一、问题
在好大夫在线内部,S3系统负责各业务方操作日志的集中存储、查询和管理。目前,该系统日均查询量数千万次,插入量数十万次。随着日志量的不断累积,主表已经达到数十亿,单表占用磁盘空间400G+。S3是业务早期就存在的系统,当时为了简单快速落地,使用了MySQL来存储,随着业务的不断增长,同时也要兼顾性能和可扩展性,到了必须要重新选型的时候了。
新项目命名为:LogStore。
二、目标
1、安全性
S3系统在设计之初,没有按业务系统考虑数据隔离,而是直接采用 key(系统 + 类名 + id) + 有限固定字段 + 序列化value 的方式进行存储,这种方式显然不便于后续集群拆分和管理。LogStore系统要在逻辑上进行数据区域划分,业务方在接入时要指定app进行必要的权限验证,以区分不同业务数据,进而再进行插入和查询操作。
2、通用性
S3主要提供一种3层结构,采用MySQL固定字段进行存储,这就不可避免的会造成字段空间的浪费。LogStore系统需要提供一种通用的日志存储格式,由业务方自行规定字段含义,并且保留一定程度的可查询维度。
3、高性能
S3系统的QPS在300+,单条数据最大1KB左右。LogStore系统要支持当前QPS 10倍以上的写入和读取速度。
4、可审计
要满足内部安全审计的要求,LogStore系统不提供对数据的更新,只允许数据的插入和查询。
5、易扩展
LogStore系统以及底层存储要满足可扩展特性,可以在线扩容,满足公司未来5年甚至更长时间的日志存储需求,并且要最大化节省磁盘空间。
三、方案选型
为了达成改造目标,本次调研了四种存储改造方案,各种方案对比如下:

1、我们不合适—分库分表
分库分表主要分为应用层依赖类中间件和代理中间件,无论哪种均需要修改现有PHP和Java框架,同时对DBA管理数据也带来一定的操作困难。为了降低架构复杂度,架构团队否定了引入DB中间件的方案,还是要求运维简单、成本低的方案。
2、我们不合适—TiDB
TiDB也曾一度进入了我们重点调研对象,只是由于目前公司的DB生态主要还是在MGR、MongoDB、MySQL上,在可预见的需求中,也没有能充分发挥TiDB的场景,所以就暂时搁置了。
3、我们不合适—ElasticSearch
ELK-stack提供的套件确实让ES很有吸引力,公司用ES集群也有较长时间了。ES优势在于检索和数据分析领域,也正是因为其检索和分析的功能的强大,无论写入、查询和存储成本都比较高,在日志处理的这个场景下,性价比略低,所以也被pass了。
4、适合的选择—MongoDB
业务操作日志读多写少,很适合文档型数据库MongoDB的特点。同时,MongoDB在业界得到了广泛的使用,公司也有很多业务在使用,在MongoDB上积累了一定的运维经验,最终决定选择MongoDB作为新日志系统存储方案。
四、性能测试
为了验证MongoDB的性能能否达到要求,我们搭建了MongoDB集群,机器配置、架构图和测试结果如下:
1、机器配置
MongoDB集群3台机器配置如下:
|
CPU |
内存 |
硬盘 |
OS |
Mongo版本 |
|
8核 |
15G MongoDB 内存分配单节点8G |
100G |
CentOS release 6.6 (Final) |
3.2.17 |
2、架构图架构图
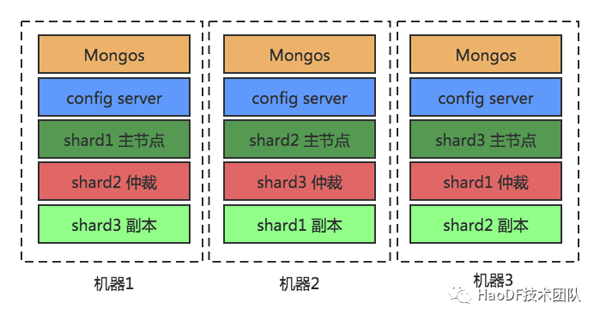
3、测试场景架构图
本次MongoDB测试采用YCSB(https://github.com/brianfrankcooper/YCSB)性能测试工具,ycsb的workloads目录下保存了6种不同的workload类型,代表了不同的压测负载类型,本次我们只用到了其中5种,具体场景和测试结果如下。
|
workloada |
100%插入,用来加载测试数据 |
|
workloadb |
读多写少,90%读,10%更新。 |
|
workloadc |
读多写少,100%读。 |
|
workloadd |
读多写少,90%读,10%插入。 |
|
workloadf |
混合读写,50%读,25%插入、25%更新 |
(1) 插入平均文档大小为5K,数据量为100万,并发100,数据量总共5.265G 左右,执行的时间以及磁盘压力:
结论:插入100w数据,总耗时219s,平均insert耗时21.8ms,吞吐量4568/s。
(2) 测试90%读,10%更新,并发100的场景:
结论:总耗时236s,read平均耗时23.6ms,update平均耗时23.56ms,吞吐量达到4225/s。
(3) 测试读多写少,100%读 ,并发100场景:
结论:总耗时123s,平均read耗时12.3ms,吞吐量达到8090/s。
(4) 测试读多写少,90%读,10%插入,并发100的场景:
结论:总耗时220s,read平均耗时21.9ms,insert平均耗时21.9ms,吞吐量达到4541/s。
(5) 测试混合读写,50%读,25%插入、25%更新,并发100的场景:
结论:总耗时267s,read平均耗时26.7ms,update平均耗时26.7ms,insert平均耗时26.6ms,吞吐量为3739/s。
4、测试结果对比架构图

可以看出MongoDB适合读多写少的时候,性能最好,读写速率能满足生产需求。
五、无缝迁移实践
为了保障业务的无缝迁移,也为了最大化降低业务研发同学的投入成本,我们决定采用分阶段切换的方案。
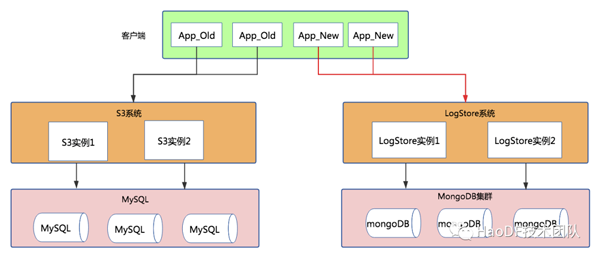
第一步:系统应用层改造+LogStore系统搭建
首先,在S3系统中内置读开关和写开关,可将读写流量分别引入到LogStore系统中,而新应用的接入可以直接调用LogStore系统,此时结构示意图如下。
第二步:增量数据同步
为了让S3系统和LogStore系统中新增数据达到一致,在底层数据库采用Maxwell订阅MySQL Binlog的方式同步到MongoDB中,示意图如下:
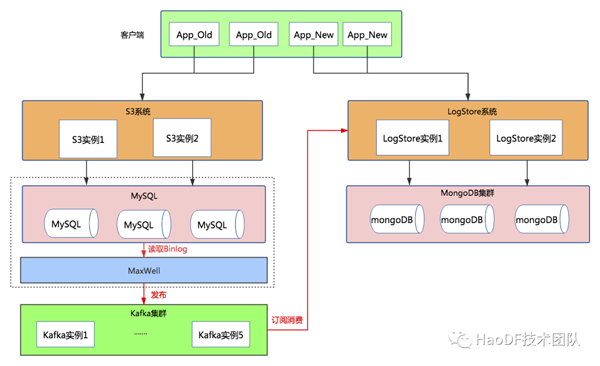
Maxwell(http://maxwells-daemon.io)实时读取MySQL二进制日志binlog,并生成 JSON 格式的消息,作为生产者发送给 Kafka,Logstore系统消费Kafka中的数据写入到mongodb数据库中。
至此,对于业务方现有日志类型,新增数据在底层达到双写目的,S3系统和LogStore系统存储两份数据;如果业务方新增日志类型,则直接调用LogStore系统接口即可。接下来,我们将对已有日志类型老数据进行迁移。
第三步:存量数据迁移
此次迁移S3老数据采用php定时任务脚本(多个)查询数据,将数据投递到RabbitMQ队列中,LogStore系统从RabbitMQ队列拉取消息进行消费存储到MongoDB中,示意图如下:

(1) 由于原mysql表中id为varchar类型并且非主键索引,只能利用ctime索引分批次进行查询,数据密集处进行chunk投递到mq队列中。
(2) 数据无法一天就迁移完,迁移过程中可能存在中断的情况。脚本采用定时任务每天执行20h, 在上线时间停止执行,同时将停止时间记录到Redis中。
(3) 由于需要迁移数据量较大,在mq和消费者能承受的情况下,尽可能多地增加脚本数量,缩短导数据的时间。
(4) 脚本执行期间,观察业务延时情况和MySQL监控情况,发现有影响立即进行调整,以保障不影响正常业务。
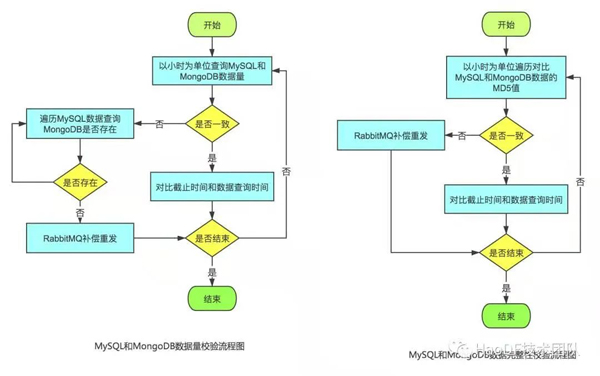
第四步:校验数据
老数据导入完成后,下面就要对老数据进行校验,校验从两个方面进行: 数据量和数据完整性。
- 数据量:基于S3系统老数据的id, 查询在MongoDB中是否存在,如果不存在则进行补偿重发;
- 数据完整性:对于S3和MongoDB中的数据按照相同规则进行md5校验,校验不通过则进行补偿重发。
第五步:数据双写
将应用层预制的写开关打开,将流量导入到LogStore中,此时MySQL的流量并没有停掉,继续执行binlog同步。结构如下:
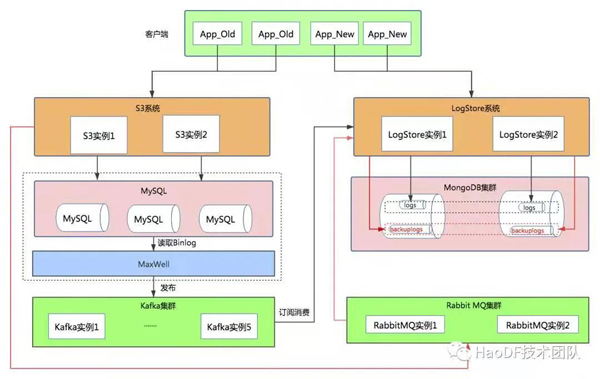
从图中可以看到,从S3调用点的写接口的流量都写入到MongoDB数据库backuplogs集合中,为什么不直接写入到logs表中呢?留个小悬念,在后文中有解释。
第六步:灰度切换S3读到LogStore系统
上文我们提到,对于S3系统应用层读写调用点均分别内置了切换开关,打开应用层读开关,所有的读操作全部走LogStore, 切换后示意图如下所示:

第七步:灰度切换写接口到LogStore系统
打开应用层写开关,所有写操作会通过mq异步写到MongoDB中,那如何证明应用层写调用点修改完全了呢?
上文中双写数据一份到logs表中,一份到backuplogs表中,通过Maxwell的Binlog同步的数据肯定是最全的,数据量上按理来说 count( logs) >= count(backuplogs), 如果两个集合一段时间内的数据增量相同,则证明写调用点修改完全,可以去掉双写,只保留LogStore这条线,反之需要检查修改再次验证。切换写完成后,示意图如下:

六、MongoDB与故障演练
故障演练能够检测服务是否真正高可用,及时发现系统薄弱的环节,提前准备好预案减少故障恢复时间。为了验证MongoDB是否真正高可用,我们在线下搭建了MongoDB集群:

同时,我们编写脚本模拟用户MongoDB数据插入和读取,基于好大夫在线自研故障演练平台,对机器进行故障注入,查看各种故障对用户的影响。故障演练内容CPU、内存、磁盘、网络和进程Kill等操作,详情如下图所示:
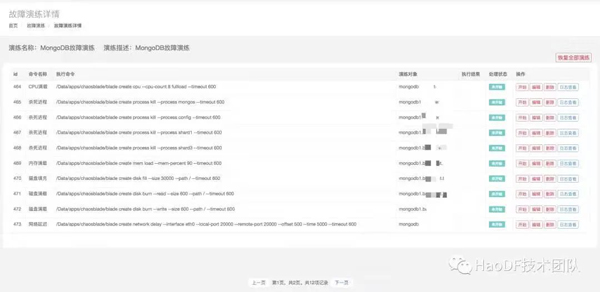
实验结果:
- CPU、磁盘填充和磁盘负载对MongoDB集群影响较小;
- 内存满载可能会发生系统OOM,导致MongoDB进程被操作系统Kill,由于MongoDB存在数据副本和自动主从切换,对用户影响较小;
- 网络抖动、延迟和丢包会导致mongos连接服务器时间变长,客户端卡顿的现象发生,可通过网络监控的手段监测;
- 分别主动Kill掉MongoDB的主节点、从节点、仲裁节点、mongos、config节点,对整个集群影响较小。
整体而言,MongoDB存在副本和自动主从切换,客户端存在自动检测重连机制,单个机器发生故障时对整体集群可用性影响较小。同时,可增加对单机器的资源进行监控,达到阈值进行报警,减小故障发现和恢复时间。
七、总结
1、MongoDB的使用
- MongoDB数据写入可能各个分片不均匀,此时可以开启块均衡策略;由于均衡器会增加系统负载,最好选择在业务量较小的时候进行;
- 合理选择分片键和建立索引,会使你的查询速度更快,这个要具体场景具体分析。
2、迁移数据
- 必须保留唯一标识数据的字段,最好是主键id,方便校验数据;
- 一定要考虑多进程,脚本要自动化,缩短迁移时间和减小人工介入;
- 迁移过程中,要时刻关注数据库、中间件及应用相关指标,防止导出导入数据影响正常业务;
- 要在同样配置的环境下充分演练,提前制定数据比对测试用例,以防止数据丢失;
- 每一步线上操作(如切换读写),都要有对应的回滚计划,最大限度降低对业务的影响。
本文链接:https://my.lmcjl.com/post/12209.html
4 评论