Cross-Resolution Semi-Supervised Adversarial Learning for Pansharpening
(用于泛锐化的交叉分辨率半监督对抗学习)
现有的基于深度神经网络(DNN)的方法已经产生了良好的泛锐化图像。然而,监督DNN为基础的泛锐化方法遭受性能下降时,融合低空间分辨率多光谱(LR MS)和全色(PAN)图像在全分辨率。基于无监督DNN的方法缓解了这个问题,但由于缺乏参考图像,它们的训练变得困难。本文建立了一个新的半监督框架,以共同学习从降低和全分辨率数据集的融合图像的重建。具体来说,我们提出了一个跨分辨率半监督对抗学习网络(CrossNet),它由一个监督模块和一个无监督模块组成。在这两个模块中,低分辨率或全分辨率源图像通过重建融合图像分解为分辨率不变分量和分辨率感知分量。此外,交叉分辨率融合图像的合成,以提高两种成分的解纠缠。通过重建的跨分辨率融合图像,监督和非监督模块也有效地耦合。然后,半监督框架可以同时利用降低分辨率数据集中的监督信息,并通过全分辨率数据集减轻性能下降。此外,对抗性学习被用来提高源图像在不同分辨率下的分辨率不变分量之间的一致性。最后,广泛的实验QuickBird,GeoEye-1,WorldView-2,和WorldView-3数据集表明,所提出的CrossNet可以产生最先进的融合结果定性和定量评估。
Introduction
随着成像技术的迅速发展,GeoEye-1、QuickBird、高分1/2等遥感卫星相继发射。这些卫星正在收集越来越多的多光谱(MS)和全色(PAN)图像,用于地球观测任务,包括土地覆盖分类、变化检测和目标跟踪。然而,由于成像传感器的限制,这些卫星捕获的MS图像具有比PAN图像更低的空间分辨率。相反,PAN图像的光谱分辨率低于MS图像的光谱分辨率。对于这些卫星,很难直接获得高空间分辨率MS(HR MS)图像。因此,研究人员采用泛锐化技术来融合低空间分辨率MS(LR MS)和PAN图像,以生成HR MS图像。
过去三十年见证了这一领域的显著繁荣。已经提出了许多泛锐化方法,它们通常可以分为四个范例:基于组分替代(CS)的方法、基于多分辨率分析(MRA)的方法、基于退化模型(DM)的方法和基于深度神经网络(DNN)的方法。
基于CS的方法认为,在LR MS图像中的空间和光谱信息可以通过一些变换独立地分离。然后,LR MS图像的空间信息可以由PAN图像代替。最后,对新的空间和光谱信息施加相应的逆变换以产生HR MS图像。在基于CS的方法中,广泛使用的变换是主成分分析,强度色调饱和度,Gram-Schmidt(GS)和波段相关空间细节。这些方法的融合图像表现出良好的性能,在空间增强。然而,光谱信息不能很好地保存,因为大的光谱范围差异之间的LR MS和PAN图像。基于MRA的方法通过将PAN图像的空间细节注入LR MS图像中来产生HR MS图像。具体而言,MRA工具用于空间细节的建模,包括拉普拉斯金字塔、小波和轮廓波。基于MRA的方法在光谱保持方面具有高保真度。但是由于源图像中的局部不相似性,一些空间伪影可能被引入到融合图像中。在基于DM的方法中,LR MS和PAN图像分别被公式化为HR MS图像在空间和光谱域中的退化结果。例如,Wang等人和 Li等人采用MS图像中所有波段的线性组合作为光谱退化以产生合成PAN图像。在这些方法中,不同波段的组合系数是从MS和PAN图像的光谱响应导出的。然后,通过求解空间和光谱DM来获取期望的HR MS图像。为了正则化模型的解空间,挖掘各种先验,如稀疏性,非负性和总变差来约束不适定的逆问题。属于第三范式的方法综合令人满意的结果。然而,它们的计算复杂度是相当大的,因为DM迭代优化。
近年来,基于DNN的方法引起了人们的广泛关注,并取得了良好的性能。根据训练需要地面真值还是参考图像,这些方法可以分为两类:监督方法和非监督方法。
第一种基于DNN的方法由于监督信息的可用性而被广泛研究,并且已经提出了各种网络。例如,Masi等人首先采用了由三层组成的卷积神经网络(CNN)来融合LR MS和PAN图像。随后,在[24]中进一步开发了该方法,以通过目标自适应策略获得性能增益。Yang等人构建了一个残差网络来学习空间细节,并将其注入到上采样的LR MS图像中。考虑到双输入的情况,设计了一些双流网络来从LR MS和PAN图像中提取空间和光谱特征。例如,Zhang等人使用双流网络提取空间和光谱特征,这些特征由级联自适应融合模块集成。Yang等人提出了一种具有残差学习的双流CNN,以学习更多信息的空间特征。作为一个强大的生成模型,生成对抗网络(GAN)在这个任务中也表现出良好的能力。Zhao等人提出了一种轻量级GAN来融合LR MS和PAN图像,其中利用快速引导滤波器来保留融合图像中的空间细节。此外,最近发明的网络transformer被应用于该领域,因为它可以更好地捕获全局属性。例如,Cao等人提出了一种用于全色锐化的空间-光谱交互变换器。该方法通过变换器充分利用图像在不同尺度下的全局信息。最近,模型驱动的DNN也被探索以生成HR MS图像。Yan等人将DNN嵌入CS和MRA框架中,以提高其表示能力和可解释性。由于物理模型的约束,模型驱动的DNN在融合图像的空间和光谱保留方面表现得更好。上述方法可以在监督信息的帮助下充分训练。然而,必须合成分辨率降低的数据,其中原始MS和PAN图像由手工操作者在空间上降级。然后,原始MS图像被视为用于训练的参考图像。但是真实的场景中的空间退化过程非常复杂,无法通过手工操作精确建模。因此,在分辨率降低的数据上训练的DNN模型在应用于以全分辨率融合源图像时可能会遭受性能下降。
考虑到降低分辨率和全分辨率图像之间差距,研究人员将重点转移到无监督方案,即直接在全分辨率LR MS和PAN图像上训练DNN。由于预训练模型已经产生了显着的改进,因此开发了一些两阶段方法,其中包括预训练和微调。例如,Wang等人利用降低分辨率的数据来训练三流融合网络,该网络通过自适应损失进行微调。Chen等人提出了一种迭代残差网络,该网络在降低分辨率和全分辨率数据集上连续训练。在无监督的情况下,GAN也被考虑并用于区分真实的源图像和合成源图像。在[46]中,引入了两个鉴别器,它们分别负责保存空间和光谱信息。在类似的框架下,Xu 等人还建立了一个生成器和两个鉴别器之间的对抗学习,其中计算均值差图像以改善融合结果的重建。由于缺乏监督信息,一些研究人员设计了更复杂的损失,以确保融合图像的质量。除了空间和光谱退化损失,Luo等人使用两个指标,结构相似性(SSIM)和无参考质量(QNR)来约束网络的训练。Ni等人利用模糊块和灰色块来描述融合图像和源图像之间的空间和光谱退化,这更好地拟合退化过程。此外,Qu等人设计了一种无监督的自我注意机制,它明确地提取细节,并将它们注入空间变化的方式。Zhou等人使用循环一致性损失和对抗学习来提高无监督模型的融合性能。
基于无监督DNN的方法减轻了对配对图像的需求,因为它们直接在没有参考图像的全分辨率数据集上训练。因此,它们避免了与分辨率相关的差距所引起的问题。然而,由于参考图像的不存在,无监督DNN很难训练。需要仔细设计复杂的训练框架或损失,以确保良好的融合性能。
为了同时利用降分辨率数据中的监督信息和通过全分辨率数据来缓解分辨率差距,本文建立了一种新的半监督学习框架,该框架将降分辨率数据集中的成对图像和全分辨率数据集中的未成对图像集成在一起进行训练。具体来说,我们提出了一个跨分辨率半监督对抗学习网络(CrossNet),其中不同分辨率的源图像分别通过分辨率不变模块(RIM) 和 分辨率感知模块(RAM) 分解为分辨率不变组件和分辨率感知组件。对于相应的降分辨率源图像和全分辨率源图像,它们之间的差异主要是高频的丰富度,也称为空间细节。因此,低分辨率源图像中的高频被认为是它们的分辨率感知分量。然后,低频被认为是源图像的分辨率不变的分量。在解纠缠的分辨率不变和感知组件的分辨率降低的源图像,它们被重新组合,以重建的降低分辨率的融合图像的监督地面真相。类似地,全分辨率源图像也被分解为分辨率不变和感知组件。但是,这些组件被用来合成全分辨率融合图像在一个无监督的方式,因为地面真相是不存在的。此外,我们使用融合图像的交叉分辨率重建连接监督和无监督计划。由于在所提出的框架中利用了监督和非监督信息,因此它被称为半监督学习。此外,我们假设降低和全分辨率图像的分辨率不变的组件是相同的。因此,引入对抗学习以确保源图像在不同分辨率下的分辨率不变分量之间的一致性。通过半监督公式,提出的CrossNet可以有效地使用监督信息在降低分辨率的数据和学习的真实的分布在全分辨率的数据。在不同卫星数据集上的实验结果证明了所提出的CrossNet的有效性。
据我们所知,这篇文章是第一篇在降低分辨率和全分辨率数据集上实现DNN联合训练的文章。图1展示了我们提出的CrossNet与其他基于对抗学习的网络之间的差异,例如基于GAN的泛锐化(PSGAN)和Pan-GAN 。从图1(a)可以看出,PSGAN仅使用降低分辨率的数据进行训练,并且利用鉴别器来区分融合图像和参考图像。相反,图1(b)中的Pan-GAN直接在全分辨率数据上训练,并且考虑两个鉴别器以确保融合图像中的空间和光谱信息。对于图1©中所提出的CrossNet,同时采用降低和全分辨率数据。对抗学习施加在分类器上,以区分来自不同分辨率的分辨率不变分量。本文的贡献概括如下:
1)数据集在统一的框架中。与监督或无监督方法相比,所提出的半监督框架可以更好地同时利用降低分辨率和全分辨率数据集,从而提高融合图像的质量。
2)我们分解源图像在不同的分辨率作为分辨率不变和感知组件。通过重建全分辨率或降低分辨率的融合图像,实现了在相同分辨率下两种分量之间的兼容性。在不同分辨率的组件被用来产生交叉融合的图像解纠缠学习。
3)我们采用对抗学习,以进一步提高分辨率不变组件在不同分辨率之间的一致性。它增强了无监督模块和监督模块的耦合。
PROPOSED METHOD
框架
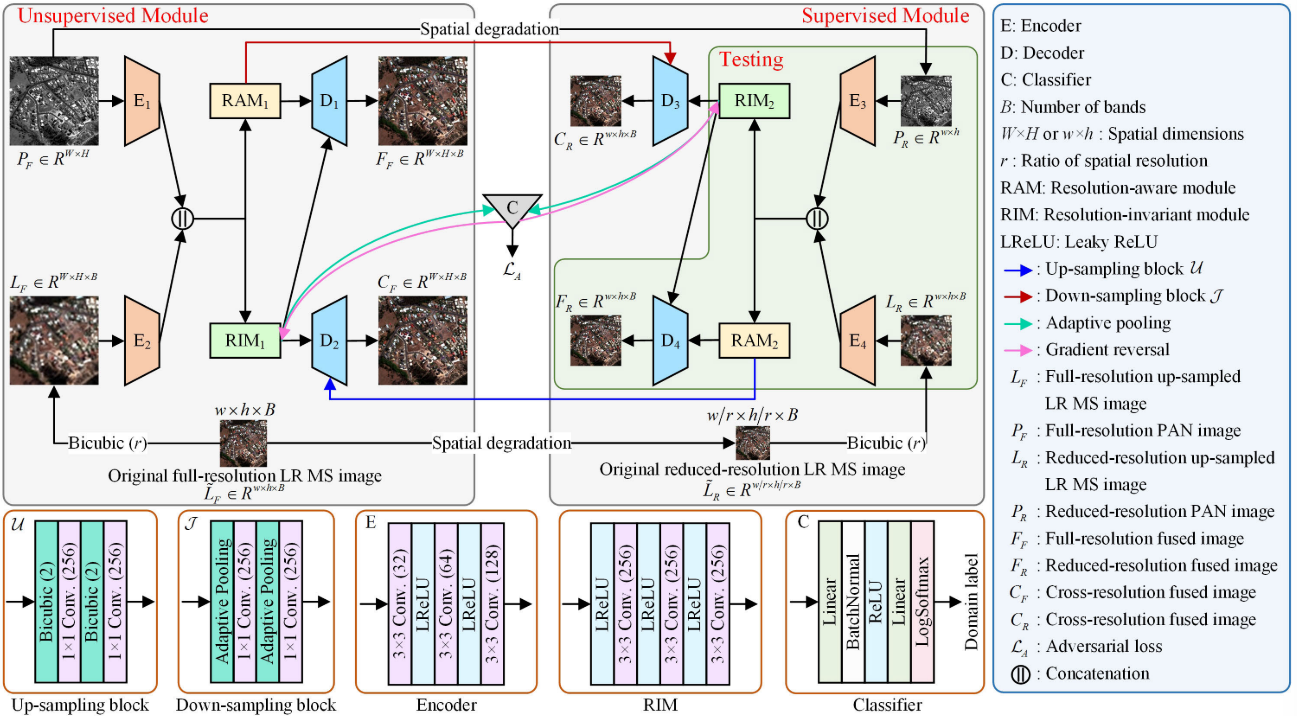
图2示出了所提出的CrossNet的框架。它由无监督和监督模块组成,它们共同学习从降低分辨率和全分辨率数据融合图像的重建映射。无监督模块和监督模块都由两个编码器、两个解码器、RIM和RAM组成。输入图像首先由相应的编码器投影到特征空间中。然后,RIM和RAM被用来解开分辨率不变组件和分辨率感知组件的级联特征。最后,解码器对解纠缠分量进行积分,重构融合图像。
在CrossNet中,原始全分辨率LR MS图像~L F ∈ R w × h × B R^{w×h×B} Rw×h×B和PAN图像PF ∈ R W × H R^{W×H} RW×H被考虑用于无监督学习。~L F 的空间和光谱维度分别为w × h和B。PF的尺寸为W × H。为了便于在特征空间中进行级联,对~L F 进行插值以获得上采样版本LF ∈ R w × h × B R^{w×h×B} Rw×h×B,然后将其馈送到对应的编码器E2中。在监督模块中,通过下采样和模糊来对~L F 和PF 进行空间降级,以分别生成分辨率降低的LR MS图像~L F ∈ R w / r × h / r × B R^{w/r ×h/r ×B} Rw/r×h/r×B和PAN图像PR ∈ R w × h R^{w×h} Rw×h。然后,原始全分辨率LR MS图像L ~ F被视为用于监督学习的基础事实。类似于无监督模块中的输入,~L R 也通过双三次算子进行上采样,并且上采样结果LR被视为后续编码器E4的输入。
在半监督框架中,无监督和监督模块通过在降低的和全分辨率下融合图像的跨分辨率重建来桥接。以无监督模块为例,将来自RIM1和RAM1的特征混合,通过解码器D1生成全分辨率融合图像FF ∈ R W × H × B R^{W×H×B} RW×H×B。通过组合来自RIM1的特征和来自RAM2的上采样特征来产生交叉分辨率融合图像CF ∈ R W × H × B R^{W×H×B} RW×H×B。在监督模块中也制定了类似的架构以产生降低分辨率的融合图像FR ∈ R w × h × B R^{w×h×B} Rw×h×B和交叉分辨率的融合图像CR ∈ R w × h × B R^{w×h×B} Rw×h×B。在提出的CrossNet中,来自无监督和监督模块的分辨率不变组件被视为输入图像的低频特征,并且在统计上是相似的。为了提高这两个组件之间的一致性,引入对抗学习,这是通过最大化的损失域分类器。因此,对抗学习鼓励无监督和监督模块中的RIM1和RIM2学习分辨率不变的信息。
最后,无监督和监督的模块进行联合训练,然后,我们采用的网络重建的降低分辨率的融合图像FR进行测试。
Unsupervised Module
根据图2中的公式,利用解纠缠表示对源图像中分辨率不变和分辨率感知的分量进行建模。解纠缠表示旨在学习特征空间中数据变化的潜在因素。例如,Cao等人通过解纠缠表示将LR MS和PAN图像编码为共同特征和独特特征。假设图像的轮廓和形状包含在它们的共同特征中。光谱信息和空间细节分别被认为是LR MS和PAN图像独特的功能。
在本文中,我们将降低分辨率的数据和全分辨率数据集成起来进行训练。这两种数据之间的主要区别是空间细节的丰富性。因此,我们将源图像中的空间细节视为分辨率感知组件。然后,低频被认为是源图像的分辨率不变的分量。在分析之后,我们采用解纠缠表示来分离源图像中的分辨率感知和不变分量。在无监督模块的情况下,解纠缠被定义为
其中XA和XI分别是PF和LF中的分辨率感知和不变分量。Concat(·)是级联运算。类似地,分辨率降低的源图像PR和LR被分解为

在无监督模块中,两个融合的图像,FF和CF,被重建,以平衡解纠缠的分辨率感知和不变的组件在图像中。XA和XI被重新组合以产生全分辨率融合图像FF,这确保了它们之间的兼容性。FF的重构被写为
通过(3)中的重建和(4)中的交叉分辨率重建,我们可以获得两个融合图像,即,FF和CF。然而,地面实况在无监督模块中不可用,其不能为FF和CF提供监督信息。因此,我们利用融合图像和源图像之间的空间和光谱退化关系来约束无监督模块的训练。然后,无监督损失可以定义为
其中Spa(·)和Spe(·)分别表示空间和光谱退化算子。具体地,我们将高斯滤波和下采样设置为比率为4,因为Spa(·)和Spe(·)是沿着MS图像的光谱维度的线性平均操作。
Supervised Module
在监督模块中,还生成两幅分辨率降低的融合图像。对于FR,其通过解码来自RIM2的分辨率不变分量YI和来自RAM2的分辨率感知分量YA的重组来获得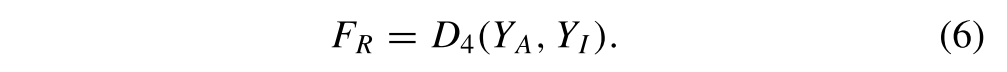
YI足够了。然后,使用无监督模块中的RAM1的XA来获得跨分辨率融合图像CR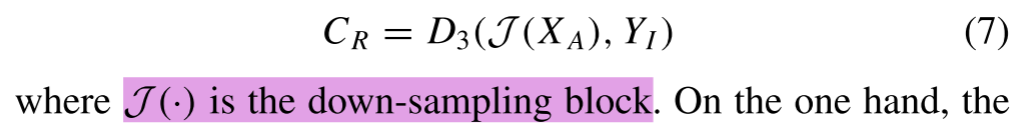
一方面,CR的重建有助于RIM2和RAM2更好地解开分辨率不变和分辨率感知分量。另一方面,XA的引入缓解了监督模块中的分辨率差距。
最后,产生FR和CR以近似真实值~L F。因此,监督损失被定义为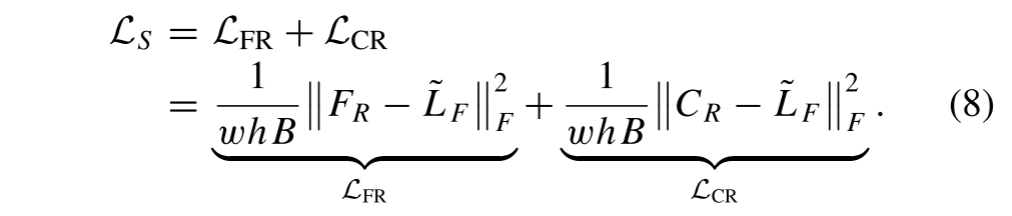
Cross-Resolution Adversarial Learning
在CrossNet中,无监督和监督模块中的源图像都被解纠缠为相应的分辨率感知和分辨率不变组件。我们假设分辨率不变分量是与分辨率无关的特征,它包含了源图像中的低频部分。因此,XI和YI在内容信息方面是一致的。为了提高它们之间的一致性,我们引入了一个领域分类器到建议的CrossNet对抗学习。具体来说,RIM1和RIM2旨在生成分辨率不变的组件,这会混淆域分类器。相反,域分类器尽力区分分辨率不变分量是来自全分辨率域还是来自降低分辨率域。
根据上面的分析,通过最大化交叉熵损失来实现分辨率不变分量的对抗学习

其中d是域标签。d = 0和d = 1分别对应于全分辨率域和降低分辨率域。C(·)代表域分类器。图2中的自适应池化表示为AP(·)。x是来自RIMl的Xl或来自RIM2的Yl。
由于对抗学习的引入,随机梯度下降不能直接在领域分类器RIM1和RIM2的联合优化上实现。为了同时实现域分类损失的最大化和融合损失的最小化,梯度反转层被插入到域分类器和RIM1或RIM2之间的反向传播中。该层不包含任何可训练参数。当误差反向传播时,梯度乘以-1,然后传递给前面的模块。在前向传播期间,梯度反转层可以被视为单位变换。
Architecture Details
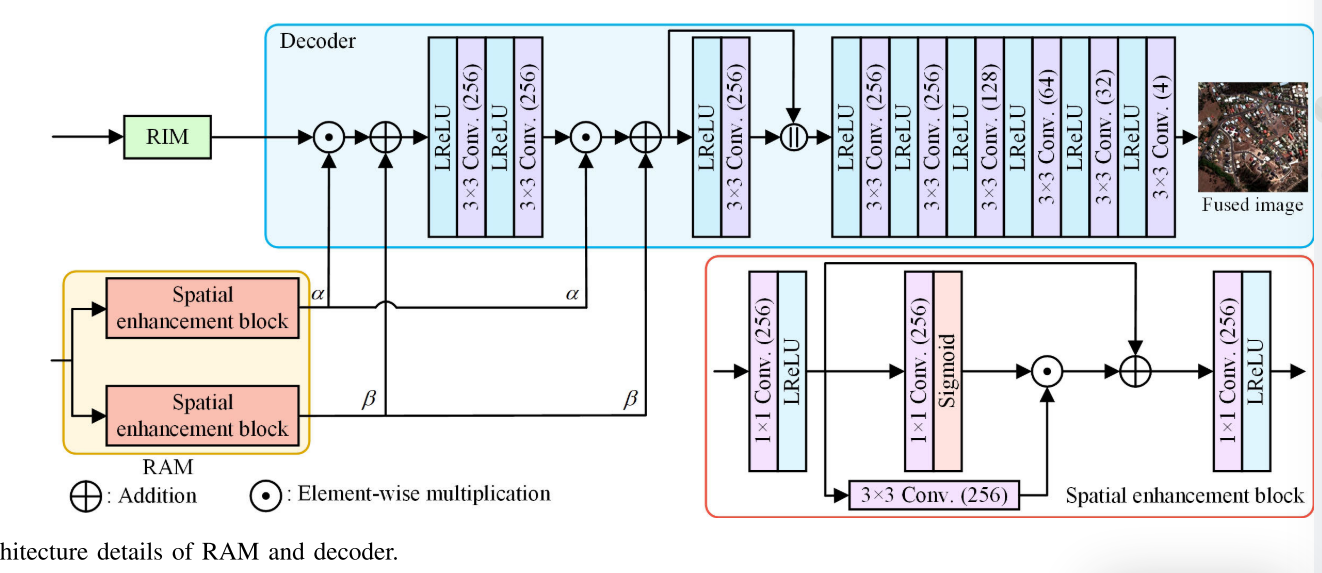
在提出的CrossNet中,源图像由RIMs和RAMs解缠。然后,从这些模块的特征被耦合到重建融合图像由其相应的解码器。图3示出了RAM和解码器的架构细节。为了有效地提取源图像中的空间细节,我们设计了一个空间增强块,如图3所示。然后,使用两个空间增强块来形成RAM。最后,来自RIM的分辨率不变分量和来自RAM的分辨率感知分量被馈送到解码器。
以FR的重建为例,首先融合来自RAM2的YA = {α,β}和来自RIM2的YI,并且特征融合(FF)被定义为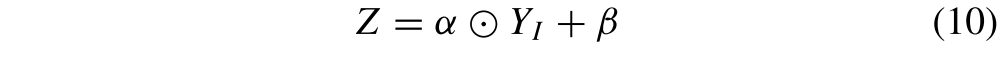
其中Z是YA和Yl的融合特征。⊙表示元素乘法。为了将RAM的空间细节充分地注入到融合图像FR中,(10)中的FF也被实现在图3中所示的更深层处的特征上。最后,我们可以从对应的解码器D4获得FR。对于FF的重构,FF类似于(10)中的FF。当我们使用D2和D3产生CF和CR时,α和β应该被上采样或下采样以匹配来自RIM的特征的大小。
当FF、CF、FR和CR由解码器重构时,通过最小化以下总损失LT以半监督方式训练所提出的CrossNet:
在训练后的模型中,我们采用网络重建的低分辨率融合图像FR作为测试模型。在第III-F节中,我们探索了不同网络在无监督和有监督模块中产生的融合结果。
EXPERIMENTS
在本节中,我们对来自GeoEye-1,QuickBird,WorldView-2和WorldView-3卫星的数据集进行了广泛的实验,以证明所提出的CrossNet的有效性。
Experimental Setting
1) Datasets: 所提出的CrossNet同时在降低分辨率和全分辨率数据集上进行训练。考虑与[58]中相同的划分方式来准备本节中使用的数据集。具体来说,我们首先准备全分辨率数据集,然后在空间上降级以合成相应的降低分辨率数据集。对于QuickBird数据集,裁剪1100对全分辨率LR MS和PAN图像以形成全分辨率数据集。全分辨率LR MS和PAN图像的尺寸分别为64 × 64和256 × 256。然后,对全分辨率图像进行降采样和模糊处理,生成分辨率分别为16 × 16和64 × 64的LLR MS和PAN图像。因此,降低分辨率的数据集还包含1100对LR MS和PAN图像。
2) Compared Methods and Indexes:
在下面的部分中,将提出的CrossNet与11种方法进行比较,包括Indusion ,GS ,调制传递函数(MTF)-广义拉普拉斯金字塔(GLP),具有MTF匹配滤波器的GLP,乘法注入模型和后处理(MTF-GLP-HPM-PP),基于平滑滤波器的强度调制(SFIM),PSGAN,双流融合网络(TFNet)、基于CNN的全色锐化(PNN)、全色锐化网络(PanNet)、增强型PanNet和融合网络(Fusion-Net)。所有方法的降低分辨率融合图像通过基于参考的指标进行评估,例如均方根误差(RMSE),相对无量纲全局合成误差(ERGAS),光谱角映射器(SAM),Q4和通用图像质量指数(UIQI)。对于全分辨率融合图像,DS和Dλ 分别用于评估其空间和光谱信息。通过组合DS和Dλ,质量无参考(QNR)被设计为提供融合图像的总体评估。
3) Implementation Details: CrossNet基于PyTorch框架构建,并在NVIDIA GeForce RTX 3090 GPU上进行训练。具体来说,亚当优化器被认为是最小化损失函数,学习率被设置为10 - 4。批量大小为2,训练时期的数量设置为200。此外,为了公平比较所有基于DNN的方法,我们在验证数据集上验证了每个时期的训练模型,并使用SAM作为指标来找到最佳模型。对于特定的模型,如果它在验证数据集中产生最小SAM,我们将使用该模型进行测试。以这种方式,可以确保所有基于DNN的方法实现其自身的最佳性能。
Experiments on Reduced-Resolution Datasets
在本节中,将在GeoEye-1、QuickBird、WorldView-2和WorldView-3数据集上进行降低分辨率的实验。图4-7分别显示了所有方法在四个数据集上的融合结果。它们对应的绝对误差图4-7也在图的第二行和第四行中给出。此外,选择一个局部区域进行更直接的比较,其放大的版本由红色矩形突出显示,并放置在融合图像的右下角。
从图4中,我们可以看到,一些传统方法,如GS和MTF-GLP-HPM-PP,遭受光谱失真,这在其放大区域中更明显。此外,传统方法的误差图表现出更大的重建误差比基于DNN的方法,特别是在建筑物区域。基于DNN的方法在空间细节方面具有接近的性能。然而,在PSGAN和PNN的融合结果中,可以发现轻微的频谱失真。从图4中的误差图,可以看出,当与其他基于DNN的方法相比时,所提出的CrossNet更好地逼近参考图像。表II示出了所提出的CrossNet在所有指标方面获得最佳值,这验证了所提出的半监督学习框架的有效性。此外,我们可以看到PNN在这个表中比PanNet更好。类似的现象也可以在[65][66]和[67]发现。
PanNet结果中的失真可能是由过度的空间注入引起的。图中的误差图。结果表明,本文提出的CrossNet算法在重构融合图像方面优于其他算法。表III提供了所有方法在30对LR MS和PAN图像上的平均值。最佳值以粗体突出显示。在表III中,我们可以看到最佳值是由建议的CrossNet产生的。因此,所提出的半监督学习可以更好地学习图像中的空间和光谱信息。
在图6中,显而易见的是,MTF-GLP-HPM-PP、PSGAN和PNN表现出一些光谱失真,诸如放大区域中的蓝色色调的变暗,其与参考图像明显可区分。关于空间细节,我们观察到,传统的方法表现出更明显的轮廓在误差图,从参考图像的差异更大。虽然增强型PanNet和Fusion-Net的性能略好于其他基于DNN的方法,但它们在保留光谱信息方面不如我们的方法,如错误图所示。表IV表明,我们的方法在所有指标中实现了最佳值,这证实了我们方法的有效性。
在图7中,我们观察到我们的方法与缩放区域中的其他方法相比,在蓝色屋顶方面产生更清晰的细节。误差图表明,传统方法和基于DNN的方法,如PSGAN,TFNet,PNN,与参考图像相比,有明显的误差。此外,除了Fusion-Net中的SAM值之外,我们的方法在表V的所有度量中实现了最佳结果。但是我们提出的CrossNet提供了第二好的SAM。
本文链接:https://my.lmcjl.com/post/12208.html
4 评论