目录
-
一、适合创建索引
- 1、字段的数值有唯一性限制
- 2、频繁作为Where查询条件的字段
- 3、经常Groupby和Orderby的列
- 4、Update、Delete的where条件列
- 5、Distinct字段需要创建索引
- 6、多表Join连接操作时,创建索引注意事项
- 7、使用列的类型小的创建索引
- 8、使用字符串前缀创建索引
- 9、区分度高的列适合作为索引
- 10、使用最频繁的列放到联合索引的左侧
- 11、在多个字段都要创建索引的情况下,联合索引由于单值索引
-
二、不适合创建索引
- 1、在where中使用不到的字段不要设置索引
- 2、数据量小的表最好不要使用索引
- 3、有大量重复数据的列上不要建立索引
- 5、不建议用无序的值作为索引
- 6、删除不在使用或很少使用的索引
- 7、不要定义冗余或重复的索引
- 8、删除不在使用或很少使用的索引
- 9、不要定义冗余或重复的索引
-
总结
一、适合创建索引
1、字段的数值有唯一性限制
根据Alibaba规范,指明在业务上具有唯一特性的字段,即使是组合字段,也必须建成唯一索引。

例如,学生表中的学号时具有唯一性的字段,为该字段建立唯一性索引可以快速查询出某个学生的信息,如果使用姓名的话,可能存在同名的情况,从而降低查询速度。
2、频繁作为Where查询条件的字段
某个字段在Select语句的Where条件中经常被使用到,那么就需要给这个字段创建索引,尤其实在数据量大的情况下,创建普通索引就可以大幅提升查询效率。
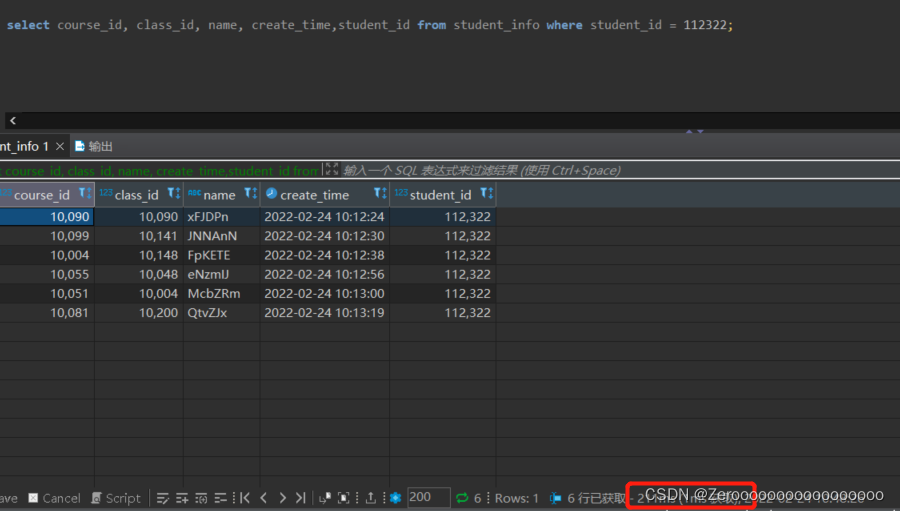
比如测试表student_info有100万数据,假设查询student_id=112322的用户信息,如果没有对student_id字段创建索引,查询结果如下:
?
|
1 |
|
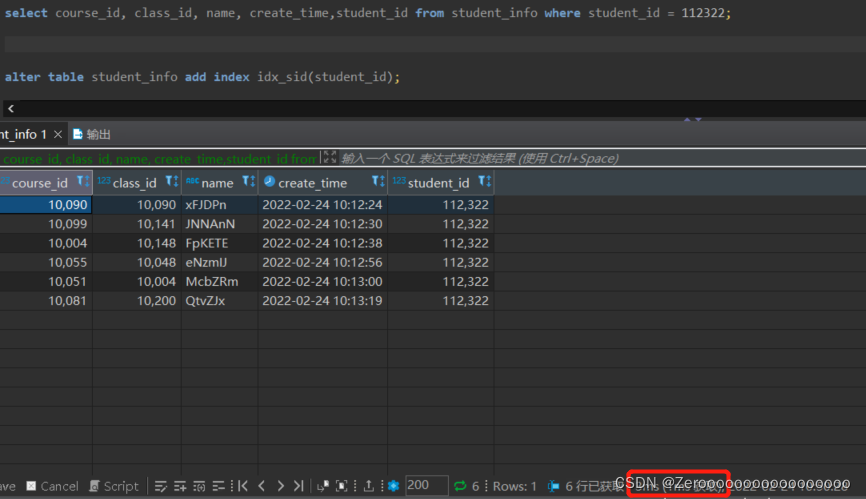
为student_id创建索引后,查询结果如下:
?
|
1 2 |
|
3、经常Group by和Order by的列
索引就是让数据按照某种顺序进行存储或检索,因此当使用Group by对数据进行分组查询或使用Order by对数据进行排序的时候 ,就需要对分组或排序的字段进行索引。如果待排序的列有多个,那可以在这些列上建立组合索引。
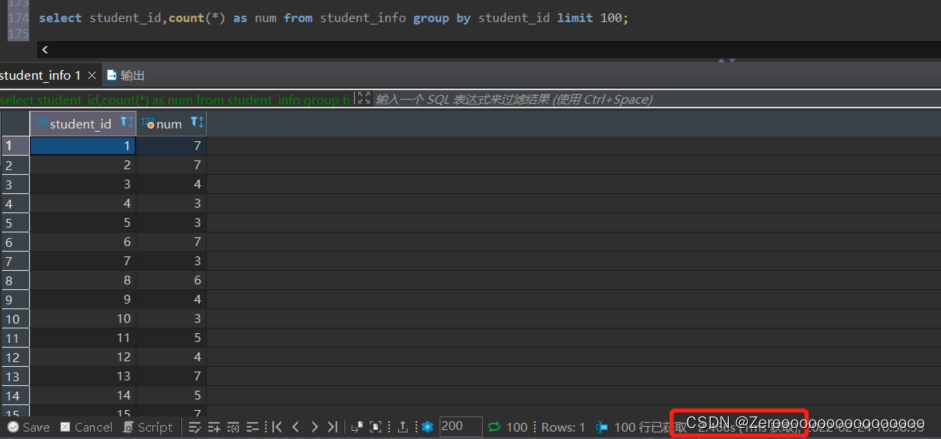
比如,按照student_id对学生选秀的课程进行分组,显示不同的student_id和课程的数量,显示100条。如果不对student_id创建索引,查询结果如下:
?
|
1 |
|
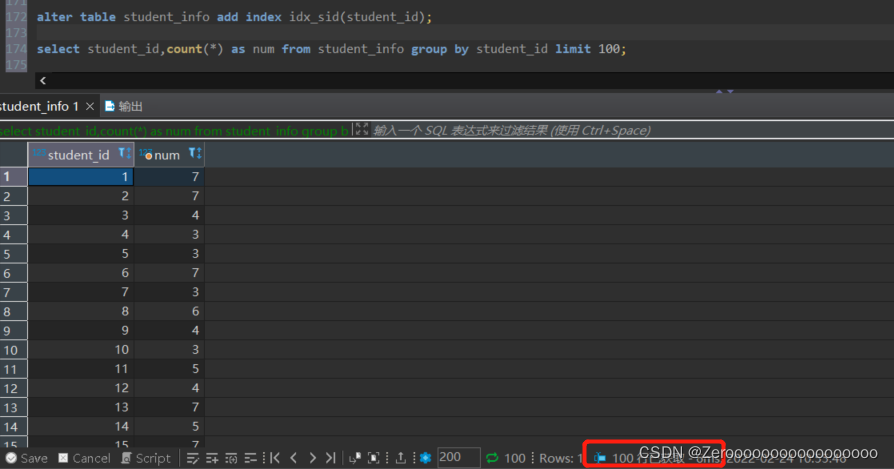
为student_id创建索引后,查询结果如下:
?
|
1 2 |
|
4、Update、Delete的where条件列
对数据按照某个条件进行查询后再进行Update或Delete的操作,如果对Where字段创建了索引,就能答复提升效率。原因是因为需要先根据Where条件列检索出来这条记录,然后再对他进行更新或删除。如果进行更新的时候,更新的字段是非索引字段,提升效率会更明显,这是因为费索引字段更新不需要对所以进行维护。
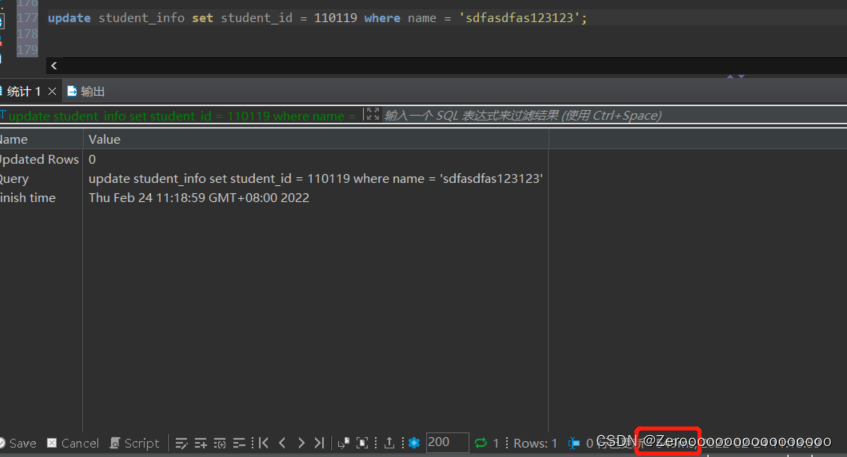
比如对student_info表中的name字段为sdfasdfas123123的数据修改student_id为110119,在没有对name字段建立索引的情况下,执行情况如下:
?
|
1 |
|
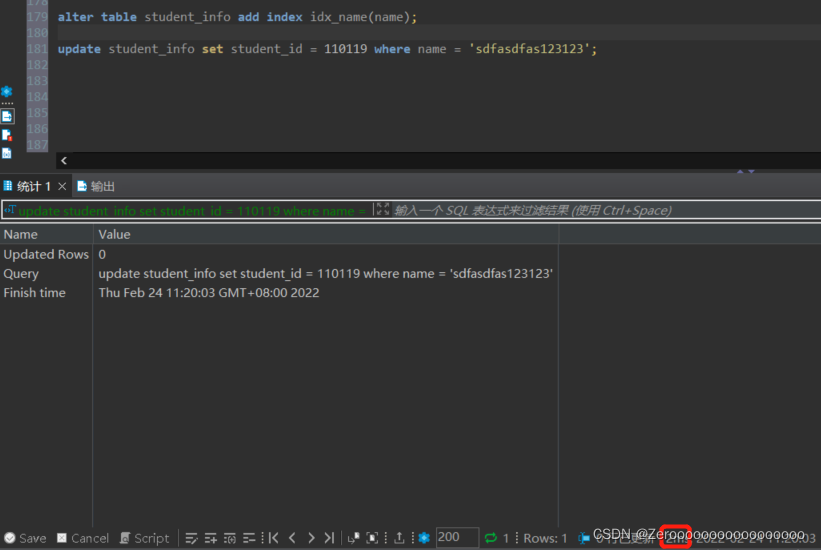
添加索引后,执行情况如下:
?
|
1 2 |
|
5、Distinct字段需要创建索引
有时候需要对某个字段进行去重,使用Distinct,那么对这个创建索引也会提升查询效率。
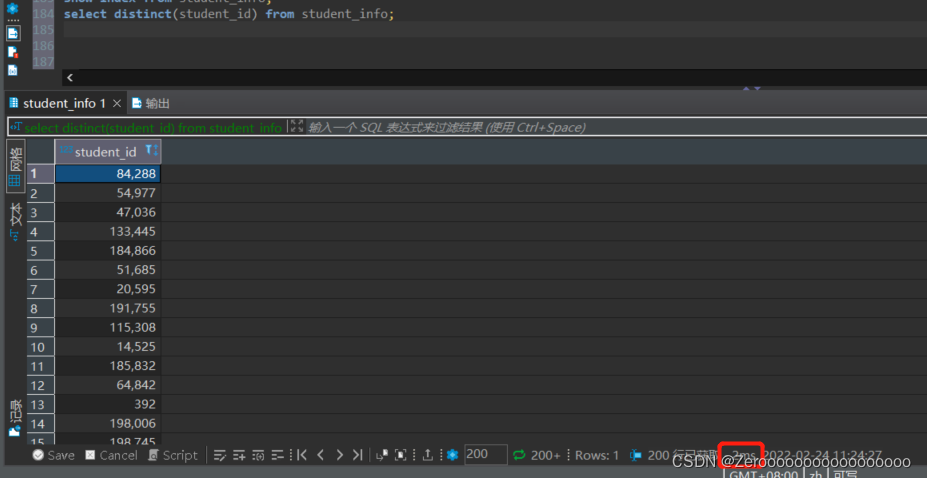
比如查询课程表中不同student_id都有哪些,如果没有为student_id创建索引,执行情况如下:
?
|
1 |
|
创建索引后,执行情况如下:
?
|
1 2 |
|
6、多表Join连接操作时,创建索引注意事项
首先,连接表的数据量尽量不超过3张,因为每增加一张表就相当于增加了一次嵌套的循环,数量级增长非常快,严重影响查询效率。其次,对Where条件创建索引,因为Where才是对数据条件的过滤,如果再数据量非常大的情况下,没有Where条件过滤时非常可怕的,最后,对于连接的字段创建索引,并且改字段再多张表中类型必须一致。

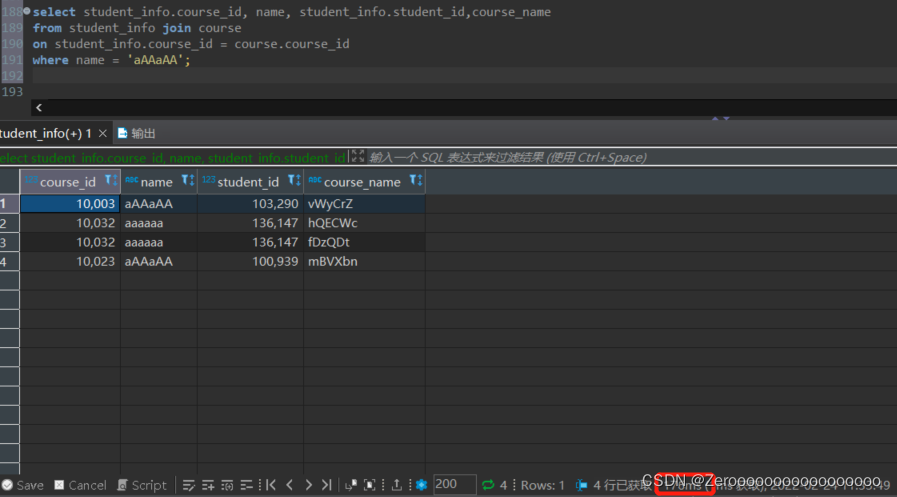
比如,只对student_id创建索引,查询结果如下:
?
|
1 2 3 4 |
|
给name字段创建索引后,查询结果如下:
?
|
1 2 3 4 5 |
|
7、使用列的类型小的创建索引
这里所说的类型小值意思是该类型表示的数据范围的大小。比如在定义表结构的时候要显示的指定列的类型,以整数类型为例,有TINYINT、MEDIUMINT、INT、BIGINT等,他们占用的存储空间依次递增,能表示的数据范围也是一次递增。如果相对某个整数列建立索引的话,在表示的整数范围允许的情况下,尽量让索引列使用较小的类型,例如能使用INT不要使用BIGINT,能使用MEDIUMINT不使用INT,原因如下:
- 数据类型越小,在查询时进行的比较操作越快
- 数据类型越小,索引占用的空间就越少,在一个数据页内就可以存下更多的记录,从而减少磁盘I/O带来的性能损耗,也就意味着可以存储更多的数据在数据页中,提高读写效率。
8、使用字符串前缀创建索引
根据Alibaba开发手册,在字符串上建立索引时,必须指定索引长度,没有必要对全字段建立索引。

比如有一张商品表,表中的商品描述字段较长,在描述字段上建立前缀索引如下:
?
|
1 2 |
|
区分度的计算可以使用count(distinct left(列名, 索引长度))/count(*)来确定。
9、区分度高的列适合作为索引
列的基数值得时某一列中不重复数据的个数,比如说某个列包含值2,5,3,6,2,7,2,虽然有7条记录,但该列的基数却是5,也就是说,在记录行数一定的情况下,列的基数越大,该列中的值就越分散;列的基数越小,该列中的值就越集中。这里列的基数指标非常重要,直接影响是否能有效利用索引。最好为列的基数大的列建立索引,为基数太小的列建立索引效果反而不好。
可以使用公式select count(distinct col)/count(*) from table 来计算区分度,越接近1区分度越好。
10、使用最频繁的列放到联合索引的左侧
这条就是通常说的最左前缀匹配原则。 通俗来讲就是将Where条件后经常使用的条件字段放在索引的最左边,将使用频率相对低的放到右边。
11、在多个字段都要创建索引的情况下,联合索引由于单值索引
二、不适合创建索引
1、在where中使用不到的字段不要设置索引
通常索引的建立是有代价的,如果建立索引的字段没有出现在where条件(包括group by、order by)中,建议一开始就不要创建索引或将索引删除,因为索引的存在也会占用空间。
2、数据量小的表最好不要使用索引
3、有大量重复数据的列上不要建立索引
在条件表达式中经常用到的不同值较多的列上建立索引,但字段中如果有大量重复数据,也不用创建索引。比如学生表中的性别字段,只有男和女两种值,因此无需建立索引。如果建立索引,不但不会提高查询效率,反而会严重降低数据更新速度。
4、避免对经常更新的表创建过多的索引
- 频繁更新的字段不一定要创建索引,因为更新数据的时候,索引也要跟着更新,如果索引太多,更新的时候会造成服务器压力,从而影响效率。
- 避免对经常更新的表创建过多的索引,并且索引中的列尽可能少。此时虽然提高了查询速度,同时也会降低更新表的速度。
5、不建议用无序的值作为索引
例如身份证、UUID(在索引比较时需要转为ASCII,并且插入时可能造成页分裂)、MD5、HASH、无序长字符串等。
6、删除不在使用或很少使用的索引
表中的数据被大量更新或者数据的使用方式被改变后,原有的一些索引可能不会被使用到。DBA应定期找出这些索引并将之删除,从而较少无用索引对更新操作的影响。
7、不要定义冗余或重复的索引
例如身份证、UUID(在索引比较时需要转为ASCII,并且插入时可能造成页分裂)、MD5、HASH、无序长字符串等。
8、删除不在使用或很少使用的索引
表中的数据被大量更新或者数据的使用方式被改变后,原有的一些索引可能不会被使用到。DBA应定期找出这些索引并将之删除,从而较少无用索引对更新操作的影响。
9、不要定义冗余或重复的索引
总结
到此这篇关于MySQL索引创建原则的文章就介绍到这了,更多相关MySQL索引创建原则内容请搜索服务器之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持服务器之家!
原文链接:https://blog.csdn.net/lissic_blog/article/details/123110631
本文链接:https://my.lmcjl.com/post/11352.html
4 评论