🦉 AI新闻
🚀 小米宣布未来五年投入1000亿元,开启AI大模型内测版本
摘要:在小米雷军年度演讲上,小米宣布未来五年将投入1000亿元人民币用于技术研发,同时公布了AI大模型内测版本的邀请测试。该内测版本将给用户带来更强大的对话体验和多项功能升级,展示了小米在人工智能领域的重要进展。此外,小米还透露了AI大模型在手机本地跑通的成功,以及出色的上下文理解能力和超级问答功能。这一消息引起了公众的关注和兴趣,对小米未来发展前景产生了重要影响。
🚀 教育领域应对AI作弊方式的探索
摘要:人工智能在教育中的应用给大学教授带来新的挑战。一些教授为了应对学生使用AI程序ChatGPT作弊的问题,决定在秋季学期采用传统的纸笔考试和手写作文的方式进行评估。教授们普遍对人工智能在教育中的作用提出质疑。一些学校直接禁止使用ChatGPT,而另一些学校则探索如何将其作为一种学习工具。在寻找方法对抗生成式AI的考试作弊过程中,一些教授计划采用口头考试和个性化作业等方式防止学生使用ChatGPT。ChatGPT的使用量有所下降,这可能意味着其用户群体较窄,使用场景有限。
🚀 Bing Chat升级完成 99%,支持引入第三方插件和“nosearch”功能
摘要:微软的Bing Chat已经完成了99%的升级,可以支持上线。此次升级的目的是提高Bing Chat的速度和可靠性,并引入第三方插件和“nosearch”等新功能。通过“nosearch”功能,用户可以在不使用网络信息的情况下使用Bing Chat来回答问题。微软计划将Bing AI Chat引入Brave和Safari浏览器,并为Bing Chat引入第三方插件。微软还透露,Bing已经实现了连续九个季度的增长,将为用户带来更多人工智能驱动的功能和价值。
🚀 微软表示GPT-4在医疗领域具有巨大潜力
摘要:微软研究团队表示,GPT-4等大型模型在医疗领域有巨大的潜力,可以帮助加快医疗流程,建立更加精准的病理模型,并提高医疗药物的开发效率。虽然GPT-4仅接受通用互联网数据而非特定医学数据的训练,但它能够根据指定的医学标准构建复杂的临床研究,并在处理医疗图像和其他生物数据方面发挥更多作用。微软目前正在基于GPT-4开发LLaVA-Med 医疗模型,用于提供生物医学成像数据,加速医疗产业相关护理和研究。微软依赖GPT-4开发专用的医疗模型。
🚀 英特尔以 Premier 会员身份加入 PyTorch 基金会
摘要:英特尔宣布以 Premier 会员身份加入 PyTorch 基金会,五年来一直积极参与 PyTorch 开发,优化 CPU 推理性能并提升英特尔处理器上的 AI 性能。英特尔在 PyTorch 2.0 中对 TorchInductor CPU FP32 推理进行了优化,改进了 PyG 中 GNN 的推理和训练性能,并针对 x86 CPU 平台优化了 Int8 推理。英特尔目前有四名 PyTorch 维护者,他们负责维护 CPU 性能模块和编译器前端。英特尔加入 PyTorch 基金会对于促进 AI 技术发展具有重要意义。
🚀 42岁倭黑猩猩学会玩《我的世界》引人关注
摘要:42岁的倭黑猩猩Kanzi在猩猩行动计划中学会了玩《我的世界》,通过与训练师的互动,它学会了移动、收集零食、打碎障碍物等技能。有趣的是,猩猩的学习方式和人类教AI玩《我的世界》的方法非常相似,包括上下文强化学习、模仿学习、课程学习等。这次实验再次验证了动物视觉系统在适应新环境方面的出色能力,超过了人工智能模型。这个发现引起了网友们的热议和恶搞。这个实验也提醒我们应关注动物学习的差异和人工智能的发展。
🚀 OpenAI可能在2024年底面临破产的潜在财务危机
摘要:天风国际分析师郭明錤表示,尽管人工智能(AI)和通用人工智能(AIGC)已成为明确的趋势,但若AI/AIGC无法创造可持续获利的商业模式,产业对其投资可能会放缓。有媒体发布报告称OpenAI仅运行其人工智能服务ChatGPT每天需花费约70万美元,而目前尚没有足够的收入来实现收支平衡。如果OpenAI不能很快获得更多资金,该公司可能在2024年底之前申请破产。此外,微软投资了100亿美元来支撑OpenAI的运作。该报告引起了公众的关注。
🗼 AI知识
🔥 纯C/C++实现的Stable Diffusion
克隆和构建 stable-diffusion.cpp 图像处理程序的库,解释了各种命令行参数的用法,如指定线程数、模型路径、输出路径、提示和采样设置等。使用不同精度以获得更好图像质量的选项。
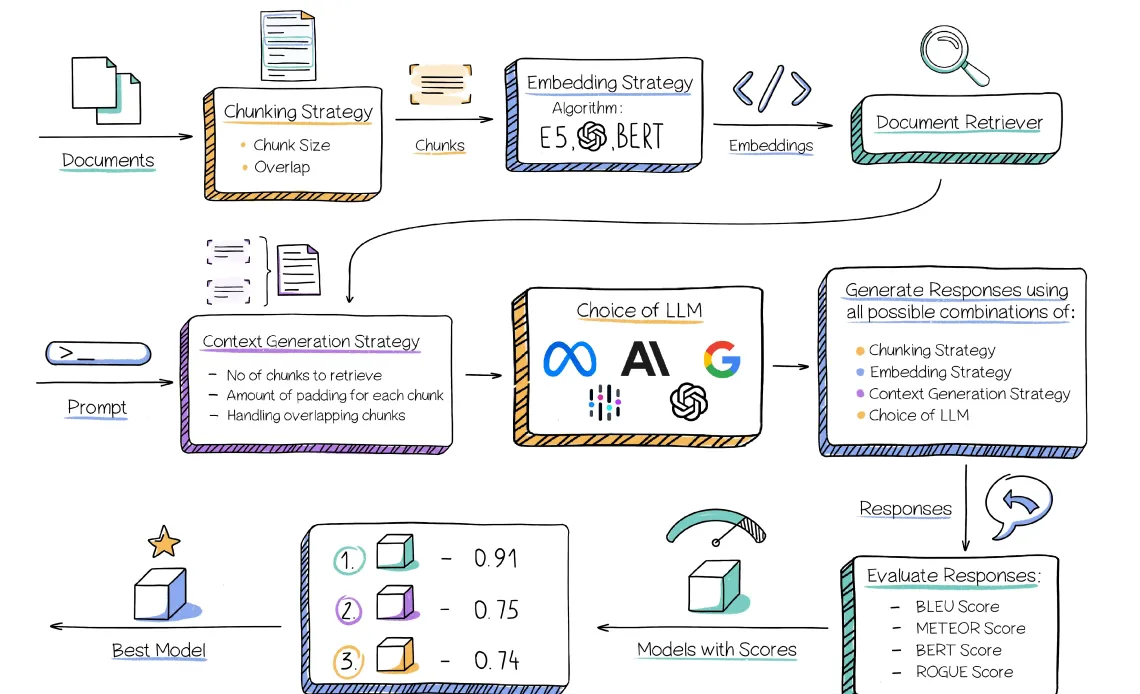
🔥 企业内部知识问答系统面临的挑战及解决方案
本文探讨了企业在利用ChatGPT等语言模型回答内部知识库问题时面临的挑战,并提出了微调开源语言模型和使用检索增强生成(RAG)两种解决方案。文章重点分析了影响RAG方法性能的因素,如文本块大小、文本块间重叠部分、嵌入技术、文档检索器和语言模型选择等。Abacus.AI提供了一种新颖的AutoML方法来找到特定用例的最佳组合。文章还介绍了Abacus.AI使用的评估指标,如BLEU、METEOR、BERT和ROGUE等,用于评估机器生成回复的质量。Abacus.AI为企业优化语言模型聊天机器人系统提供了解决方案。
更多AI工具,参考Github-AiBard123,国内AiBard123
本文链接:https://my.lmcjl.com/post/11704.html
4 评论