情景学习(In-context learning)
对于一些LLM没有见过的新任务,只需要设计一些任务的语言描述,并给出几个任务实例,作为模型的输入,即可让模型从给定的情景中学习新任务并给出满意的回答结果。这种训练方式能够有效提升模型小样本学习(few-shot learning)的能力。下图是一个情景学习的示例。
可以看到,只需要以自然语言的形式描述两个情感分类任务输入输出的例子,LLM就能够对新输入数据的情感极性进行判断。
思维链(Chain-of-Thought,CoT)
对于一些逻辑较为复杂的问题,直接向大规模语言模型提问可能会得到不准确的回答,但是如果以提示(prompt)的方式在输入中给出有逻辑的解题步骤(即将复杂问题拆解为多个子问题解决再从中抽取答案)的示例后再提出问题,大模型就能给出正确题解。
如图所示,直接让模型进行数学题的计算会得到错误的结果,而引入解题过程则可以激发模型的推理能力,从而得到的正确的结果。
有时,甚至不用给示例,在输入后面接一句“Let’s think step by step”,模型的输出就是一步一步“思考”后的各个子问题的结果,再将该输出拼到输入后构造第二次输入数据,大模型就能进一步将上一步的输出整合,得出正确的复杂问题的解。(so amazing!)
目前有研究发现,由于数据集中存在的大量代码数据,得益于代码的强逻辑性,通过将问题中的文本内容替换为编程语言能够进一步提升模型的CoT能力(Program-aided Reasoning)。
由于CoT技术能够激发大规模语言模型对复杂问题的求解能力,该技术也被认为是打破比例定律的关键。
03
自然指令学习
(Learning from Natural Instructions)
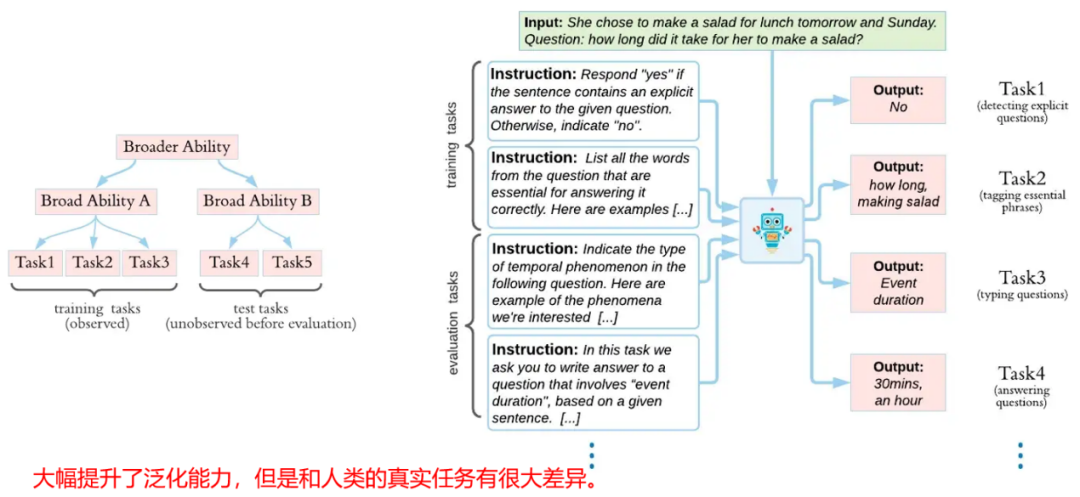
这种训练方式会在输前面添加一个“指令(instruction)”,该指令能够以自然语言的形式描述任务内容,从而使得大模型根据输入来输出任务期望的答案。该方式将下游任务进一步和自然语言形式对齐,能显著提升模型对未知任务的泛化能力。
https://mp.weixin.qq.com/s/vz6x5n8tGKSErwS-_bQY2A
本文链接:https://my.lmcjl.com/post/11371.html
4 评论