API使用的没有关联类型的指针类型(可以接收任何类型的指针)。在Rust里,std::os::raw::c_void定义了void指针。一个HANDLE(句柄)是在Windows中指向一些不透明资源的指针。LPVOID,PVOID, // 在Windows里,数据类型的名称常常会用一个前缀代表类型的缩写。P代表指针,LP代表长指针(例如64位的指针)。SIZE_T, // LPSYSTEM_INFO, // 指向一个SYSTEM_INFO结构体的指针。SYSTEM_INFO, // 在Windows内部定义的一些结构体。MEMORY_BASIC_INFORMATION as MEMINFO,
};
fn main() { // 这些变量的初始化代码会放在unsafe块中。为了使其在外部作用域中能够被访问到,所以需要在这里定义。let this_pid: DWORD;let this_proc: HANDLE;let min_addr: LPVOID;let max_addr: LPVOID;let mut base_addr: PVOID;let mut proc_info: SYSTEM_INFO;let mut mem_info: MEMORY_BASIC_INFORMATION;const MEMINFO_SIZE: usize = std::mem::size_of::<MEMINFO>();unsafe { // 这个代码块保证了所有内存被初始化。base_addr = std::mem::zeroed();proc_info = std::mem::zeroed();mem_info = std::mem::zeroed();}unsafe { // 在这个代码块中,是发起系统调用的代码。this_pid = kernel32::GetCurrentProcessId();this_proc = kernel32::GetCurrentProcess();kernel32::GetSystemInfo( // 此函数没有使用返回值,而是使用了C的惯用法,来把运行结果提供给调用方。我们提供一个指向某个预定义结构体的指针,然后在函数返回后读取该结构体的新值,以查看其结果。&mut proc_info as LPSYSTEM_INFO);};min_addr = proc_info.lpMinimumApplicationAddress; // 为了方便,此处重命名了这些变量。max_addr = proc_info.lpMaximumApplicationAddress;println!("{:?} @ {:p}", this_pid, this_proc);println!("{:?}", proc_info);println!("min: {:p}, max: {:p}", min_addr, max_addr);loop { // 这个循环完成了扫描地址空间的工作。let rc: SIZE_T = unsafe {kernel32::VirtualQueryEx( // 这个系统调用,提供了这个正在运行的程序的内存地址空间中一个指定段的信息,此指定段的起始位置的地址是base_addr。this_proc, base_addr,&mut mem_info, MEMINFO_SIZE as SIZE_T)};if rc == 0 {break}println!("{:#?}", mem_info);base_addr = ((base_addr as u64) + mem_info.RegionSize) as PVOID;}
}// code result:
MEMORY_BASIC_INFORMATION { ⇽---- 这个结构体是在Windows API中定义的。BaseAddress: 0x00007ffbe8d9b000,AllocationBase: 0x0000000000000000,AllocationProtect: 0, ⇽---- 这些字段是Windows API中定义的枚举体,它们是用整数来表示的。可以把它们解码为枚举体的变体名,但是如果不向此清单中添加额外的代码,就无法使用这些变体名。RegionSize: 17568124928,State: 65536,Protect: 1,Type: 0
}
MEMORY_BASIC_INFORMATION {BaseAddress: 0x00007ffffffe0000,AllocationBase: 0x00007ffffffe0000,AllocationProtect: 2,RegionSize: 65536,State: 8192,Protect: 1,Type: 131072
6.4.5 第三步:读取和写入进程内存中的字节数据
操作系统提供了用于读取和写入内存的工具,甚至在其他程序中也可以完成。这是多种工具程序都会用到的一种基础技术,其中包括即时编译器(JIT)、程序调试器,还有帮助人们在游戏中"作弊”的程序。在Windows中,这个过程一般来说看起来像下面这个 Rust 风格的伪代码:
let pid = some_process_id;
OpenProcess(pid);loop address space {*call* VirtualQueryEx() to access the next memory segment*scan* the segment by calling ReadProcessMemory(),looking for a selected pattern*call* WriteProcessMemory() with the desired value
}
Linux使用 process_vm_readv() 和 process_vm_writev() 提供了一个更简单的API。它们的功能类似于 Windows中的 ReadProcessMemory() 和 writeProcessMemory()
七、文件和存储
7.2 serde 与 bincode 序列化
源码地址为 git clone https://github.com/rust-in-action/code rust-in-action && cd rust-in-action/ch7/ch7-serde-eg。
若想自己创建项目,可设置 Cargo.toml 如下:
[package]
name = "ch7-serde-eg"
version = "0.1.0"
authors = ["Tim McNamara <author@rustinaction.com>"]
edition = "2021"[dependencies]
bincode = "1"
serde = "1"
serde_cbor = "0.8"
serde_derive = "1"
serde_json = "1"
use bincode::serialize as to_bincode; // <1>
use serde_cbor::to_vec as to_cbor; // <1>
use serde_derive::Serialize;
use serde_json::to_string as to_json; // <1>#[derive(Serialize)] // 这会让serde_derive软件包来自行编写必要的代码,用来执行在内存中的City和磁盘中的City的转换。
struct City {name: String,population: usize,latitude: f64,longitude: f64,
}fn main() {let calabar = City {name: String::from("Calabar"),population: 470_000,latitude: 4.95,longitude: 8.33,};let as_json = to_json(&calabar).unwrap(); // <3>let as_cbor = to_cbor(&calabar).unwrap(); // <3>let as_bincode = to_bincode(&calabar).unwrap(); // <3>println!("json:\n{}\n", &as_json);println!("cbor:\n{:?}\n", &as_cbor);println!("bincode:\n{:?}\n", &as_bincode);println!("json (as UTF-8):\n{}\n", String::from_utf8_lossy(as_json.as_bytes()));println!("cbor (as UTF-8):\n{:?}\n", String::from_utf8_lossy(&as_cbor));println!("bincode (as UTF-8):\n{:?}\n", String::from_utf8_lossy(&as_bincode));
}// code result:
json:
{"name":"Calabar","population":470000,"latitude":4.95,"longitude":8.33}cbor:
[164, 100, 110, 97, 109, 101, 103, 67, 97, 108, 97, 98, 97, 114, 106, 112, 111, 112, 117, 108, 97, 116, 105, 111, 110, 26, 0, 7, 43, 240, 104, 108, 97, 116, 105, 116, 117, 100, 101, 251, 64, 19, 204, 204, 204, 204, 204, 205, 105, 108, 111, 110, 103, 105, 116, 117, 100, 101, 251, 64, 32, 168, 245, 194, 143, 92, 41]bincode:
[7, 0, 0, 0, 0, 0, 0, 0, 67, 97, 108, 97, 98, 97, 114, 240, 43, 7, 0, 0, 0, 0, 0, 205, 204, 204, 204, 204, 204, 19, 64, 41, 92, 143, 194, 245, 168, 32, 64]json (as UTF-8):
{"name":"Calabar","population":470000,"latitude":4.95,"longitude":8.33}cbor (as UTF-8):
"�dnamegCalabarjpopulation\u{1a}\0\u{7}+�hlatitude�@\u{13}������ilongitude�@ ��\u{8f}\\)"bincode (as UTF-8):
"\u{7}\0\0\0\0\0\0\0Calabar�+\u{7}\0\0\0\0\0������\u{13}@)\\���� @"
7.3 实现一个 hexdump
首先从原始字符串中读取,程序如下:
use std::io::prelude::*; // prelude导入了在I/O操作中常用的一些trait,例如Read和Write。const BYTES_PER_LINE: usize = 16;
// 当你使用原始字符串字面量(raw string literal)来构建多行的字符串字面量时,双引号是不需要转义的(注意这里的r前缀和#分隔符)。
// 额外的那个b前缀表示, 应该把这里的字面量数据视为字节数据(&[u8]),而不是UTF-8文本数据(&str)。
const INPUT: &'static [u8] = br#"
fn main() {println!("Hello, world!");
}"#;fn main() -> std::io::Result<()> {let mut buffer: Vec<u8> = vec!(); INPUT.read_to_end(&mut buffer)?; let mut position_in_input = 0;for line in buffer.chunks(BYTES_PER_LINE) {print!("[0x{:08x}] ", position_in_input); // 输出当前位置的信息,最多8位,不足8位则在左侧用零填充。如[0x00000000]for byte in line {print!("{:02x} ", byte); // 如 0a 66 6e 20 6d 61 69}println!();position_in_input += BYTES_PER_LINE;}Ok(())
}// code result:
[0x00000000] 0a 66 6e 20 6d 61 69 6e 28 29 20 7b 0a 20 20 20
[0x00000010] 20 70 72 69 6e 74 6c 6e 21 28 22 48 65 6c 6c 6f
[0x00000020] 2c 20 77 6f 72 6c 64 21 22 29 3b 0a 7d
其次从文件中读取,程序如下:
use std::env;
use std::fs::File;
use std::io::prelude::*;
const BYTES_PER_LINE: usize = 16; // <1>fn main() {let arg1 = env::args().nth(1);let fname = arg1.expect("usage: fview FILENAME");let mut f = File::open(&fname).expect("Unable to open file.");let mut pos = 0;let mut buffer = [0; BYTES_PER_LINE];while let Ok(_) = f.read_exact(&mut buffer) {print!("[0x{:08x}] ", pos);for byte in &buffer {match *byte {0x00 => print!(". "),0xff => print!("## "),_ => print!("{:02x} ", byte),}}println!("");pos += BYTES_PER_LINE;}
}// code result:
y% echo abcabcabcabcabcabcabcabcabcabcabcabc > d.txt
y% cargo run d.txt
[0x00000000] 61 62 63 61 62 63 61 62 63 61 62 63 61 62 63 61
[0x00000010] 62 63 61 62 63 61 62 63 61 62 63 61 62 63 61 62
7.4 操作文件
7.4.1 打开文件
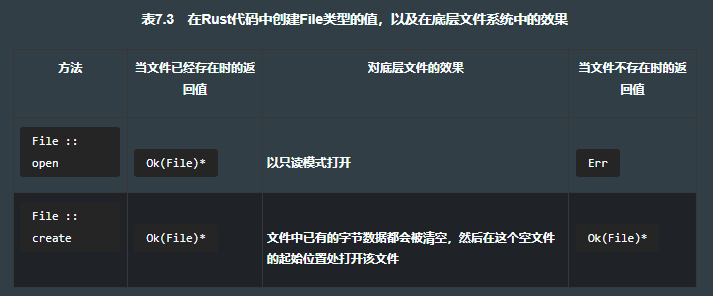
如果需要更多的控制权限,可以使用std::fs::OpenOptions。它提供了必要的选项,可以根据任何预期的应用情况来调整。清单7.16给出了一个很好的示例,在此代码中使用了 append(追加) 模式。此应用程序需要文件是可读可写的,而且如果文件不存在,它就会创建出该文件。清单7.5摘自清单7.16,展示了使用std::fs::OpenOptions创建一个可写的文件,并且打开文件时不会清空文件内容。
let f = OpenOptions::new() // 建造者模式例子。每个方法都会返回一个OpenOptions结构体的新实例,并且附带相关选项的集合。.read(true) // 为读取而打开文件。.write(true) // 开启写入。这行代码不是必需的,因为后面的append隐含了写入的选项。.create(true) // 如果在path处的文件不存在,则创建一个文件出来。.append(true) // 不会删除已经写入磁盘中的任何内容。.open(path)?; // 打开在path处的文件,然后解包装中间产生的Result。
7.4.2 用 std::fs::Path 交互
处理文件就用专业的 Path 包,而不要用 String 包,防止意想不到的麻烦,例如下文代码中 x 为 Some(“”):
fn main() {let hello = String::from("/tmp/ hello.txt");let x = hello.split("/").nth(0);let y = hello.split("/").nth(1);let z = hello.split("/").nth(2);println!("{:?}, {:?}, {:?}", x, y, z);
} // code result:
Some(""), Some("tmp"), Some(" hello.txt")
7.5 基于 append 模式实现 kv数据库
目标是,通过 append 模式,使 kv 的数据永不丢失或损坏。
7.5.1 kv 模型
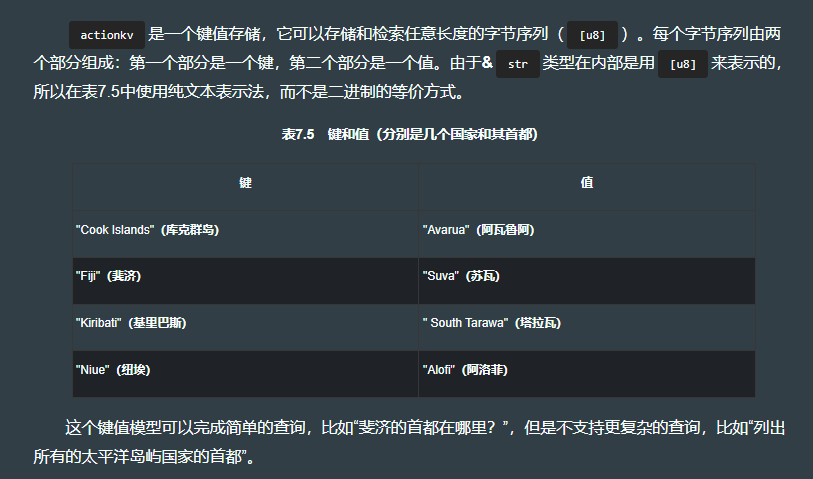
7.5.2 命令行接口
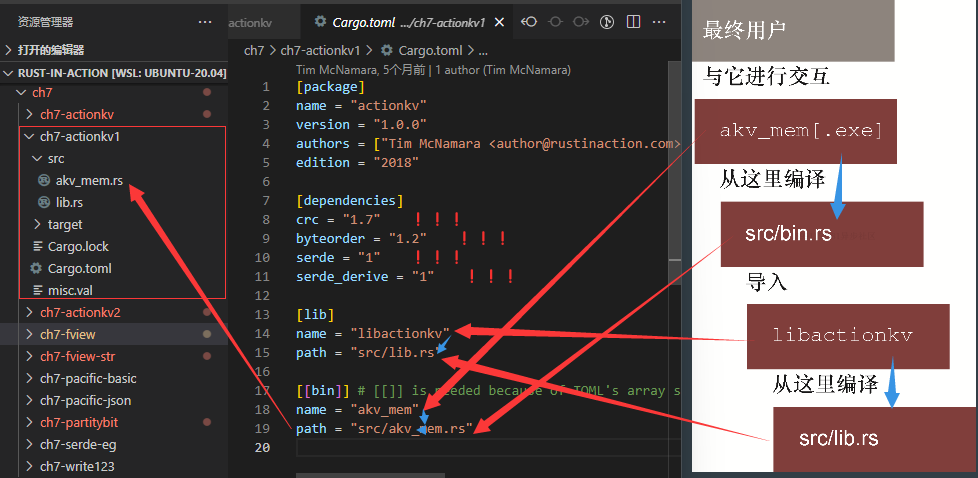
cargo new --lib actionkv
touch src/akv_mem.rstree # 输出如下:
├──src
│ ├──akv_mem.rs
│ └──lib.rs
└──Cargo.toml
设置 Cargo.toml 如下:
[package]
name = "actionkv"
version = "0.1.0"
edition = "2021"# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html[dependencies]
byteorder = "1.2" # 使用额外的trait扩展了许多Rust类型,让它们能够以可重复的、易于使用的方式被写入磁盘和读回到程序中。
crc = "1.7" # 校验[lib]
name = "libactionkv" # Cargo.toml中的这个分段,为你将要构建出的库给出一个名字。注意,一个crate中只可以有一个库。
path = "src/lib.rs"[[bin]] # [[bin]]分段可以有多个,定义了将从此包中构建出的可执行文件。双方括号语法是必需的,因为它明确地将这个bin描述为一个或多个bin元素的一部分。
name = "akv_mem"
path = "src/akv_mem.rs"
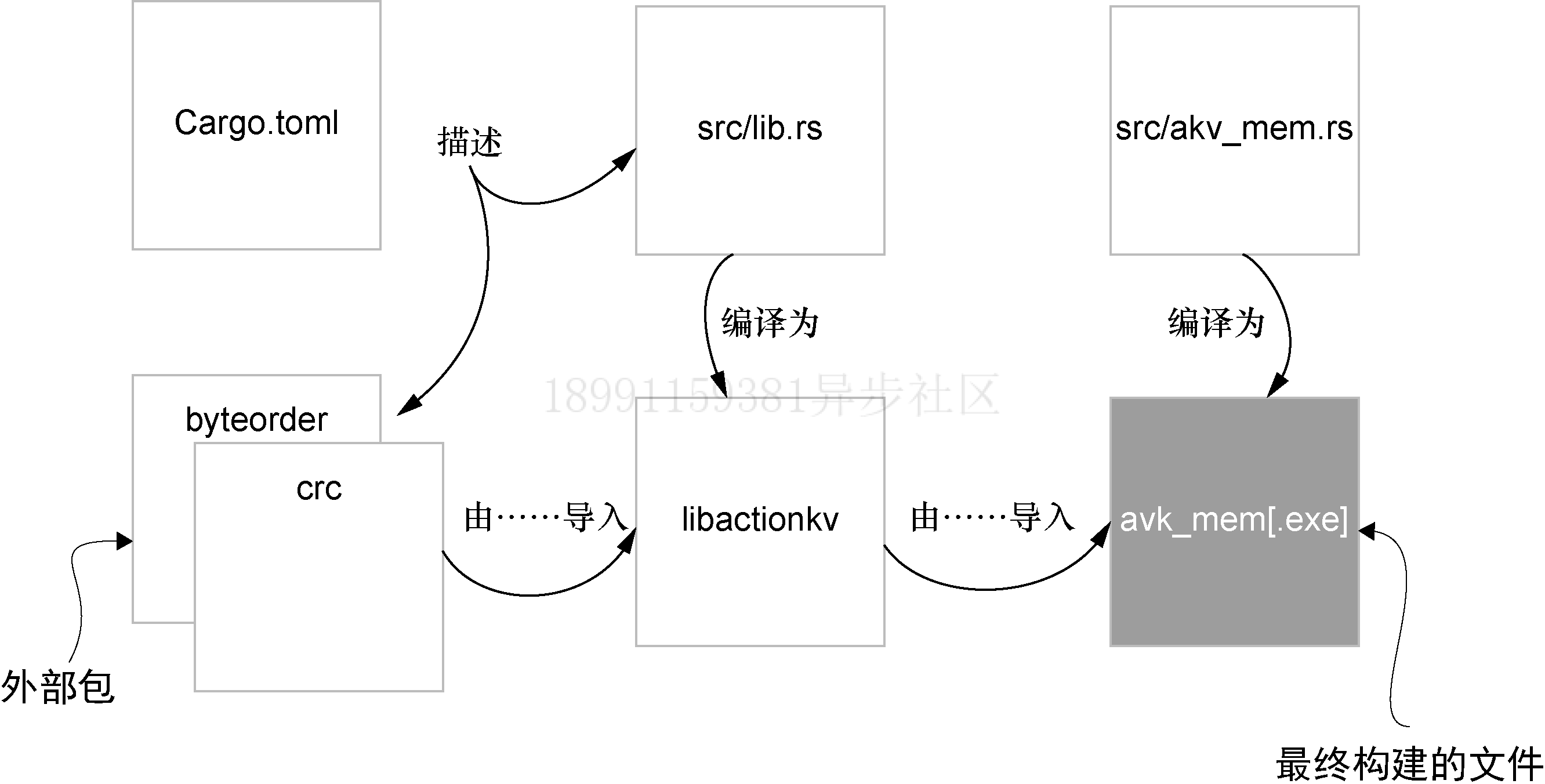
actionkv 项目最后会由多个文件组成。图7.1展示了这些文件之间的关系,以及它们如何协同工作来构建名为akv_mem的可执行文件,这个可执行文件在项目的Cargo. toml文件的分段中进行了描述。
7.6 前端代码
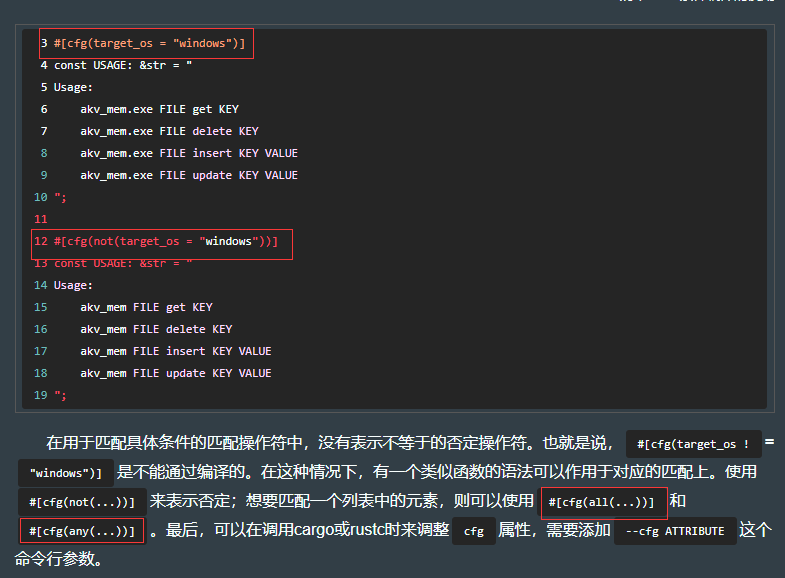
use libactionkv::ActionKV; // 尽管src/lib.rs是存在于我们的项目中的,但是在我们项目中的src/bin.rs文件,会把它视为与任何其他的包一样,同等对待。#[cfg(target_os = "windows")] // 此处的cfg属性注解,可以让Windows用户在此应用的帮助文档中看到正确的文件扩展名。这个属性注解将会在后文中进行讲解。
const USAGE: &str = "
Usage:akv_mem.exe FILE get KEYakv_mem.exe FILE delete KEYakv_mem.exe FILE insert KEY VALUEakv_mem.exe FILE update KEY VALUE
";#[cfg(not(target_os = "windows"))]
const USAGE: &str = "
Usage:akv_mem FILE get KEYakv_mem FILE delete KEYakv_mem FILE insert KEY VALUEakv_mem FILE update KEY VALUE
";fn main() {let args: Vec<String> = std::env::args().collect();let fname = args.get(1).expect(&USAGE);let action = args.get(2).expect(&USAGE).as_ref();let key = args.get(3).expect(&USAGE).as_ref();let maybe_value = args.get(4);let path = std::path::Path::new(&fname);let mut store = ActionKV::open(path).expect("unable to open file");store.load().expect("unable to load data");match action {"get" => match store.get(key).unwrap() {None => eprintln!("{:?} not found", key),Some(value) => println!("{:?}", value),},"delete" => store.delete(key).unwrap(),"insert" => {let value = maybe_value.expect(&USAGE).as_ref();store.insert(key, value).unwrap()}"update" => {let value = maybe_value.expect(&USAGE).as_ref();store.update(key, value).unwrap()}_ => eprintln!("{}", &USAGE),}
}
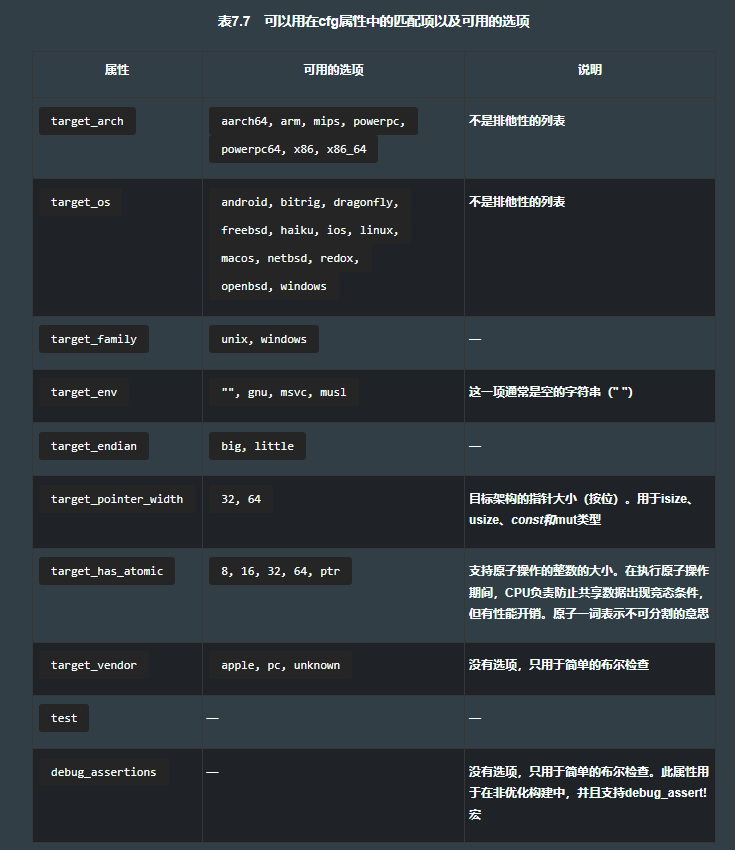
7.6.1 用条件编译定制要编译的内容
7.7 核心:LIBACTIONKV 包
在7.6节中构建的命令行应用程序,把具体的工作分派给了 libactionkv::ActionKV。结构体 ActionkV 负责管理与文件系统的交互,以及编码和解码来自磁盘中的格式数据。图7.2描述了这些关系。
7.7.1 初始化 ActionKV 结构体
use std::collections::HashMap;
use std::fs::{File, OpenOptions};
use std::io;
use std::io::prelude::*;
use std::io::{BufReader, BufWriter, SeekFrom};
use std::path::Path;use byteorder::{LittleEndian, ReadBytesExt, WriteBytesExt};
use crc::crc32;
use serde_derive::{Deserialize, Serialize};type ByteString = Vec<u8>;
type ByteStr = [u8];#[derive(Debug, Serialize, Deserialize)] // 让编译器自动生成序列化的代码,以便将KeyValuePair(键值对)的数据写入磁盘。
pub struct KeyValuePair {pub key: ByteString,pub value: ByteString,
}#[derive(Debug)]
pub struct ActionKV {f: File,pub index: HashMap<ByteString, u64>,
}impl ActionKV {pub fn open(path: &Path) -> io::Result<Self> {let f = OpenOptions::new().read(true).write(true).create(true).append(true).open(path)?;let index = HashMap::new();Ok(ActionKV { f, index })}fn process_record<R: Read>(// <1>f: &mut R,) -> io::Result<KeyValuePair> {let saved_checksum = f.read_u32::<LittleEndian>()?;let key_len = f.read_u32::<LittleEndian>()?;let val_len = f.read_u32::<LittleEndian>()?;let data_len = key_len + val_len;let mut data = ByteString::with_capacity(data_len as usize);{f.by_ref() // <2>.take(data_len as u64).read_to_end(&mut data)?;}debug_assert_eq!(data.len(), data_len as usize);let checksum = crc32::checksum_ieee(&data);if checksum != saved_checksum {panic!("data corruption encountered ({:08x} != {:08x})",checksum, saved_checksum);}let value = data.split_off(key_len as usize);let key = data;Ok(KeyValuePair { key, value })}pub fn seek_to_end(&mut self) -> io::Result<u64> {self.f.seek(SeekFrom::End(0))}pub fn load(&mut self) -> io::Result<()> {let mut f = BufReader::new(&mut self.f);loop {let current_position = f.seek(SeekFrom::Current(0))?;let maybe_kv = ActionKV::process_record(&mut f);let kv = match maybe_kv {Ok(kv) => kv,Err(err) => {match err.kind() {io::ErrorKind::UnexpectedEof => {// <3>break;}_ => return Err(err),}}};self.index.insert(kv.key, current_position);}Ok(())}pub fn get(&mut self, key: &ByteStr) -> io::Result<Option<ByteString>> {// <4>let position = match self.index.get(key) {None => return Ok(None),Some(position) => *position,};let kv = self.get_at(position)?;Ok(Some(kv.value))}pub fn get_at(&mut self, position: u64) -> io::Result<KeyValuePair> {let mut f = BufReader::new(&mut self.f);f.seek(SeekFrom::Start(position))?;let kv = ActionKV::process_record(&mut f)?;Ok(kv)}pub fn find(&mut self, target: &ByteStr) -> io::Result<Option<(u64, ByteString)>> {let mut f = BufReader::new(&mut self.f);let mut found: Option<(u64, ByteString)> = None;loop {let position = f.seek(SeekFrom::Current(0))?;let maybe_kv = ActionKV::process_record(&mut f);let kv = match maybe_kv {Ok(kv) => kv,Err(err) => {match err.kind() {io::ErrorKind::UnexpectedEof => {// <3>break;}_ => return Err(err),}}};if kv.key == target {found = Some((position, kv.value));}// important to keep looping until the end of the file,// in case the key has been overwritten}Ok(found)}pub fn insert(&mut self, key: &ByteStr, value: &ByteStr) -> io::Result<()> {let position = self.insert_but_ignore_index(key, value)?;self.index.insert(key.to_vec(), position);Ok(())}pub fn insert_but_ignore_index(&mut self, key: &ByteStr, value: &ByteStr) -> io::Result<u64> {let mut f = BufWriter::new(&mut self.f);let key_len = key.len();let val_len = value.len();let mut tmp = ByteString::with_capacity(key_len + val_len);for byte in key {tmp.push(*byte);}for byte in value {tmp.push(*byte);}let checksum = crc32::checksum_ieee(&tmp);let next_byte = SeekFrom::End(0);let current_position = f.seek(SeekFrom::Current(0))?;f.seek(next_byte)?;f.write_u32::<LittleEndian>(checksum)?;f.write_u32::<LittleEndian>(key_len as u32)?;f.write_u32::<LittleEndian>(val_len as u32)?;f.write_all(&tmp)?;Ok(current_position)}#[inline]pub fn update(&mut self, key: &ByteStr, value: &ByteStr) -> io::Result<()> {self.insert(key, value)}#[inline]pub fn delete(&mut self, key: &ByteStr) -> io::Result<()> {self.insert(key, b"")}
}
7.7.2 处理单条记录
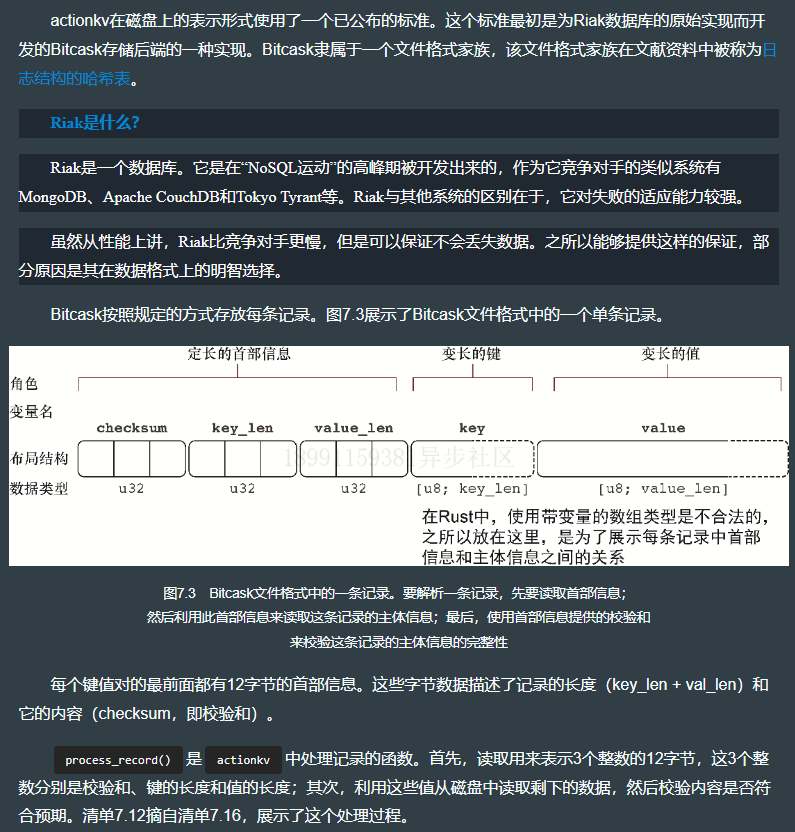
处理代码详见上节的 fn process_record() 函数。
7.7.3 以确定的字节顺序将多字节二进制数据写入磁盘
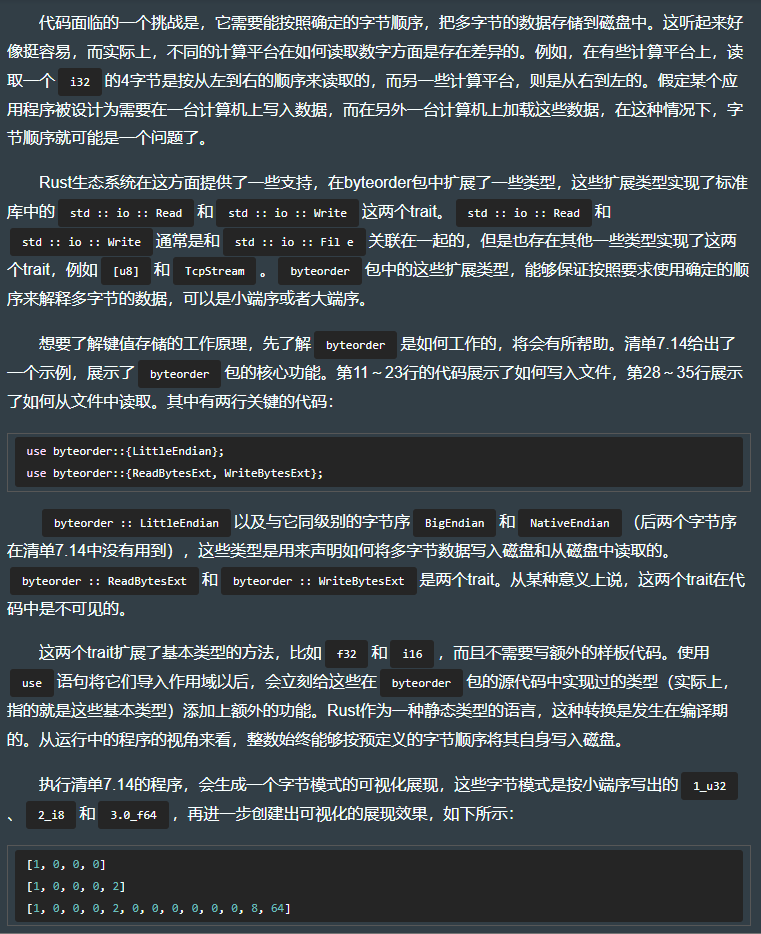
use std::io::Cursor; // 因为文件支持seek(),即拥有向前或者向后移动到不同的位置上的能力,要让Vec<T> 能够模拟文件,必须要额外做一些事情。而io::Cursor就是做这个的,它使得位于内存中的Vec<T> 在行为上类似于文件。
use byteorder::LittleEndian; // 这个类型在此程序中调用多个read_*() 和write_*()方法时,作为这些方法的类型参数来使用。
use byteorder::{ReadBytesExt, WriteBytesExt}; // 这两个trait提供了read_*() 和write_*()方法。fn write_numbers_to_file() -> (u32, i8, f64) {let mut w = vec![]; // 这个变量名w是writer的缩写。let one: u32 = 1;let two: i8 = 2;let three: f64 = 3.0;w.write_u32::<LittleEndian>(one).unwrap(); // 把值写入“磁盘”。这些方法会返回io::Result,在这里我们使用简单处理,直接把它给“吞掉了”,因为除非运行该程序的计算机出现严重问题,否则这些方法不会失败。println!("{:?}", &w);w.write_i8(two).unwrap(); // 单字节的类型i8和u8,显然,因为它们是单字节类型,所以不会接收字节序的参数。println!("{:?}", &w);w.write_f64::<LittleEndian>(three).unwrap();println!("{:?}", &w);(one, two, three)
}fn read_numbers_from_file() -> (u32, i8, f64) {let mut r = Cursor::new(vec![1, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 8, 64]);let one_ = r.read_u32::<LittleEndian>().unwrap();let two_ = r.read_i8().unwrap();let three_ = r.read_f64::<LittleEndian>().unwrap();(one_, two_, three_)
}fn main() {let (one, two, three) = write_numbers_to_file();let (one_, two_, three_) = read_numbers_from_file();assert_eq!(one, one_);assert_eq!(two, two_);assert_eq!(three, three_);
}
7.7.4 用校验和验证 I/O 错误

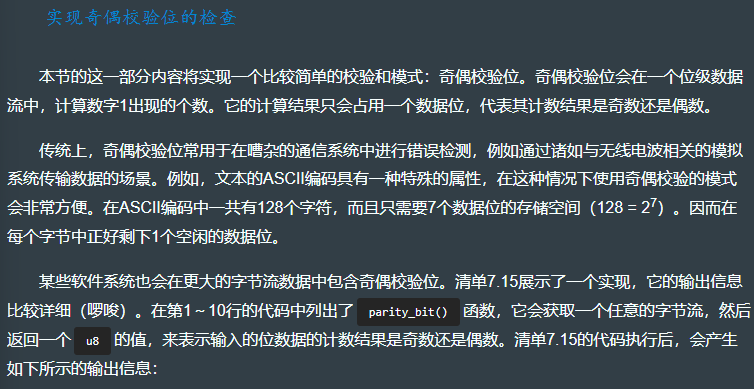
fn parity_bit(bytes: &[u8]) -> u8 {// 获取一个字节切片作为参数bytes,并返回一个单字节作为输出。此函数可以很容易地返回一个布尔值,但是在这里返回u8,可以让这个返回结果在之后能够移位到某个期望的位置上。let mut n_ones: u32 = 0;for byte in bytes {let ones = byte.count_ones(); // Rust的所有整数类型,都配有count_ones() 方法和count_zeros() 方法。n_ones += ones;println!("{} (0b{:08b}) has {} one bits", byte, byte, ones);}(n_ones % 2 == 0) as u8 // 有多种方法可以用来优化这个函数。一种很简单的方法就是,可以硬编码一个类型为const [u8; 256]的数组,数组中的0和1与预期的结果相对应,然后用每个字节对此数组进行索引。
}fn main() {let abc = b"abc";println!("input: {:?}", abc);println!("output: {:08x}", parity_bit(abc));println!();let abcd = b"abcd";println!("input: {:?}", abcd);println!("result: {:08x}", parity_bit(abcd))
}// code result:
input: [97, 98, 99]
97 (0b01100001) has 3 one bits
98 (0b01100010) has 3 one bits
99 (0b01100011) has 4 one bits
output: 00000001 // 因(3+3+4)%2 == 0 成立, 故返回output=1input: [97, 98, 99, 100]
97 (0b01100001) has 3 one bits
98 (0b01100010) has 3 one bits
99 (0b01100011) has 4 one bits
100 (0b01100100) has 3 one bits
result: 00000000 // 因(3+3+4+3)%2 == 0 不成立, 故返回output=0
7.7.8 创建 HashMap 和写入
use std::collections::HashMap;fn main() {let mut capitals = HashMap::new(); // <1>capitals.insert("Cook Islands", "Avarua");capitals.insert("Fiji", "Suva");capitals.insert("Kiribati", "South Tarawa");capitals.insert("Niue", "Alofi");capitals.insert("Tonga", "Nuku'alofa");capitals.insert("Tuvalu", "Funafuti");let tongan_capital = capitals["Tonga"]; // <2>println!("Capital of Tonga is: {}", tongan_capital);
}// code result:
Capital of Tonga is: Nuku'alofa
#[macro_use] // 把serde_json包合并到此包中,并使用它的宏。这个语法会把 json! 宏导入作用域中
extern crate serde_json; // <1>fn main() {let capitals = json!({ // json! 会接收一个JSON字面量(这个JSON字面量是由字符串组成的Rust表达式),这个宏会把JSON字面量转换成类型为serde_json::Value的Rust值,这个类型是枚举体,能够表示JSON规范中所描述的所有类型。"Cook Islands": "Avarua","Fiji": "Suva","Kiribati": "South Tarawa","Niue": "Alofi","Tonga": "Nuku'alofa","Tuvalu": "Funafuti"});println!("Capital of Tonga is: {}", capitals["Tonga"])
}
7.7.9 查询 HashMap
capitals["Tonga"] // 返回 "Nuku’alofa"。这种方式会返回该值的一个只读的引用(当处理包含字符串字面量的示例时,这里存在一定的"欺骗性”,因为它们作为引用的状态有些变形)。在Rust文档中,这是指& v,其中&表示只读引用,而v是值的类型。如果键不存在,程序将会引发 panic。capitals.get("Tonga") // 返回Some( "Nuku’alofa" ), 返回一个 Option<&V>,防止 panic。
7.7.10 HashMap 和 BTreeMap 对比
use std::collections::BTreeMap;fn main() {let mut voc = BTreeMap::new();voc.insert(3_697_915, "Amsterdam");voc.insert(1_300_405, "Middelburg");voc.insert(540_000, "Enkhuizen");voc.insert(469_400, "Delft");voc.insert(266_868, "Hoorn");voc.insert(173_000, "Rotterdam");for (guilders, kamer) in &voc {println!("{} invested {}", kamer, guilders); // 按照排序顺序输出。}print!("smaller chambers: ");for (_guilders, kamer) in voc.range(0..500_000) {// BTreeMap允许你使用范围(range)语法进行迭代,以此来选择操作全部键的一部分。print!("{} ", kamer);}println!("");
}// code result:
Rotterdam invested 173000
Hoorn invested 266868
Delft invested 469400
Enkhuizen invested 540000
Middelburg invested 1300405
Amsterdam invested 3697915
smaller chambers: Rotterdam Hoorn Delft
7.7.11 添加数据库索引
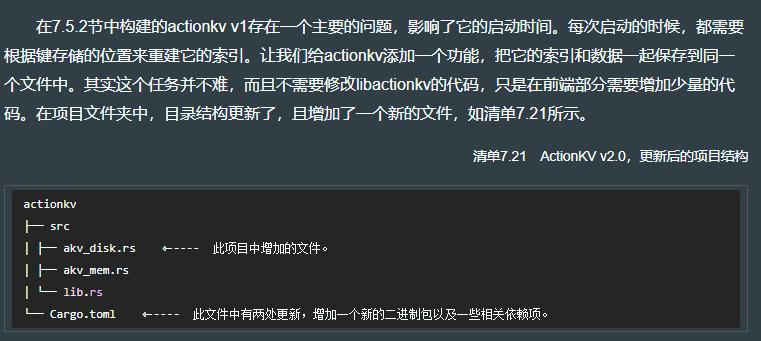
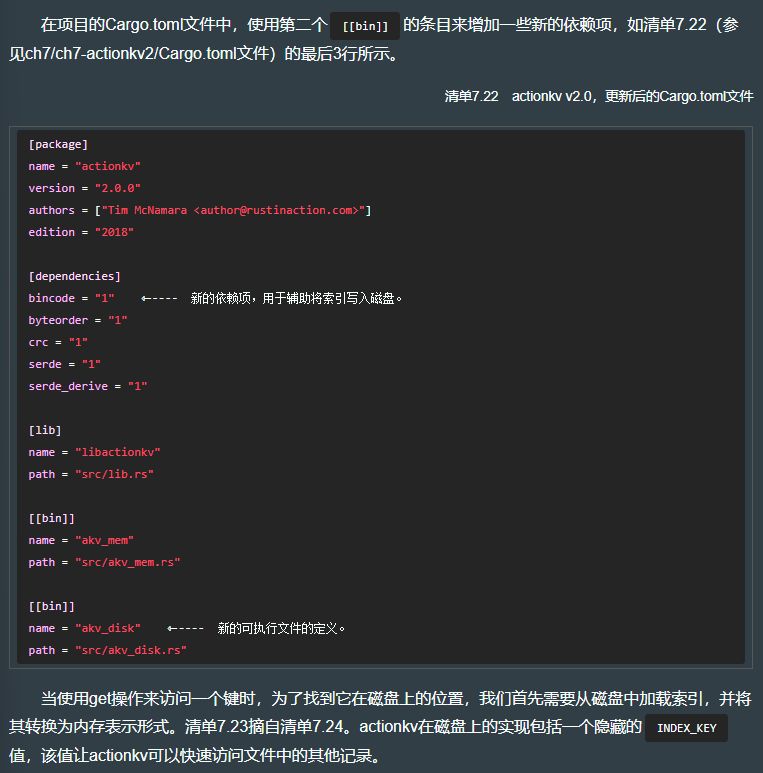
use libactionkv::ActionKV;
use std::collections::HashMap;#[cfg(target_os = "windows")]
const USAGE: &str = "
Usage:akv_disk.exe FILE get KEYakv_disk.exe FILE delete KEYakv_disk.exe FILE insert KEY VALUEakv_disk.exe FILE update KEY VALUE
";#[cfg(not(target_os = "windows"))]
const USAGE: &str = "
Usage:akv_disk FILE get KEYakv_disk FILE delete KEYakv_disk FILE insert KEY VALUEakv_disk FILE update KEY VALUE
";type ByteStr = [u8];
type ByteString = Vec<u8>;fn store_index_on_disk(a: &mut ActionKV, index_key: &ByteStr) {a.index.remove(index_key);let index_as_bytes = bincode::serialize(&a.index).unwrap();a.index = std::collections::HashMap::new();a.insert(index_key, &index_as_bytes).unwrap();
}fn main() {const INDEX_KEY: &ByteStr = b"+index";let args: Vec<String> = std::env::args().collect();let fname = args.get(1).expect(&USAGE);let action = args.get(2).expect(&USAGE).as_ref();let key = args.get(3).expect(&USAGE).as_ref();let maybe_value = args.get(4);let path = std::path::Path::new(&fname);let mut a = ActionKV::open(path).expect("unable to open file");a.load().expect("unable to load data");match action {"get" => {let index_as_bytes = a.get(&INDEX_KEY).unwrap().unwrap();let index_decoded = bincode::deserialize(&index_as_bytes);let index: HashMap<ByteString, u64> = index_decoded.unwrap();match index.get(key) {None => eprintln!("{:?} not found", key),Some(&i) => {let kv = a.get_at(i).unwrap();println!("{:?}", kv.value) <1>}}}"delete" => a.delete(key).unwrap(),"insert" => {let value = maybe_value.expect(&USAGE).as_ref();a.insert(key, value).unwrap();store_index_on_disk(&mut a, INDEX_KEY); <2>}"update" => {let value = maybe_value.expect(&USAGE).as_ref();a.update(key, value).unwrap();store_index_on_disk(&mut a, INDEX_KEY); <2>}_ => eprintln!("{}", &USAGE),}
}
本文链接:https://my.lmcjl.com/post/10631.html
4 评论