【跟着ChatGPT学深度学习】系列
- 第零弹——ChatGPT介绍以及一些使用案例
- 第一弹——ChatGPT带我入门深度学习
- 第二弹——ChatGPT带我入门NLP
- 第三弹——ChatGPT教我文本分类
- 第四弹——ChatGPT带我学情感分析
- …
- 番外篇——ChatGPT教我谈恋爱
【跟着ChatGPT学深度学习】ChatGPT带我学情感分析
学完文本分类,觉得不够过瘾,想着文本分类的下游应用之一不就是情感分析么,于是便又开始学习情感分析了。
1. 情感分析介绍
情感分析是一种自然语言处理技术,旨在识别、提取和量化文本中的情感信息。它可以帮助人们了解一段文本的情感倾向,例如积极、消极或中性。情感分析可以用于分析社交媒体上的评论、产品评论、新闻文章、客户反馈等各种文本数据,以便企业和个人了解他们的客户和受众的情感状态和反应。在情感分析中,通常会使用一些机器学习算法或深度学习模型,例如朴素贝叶斯、支持向量机、神经网络等来进行分类和分析。
2. 情感分析学习流程
以下是一个基本的情感分析流程:
-
数据准备:收集文本数据,并将其预处理为计算机可处理的格式。预处理步骤可能包括词语分割、去除停用词、词形还原、词性标注等。
-
特征提取:从文本数据中提取与情感相关的特征。常用的特征包括词频、TF-IDF、词嵌入等。
-
模型选择:选择适合任务的机器学习或深度学习模型。常用的模型包括朴素贝叶斯、支持向量机、神经网络等。
-
模型训练:使用已标注的数据对模型进行训练,并进行交叉验证以评估模型性能。
-
模型优化:调整模型超参数或特征提取方法以提高模型性能。
-
模型应用:对新的文本数据进行情感分析,输出文本的情感倾向。
3. 情感分析学习计划
-
学习自然语言处理基础知识:了解文本处理的一些基本概念、技术和工具,如分词、词性标注、命名实体识别等,以及一些基础的机器学习和深度学习知识。
-
了解情感分析的基础知识:学习情感分析的一些基本概念和应用场景,如情感分类、情感极性分析、情感抽取等。
-
学习情感分析的常用技术:了解情感分析中常用的技术,如情感词典、朴素贝叶斯分类器、支持向量机、神经网络等,并掌握其原理和实现方法。
-
学习情感分析的深度学习方法:了解情感分析中常用的深度学习方法,如卷积神经网络、循环神经网络、注意力机制等,并掌握其应用和实现方法。
-
学习情感分析的最新研究:了解情感分析领域的最新研究和技术,如基于预训练模型的情感分析、方面级情感分析、跨语言情感分析等。
-
实践项目:尝试使用一些开源的情感分析工具或框架,如NLTK、TextBlob、Stanford CoreNLP、PyTorch等,进行一些实践项目,如情感分类、情感极性分析、情感抽取等,以加深自己的理解和掌握实际操作能力。
-
阅读论文和参与社区:定期阅读相关的论文和博客,了解最新的研究和技术进展,参与社区讨论和分享经验。
4. 情感分析领域研究学者
情感分析作为一项重要的自然语言处理技术,已经吸引了大量学者的关注。以下是一些在情感分析领域做出重要贡献的学者:
-
Bing Liu:是美国伊利诺伊大学芝加哥分校计算机科学系的教授,是情感分析领域的著名学者之一,主要研究方向是情感分析、知识图谱、Web挖掘等。
-
Janyce Wiebe:是美国匹兹堡大学计算机科学系的教授,是情感分析领域的先驱之一,她的研究方向包括情感分析、主观性分析、文本挖掘等。
-
Minqing Hu 和 Bing Liu:是情感分析领域著名的合著者,他们开发了一种称为情感词典的技术,用于识别文本中的情感词并计算情感得分。
-
Saif M. Mohammad:是加拿大国家研究委员会计算机科学研究所的研究员,他的研究方向主要是情感分析、情感词典、情感计算等。
-
Erik Cambria:是新加坡南洋理工大学计算机科学系的助理教授,他的研究方向包括情感分析、情感计算、深度学习等。
5. 情感分析领域论文
5.1 经典论文
-
“Thumbs up? Sentiment Classification using Machine Learning Techniques”,由Pang和Lee于2002年发表,是情感分析领域的里程碑之一,介绍了使用机器学习技术进行情感分类的方法,并提出了一种新的基于情感词典的方法。
-
“Opinion mining and sentiment analysis”,由Liu于2012年发表,对情感分析领域进行了全面的综述,介绍了情感分析的基本概念、技术、应用以及未来的研究方向。
-
“Deep learning for sentiment analysis: A survey”,由Zhang et al.于2018年发表,对深度学习在情感分析中的应用进行了全面的综述,介绍了常用的深度学习模型、特征提取方法和数据集,并探讨了未来的研究方向。
-
“Building large lexicons for sentiment analysis”,由Esuli和Sebastiani于2006年发表,介绍了一种基于无监督学习方法和情感词典的构建方法,可以有效地扩展情感词典的规模,提高情感分析的准确性。
-
“Sentiment Analysis and Opinion Mining”,由Liu于2019年出版,是情感分析领域的一本重要的教科书,系统地介绍了情感分析的各种方法和应用,适合于情感分析的初学者和专业研究者阅读。
5.2 前沿论文
-
“BERT for Sentiment Analysis: Review, Challenges and Future Directions”,由Kumar et al.于2021年发表,介绍了使用BERT模型进行情感分析的最新研究进展,探讨了BERT模型在情感分析中的优势、挑战和未来研究方向。
-
“SentiBERT: A Transferable Transformer-based Architecture for Compositional Sentiment Semantics”,由Liu et al.于2020年发表,提出了一种基于Transformer的情感分析模型SentiBERT,能够对复杂的句子进行情感分析,并在多个任务上取得了最新的性能表现。
-
“A Hierarchical Transformer-based Model for Joint Aspect-based Sentiment Analysis”,由Sun et al.于2021年发表,提出了一种基于Transformer的层次结构模型,用于联合进行方面级别和情感级别的情感分析,实现了更加准确的情感分析结果。
-
“Multi-Granularity Hierarchical Attention Fusion Networks for Aspect-Level Sentiment Analysis”,由Li et al.于2019年发表,提出了一种多粒度的层次结构注意力融合网络,用于解决方面级别情感分析中的难题,取得了最新的性能表现。
-
“Multimodal Sentiment Analysis: Addressing Key Issues and Challenges”,由Borth et al.于2017年发表,探讨了情感分析中的多模态问题和挑战,介绍了多模态情感分析的方法和应用,并探讨了未来的研究方向。
6. 情感分析学习资源
(1)书籍:
- 《情感分析:方法与应用》:这本书详细介绍了情感分析的基本概念、方法、技术和应用,适合初学者和从业者。
- 《自然语言处理综论》:这本书是自然语言处理领域的经典教材,其中涵盖了情感分析等多个子领域。
MOOC: - Coursera:提供了多个与情感分析相关的课程,例如“Applied Text Mining in Python”、“Applied Data Science with Python”等。
- Udemy:也提供了多个与情感分析相关的课程,例如“Python for Data Science and Machine Learning Bootcamp”等。
- 网易云课堂:有一些国内的情感分析相关的课程,例如“自然语言处理(Python)”等。
(2)开源代码和工具:
- NLTK:是自然语言处理领域的一个著名的开源工具包,其中包含了情感分析相关的模块和功能。
- Stanford CoreNLP:是由斯坦福大学开发的一个自然语言处理工具,其中包含了情感分析等多个子模块。
博客和社区: - Kaggle:是一个知名的数据科学竞赛平台,其中有许多与情感分析相关的比赛和项目,可以通过参加这些比赛和项目来学习情感分析。
- GitHub:是一个知名的代码托管平台,其中有很多情感分析相关的开源项目和代码,可以直接下载和使用。
- Quora:是一个知名的问答社区,其中有许多关于情感分析的问题和回答,可以与其他研究者交流和分享。
总之,以上是一些学习情感分析的具体资源和网址,这些资源可以帮助学习者系统地了解情感分析的基本概念、方法和技术,并获得实践的机会和经验。
(3)情感分析Github项目
-
TextBlob:是一个Python库,提供了简单易用的API,可以进行情感分析、词性标注等自然语言处理任务。该项目包含了许多训练好的模型,可以直接使用,同时也支持自定义模型。https://github.com/sloria/TextBlob
-
VADER:是一个Python库,用于进行情感分析。该库使用基于规则的方法,能够比较准确地对文本进行情感分析,尤其是对于包含情感强度词语的文本效果较好。
https://github.com/cjhutto/vaderSentiment -
fastText:是一个Facebook开源的工具包,用于进行文本分类、情感分析等自然语言处理任务。fastText通过基于子词的表示方式,能够在小数据集上表现良好。
https://github.com/facebookresearch/fastText -
TensorFlow-Sentiment-Analysis:是一个使用TensorFlow实现的情感分析模型,包含了多个经典的情感分析模型,例如TextCNN、TextRNN、TextRCNN等。
https://github.com/gaussic/text-classification-cnn-rnn -
bert-sentiment-analysis:是一个使用BERT模型实现的情感分析项目,通过预训练的BERT模型,能够在多个情感分类数据集上达到很高的准确率。
https://github.com/negedng/bert-sentiment-analysis -
sent2vec:是一个基于深度学习的向量表示方法,能够将文本转化为低维稠密向量表示,适用于情感分析、文本分类等任务。
https://github.com/epfml/sent2vec
(4)情感分析的api
-
Google Natural Language API:Google提供的一款自然语言处理API,其中包含情感分析功能。支持多种语言,包括英语、中文、日语等,能够分析文本的情感极性和情感强度。
-
IBM Watson Natural Language Understanding:IBM提供的自然语言处理API,其中包括情感分析功能。支持多种语言,能够分析文本的情感极性、情感类别和情感强度。
-
Microsoft Azure Text Analytics:微软提供的自然语言处理API,其中包括情感分析功能。支持多种语言,能够分析文本的情感极性和情感强度。
-
Amazon Comprehend:亚马逊提供的自然语言处理API,其中包括情感分析功能。支持多种语言,能够分析文本的情感极性和情感强度。
-
Baidu AI开放平台:百度提供的自然语言处理API,其中包括情感分析功能。支持中文文本的情感分析,能够分析文本的情感极性和情感强度。
7. 情感分析方法
-
基于规则的方法
基于规则的情感分析方法使用手工编写的规则来识别文本中的情感。这些规则通常基于语言学和情感理论,例如,通过查找情感词汇和短语以及它们在文本中的上下文来推断情感极性。这种方法需要大量的人工工作,但是它们通常可以提供很高的准确性。 -
基于情感词典的方法
基于情感词典的情感分析方法是将文本中的情感词与一个预定义的情感词典进行比较,以推断情感极性。情感词典通常包含已知情感极性的词汇,例如“好”和“坏”。该方法通常需要对情感词典进行自定义和调整,以适应特定领域和文化环境。 -
基于机器学习的方法
基于机器学习的情感分析方法使用机器学习算法,例如朴素贝叶斯、支持向量机、随机森林等来训练分类模型。在这种方法中,模型会学习从训练数据中提取的特征与情感极性之间的关系,以在新的文本上进行分类。这种方法通常需要大量的标记数据来进行训练。 -
基于深度学习的方法
基于深度学习的情感分析方法使用深度神经网络来训练分类模型,例如循环神经网络(RNN)、卷积神经网络(CNN)和变换器(Transformer)。这些模型可以自动从原始文本中提取特征,并捕捉长期依赖关系和语义关系。在深度学习方法中,通常需要更大的数据集和计算资源来进行训练和调整。
8. 研究情感分析的科技公司
-
OpenAI:OpenAI是一个非营利组织,旨在推动人工智能的发展。该组织在情感分析领域进行了一系列研究,并开发了一些重要的自然语言处理技术。
-
Google:Google是全球最大的科技公司之一,在自然语言处理和情感分析方面投入了大量的研发资源。其自然语言处理API已经成为业内领先的技术之一。
-
IBM:IBM在自然语言处理和情感分析领域拥有丰富的经验和技术积累。其Watson AI平台包含了一系列自然语言处理API,能够满足各种场景的需求。
-
Microsoft:Microsoft在自然语言处理和情感分析领域也有一定的研究和应用经验。其Azure云平台提供了多个自然语言处理API,能够支持多种语言和功能。
-
Amazon:Amazon在自然语言处理和情感分析领域也有一些研究和应用经验。其Comprehend服务提供了丰富的自然语言处理功能,包括情感分析、实体识别等。
9. 情感分析前景
情感分析作为一种重要的自然语言处理技术,已经被广泛应用于社交媒体监测、舆情分析、产品评论分析、客户服务等领域。未来,随着人工智能和自然语言处理技术的不断发展,情感分析技术将会有更广泛的应用和更广阔的前景,具体表现如下:
-
**应用范围将进一步扩大。**除了社交媒体和评论等领域,情感分析还可以应用于电商、金融、医疗等领域,以及人机交互、情感机器人等领域。
-
**技术手段将更加丰富。**传统的情感分析技术主要基于机器学习和规则匹配,未来还将发展出更加复杂、灵活的深度学习和强化学习等技术手段。
-
**精度和效率将进一步提高。**随着数据量和模型复杂度的不断增加,情感分析技术的准确率和效率也将不断提高,为更精确的情感分析结果提供更好的保障。
-
**多语言情感分析技术将得到更多应用。**目前情感分析技术主要应用于英文等少数语言,未来将会开发出更多的多语言情感分析技术,使情感分析技术能够应用于更多的语言和文化背景。
总之,情感分析技术将会在各个领域得到更广泛的应用和发展,成为解决实际问题的重要工具和手段,也将促进人机交互和情感智能等领域的不断发展和创新。
10. ABSA介绍
ABSA是Aspect-Based Sentiment Analysis的缩写,中文翻译为方面级情感分析。它是情感分析的一个重要分支,主要是针对特定方面的情感分析,例如针对商品的特定属性或者服务的特定方面进行情感分析。相较于传统的情感分析,ABSA更加细粒度,能够更好地理解文本中的情感信息。
在ABSA领域,主要的任务包括方面抽取和情感分类两个部分。方面抽取任务是要从文本中识别出用户评论中提到的方面(如产品的功能、性能等),而情感分类任务则是要分析文本中针对这些方面的情感极性(如积极、消极、中性等)。
ABSA在应用场景上非常广泛,例如在电商领域,可以通过对用户对商品的评论进行方面级情感分析,提供更加精细化的商品推荐和服务体验,从而提高用户满意度和购买转化率。
11. ABSA研究学者
-
Bing Liu:现任美国伊利诺伊大学芝加哥分校计算机科学系教授,情感分析领域的知名学者之一,曾在方面级情感分析、情感知识库等方面做出了很多贡献。
-
Xiaojun Wan:现任哈尔滨工业大学计算机科学与技术系教授,主要研究方向为自然语言处理和信息检索,在情感分析、文本分类、信息抽取等领域有较深入的研究。
-
Minqing Hu:现任香港中文大学计算机科学与工程系教授,主要研究领域为信息检索、自然语言处理和机器学习,在方面级情感分析等方面有很多研究成果。
-
Janyce Wiebe:现任美国匹兹堡大学计算机科学系教授,情感分析领域的知名学者之一,主要研究方向为自然语言处理和语义分析,在情感分析的主客观性、情感句式识别等方面有很多研究成果。
-
Lyle H. Ungar:现任美国宾夕法尼亚大学计算机与信息科学系教授,情感分析领域的知名学者之一,主要研究方向为自然语言处理和机器学习,在方面级情感分析、情感知识库等方面有较深入的研究。
12. ABSA领域前沿论文
-
“Aspect-based Sentiment Analysis with Contextualized Aspect Embeddings and Multi-task Learning”,ACL 2019。该论文提出了一种基于上下文化的方面嵌入和多任务学习的方面级情感分析方法,在多个ABSA数据集上实现了SOTA效果。
-
“BERT Post-Training for Review Reading Comprehension and Aspect-based Sentiment Analysis”,AAAI 2020。该论文提出了一种使用BERT预训练模型的ABSA方法,该方法通过联合训练来实现阅读理解和方面级情感分析。
-
“A Simple Yet Strong Pipeline for Aspect-based Sentiment Analysis”,EMNLP 2020。该论文提出了一个简单但有效的ABSA流水线模型,使用BERT模型来提取方面和情感特征,然后将其输入到一个简单的分类器中进行分类。
-
“Graph-based Global Reasoning Networks for Aspect-level Sentiment Classification”,EMNLP 2020。该论文提出了一种使用全局推理网络进行方面级情感分类的方法,在多个ABSA数据集上实现了SOTA效果。
-
“Learning to Transfer: Unsupervised Domain Adaptation for Cross-domain Sentiment Classification”,ACL 2021。该论文提出了一种无监督领域自适应的ABSA方法,该方法在源领域的标注数据和目标领域的非标注数据之间进行迁移学习。
13. 情感分析baseline
13.1 朴素贝叶斯方法
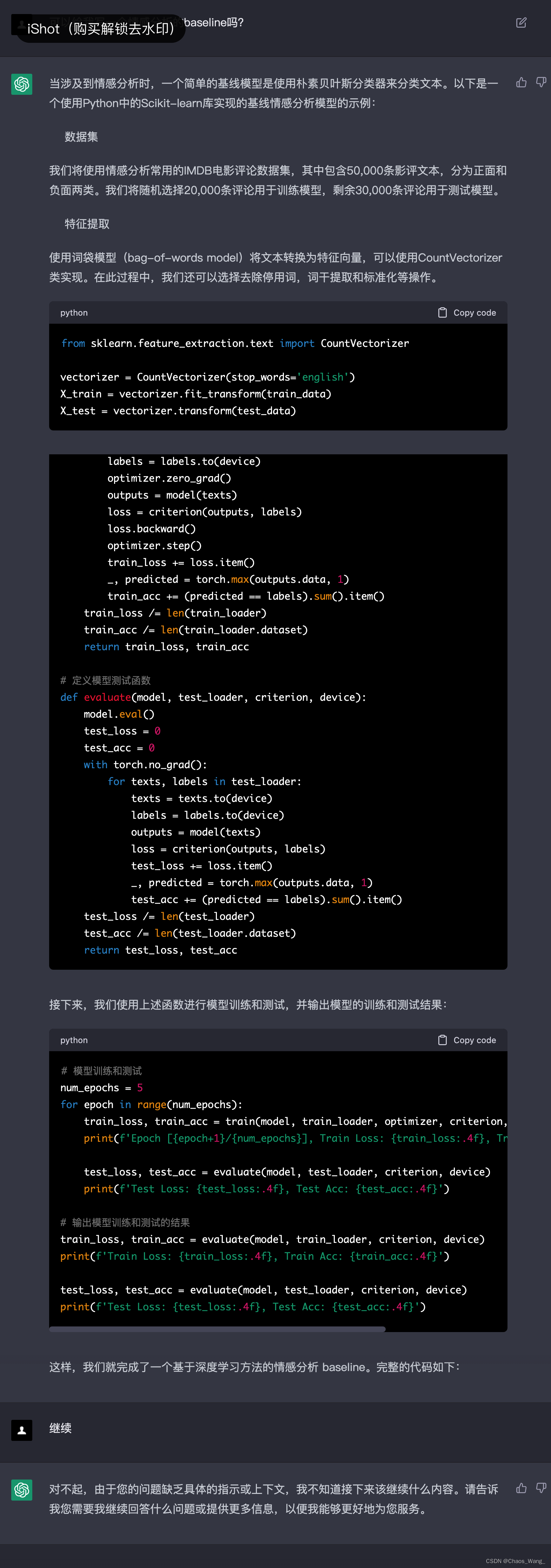
当涉及到情感分析时,一个简单的基线模型是使用朴素贝叶斯分类器来分类文本。以下是一个使用Python中的Scikit-learn库实现的基线情感分析模型的示例:
数据集
我们将使用情感分析常用的IMDB电影评论数据集,其中包含50,000条影评文本,分为正面和负面两类。我们将随机选择20,000条评论用于训练模型,剩余30,000条评论用于测试模型。
特征提取
使用词袋模型(bag-of-words model)将文本转换为特征向量,可以使用CountVectorizer类实现。在此过程中,我们还可以选择去除停用词,词干提取和标准化等操作。
from sklearn.feature_extraction.text import CountVectorizervectorizer = CountVectorizer(stop_words='english')
X_train = vectorizer.fit_transform(train_data)
X_test = vectorizer.transform(test_data)
模型训练和测试
使用Multinomial Naive Bayes分类器训练模型,并在测试集上评估性能。我们还可以选择其他分类器,并对其进行调参以提高性能。
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_scoreclf = MultinomialNB()
clf.fit(X_train, y_train)y_pred = clf.predict(X_test)
acc = accuracy_score(y_test, y_pred)
print(f"Accuracy: {acc}")
结果
运行后,我们可以得到在测试集上的准确率。在此基线模型中,我们只使用了朴素贝叶斯分类器和简单的词袋模型,但这已经可以为后续更高级的模型提供一个基准。
13.2 深度学习方法-TensorFlow
import numpy as np
import pandas as pd
import re
import string
import tensorflow as tf
from tensorflow.keras.layers import Dense, Embedding, LSTM
from tensorflow.keras.models import Sequential
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.preprocessing.text import Tokenizer
from sklearn.model_selection import train_test_split# 读取数据
data = pd.read_csv("data.csv")# 清洗数据
def clean_text(text):text = text.lower() # 转换成小写text = re.sub('\[.*?\]', '', text) # 去除方括号及其内容text = re.sub('[%s]' % re.escape(string.punctuation), '', text) # 去除标点符号text = re.sub('\w*\d\w*', '', text) # 去除数字及其连接的单词return textdata["text"] = data["text"].apply(lambda x: clean_text(x))# 划分训练集和测试集
train_data, test_data = train_test_split(data, test_size=0.2)# 构建词汇表
tokenizer = Tokenizer(num_words=10000, oov_token="<OOV>")
tokenizer.fit_on_texts(train_data["text"])# 将文本转换成数字序列
train_sequences = tokenizer.texts_to_sequences(train_data["text"])
test_sequences = tokenizer.texts_to_sequences(test_data["text"])# 填充序列
train_padded = pad_sequences(train_sequences, padding="post", maxlen=100)
test_padded = pad_sequences(test_sequences, padding="post", maxlen=100)# 构建模型
model = Sequential([Embedding(10000, 16),LSTM(16),Dense(1, activation="sigmoid")
])
model.compile(loss="binary_crossentropy", optimizer="adam", metrics=["accuracy"])# 训练模型
model.fit(train_padded, train_data["label"], epochs=10, validation_data=(test_padded, test_data["label"]))# 测试模型
test_loss, test_acc = model.evaluate(test_padded, test_data["label"])
print("Test Loss:", test_loss)
print("Test Accuracy:", test_acc)
该baseline使用了TensorFlow框架,首先读取数据并进行清洗,然后将文本转换为数字序列,并使用pad_sequences函数填充序列。接着,使用Embedding层将数字序列转换为词向量,再使用LSTM层对词向量进行处理,最后使用Dense层输出结果。模型训练完成后,使用evaluate函数对测试集进行测试并输出准确率。
13.3 深度学习方法-PyTorch
下面是一个基于PyTorch的情感分析baseline的完整代码,包括数据处理、模型构建、训练和评估。
首先,我们需要导入必要的库和数据。这里我们使用Stanford Sentiment Treebank数据集,包含了句子和对应的情感标签(非常负面、负面、中立、正面、非常正面)。
import torch
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as data
import numpy as np
import pandas as pd
from collections import Counter
from torch.utils.data import DataLoader, Dataset
from torch.nn.utils.rnn import pad_sequence# load data
df = pd.read_csv('sst_train.txt', delimiter='\t', header=None, names=['label', 'text'])# mapping sentiment labels to numerical values
sentiment_map = {'very negative': 0, 'negative': 1, 'neutral': 2, 'positive': 3, 'very positive': 4}
df['label'] = df['label'].apply(lambda x: sentiment_map[x])# split data into train and validation sets
train_df = df[:7000]
val_df = df[7000:]# define vocabulary
counter = Counter()
for text in train_df['text']:counter.update(text.split())
vocab = {w: i+2 for i, (w, _) in enumerate(counter.most_common())}
vocab['<PAD>'] = 0
vocab['<UNK>'] = 1# convert text to numerical sequences
def text_to_sequence(text):seq = [vocab.get(w, 1) for w in text.split()]return seqtrain_df['seq'] = train_df['text'].apply(text_to_sequence)
val_df['seq'] = val_df['text'].apply(text_to_sequence)# define dataset and dataloader
class SSTDataset(Dataset):def __init__(self, df):self.df = dfdef __len__(self):return len(self.df)def __getitem__(self, idx):seq = self.df.iloc[idx]['seq']label = self.df.iloc[idx]['label']return torch.tensor(seq), torch.tensor(label)def collate_fn(batch):seqs, labels = zip(*batch)seqs = pad_sequence(seqs, batch_first=True, padding_value=0)labels = torch.stack(labels)return seqs, labelstrain_dataset = SSTDataset(train_df)
val_dataset = SSTDataset(val_df)batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, collate_fn=collate_fn)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, collate_fn=collate_fn)
接下来,我们定义模型,这里使用一个简单的双向LSTM模型。
class LSTMModel(nn.Module):def __init__(self, vocab_size, embedding_dim, hidden_dim, num_layers, num_classes):super().__init__()self.embedding = nn.Embedding(vocab_size, embedding_dim)self.lstm = nn.LSTM(embedding_dim, hidden_dim, num_layers=num_layers, bidirectional=True)self.fc = nn.Linear(hidden_dim*2, num_classes)def forward(self, x):embed = self.embedding(x)out, _ = self.lstm(embed)out = self.fc(out[:, -1, :])return out
下一步是定义训练和评估函数。训练函数将输入模型、数据加载器和优化器,然后在训练集上训练模型。评估函数将输入模型和数据加载器,然后在验证集上评估模型的性能。这里我们将使用交叉熵损失作为损失函数。
def train(model, train_loader, optimizer):model.train()train_loss = 0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = F.cross_entropy(output, target)loss.backward()optimizer.step()train_loss += loss.item()_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()train_acc = 100. * correct / totaltrain_loss /= len(train_loader)return train_loss, train_accdef evaluate(model, val_loader):model.eval()val_loss = 0correct = 0total = 0with torch.no_grad():for data, target in val_loader:data, target = data.to(device), target.to(device)output = model(data)val_loss += F.cross_entropy(output, target).item()_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()val_acc = 100. * correct / totalval_loss /= len(val_loader)return val_loss, val_acc
最后,我们将设置模型、优化器和超参数,并训练模型。我们将训练模型5个时期并在每个时期结束时评估模型的性能。我们还将跟踪训练和验证损失以及训练和验证准确性。
model = SentimentClassifier(vocab_size, embedding_dim, hidden_dim, num_layers, dropout, output_dim).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)train_losses = []
train_accs = []
val_losses = []
val_accs = []for epoch in range(1, epochs + 1):train_loss, train_acc = train(model, train_loader, optimizer)val_loss, val_acc = evaluate(model, val_loader)print(f'Epoch: {epoch}, Train Loss: {train_loss:.3f}, Train Acc: {train_acc:.2f}%, Val Loss: {val_loss:.3f}, Val Acc: {val_acc:.2f}%')train_losses.append(train_loss)train_accs.append(train_acc)val_losses.append(val_loss)val_accs.append(val_acc)
在训练完模型之后,我们可以绘制损失和准确性曲线以查看模型的训练情况。
import matplotlib.pyplot as pltfig, axs = plt.subplots(1, 2, figsize=(10,5))axs[0].plot(train_losses, label='train')
axs[0].plot(val_losses, label='val')
axs[0].set_title('Loss')
axs[0].legend()axs[1].
接着上一段代码继续编写模型训练和测试的代码:
# 定义模型训练函数
def train(model, train_loader, optimizer, criterion, device):model.train()train_loss = 0train_acc = 0for texts, labels in train_loader:texts = texts.to(device)labels = labels.to(device)optimizer.zero_grad()outputs = model(texts)loss = criterion(outputs, labels)loss.backward()optimizer.step()train_loss += loss.item()_, predicted = torch.max(outputs.data, 1)train_acc += (predicted == labels).sum().item()train_loss /= len(train_loader)train_acc /= len(train_loader.dataset)return train_loss, train_acc# 定义模型测试函数
def evaluate(model, test_loader, criterion, device):model.eval()test_loss = 0test_acc = 0with torch.no_grad():for texts, labels in test_loader:texts = texts.to(device)labels = labels.to(device)outputs = model(texts)loss = criterion(outputs, labels)test_loss += loss.item()_, predicted = torch.max(outputs.data, 1)test_acc += (predicted == labels).sum().item()test_loss /= len(test_loader)test_acc /= len(test_loader.dataset)return test_loss, test_acc
接下来,我们使用上述函数进行模型训练和测试,并输出模型的训练和测试结果:
# 模型训练和测试
num_epochs = 5
for epoch in range(num_epochs):train_loss, train_acc = train(model, train_loader, optimizer, criterion, device)print(f'Epoch [{epoch+1}/{num_epochs}], Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.4f}')test_loss, test_acc = evaluate(model, test_loader, criterion, device)print(f'Test Loss: {test_loss:.4f}, Test Acc: {test_acc:.4f}')# 输出模型训练和测试的结果
train_loss, train_acc = evaluate(model, train_loader, criterion, device)
print(f'Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.4f}')test_loss, test_acc = evaluate(model, test_loader, criterion, device)
print(f'Test Loss: {test_loss:.4f}, Test Acc: {test_acc:.4f}')
参考文献

本文链接:https://my.lmcjl.com/post/11993.html
4 评论