写在前面:
上一篇文章我介绍了C++该怎么学,什么是命名空间,以及C++的输入输出,
这里是传送门:http://t.csdn.cn/Oi6V8
这篇文章我们继续来学习C++的基础知识。
目录
写在前面:
1. 缺省参数
2. 函数重载
3. C++是如何支持函数重载的
写在最后:
1. 缺省参数
在学习C语言的时候,如果一个函数存在参数,
比如说这个函数:
void Func(int a) {}我们在调用的时候就一定要给他传参,
而C++提供的缺省参数,能让我们对函数的传参更加灵活,
举个例子:
#include <iostream>
using namespace std;void Func(int a = 10) {cout << a << endl;
}int main()
{Func(); //没有传参的时候,使用参数的默认值Func(20);//传参的时候,使用指定的实参return 0;
}我们给函数设置一个缺省值,这样在我们不给函数传参的时候,
函数的形参会自动使用缺省参数,而如果我们自己给函数传参,
函数形参使用的就是我们指定或者说传给他的值。
输出:
10
20那如果有多个函数参数的函数呢?
来看下一个例子:
#include <iostream>
using namespace std;void Func(int a = 10, int b = 20, int c = 30) {cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl;
}int main()
{Func();return 0;
}如果是这样的一个函数,
我们传参的时候能不能只传一部分呢?
来看例子:
#include <iostream>
using namespace std;void Func(int a = 10, int b = 20, int c = 30) {cout << "a = " << a << " ";cout << "b = " << b << " ";cout << "c = " << c << endl;
}int main()
{Func();Func(1);Func(1, 2);Func(1, 2, 3);return 0;
}输出:
a = 10 b = 20 c = 30
a = 1 b = 20 c = 30
a = 1 b = 2 c = 30
a = 1 b = 2 c = 3我们发现这样是可行的,
那如果我想要跳着传呢?
比如说这样传上面函数的参数:
Func(1, , 2);
这样是不行的,会报错,
实际上,我们只能按顺序来传,从左往右依次传参,其他都是不行的。
你可能会有疑问,为什么要这样设计,跳着传好像也没什么啊?
我也不知道为啥,因为C++祖师爷就是这么规定的,可能祖师爷不喜欢吧。
我们上述的缺省参数的用法其实叫全缺省,
我们还可以用半缺省,也就是一些参数给缺省值,一些参数不给,
举个例子:
#include <iostream>
using namespace std;//半缺省
void Func(int a, int b = 20, int c = 30) {cout << "a = " << a << " ";cout << "b = " << b << " ";cout << "c = " << c << endl;
}int main()
{Func(1);Func(1, 2);Func(1, 2, 3);return 0;
}可别搞错了哦,半缺省只是一部分参数不使用缺省参数,
而不是真的一半的参数。
这里就有有一个规定,缺省也必须是连续的,
而且缺省必须是从右往左的缺省,不然就会报错:
比如说这样子,编译器就会报错:
void Func(int a = 10, int b, int c = 30) {}这里要分清楚:
缺省,是要从右往左缺省
传参,是要从左往右传参
那为什么祖师爷要设置这样一个语法呢?
实际上,这个语法在一些场景还是非常有用的,
我们来看这样一个场景,
比如说我们要对一个栈进行初始化:
#include <iostream>
using namespace std;struct Stack {int* a;int top;int capacity;
};//初始化一个栈
void StackInit(struct Stack* ptr) {ptr->a = (int*)malloc(sizeof(int) * 4);if (ptr->a == nullptr) {perror("StackInit::malloc::fail");return;}ptr->top = 0;ptr->capacity = 4;
}int main()
{struct Stack st;StackInit(&st);//然后我们之后要对栈插入100个数据return 0;
}如果我们明知道之后就要往栈里插入100个数据,
而我们初识化默认就是初始化大小是4个整形,
那之后插入数据的过程就会频繁扩容导致不必要的损耗,
如果我们多加一个参数:
#include <iostream>
using namespace std;struct Stack {int* a;int top;int capacity;
};//初始化一个栈
void StackInit(struct Stack* ptr, int defaultCapacity = 4) {ptr->a = (int*)malloc(sizeof(int) * defaultCapacity);if (ptr->a == nullptr) {perror("StackInit::malloc::fail");return;}ptr->top = 0;ptr->capacity = defaultCapacity;
}int main()
{struct Stack st;StackInit(&st, 100);//然后我们之后要对栈插入100个数据return 0;
}这样如果我们有需要就可以直接指定开辟空间大小,
不需要的时候不传第二个参数,也能自动使用默认的大小初始化。
这个问题就很好的解决了。
这里再补充一嘴,C语言的时候我们其实通常是这样解决这种问题的:
#include <iostream>
using namespace std;#define DEFAULT_CAPACITY 100struct Stack {int* a;int top;int capacity;
};//初始化一个栈
void StackInit(struct Stack* ptr) {ptr->a = (int*)malloc(sizeof(int) * DEFAULT_CAPACITY);if (ptr->a == nullptr) {perror("StackInit::malloc::fail");return;}ptr->top = 0;ptr->capacity = DEFAULT_CAPACITY;
}int main()
{struct Stack st;StackInit(&st);//然后我们之后要对栈插入100个数据return 0;
}通过定义一个宏的形式,
这样如果要修改初识化大小,就只用修改宏定义就行,
但是这样是没有C++这种用法灵活,
如果我们要创建两个栈,一个容量100,一个容量4的时候,他就做不到了:
#include <iostream>
using namespace std;struct Stack {int* a;int top;int capacity;
};//初始化一个栈
void StackInit(struct Stack* ptr, int defaultCapacity = 4) {ptr->a = (int*)malloc(sizeof(int) * defaultCapacity);if (ptr->a == nullptr) {perror("StackInit::malloc::fail");return;}ptr->top = 0;ptr->capacity = defaultCapacity;
}int main()
{struct Stack st1;StackInit(&st1, 100);//然后我们之后要对栈插入100个数据struct Stack st2;StackInit(&st2);return 0;
}在这个场景下,使用C++就非常的舒适。
当然啦,我们也不能说C语言就不好,C语言也是有他自己独特的优势的。
这里还有一个细节要注意,
在使用缺省参数的时候,声明和定义不能都给缺省。
那是给声明还是给定义缺省值呢?
我就直接说了,只能给声明缺省值,
我来解释一下为什么,我们调用函数的时候,其实看到的就是声明,
如果需要传参就传参,如果有缺省值没传参,传的参数就自动变成缺省参数的值,
而定义不关心这些,定义只知道你一定要给我传两个参数,
所以我们只给声明缺省值。
#include <iostream>
using namespace std; struct Stack {int* a;int top;int capacity;
};//声明给缺省
void StackInit(struct Stack* ptr, int defaultCapacity = 4);int main()
{struct Stack st1;StackInit(&st1, 100);//然后我们之后要对栈插入100个数据struct Stack st2;StackInit(&st2);return 0;
}//初始化一个栈
void StackInit(struct Stack* ptr, int defaultCapacity) {ptr->a = (int*)malloc(sizeof(int) * defaultCapacity);if (ptr->a == nullptr) {perror("StackInit::malloc::fail");return;}ptr->top = 0;ptr->capacity = defaultCapacity;
}2. 函数重载
什么是函数重载,我们来看一个例子:
#include <iostream>
using namespace std;void add(int x, int y) {cout << "int" << endl;
}void add(double x, double y) {cout << "double" << endl;
}int main()
{add(1, 2);add(1.1, 2.2);return 0;
}
输出:
int
double这个就是函数重载,
我们发现这两个函数函数名相同,但是参数类型却不同,
C语言是不允许同名函数的,而C++函数重载可以支持这个语法,
在函数调用的时候,能够根据你传的参数自动匹配类型。
补充:函数重载对函数返回值没有要求,也就是返回值不同是不构成重载的。
这里我直接总结出函数重载的规则,记住就行了:
1. 在同一个作用域
2. 函数名相同
3. 参数的类型不同或者类型的个数或者顺序不同
这个时候就出现了有趣的情况,
来看例子:
#include <iostream>
using namespace std;void f() {cout << "f()" << endl;
}void f(int a = 0) {cout << "f(int a = 0)" << endl;
}int main()
{return 0;
}
你觉得这段代码构成重载吗?
答案是构成的,因为他符合重载的规则,是可以编译通过的,
但是,如果我们无参调用这个函数呢? 编译器就会直接报错:
f()不能这样子调用,因为这样存在调用歧义。
其实函数重载就这一点点知识,已经讲完了,
但是,有一个问题,为什么C语言不支持重载,而C++能支持重载呢?
C++是怎么支持重载的呢?
其实是在编译链接的过程,函数名修饰规则有所不同。
3. C++是如何支持函数重载的
这里我需要先做的一个小的铺垫内容,
我们在进行函数调用的时候,调用函数的底层是怎么样的?
比如说这一段代码:
#include <stdio.h>void f(int a) {printf("f(int a)\n");
}void f(int a, double b) {printf("f(int a, double b)\n");
}int main()
{f(1);f(1, 1.1);return 0;
}来看汇编代码:

我们可以看到,汇编实际上是使用call 指令来调用函数的,
然后在调用 jump 指令跳转到函数的定义:

这个时候我们就进入函数了:
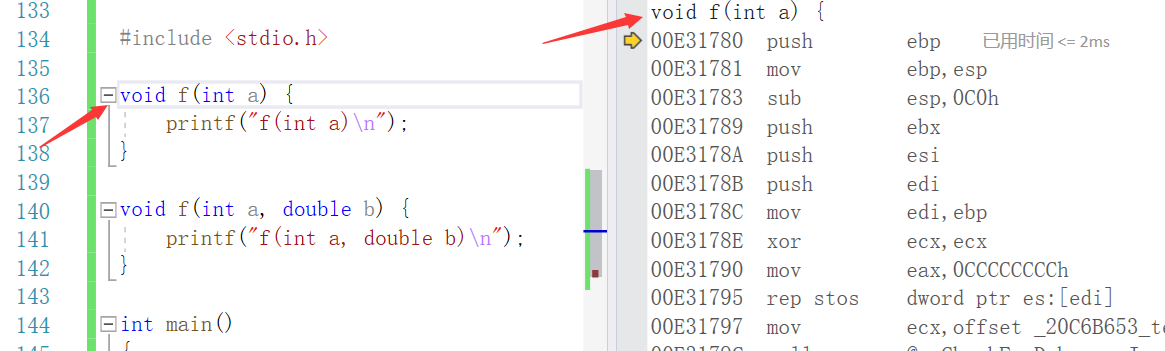 那么了解函数是怎么调用之后,我们再继续探究函数重载,
那么了解函数是怎么调用之后,我们再继续探究函数重载,
这里我采用gcc环境来进行演示,
先来看C语言,还是这段代码:
#include <stdio.h>void f(int a) {printf("f(int a)\n");
}void f(int a, double b) {printf("f(int a, double b)\n");
}int main()
{f(1);f(1, 1.1);return 0;
}这样子肯定是编译不通过的,
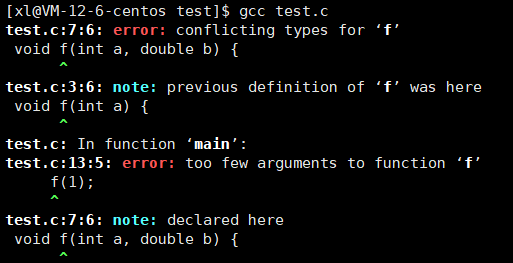
看到这个报错,conflicing types,其实就是函数名冲突了,
我们修改一下代码,让他能够编译通过:
#include <stdio.h>void f(int a, double b) {printf("f(int a, double b)\n");
}int main()
{f(1, 1.1);return 0;
}来看看他的汇编代码是怎么样的:
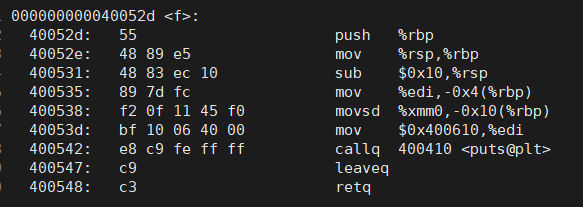
我们通过汇编可以看到,汇编代码中 call 的这个函数的函数名是 f
跟我们设置的函数名是相同的,
要是我们定义了两个函数名相同的函数,那 call < f > ,究竟call 的是谁?
那就会出现函数命名的冲突问题,
但是这些只是我们现在的推测,接下来我们看看C++的汇编是怎么操作的:
还是这段代码:
#include <stdio.h>void f(int a) {printf("f(int a)\n");
}void f(int a, double b) {printf("f(int a, double b)\n");
}int main()
{f(1);f(1, 1.1);return 0;
}但是我们换成了C++的环境(C++兼容C语言)

看看我们发现了什么?
两个同样的函数,到了C++环境下编译出来的汇编代码,他的函数名怎么这么奇怪?
上面是带有两个函数参数的函数 f (int a, double b)
我们再来看看那个带着一个函数参数的同名函数 f (int a):
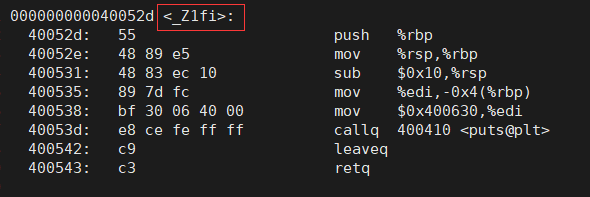
发现了吗?
他们在C++代码中函数名是相同的,
但是到了汇编代码这里,函数名却不一样了,使用 call 指令调用的函数就不一样了,
这样就没有所谓的函数名冲突的问题了,
现在你应该大致理解为什么C语言不支持同名函数了,
C语言下编译出来的汇编代码的函数名是跟C语言代码写的函数名是相同的,
就自然不支持同名函数,而C++编译出来的汇编代码展现的函数名明显不相同。
我们再仔细看看:
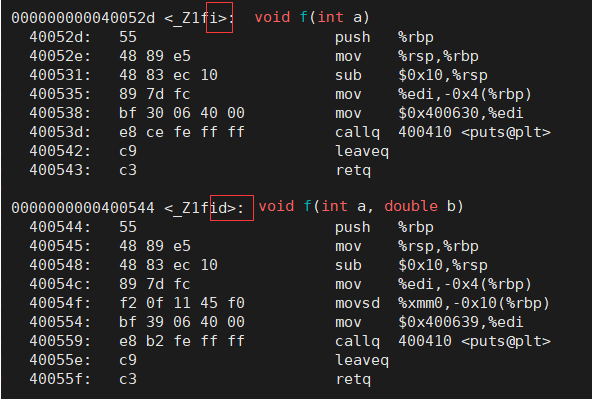
可以看到他的命名规则还是有一点讲究的。
不过他的命名规则的细节我就不深究了,最重要的是理解函数重载的底层是怎么样的。
祖师爷创造这些语法还是有迹可循的,
同时我们也能感受到,真正设计一个语言还是非常困难的,
需要对各方面的知识有着深入的理解。
这里还是补充一嘴:学习C++的时候,多学底层还是非常重要的,
我们要做到:知其然,知其所以然,这样才能体现我们学习的优势,算是我的一些感想吧。
补充:
这个时候我们又能理解一个点,
函数重载为什么不能支持函数返回值不同呢?一定要返回值相同才能重载。
我们刚刚分析的汇编代码中的函数名修饰规则,
实际上汇编在调用函数的时候,就是通过call 指令查找函数的过程,
来看这段代码:
#include <stdio.h>void func();
int func();int main()
{func();return 0;
}返回值在调用的时候不会体现,
也就是说我们在调用 func() 函数的时候,我们不知道调用的是哪一个,
如果参数不同,编译器至少知道这是两个不同的函数,
到 call 的时候才可能出现查找函数出现歧义,
而调用 func() 这个函数,编译器就不知道究竟想调用哪个函数,
所以在编译阶段就会直接报错,
所以就算把返回值加入函数名修饰规则,编译也走不到那一步。
来看一眼编译器是怎么说的:
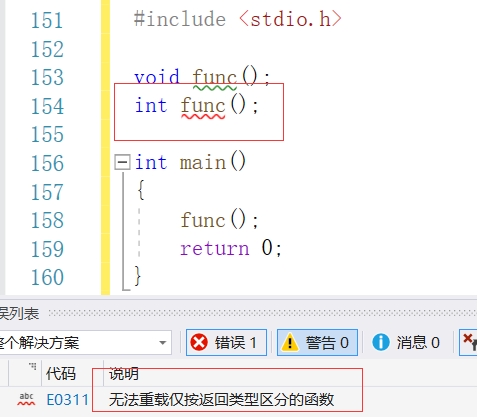
直接给你飘红了,还贴心的告诉你无法支持按返回类型区分的函数重载。
这里补充一句:
为什么我不在Windows下或者说VS下探究这个函数名修饰规则,
而是跑到了gcc/g++环境下去看呢?
因为VS他的函数名修饰规则比较复杂,没有g++那么清晰,
如果你感兴趣的话可以上网搜一下VS下的函数名修饰规则,这里就不展示了。
写在最后:
以上就是本篇文章的内容了,感谢你的阅读。
如果感到有所收获的话可以给博主点一个赞哦。
如果文章内容有遗漏或者错误的地方欢迎私信博主或者在评论区指出~
本文链接:https://my.lmcjl.com/post/11135.html
4 评论