
ChatGPT原理剖析:InstructGPT详解
1. InstructGPT原理
GPT-3是一种预训练的语言模型,它在多种自然语言处理任务上都表现出了很好的性能。然而,GPT-3仍然存在一些局限性,例如它不能够直接根据提示生成特定任务的响应,需要通过微调才能够完成。微调是指在特定任务上针对预训练模型进行的有监督学习,以此来调整模型的权重,使其在该任务上的表现更好。
在许多应用中,人们需要GPT-3模型完成一些特定的任务,例如翻译、摘要、回答问题等。传统的方法是通过人工标注数据集来训练模型,在特定任务上进行微调。然而,这种方法需要大量的人力和时间,并且可能存在标注数据集的不准确性等问题。
为了解决这些问题,OpenAI提出了InstructGPT模型。InstructGPT的原理是利用人类的反馈对语言模型进行微调,使其更能符合用户的意图和指示。它使用了一个叫做指令-回答对的数据集,其中包含了各种任务和场景下的问题和答案。它还使用了一个叫做指令-评价对的数据集,其中包含了语言模型生成的输出和人类给出的评分。通过这两个数据集,InstructGPT可以学习如何根据不同的指令生成更有用、更真实、更友好的输出。
InstructGPT模型通过让人工编写提示来引导GPT-3生成特定任务的响应,从而省去了标注数据集的过程。具体来说,InstructGPT模型要求标注者编写三种类型的提示:
-
简单提示:标注者提出一个任意任务,同时确保任务具有足够的多样性。
-
Few-shot提示:标注者提出一条指令,以及该指令的多个查询/响应对。
-
基于用户提示:根据OpenAI API的候选名单申请中陈述的许多用例来提供提示。
通过这些提示,InstructGPT模型生成了三个不同的数据集,用于微调过程。这些数据集分别是:
-
SFT数据集:带有用于训练SFT模型的标签器演示。
-
RM数据集:带有用于训练模型输出的标签器排名。
-
PPO数据集:没有任何人工标签,用作RLHF微调的输入。
在筛选标注者上,与供应商紧密合作,通过入职流程、为每个任务提供详细的说明、有个聊天室帮助回答问题等等来帮助标注者们在同个任务下有同样的偏好。在有监督微调(SFT)方面,使用了有监督学习在标签演示中微调GPT-3。
2. InstructGPT的训练步骤
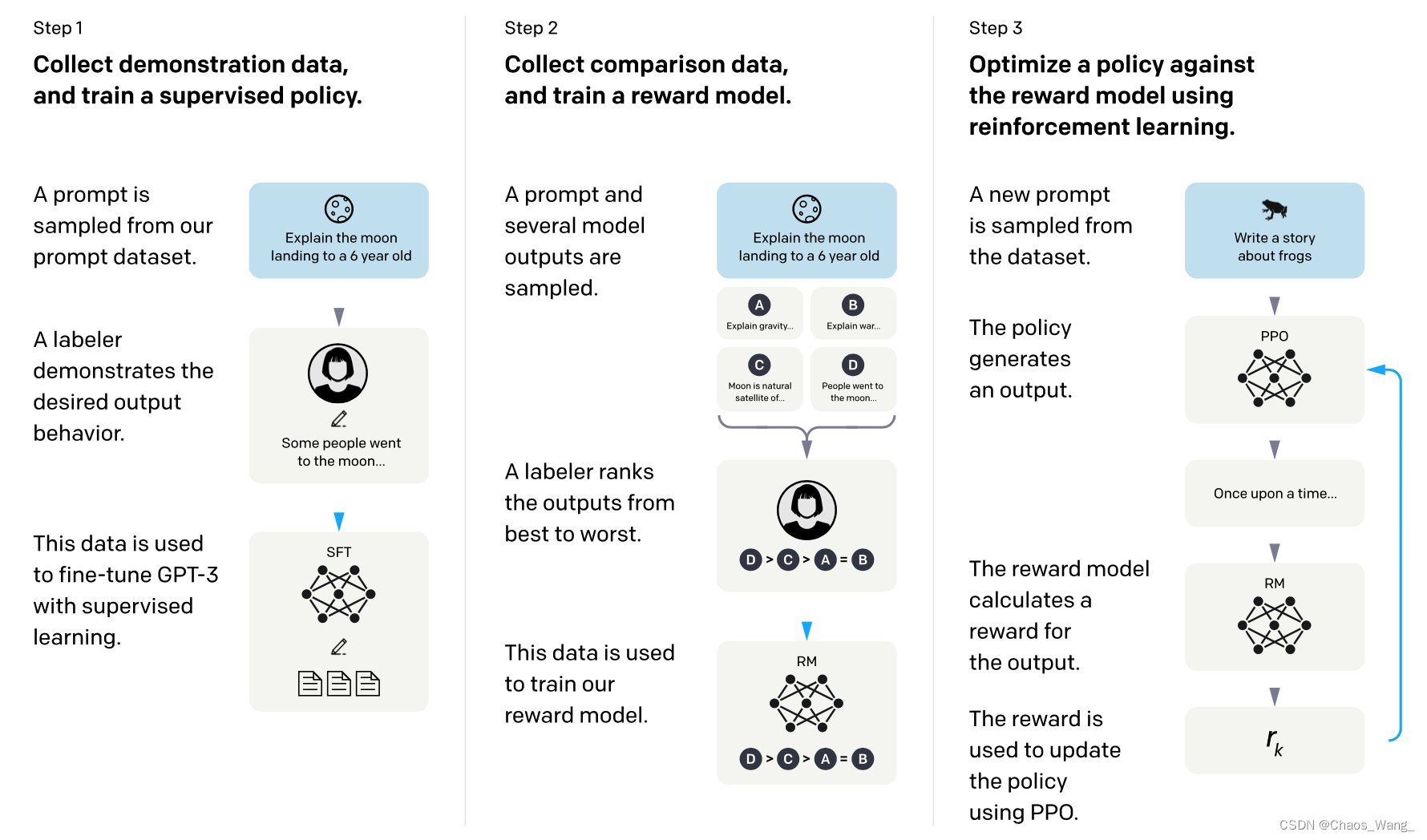
- 监督微调 (SFT):使用一个包含各种指令-回答对的数据集,对GPT-3进行监督学习,使其能够根据不同的指令生成合理的回答。
- 奖励模型 (RM) 训练:使用一个包含各种指令-评价对的数据集,训练一个奖励模型,使其能够根据人类给出的评分,给语言模型生成的输出打分。
- 强化学习 (RL):使用近端策略优化 (PPO) 算法,对语言模型进行强化学习,使其能够最大化奖励模型给出的分数。
2.1 监督微调 (SFT)
InstructGPT监督微调的过程是这样的:
- 首先,收集一些人类提供的问题和回答,作为反馈数据集。
- 然后,用这个数据集对语言模型进行监督学习,使其能够生成与人类回答相似的输出。
- 最后,评估语言模型在不同的任务上的表现,如对话、摘要、翻译等,并给出反馈指令,如“更简洁”、“更友好”、“更准确”等。
这个过程可以重复多次,以提高语言模型的质量和适应性。
InstructGPT监督微调的数据量取决于语言模型的规模和任务的复杂度。一般来说,越大的语言模型需要越多的数据来发挥其潜力。例如,GPT-3使用了45TB的原始未处理数据,而InstructGPT使用了约10万个问题和回答对。
不过,并不是数据量越多越好,因为数据的质量和多样性也很重要。如果数据存在噪声、偏见或重复,那么语言模型可能会学习到错误或有害的信息。因此,InstructGPT在收集数据时也要注意筛选和平衡。
InstructGPT保证数据的质量和多样性的方法有以下几点:
- 使用多种来源的数据,如网页、新闻、社交媒体等,以增加数据的覆盖面和代表性。
- 使用人类标注员对数据进行筛选和评估,以去除噪声、错误或有害的内容。
- 使用不同的反馈指令来调整语言模型的输出,以增加数据的多样性和灵活性。
- 使用强化学习来优化语言模型的参数,以适应不同的任务和场景。
InstructGPT监督微调后的效果有以下几点:
- 语言模型能够更好地遵循用户的意图,生成与反馈指令一致的输出。
- 语言模型能够更真实地回答问题,减少虚假或误导性的信息。
- 语言模型能够更友好地进行对话,降低有害或冒犯性的内容。
- 语言模型能够更灵活地适应不同的任务和场景,提高生成质量和多样性。
2.2 奖励模型 (RM) 训练
InstructGPT奖励模型 (RM) 训练过程有以下几个步骤:
- 使用监督微调 (SFT) 后的语言模型,根据不同的反馈指令生成多个候选输出。
- 雇佣人类标注员,根据输出的质量和与反馈指令的一致性,对每个候选输出打分或排序。
- 使用打分或排序作为标签,训练一个回归模型,该模型与语言模型共享参数,但在最后一层添加了一个线性层。
- 使用训练好的回归模型作为奖励模型 (RM),为语言模型生成的输出提供奖励信号。
2.3 强化学习 (RL)
InstructGPT近端策略优化 (PPO) 过程有以下几个步骤:
- 随机采样一个新的反馈指令,作为语言模型的输入。
- 使用语言模型生成一个候选输出,使用奖励模型 (RM) 对其打分。
- 使用PPO算法更新语言模型的参数,以最大化奖励模型 (RM) 的打分,并保持新旧策略间的差异不要太大123。
重复上述过程,直到达到预设的迭代次数或收敛条件。
InstructGPT近端策略优化 (PPO) 与其他强化学习方法的区别主要有以下几点:
- PPO是一种同轨策略(on-policy)算法,即它只使用当前策略生成的数据来更新参数,而不使用历史数据。
- PPO通过引入一个裁剪函数,来约束新旧策略间的差异不要太大,从而避免了性能崩溃的风险。
- PPO相比于其他同轨策略算法,如TRPO,具有更简单、更高效、更稳定的优点。
参考文献
[1] Training language models to follow instructions with human feedback https://arxiv.org/abs/2203.02155
[2] Deep reinforcement learning from human preferences https://arxiv.org/abs/1706.03741
[3] Learning to summarize from human feedback https://arxiv.org/abs/2009.01325
本文链接:https://my.lmcjl.com/post/11523.html
4 评论