“Training data is technology” .
数据即科技,OpenAI的联合创始人IlyaSutskever在与知名科技媒体The Verge访谈中提到。ChatGPT自发布以来热度席卷全球,一周前惊艳亮相的GPT-4更是让人感叹我们迎来了AI发展的历史性时刻。
然而我们也困惑,OpenAI为何不开源GPT-4?在我们看来,更多的奥秘或许存在于数据之中......
本文是Magic Data创始人兼CEO张晴晴博士关于数据、大模型与生成式AI的观点分享。
对话式是人机交互的关键
OpenAI成立于2015年,而Magic Data则于2016年成立。成立7年以来,Magic Data专注于对话式数据的研究。多年来,Magic Data一直被问及为什么要研究数据,而不去涉足一些更广为人知的AI领域,例如智能客服系统、无人驾驶等等。
就像在ChatGPT发布前,OpenAI一直默默深耕,直到一夜之间成为全球最热门的公司之一。Magic Data深信时间复利是实现跨越式发展的秘诀。
如今,ChatGPT让更多人认识并理解到对话式的重要性。张晴晴博士对对话式AI的理解源于18年的从业经验。在中科院工作期间,她曾帮助多家大型企业建立对话式基础系统。在这个过程中,她发现如何选择、处理数据,以及通过数据和模型的闭环耦合来认知数据,是决定人工智能能够实现多好的关键。数据对于算力算法都有直接的影响,而不仅是数据本身的价值呈现。
Magic Data坚信对话式是未来人机交互的关键。这也是为什么我们一直专注于这个领域,直到今天。
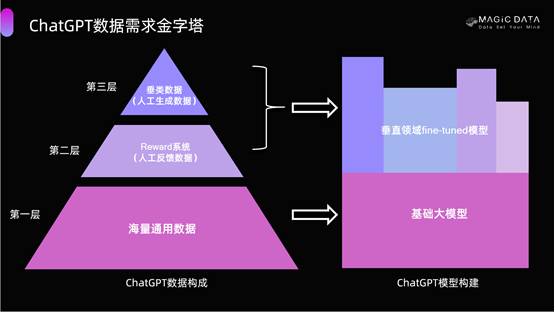
AIGC大模型的数据需求金字塔
据公开信息,ChatGPT是通过预训练加微调的方式构建的,同时引入了人类反馈强化学习机制。整个训练过程中是人机不断耦合的一个过程。在这个过程中,通过人工反馈的方式不断地调优模型,以对话式问答为核心。
构建ChatGPT这样一个大模型需要三类数据。
第一类是用于预训练的海量非结构化数据,不需要人工介入,但精准度和质量并不高。这也是因为这部分数据存在太多低质量的数据,加上大模型拥有超大参数,耗费非常多的算力,存在一定的隐患。
第二类是人机协同生产的数据,包括人工生成的问答对数据、人工对机器生成的数据进行质量排序以及机器生成的排序数据。
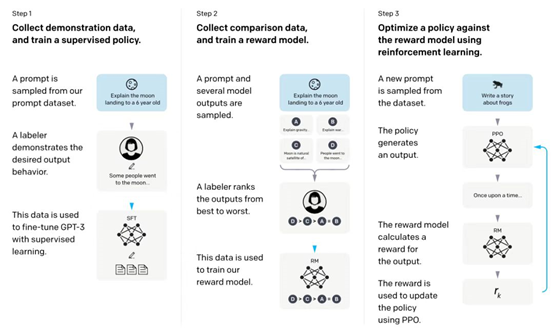
图片来源:OpenAI
第三类是知识库数据集,需要的数据量不一定很大,但需要非常精确和精准,垂域的专家知识数据将是改善ChatGPT质量的关键。
对于构建一个对话模型,张晴晴博士认为好数据需要满足三点。第一点是尽可能自然,接近人和人自然的交谈方式,而不是冷冰冰的机械式回答。第二点是领域相关性或者垂域知识的正确性,需要专家系统的介入。最重要的是数据的安全和合规性,这也是数据对于构建安全可信的ChatGPT的关键所在。
数据资源枯竭?——生成式AI数据趋势
如何满足大模型对海量训练数据的需求?根据市场研究机构的调查统计,存在于互联网上的真实数据会在2026年被消耗殆尽。在未来的AI训练数据使用中,真实数据和生成式数据都会被考虑投入使用。根据Gartner的预测显示,生成式数据的使用占比将会超过真实数据。
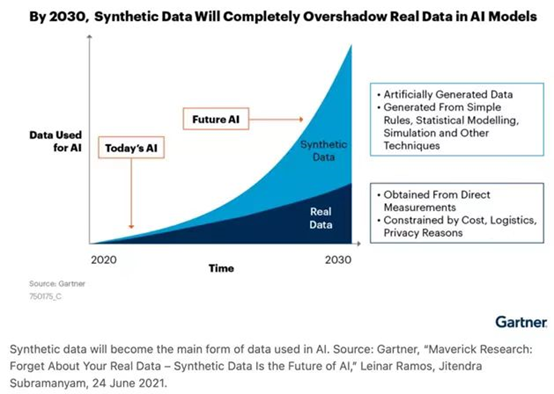
图片来源:Gartner
生成式数据是通过建立数学模型或仿真环境,采用去中心化的形态来采集取得的数据。这些数据集的生成可以在需要的情况下进行调整和控制,而且可以覆盖更多的应用场景,帮助人们和机器更好地理解数据的特性和行为。生成式数据的优点在于可以更加准确地控制生成条件,符合数据合规性的要求。
使用生成式AI数据,在满足AI训练数据需求量和多样性的同时,合规性也能在最大程度上获得保证。在未来,类ChatGPT大模型更有机会去使用这样一些生成式AI数据进行训练。
Magic Data的数据优势与能力——多轮对话数据积累已达超1亿轮次
Magic Data作为一家AI数据解决方案公司,在过去的7年间专注于构建多轮对话数据,目前已经积累了超过1亿轮次(20万小时)的高精度数据。所有数据都经过了人工检验标注,保证了数据的高质量。这些数据是通过众包的方式取得,邀请C端用户贡献数据,并回馈一定的收益。
这些数据按行业进行拆分,涵盖了日常生活中的衣食住行等方面,同时也包括了一些垂域的知识。这为数据的应用提供了更多的场景和可能性。

Magic Data多轮对话数据领域分类,访问www.magicdatatech.cn查看更多
通过多轮对话数据,我们就可以让机器可以学习到人与人之间对话时的逻辑、上下文关联关系等知识点,为训练ChatGPT等模型提供了更加丰富的数据资源。
术业有专攻,AI发展是应用、算力与数据科学的多方合力
做AI模型的人不一定是数据专家,但是数据科学对于AI发展至关重要。数据科学和算法框架是分开的两件事情,但是二者又密不可分。数据科学依赖于对框架运转的理解,而算法框架的优化则需要数据科学的支持。因此,综合各方面因素才能形成一个好的AI结果。
应用、投产、工程化能力是AI落地的关键,需要与行业紧密耦合。AI算法从业者未来可能进入AI工程师领域,这将是一件非常有成就感的事情。同时,AI的落地问题也是不容忽视的。为此,我们需要与所有的生态伙伴一起构建一个机器学习的运维闭环,通过数据的处理和模型的迭代来实现闭环。这个闭环非常长,也非常庞大,每个环节都需要专业知识。我们希望与所有的生态伙伴共同合作,实现AI在各行各业的广泛应用。
数据好,算力少
如今,像ChatGPT这样的大型模型在使用和调度中消耗大量算力,一次训练可能耗费数百万的能源,使用调度同样昂贵。考虑到人类能源有限,我们需要关注如何以更加环保的方式发展AI。如何平衡AI发展与资源消耗的问题?其中,数据是一个解决方案。我们需要让AI模型更加精干,而非臃肿。为此,喂养模型的数据应当是高质量的,而非囫囵吞枣。只有如此,才能更加节约算力,实现AI发展的可持续性。
相关链接:
https://www.theverge.com/2023/3/15/23640180/openai-gpt-4-launch-closed-research-ilya-sutskever-interview
关于MagicData
Magic Data (北京爱数智慧科技有限公司)是一家全球领先多模态AI数据解决方案提供商,为人工智能领域研发企业和科研机构提供AI训练数据集和专业咨询服务,产品涵盖智慧出行、智慧金融、智能社交、智能家居、智能终端等五大行业,迄今服务了微软、高通、英伟达、阿里巴巴、百度、腾讯等国内外近200家合作伙伴。
本文链接:https://my.lmcjl.com/post/11278.html
4 评论