前言:
本文为《趣谈网络协议》学习笔记,原文地址:趣谈网络协议_网络协议_网络编程-极客时间
一、概述
1. 商城购物的流程
a. 网络协议三要素
- 状态:200/404等
- 首部
- 内容
例子:
HTTP/1.1 200 OK
Date: Tue, 27 Mar 2018 16:50:26 GMT
Content-Type: text/html;charset=UTF-8
Content-Language: zh-CN<!DOCTYPE html>
<html>
<head>
<base href="https://pages.kaola.com/" />
<meta charset="utf-8"/> <title>网易考拉3周年主会场</title>b. 下单过程中涉及的网络协议
- 输入域名,浏览器使用DNS协议 (更精准的方式是HTTPDNS协议) 查找IP地址
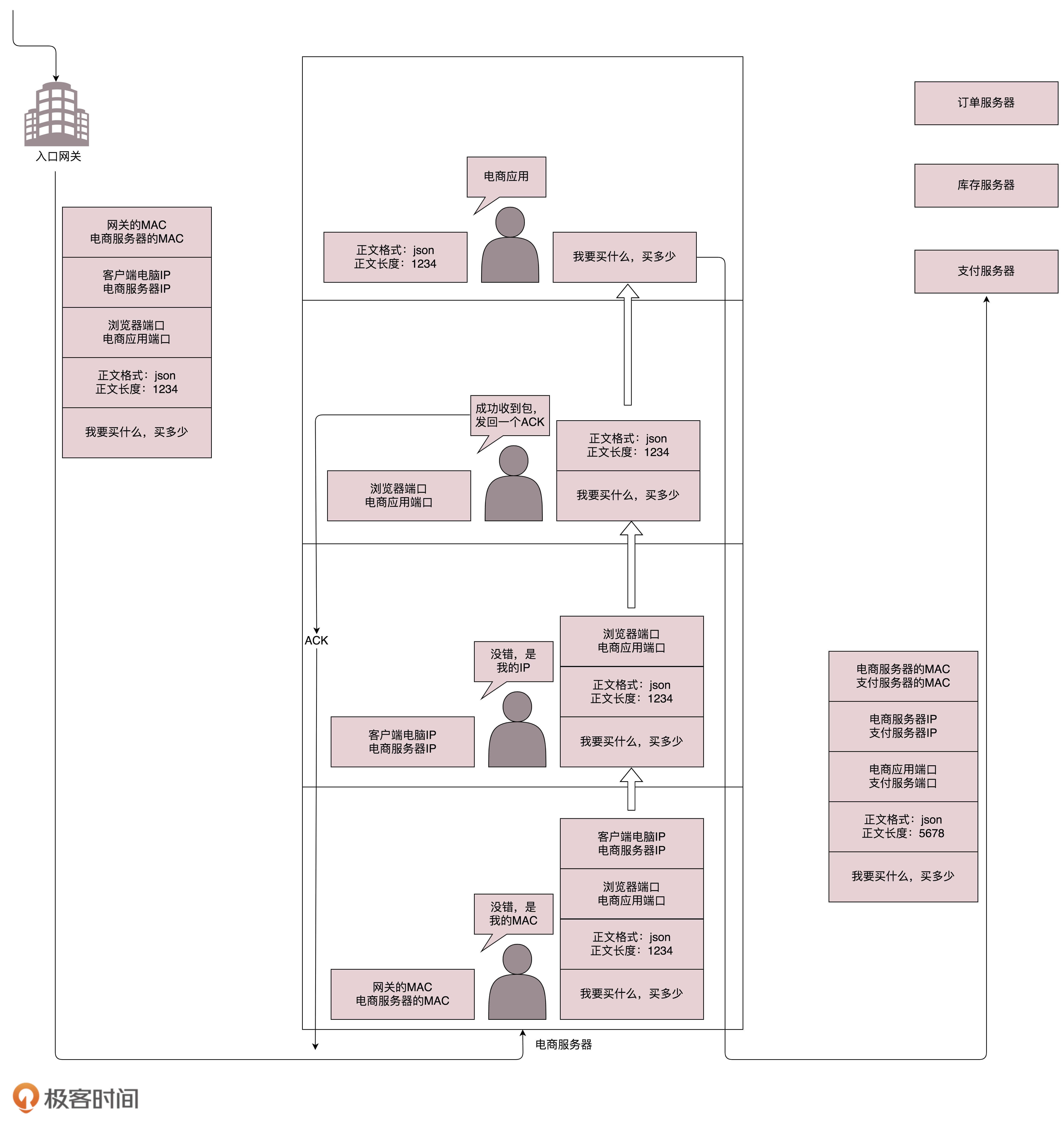
- 知道目标地址后,浏览器打包请求。普通请求会使用HTTP协议,需要加密传输的会使用HTTPS协议

- DNS、HTTP、HTTPS为应用层,浏览器会将应用层的包传递给传输层。传输层有UDP(面向无连接)和TCP(面向连接)协议。TCP协议中有两个端口,一个是浏览器监听的端口,一个是电商服务器监听的端口。操作系统一般通过端口来确定,其得到的包应该给哪些进程处理

- 传输层封装完毕后,浏览器将包传递给网络层(IP协议)。IP协议里会包含源IP和目的地址IP

- 操作系统在启动时,就会被DHCP协议配置IP地址,以及默认网关IP192.168.1.1。
- 操作系统知道了目标IP地址后,需要将请求包发送到远方。其通过网关转发数据。在本地通讯时,操作系统使用MAC地址和ARP协议将数据发送给网关。操作系统将IP包交给下一层(MAC层),网卡将包发送出去,包中包含MAC地址,数据传送到网关

- 网关接收到数据后,根据路由表寻址。临近的网关会使用路由协议(OSPF 和 BGP)沟通路由信息
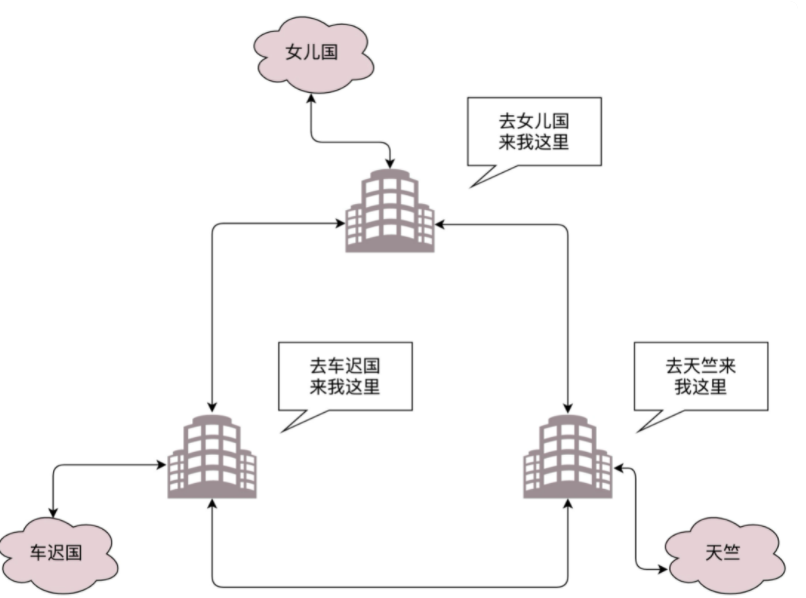
- 最后一个网关知道网络包的目的地址,使用IP地址寻找到目的结点的MAC地址,进而找到目标接待
- 找到目标结点后,将数据发送至目标结点操作系统的网络层,取下IP头,然后传递给传输层。传输层若使用TCP协议,收到数据后,会回复响应包,若传输异常,会自动重试
- 网络包到达TCP层后,可获取端口号,通过端口号将数据送达监听的进程
2. 网络为什么要分层
分层模型:
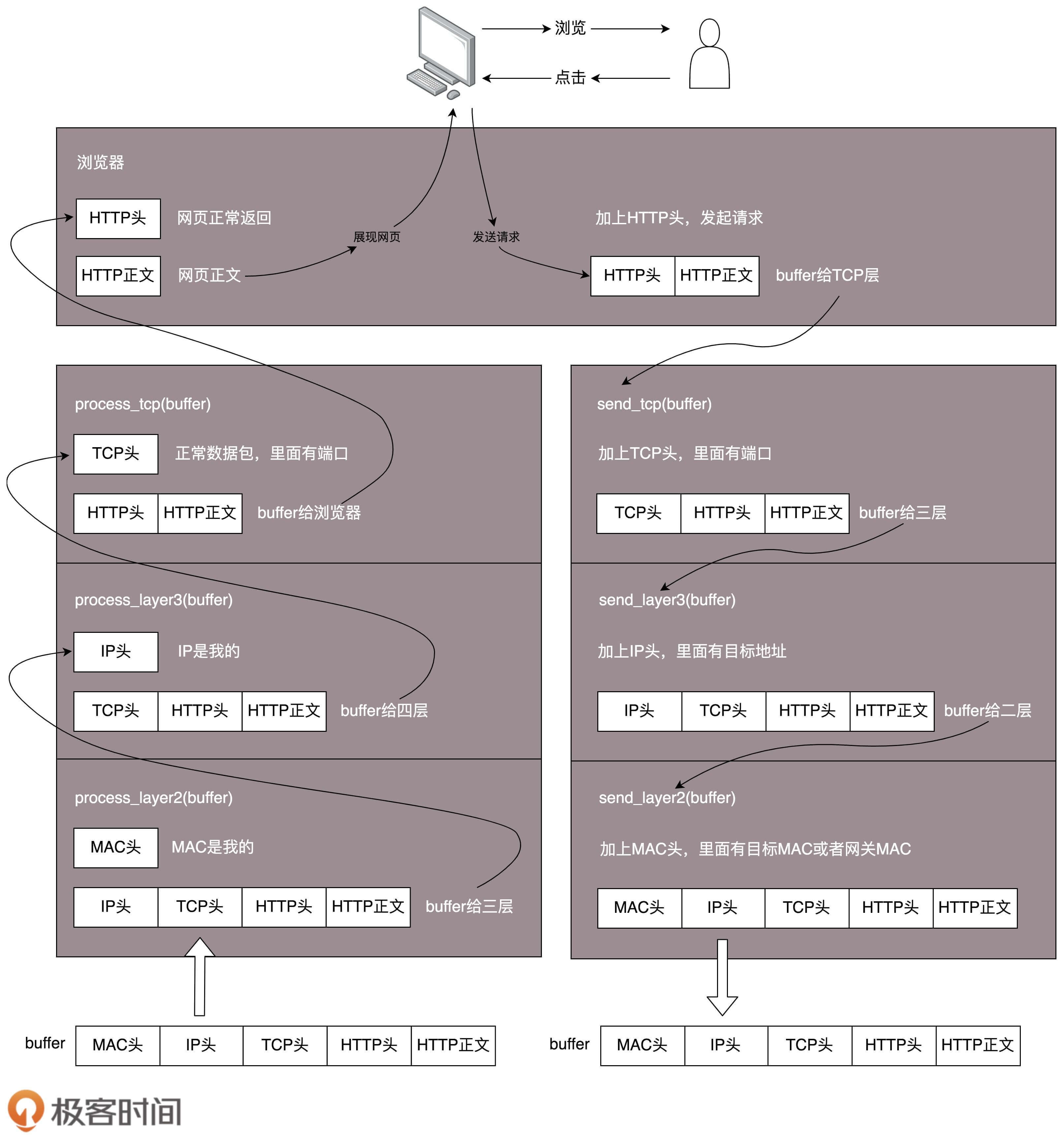
接收请求流程:
- 从一个网络包从网口中经过,处理网络包的程序判断是否需要读取(混杂模式的网络包都读取)
- 调用process_layer2(buffer),判断MAC地址与本地址是否相符,相符则继续执行下列步骤,否则不处理
- 调用process_layer3(buffer),获取头部,判断IP地址是不是自己的。若不是,则转发;若是自己的IP,则提交给上一层
- 根据传输层头部,判断使用TCP还是UDP,并交给应用处理数据(根据端口号确定)
发送请求流程:
- 用户点击网页页面请求,浏览器将端口号等信息向下传递
- 调用 send_tcp(buffer)方法,将源和目的的端口号加在TCP头
- 调用send_layer3(buffer)方法,buffer中已经有HTTP请求头和TCP请求头。在这个函数中会生成IP头,记录源和目的的IP地址
- 调用send_layer2(buffer)方法,加上MAC头,记录源MAC和目的MAC地址。目的MAC地址若无法获得,则通过协议处理过程获取MAC地址
- 通过网口发送数据
特点:
- 在网络中的包,必须是完整的。可以有下层没有上层,绝不能有上层没下层
- 二层设备接收到的数据包是完整的,设备上的处理程序只获取网络包的MAC头,判断丢弃、转发还是自己留;三层则是只处理IP头
3. ifconfig命令解读
a. 概述
linux查看ip地址指令:ifconfig/ ip addr
例子:
[root@VM-125-189-centos ~]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft forever
2: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000link/ether 52:54:00:8f:0d:2a brd ff:ff:ff:ff:ff:ffinet 9.134.125.189/20 brd 9.134.127.255 scope global eth1valid_lft forever preferred_lft forever
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN link/ether 02:42:64:a7:f5:91 brd ff:ff:ff:ff:ff:ffinet 192.168.10.1/24 brd 192.168.10.255 scope global docker0valid_lft forever preferred_lft forever- inet:ip地址
- inet6:ipv6
- CIDR:inet的IP地址后有/<num>
- scope: inet的IP地址后,有scope,global为全局可见,可接受各个地方的包;lo为环回地址,用于本机通讯,经过内核处理后,数据包之间返回,不出现在网络上
- link/ether:MAC地址,网卡的物理地址,16进制,6bytes表示
- <BROADCAST,MULTICAST,UP,LOWER_UP>:BROADCAST(网卡可以发送广播包),MULTICAST(网卡可发送多播包),LOWER_UP(L1启动,连网线),UP(网卡处于启动状态)
- MTU 1500:MAC层的概念,1500表示正文部分不允许超过 1500 个字节。正文里面有 IP 的头、TCP 的头、HTTP 的头。如果放不下,则分片传输
- qdisc mq state UP qlen 1000:排队规则
b. IP地址分类:
IP地址分类:
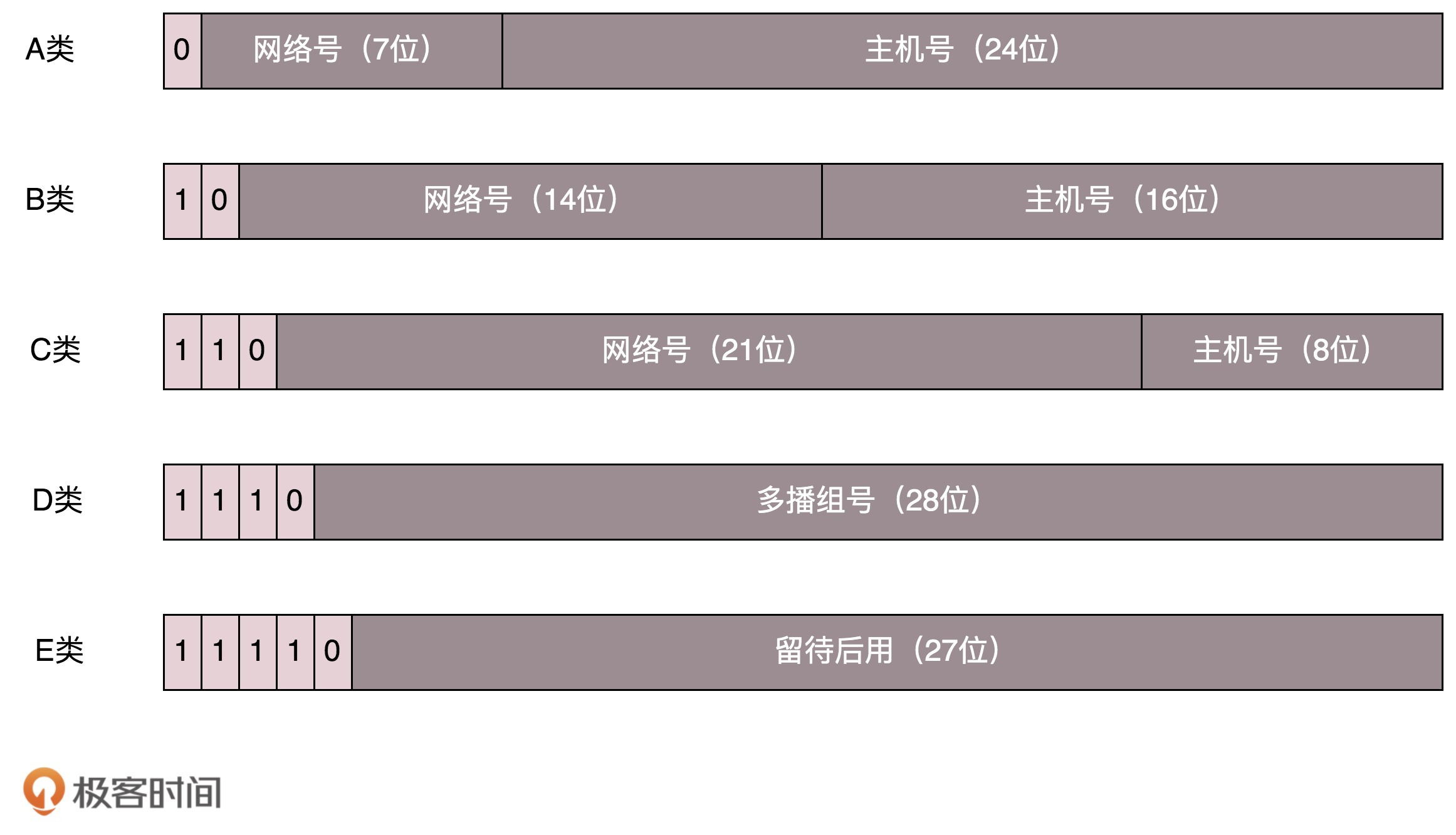
各类型IP地址下机器数量:
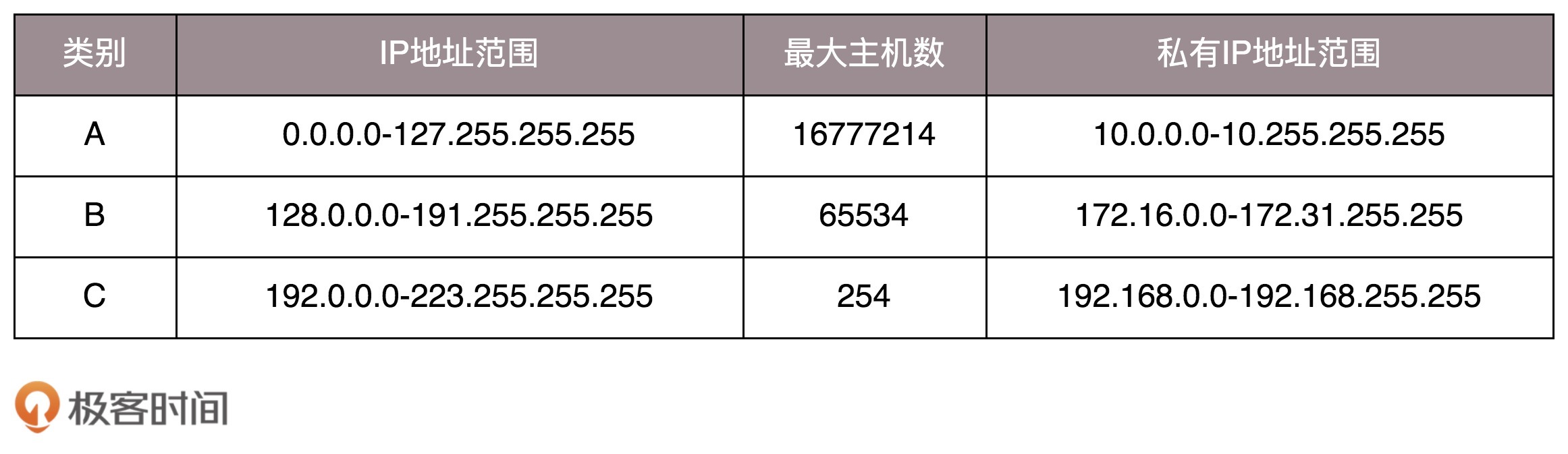
组播地址(D类):使用这一类地址,属于某个组的机器都能收到。
c. CIDR(无类型域间选路)
例子中,eth1网络号有20位,可知子网掩码为 255.255.240(1111 0000).0,网络号为 9.134.112(0111 0000).0,广播地址为 9.134.127(0111 1111).255
d. 公有IP与私有IP
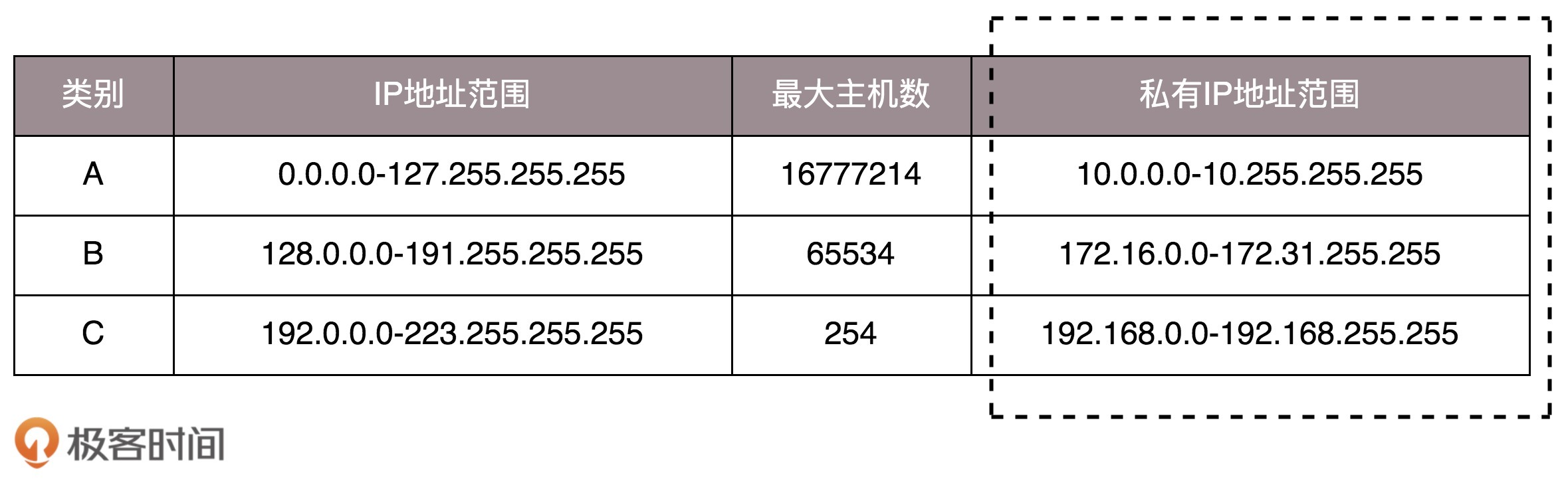
私有IP与公有IP区别:
- 私有IP允许组织内部人员自己管理、自己分配,而且可以重复,组织与组织之间,私有IP允许重复,192.168.0.x 是最常用的私有 IP 地址
- 公有IP有组织统一分配,不允许重复
e. MAC地址
MAC地址:网卡地址,16进制6byte表示,全局唯一
跨子网传输时不使用MAC地址定位的原因:MAC地址有一定的定位功能,不过范围过小。只有在子网下,才能通过ARP协议定位设备。一旦跨子网,MAC地址无法定位,需要使用IP地址
e. qdisc
定义:排队规则,内核如果需要通过某个网络接口发送数据包,它都需要按照为这个接口配置的 qdisc(排队规则)把数据包加入队列。
常用的排队规则:
- pfifo:先进先出队列
- pfifo_fast:维护三个不同优先级的先进先出队列,数据包按服务类型(TOS)分配到不同队列中。TOS是IP头的一个字段,代表当前包的优先级
4. DHCP与PXE
a. 概述
linux网络包传输过程:
- linux在获取网络包目的IP地址后,会判断IP地址与本地IP地址是否在同一个网段。
- 若在同一网段,会使用ARP协议,获取目的IP所在机器的MAC地址。
- 如果不在同一网段,Linux会试图将网络包发送到网关(网关IP必须与当前机器IP在同一网段)
b. DHCP协议
动态主机配置协议(DHCP):网络管理员配置一段共享IP地址,每一台新接入的机器通过DHCP协议,在这段共享IP中申请,使用完毕后自动归还
DHCP工作方式:
- 新加入的机器使用IP地址0.0.0.0发送广播包,目的IP是 255.255.255.255。广播包封装了UDP,UDP封装了BOOTP,格式如下

- 若网路中配置了DHCP Server,server能接收到请求,根据MAC地址,为新加入的机器分配IP(DHCP Offer)。同时,DHCP Server为客户保留为它提供的IP地址,不会为其他DHCP客户提供相同的IP地址。由于新加入的机器没有IP地址,DHCP Server使用广播地址作为目的地址,回复DHCP Offer给新加入的机器。DHCP Offer的格式如下:

- 新加入的机器可能会收到多个DHCP Offer,一般会选择最先到达的那个,并向网络发送DHCP Request广播数据包,包中包含客户端MAC,接收租约的IP地址,提供此租约的DHCP服务器地址,并告诉所有DHCP Server其将接受哪一台机器提供的IP地址,同时提示未被接受的DHCP Server撤销提供的IP。由于还没有得到DHCP Server最后确认,客户端仍然使用0.0.0.0作为源IP,以255.255.255.255为目的IP进行广播。DHCP Request格式如下

- DHCP Server收到客户端的DHCP request后,会广播返回客户端一个DHCP ACK包,表示接受客户机的选择,并将IP地址合法租用信息与其他配置信息放入广播包,发送客户端。DHCP ACK格式如下:

IP地址的收回与续租:
- 客户机会在租期过去50%后,直接向为其提供IP地址的DHCP Server发送DHCP Request。客户机在接收到DHCP Server回应的DHCP ACK后,会根据包中提供的新租期和其他已经更新的TCP/IP参数更新自己的参数,IP租用更新完成
- 租期到之后,DHCP Server会将IP收回
c. PXE
预启动执行环境PXE:用以远程安装操作系统,分为客户端和服务器端。
PXE工作方式:
- 当客户计算机启动时,BIOS会将PXE客户端调入内存中,PXE客户端发送DHCP请求,获取IP地址。DHCP Server在为PXE客户端分配IP时,会将 next-server 发送给PXE客户端,next-server执行PXE服务器地址。
- PXE客户端获取了IP,并获取PXE服务器地址,可以从PXE服务器上下载文件pxelinux.0。PXE客户端使用TFTP协议进行下载,PXE服务器端往往需要TFTP服务器
- pxelinux.0文件会指示PXE客户端向TFTP服务器请求配置文件pxelinux.cfg,文件中可获取内核信息,通过此可以获取内核,并启动linux
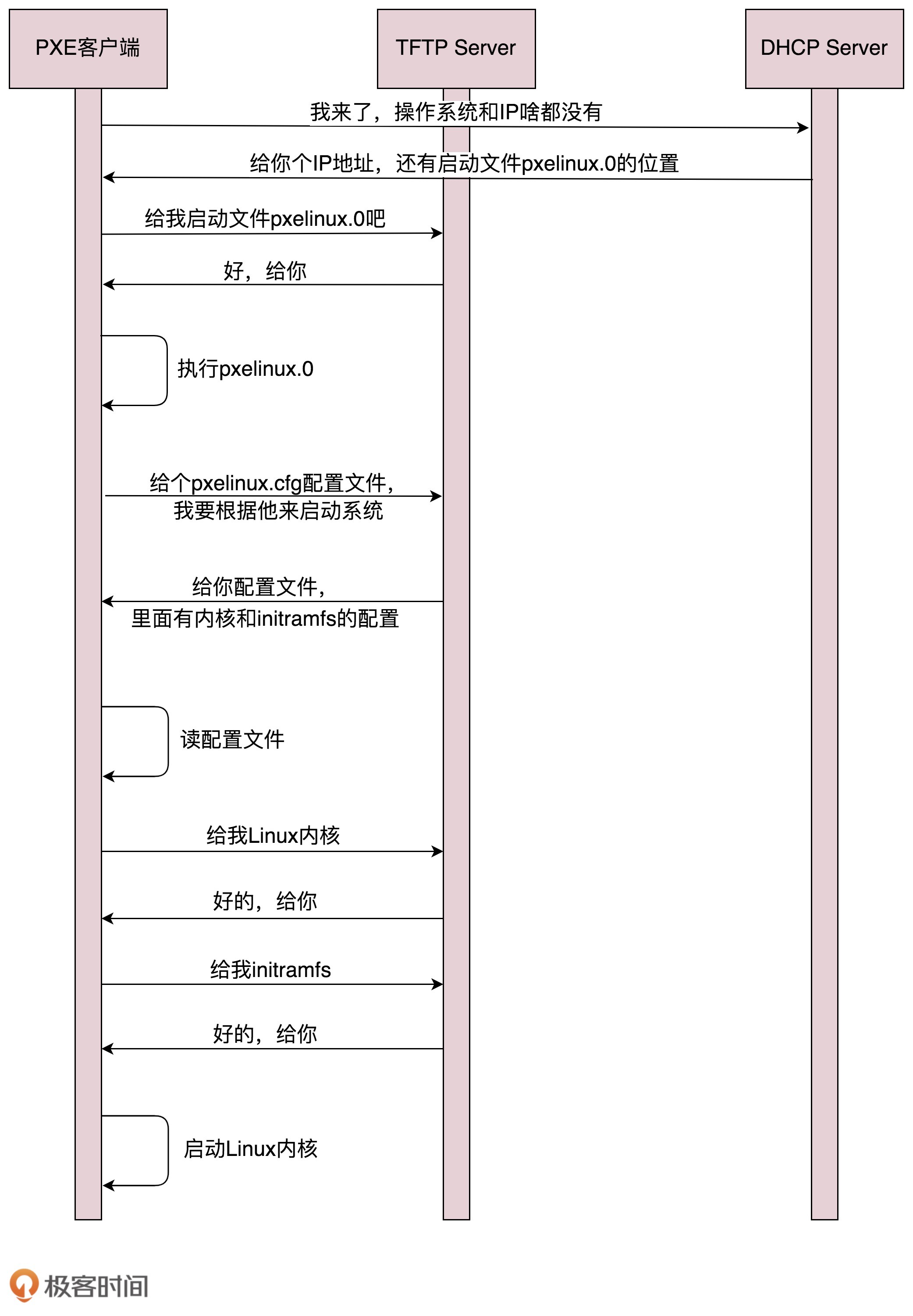
二、从二层到三层
1. 从物理层到MAC层
a.概述
集线器(Hub):工作在物理层,采用广播的模式,将接收到的每一个字节复制到其他端口上去
b. 数据链路层
集线器需要解决的问题:数据包收发的地址的确定;冲突解决;发送时出现错误的解决。
链路层采用的解决策略:
1) 多个节点发送数据时,如何防止混乱(多路访问):
- 信道划分:划分多个信道
- 轮流协议:每个节点轮流使用
- 随机接入协议:允许同时发送数据,出现冲突时解决(边听边发)
2) 数据包收发地址的确认
使用链路层地址(MAC地址)确定子网内目的与源地址。数据包在链路上广播,MAC层的网卡根据数据包的目的MAC地址判断数据包是否是发送给他的。若是,接受包,并获取IP头,若IP地址与本机一致,则继续获取TCP头,根据端口号转发数据包至本地进程
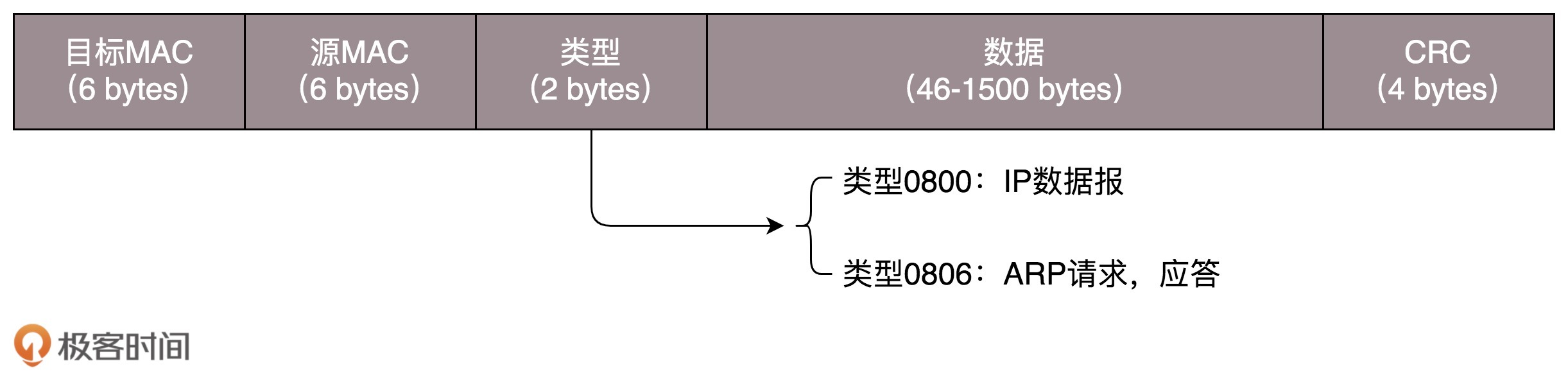
3) 发送出现错误时的校验
对于以太网,链路层的数据包最后是CRC(循环冗余校验)。通过XOR异或算法来计算整个包在传输时是否出现错误
4) 如何获知MAC地址
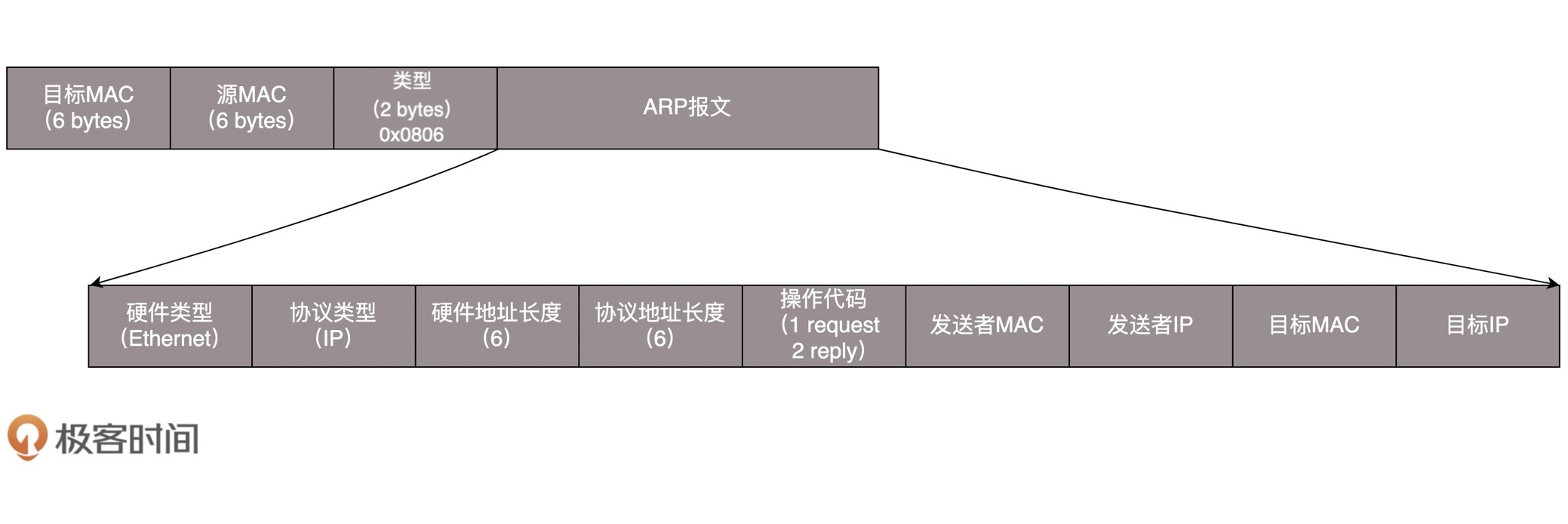
ARP协议:通过IP地址,获取MAC地址的协议
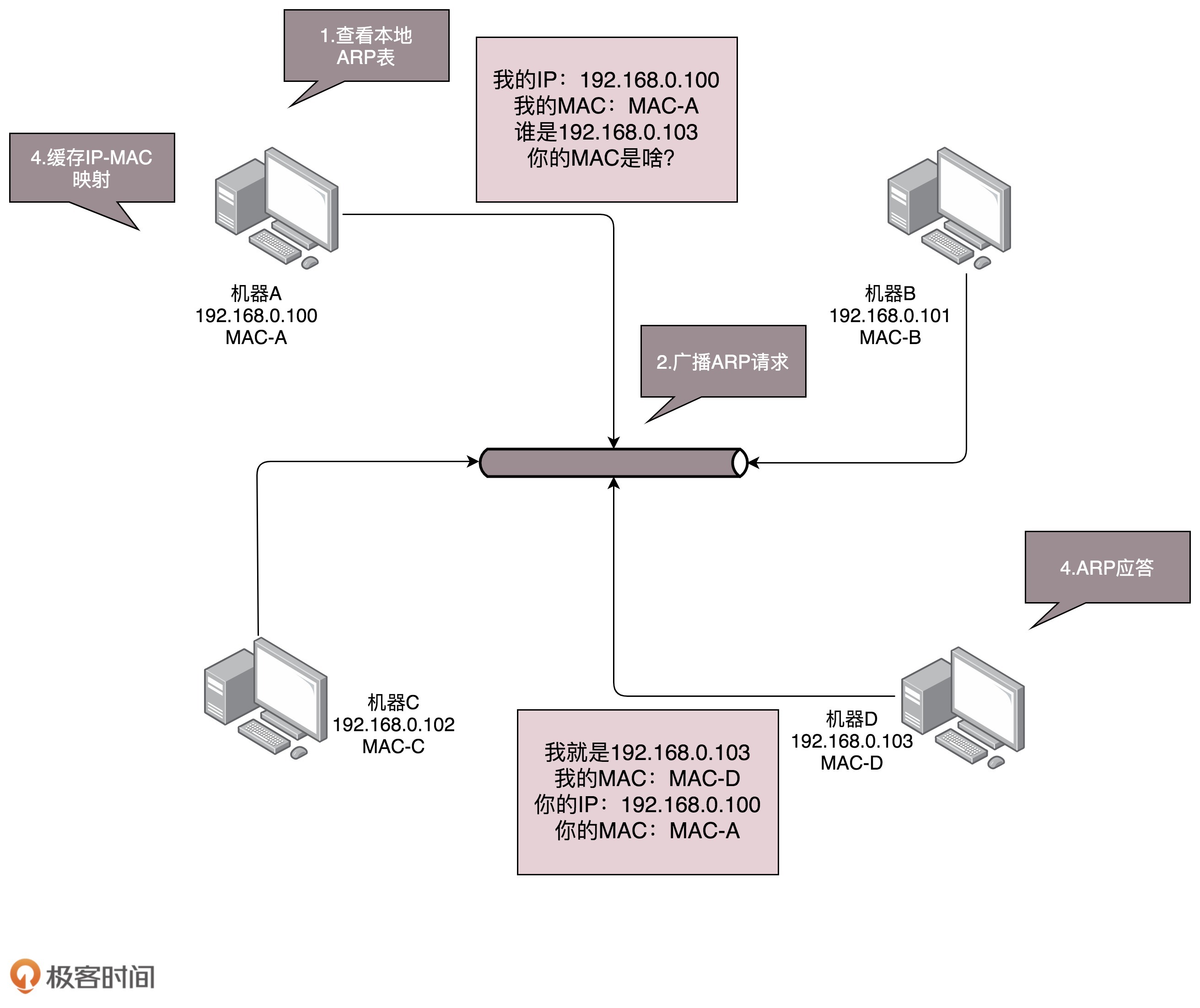
ARP协议流程:
- 节点向子网中发送一个广播包,哪个节点与该IP地址相符,则由谁应答
- 为了避免每次获取IP地址对应的MAC地址都发送ARP请求,机器本地也会进行ARP缓存。由于机器会不断上线与下线,IP会变,因此ARP的MAC地址缓存过一段时间会过期
d. 局域网
HUB设备问题:Hub是广播,无论某个接口是否需要,所有数据都会被发送。当接入的节点较多,就容易产生冲突。
交换机:可以将数据包的MAC头取下来,校验目的MAC地址,根据策略转发的设备。交换机属于二层设备
交换机学习每个口的节点的MAC地址流程:
- 一台MAC1电脑将包发送给另一台MAC2电脑,当包到达交换机时,交换机会将包转发给除了源节点接口之外的所有接口
- 同时交换机记录下MAC1所属的接口。以后有数据包发送给MAC1,可以直接根据记录转发
- 一段时间后,整个网络的结构会被基本记录下来,此时大多数数据无须广播。
- 由于每个机器的接口会变,交换机上学习的结果(转发表)有过期时间
2. 交换机与VLAN
a. STP协议
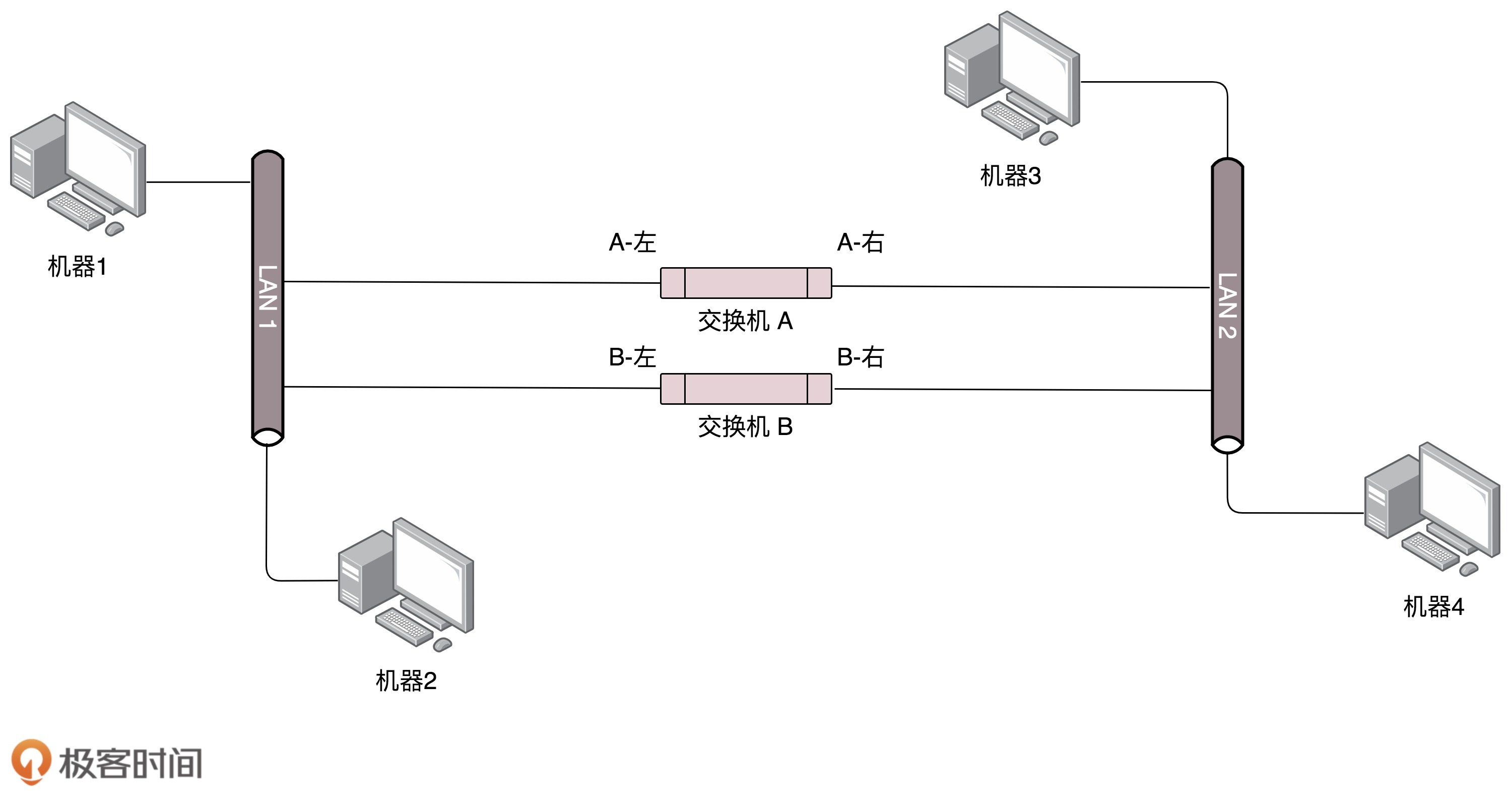
环路问题:
机器1发送数据至机器2,交换机A将广播发送到局域网2;
1)交换机B右侧端口可以收到交换机A广播的数据,交换机B左侧也可以收到机器1发送的数据,因此交换机B无法确定机器1来自左侧还是右侧
2)机器1发送的数据,经过路径 A左 A右 B右 B左 A左 不断循环,占用网络资源
STP协议概念:
BPDU网桥协议数据单元:生成树协议定义的数据包,网桥通过BPDU来相互通信,并用BPDU相关机能来动态选择根桥和备份桥。在一个生成树环境中,桥不会立即开启转发功能,必须先选定一个桥作为根桥,然后建立一个指定路径。
BPDU中的重要参数:
- 根ID:发送此配置BPDU的交换机所认为的根交换机的交换机标识
- 到根的路径消耗:从发送此配置BPDU的交换机到达根交换机的最短路径总开销,含交换机根端口的开销,不含发送此配置BPDU的端口开销。路径开销与端口的带宽成反比
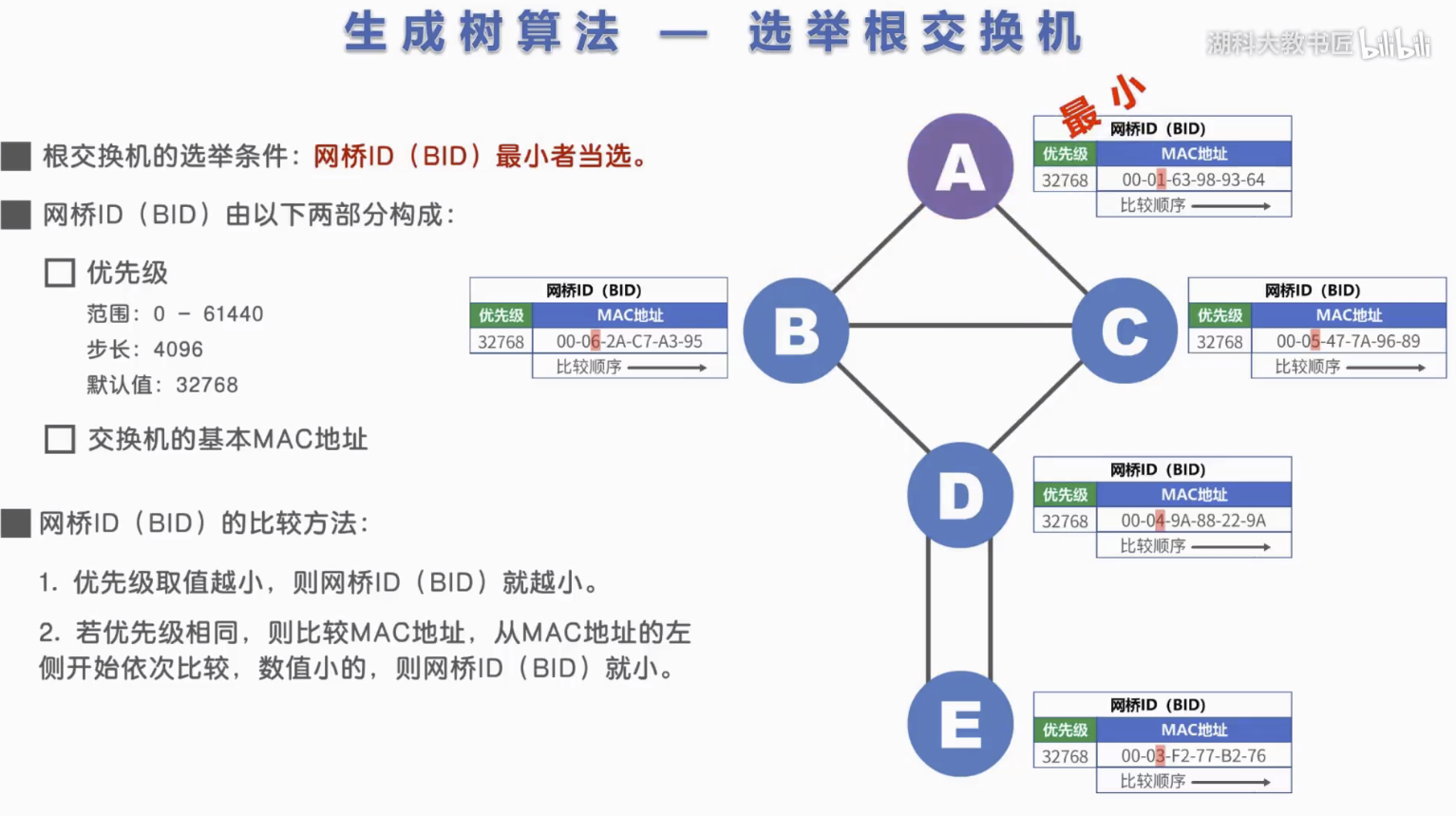
- 桥ID:发送此配置BPDU的交换机的STP交换机标识,8字节,由2字节的优先级和6字节的MAC地址构成。桥ID最小的交换机将成为根桥
- 端口ID:发送此配置BPDU的交换机端口的STP端口标识。2字节,由1字节的端口优先级和1字节的端口编号组成
BPDU比较次序:根ID > 根路径消耗 > 桥ID > 端口ID (值越小越好)
STP工作过程:
1) 每个交换机网络选举一个根桥。将网桥ID(即交换机)最小者作为根交换机
2) 每个非根桥选举一个根端口。根端口用于接收根交换机发送的BPDU,也可用来转发普通流量。
根端口选举条件:
- BPDU接收端口到根交换机的路径成本最小
- 对端网桥ID最小
- 对端的端口ID最小
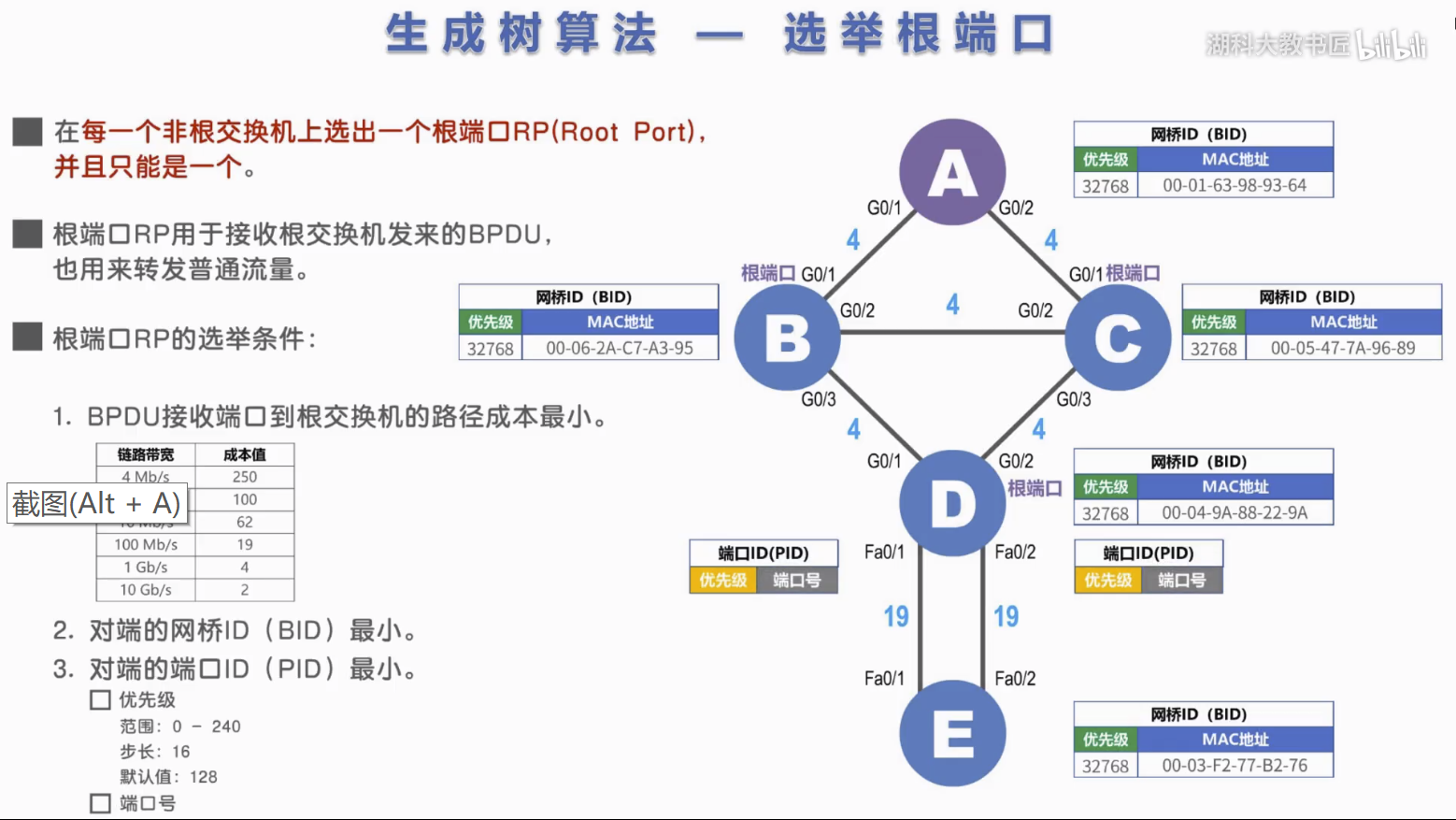
3) 每个段选举一个指定端口。指定端口在每一个网段上选出一个指定端口DP。指定端口DP转发根交换机发来的BPDU,也用来转发普通流量
指定端口选举条件:
- 根交换机的所有端口都是指定端口DP
- 根端口的对端端口一定是指定端口DP
- BPDU转发端口到根交换机的路径成本最小
- 本端的网桥ID最小(端口所在交换机的网桥id)
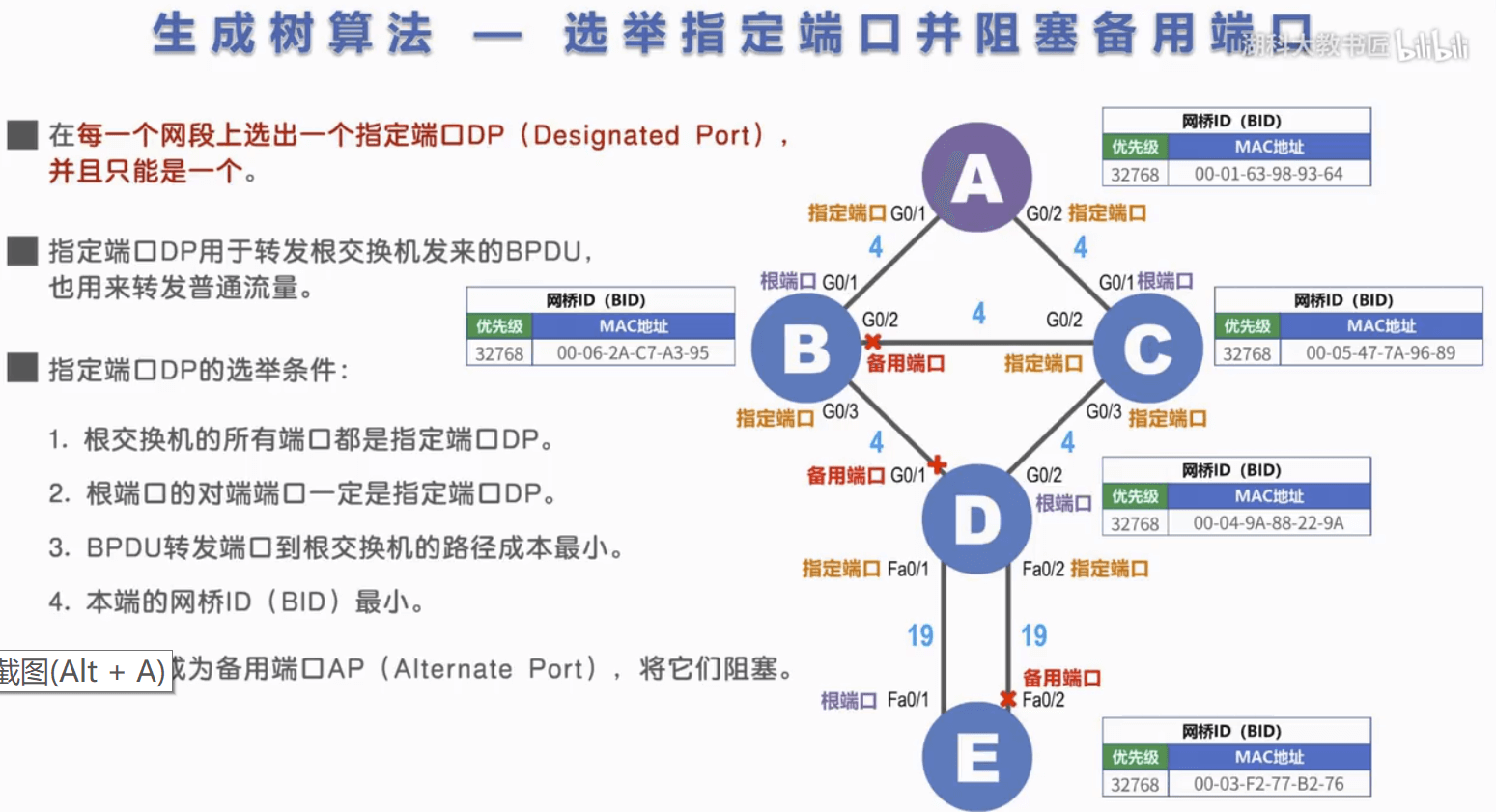
4) 阻塞非指定端口。剩余端口成为备用端口,将其阻塞
b. VLAN虚拟局域网
详细可参考:新手都能看明白的VLAN原理(上) - 知乎
问题:交换机比集线器智能一些,但避免不了广播问题。解决方法有两种,一种是物理隔离,一种是虚拟隔离(VLAN)。使用VLAN,一个交换机会连属于多个局域网的机器
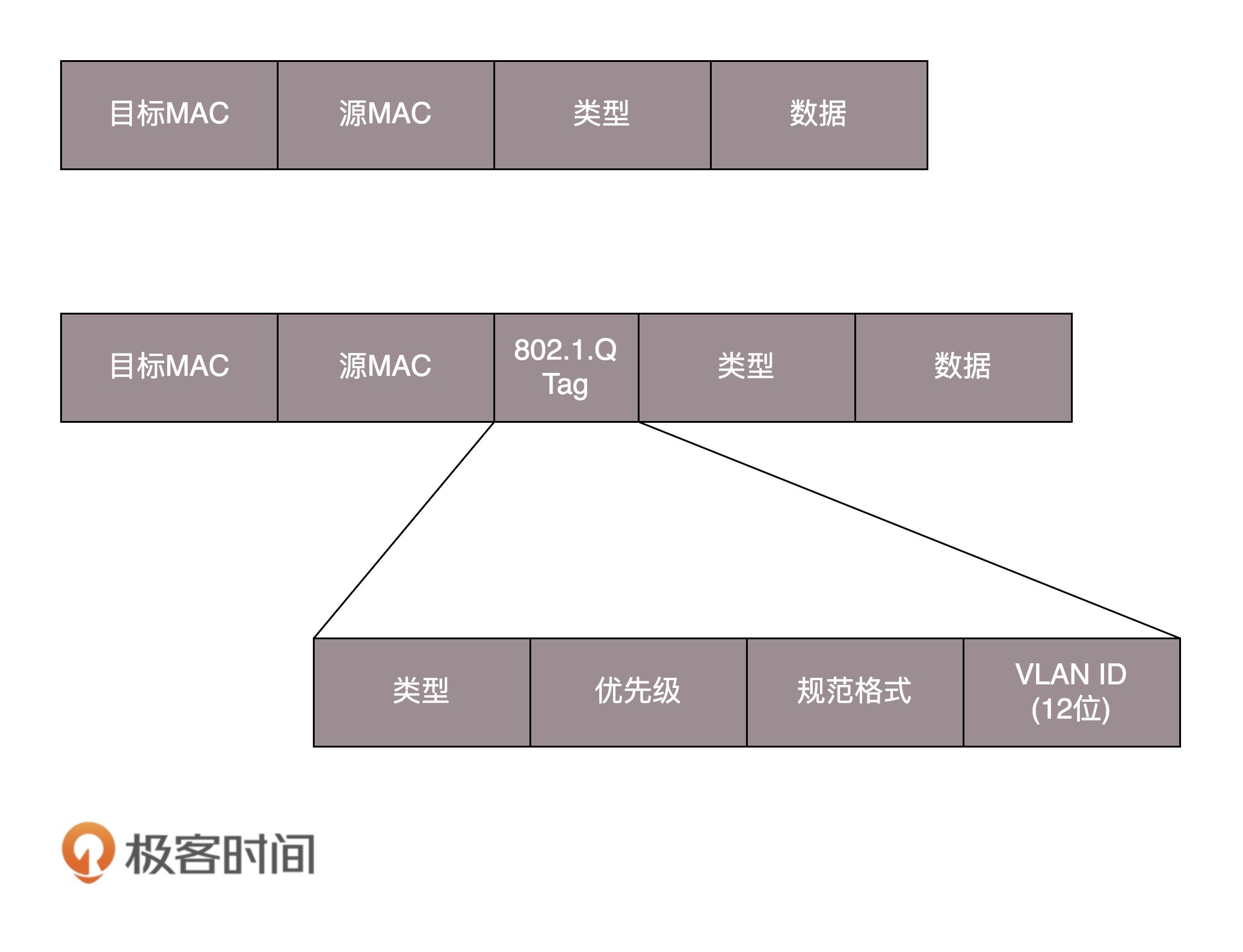
交换机区分机器属于哪个局域网的方法:
- 在原来的二层头(MAC头)加一个TAG,里面包含一个VLAN ID
- 若交换机支持VLAN,则该交换机把二层的头取下来时,能识别这个VLAN ID,只有相同VLAN的包,才会互相转发,不同VLAN数据包不可见
- 交换机之间通过Trunk口连接,它可以转发属于任何VLAN的口,交换机之间可以通过这种口相互连接

3. ICMP与ping
ICMP协议的格式(互联网控制报文协议):ICMP报文是封装在IP包里面的,因为传输是,需要带上源地址和目的地址
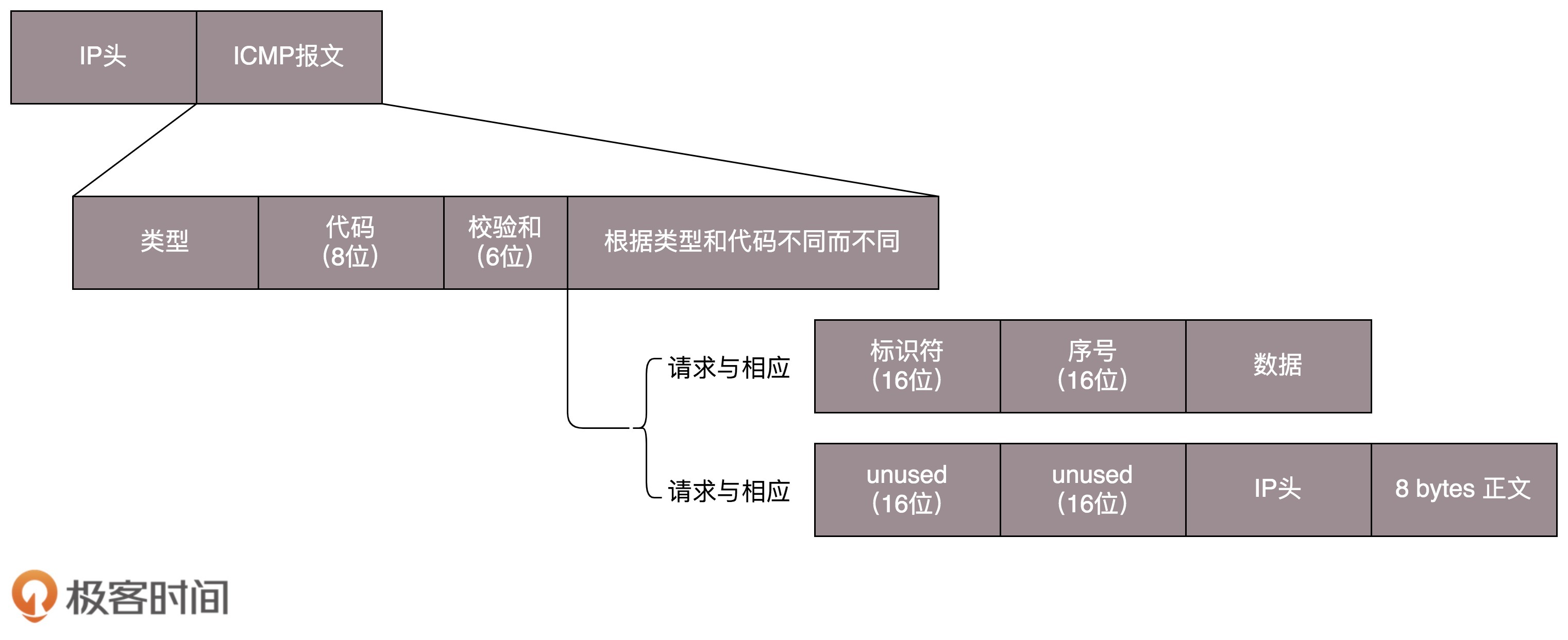
a. 查询报文类型
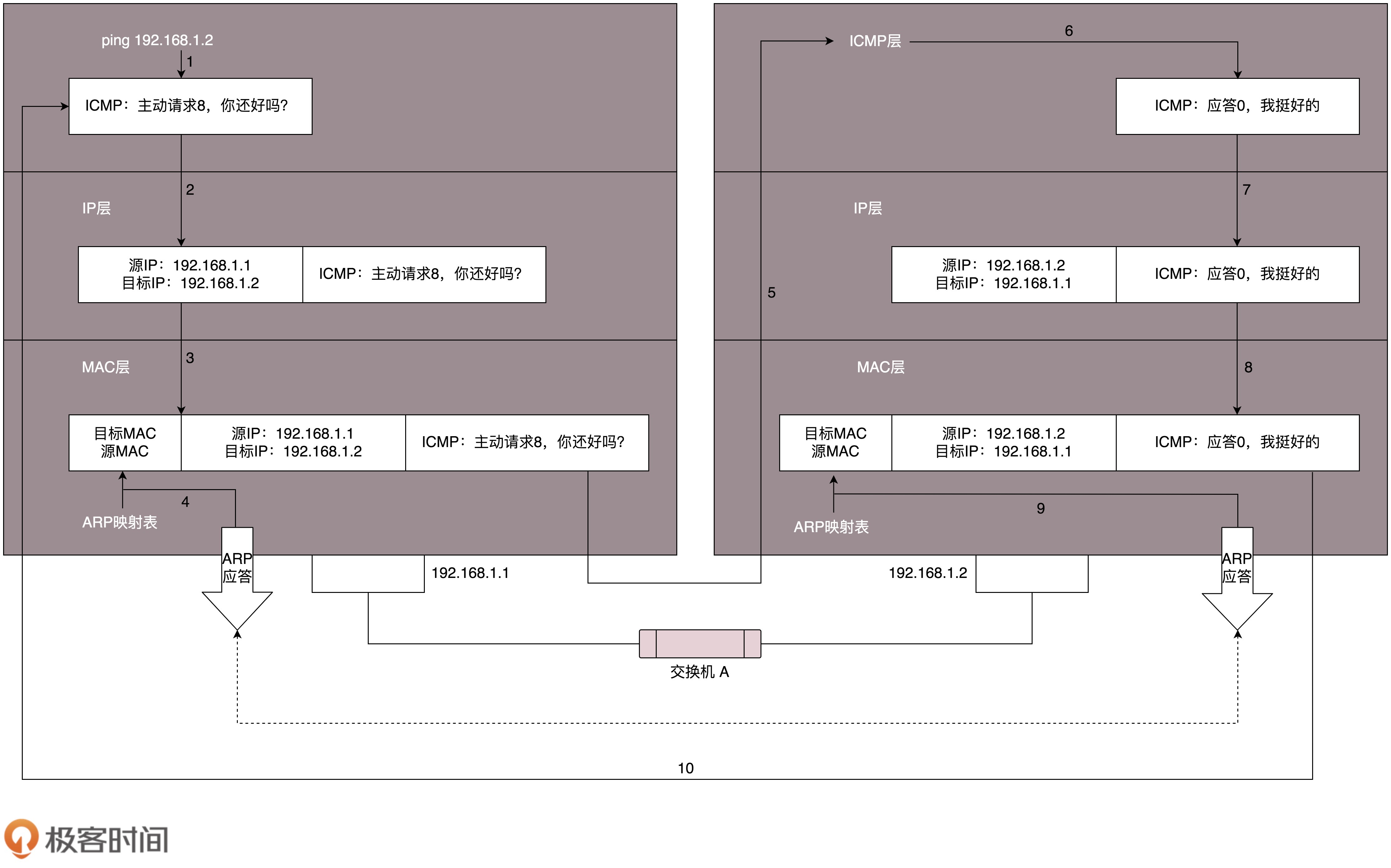
ping:ping是查询报文,是一种主动请求,并且获得主动应答的ICMP协议。相对于ICMP,ping多了两个字段,一个是标识符,一个是序号。ping还会存放发送请求的时间值,计算往返时间
ping发送过程:
- ping执行时,源主机会构建一个ICMP请求数据包,数据包包含类型字段和顺序号(用于区分连续ping时发出的多个数据包)。每发出一个请求数据包,顺序号会自动加1。为了能计算往返时间RTT,会在报文数据部分插入发送时间
- ICMP协议将数据包连同本地地址一起交给IP层,填充好目的地址和其他控制信息后,构建IP数据包,传至MAC层
- 加入MAC头,通过ARP协议获取目的MAC地址(若本地缓存的ARP映射表中含有目的地址,则直接使用)
ping接收过程:
- 主机接收到数据包后,先检查目的MAC地址是否与本地一致,一致则接收,将IP地址从数据包中提取出来,提交给本机IP层。IP层检查后,将有用的信息提交给ICMP协议
- 主机构建一个ICMP应答包,类型字段为0,顺序号为接收到的请求数据包中的顺序号,发送出去给主机 A
在规定时间内,源主机如果没有接到 ICMP 的应答包,则说明目标主机不可达;若收到应答包,则说明可达,此时,源主机用当前时刻减去该数据包最初从源主机上发出的时刻,得到 ICMP 数据包的时间延迟
b. 差错报文类型
差错报文结构:IP+ICMP+出错的IP包的IP头和IP正文的前8个字节
ICMP差错报文例子:
- 终点不可达:网络不可达/主机不可达/协议不可达/端口不可达/需要分片但设置了不分片位
- 源抑制:要求源站降低发送速度
- 超时:超过网络包的生存时间,仍然未到达
- 重定向:要求下一次请求发送给另一个路由器
Traceroute:
追踪去往目的地时沿途经过的路由器工作原理:
- 设置特殊的 TTL,来追踪去往目的地时沿途经过的路由器。例如,Traceroute 向目的IP发送UDP包,将 TTL 设置成 1,可获取直连路由器距离。以此类推,可以将TTL 设置为 2 / 3 ... ...
- Traceroute 程序会发送一份 UDP 数据报给目的主机,但它会选择一个不可能的值作为 UDP 端口号(大于 30000)。当该数据报到达时,将使目的主机的 UDP 模块产生一份“端口不可达”错误 ICMP 报文。如果数据报没有到达,则可能是超时。
确定路径的 MTU工作原理:
- 发送分组,并设置“不分片”标志。发送的第一个分组的长度正好与出口 MTU 相等。如果中间遇到窄的关口会被卡住,会发送 ICMP 网络差错包,类型为“需要进行分片但设置了不分片位”。
- 每次收到 ICMP“不能分片”差错后,减小分组的长度,直到到达目标主机。
4. 网关
a. MAC头和IP头结构

MAC头结构:目标MAC地址;源MAC地址;协议类型
IP头结构:版本号(IPV4);服务类型 TOS;TTL;源IP地址;目标IP地址
IP包发送流程:
- 若目标IP与源IP同一个网段:直接将源地址和目标地址放入 IP 头中,然后通过 ARP 获得 MAC 地址,将源 MAC 和目的 MAC 放入 MAC 头中
- 若不在同一网段:将源地址和目标地址放入 IP 头中,然后通过 ARP 获得 网关MAC 地址,将源 MAC 和网关 MAC 放入 MAC 头中
- 网关往往是路由器,是三层转发的设备,会取下IP和MAC头,根据里面的信息进行转发
b. 静态路由
定义:在路由器上,配置一条一条规则
1) 转发网关

定义:不改变 目的IP 地址的网关
流程:
- 服务器 A 要访问服务器 B,且服务器A与服务器B不在一个网段上,因此需要先发给网关。
- 根据静态配置好的网关IP,发送 ARP 获取网关的 MAC 地址,然后发送包。包的内容包含:源MAC(源机器IP地址)、目的MAC(网关连接该局域网的MAC地址)、源 IP(源服务器IP地址)、目的IP(目标服务器IP地址)
- 包到达网关,发现 MAC 一致,将包收进来,根据配置好的静态路由规则,获取下一跳IP。路由器使用ARP协议获取下一跳IP对应的MAC地址,然后发送包。包的内容包括:源 MAC地址(源服务器所在网关的网口MAC地址)、目的MAC(下一跳网口MAC地址)、源 IP(源服务器IP地址)、目标 IP(目的服务器IP地址)
- 包到达下一跳网口,发现 MAC 一致,将包收进来。若非最后一跳,继续步骤2-3,否则路由器选择与目的地址同网段的网口,使用ARP协议获取目的IP的MAC地址,发送包。包的内容包括:源 MAC地址(目的机器所在的网关对应的网口MAC地址)、目标IP的MAC地址(目标机器MAC机器)、源 IP(源服务器IP地址)、目标IP(目的服务器IP地址)
- 包到达目的机器,MAC 地址匹配,机器接收包
特点:
- 每到一个新的局域网,MAC 都是要变的,但是 IP 地址都不变。
- 在 IP 头里面,不会保存任何网关的 IP 地址。每经过一跳,需要将下一跳IP地址的MAC地址放入MAC头
2) NAT 网关

定义:改变目的IP 地址的网关。在局域网内部使用内部地址,当内部节点要与外部网络进行通讯时,在网关处将内部地址替换成公用地址
转发网关的问题:局域网之间没有商量过,各定各的网段,有可能会出现IP 段冲突
流程:
- 目的服务器B有一个公网IP,目的服务器B所在网段的网关中,需要维护服务器B公网IP与局域网内部IP的映射关系。协议会维护一张映射表,结构如下:内网ip:port -> 外网ip:空闲port
- 源服务器A访问B时,需要指定目的IP地址为B的公网IP。服务器 A 和服务器 B不在一个网段上,因而需要根据静态配置好的网关IP,发给ARP协议获取网关MAC地址,然后发送包,包内容包含:源 MAC(源机器MAC地址)、目标 MAC(机器所在网段对应的网关网口MAC地址)、源 IP(服务器A局域网IP地址)、目标 IP(服务器B公网IP)
- 包到达网关,发现 MAC 一致,将包收进来,通过ARP协议获取下一条网关的MAC地址。由于传输时不能使用局域网IP,因此在转发包时,将局域网IP转换为公网IP,然后发送包。包内容包含:源 MAC地址(连接下一跳的网关网口的MAC地址)、目标 MAC地址(下一跳网口MAC地址)、源 IP(发送网关网口的IP地址)、目标 IP(目标公网IP地址)
- 包到达目的公网IP对应的网口后,发现MAC地址一致,将包收进来。由于目的服务器B所在网段的网关是NAT网关,配置了公网IP与局域网IP的映射关系,因此网关根据公网IP,获取对应的局域网IP。
- 网关根据获取到的局域网IP地址,根据ARP协议获取目的机器对应的MAC地址,并发送包。包的内容包含:源 MAC 地址(连接目标网段网关网口的MAC地址)、目标 MAC(目标机器的MAC地址)、源 IP(源机器公网地址)、目标 IP(目标局域网IP地址)
- 包到达服务器 B,MAC 地址匹配,将包收进来
特点:
- 发送包的过程中,MAC地址会改变,IP 地址也会变
- 很多办公室访问外网的时候,也是被 NAT 过的,因为不可能办公室里面的 IP 也是公网可见的,公网地址实在是太贵了,所以一般就是整个办公室共用一个到两个出口 IP 地址。
3) NAPT
基础的NAT(只进行 IP 地址的转写)可以说是运行在第三层的,但这种NAT并没有缓解IP紧张的问题。NAPT则可以
对于 NAPT,应该区分传出(客户端)和传入(服务器)两种情况:
- 对于传出 NAT 路由器的数据包,NAT 根据源 IP 地址和传输层端口号在尽可能保留源端口号的情况下,将其转写为 NAT 可用 IP 地址池里的 IP 地址和可用的 NAT 端口,并用 Session(TCP)或者活跃计时器(UDP)的方法来记忆”源IP地址+传输层端口号 <=> NAT IP 地址 + NAT 端口号“的映射。这样,当相应的回复数据包返回 NAT 路由器时,我们可以根据记录信息将 IP 地址和端口号转写回去。
- 而对于位于 NAT 路由器后面的服务器,它需要通过监听端口来向互联网提供服务,由于服务器并不主动向 NAT 外部建立连接,NAT 也就无从根据传出包建立端口映射,那该怎么办呢?此时,NAT 路由器需要书写好端口转发或者端口映射规则,从而将传入 NAT 路由器某一个端口的数据段转发给内部网络某一台主机。
5. 路由协议
a. 如何配置路由
路由表:一个入口的网络包送到路由器时,它会根据一个本地的转发信息库,来决定如何正确地转发流量。这个转发信息库通常被称为路由表。
路由规则:一张路由表中会有多条路由规则。每一条规则至少包含这三项信息:目的网络、出口设备、下一跳网关
路由表配置:通过 route 命令和 ip route 命令都可以进行查询或者配置。例子:
ip route add 10.176.48.0/20 via 10.173.32.1 dev eth0
// 要去 10.176.48.0/20 这个目标网络,要从 eth0 端口出去,经过 10.173.32.1。b. 如何配置策略路由
策略路由:除了可以根据目的 ip 地址配置路由外,还可以根据多个参数来配置路由,这就称为策略路由
例子1:
ip rule add from 192.168.1.0/24 table 10
ip rule add from 192.168.2.0/24 table 20
// 从 192.168.1.10/24 这个网段来的,使用 table 10 中的路由表,而从 192.168.2.0/24 网段来的,使用 table20 的路由表。ip route add default scope global nexthop via 100.100.100.1 weight 1 nexthop via 200.200.200.1 weight 2
// 下一跳有两个地方,分别是 100.100.100.1 和 200.200.200.1,权重分别为 1 比 2。例子2:

假设:
- 运营商 1 给路由器分配的地址是 183.134.189.34/32,运营商网络里面的网关是 183.134.188.1/32。
- 运营商 2 给路由器分配的地址是 60.190.27.190/30,运营商网络里面的网关是 60.190.27.189/30。
根据拓扑图,可将路由配置为:
$ ip route list table main
60.190.27.189/30 dev eth3 proto kernel scope link src 60.190.27.190
// 如果去运营商二,就走 eth3
183.134.188.1 dev eth2 proto kernel scope link src 183.134.189.34
// 如果去运营商一,就走 eth2
192.168.1.0/24 dev eth1 proto kernel scope link src 192.168.1.1
// 如果访问内网,就走 eth1
127.0.0.0/8 dev lo scope link
default via 183.134.188.1 dev eth2
// 如果所有的规则都匹配不上,默认走运营商一,也即走快的网络策略路由的使用(使得租户A只能通过运营商2访问公网):
1) 添加一个 Table
# echo 200 chao >> /etc/iproute2/rt_tables
// 添加chao表2) 添加路由规则
# ip rule add from 192.168.1.101 table chao
// 租户A通过chao表路由3) 在 chao 路由表中添加规则
# ip route add default via 60.190.27.189 dev eth3 table chao
// 路由规则匹配不上,默认走eth3(运营商2)
# ip route flush cachec. 动态路由算法
应用场景:网络环境复杂并且多变,如果总是用静态路由,一旦网络结构发生变化,让网络管理员手工修改路由太复杂了,因而需要动态路由算法。
目的:为所有路由器找到并使用汇集树(此节点到所有其他节点的最优路径形成的树)
1) 距离矢量路由算法
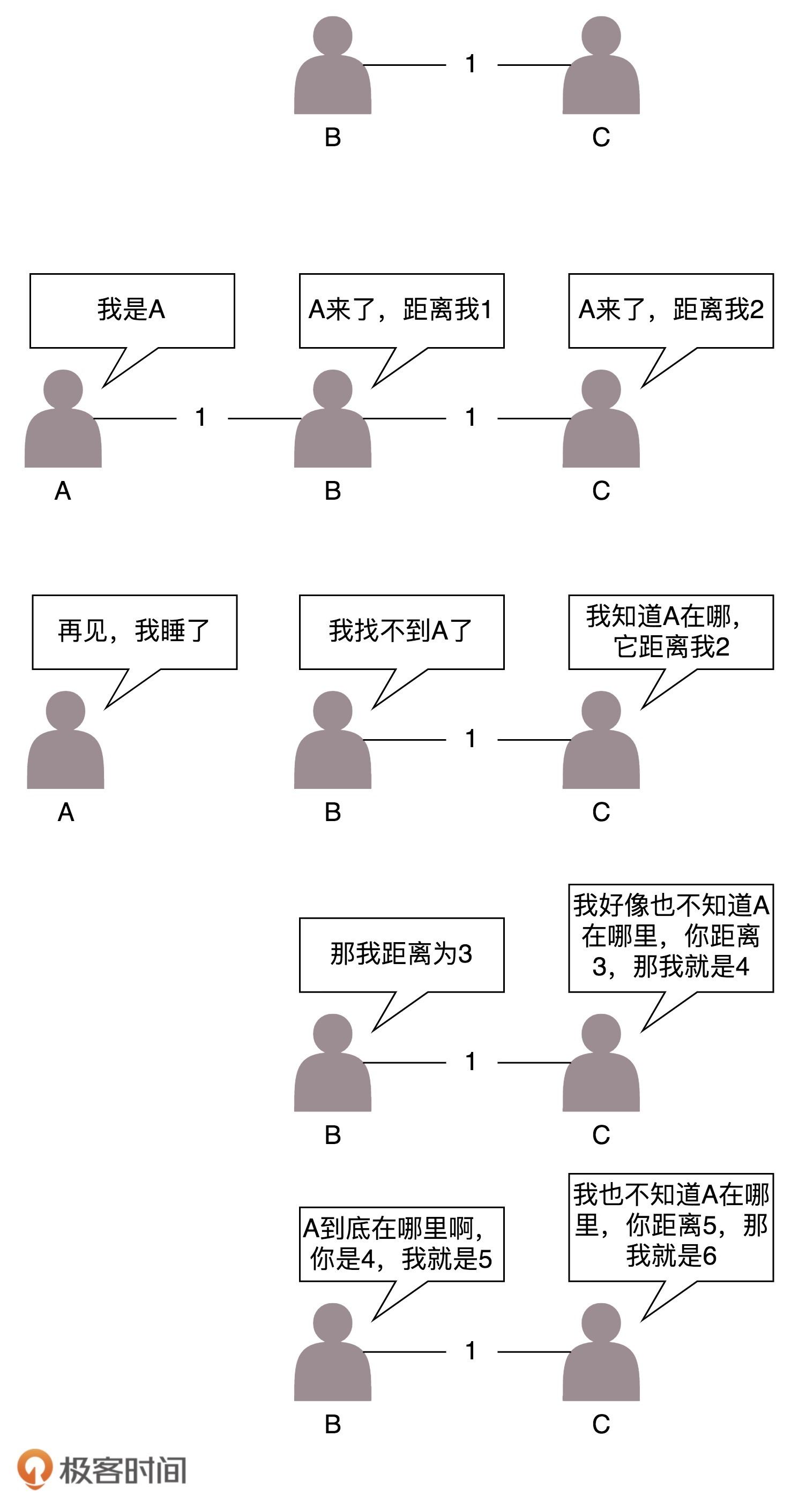
基本思路:
- 每个路由器都保存一个距离矢量表表,每个距离矢量表项包括:通信子网中的其它路由器地址(索引)、到达目的结点的下一跳地址、到达目的结点所需时间或距离(度量值)。
- 网络中每个路由器定期将自己的路由表发送给相邻的路由器。当路由器收到相邻节点发送的路由表时,会将网络中各路由器所获得的距离矢量信息在路由器上统一起来,这样只需要查看这个距离矢量表就可以为不同来源分组找到一条最佳的路由。
特点:
- 最多只能支持15跳(超过16次转发会标志为不可达)
- 新的路由器加入网络,它的邻居会很快发现它,然后将消息广播出去
- 路由器挂了,挂的消息是没有广播的。当每个路由器发现原来的道路到不了这个路由器的时候,感觉不到它已经挂了,而是试图通过其他的路径访问,直到试过了所有的路径,才发现这个路由器是真的挂了。
- 每次发送的时候,要发送整个全局路由表
2)链路状态路由算法
基本思路:当一个路由器启动的时候,首先是发现邻居,向邻居 say hello,邻居都回复。然后计算和邻居的距离,发送一个 echo,要求马上返回,除以二就是距离。然后将自己和邻居之间的链路状态包广播出去,发送到整个网络的每个路由器。这样每个路由器都能够收到它和邻居之间的关系的信息。因而,每个路由器都能在自己本地构建一个完整的图,然后针对这个图使用 Dijkstra 算法,找到两点之间的最短路径。
dijkstra算法实现:
package netLearn.Dijkstra;import java.util.Arrays;public class dijkstra {public static final int MAX = Integer.MAX_VALUE;public static void main(String[] args) {int[][] data = {{0, MAX, 10, MAX, 30, 100},{MAX, 0, 5, MAX, MAX, MAX},{MAX, MAX, 0, 50, MAX, MAX},{MAX, MAX, MAX, 0, MAX, 10},{MAX, MAX, MAX, 20, 0, 60},{MAX, MAX, MAX, MAX, MAX, 0}};dijkstra dj = new dijkstra(data, 0);dj.deal();}private int[] dis;private int[] father;private int[] flags;private int[][] data;private int begin;public dijkstra(int[][] data, int begin) {dis = new int[data.length];father = new int[data.length];flags = new int[data.length];this.data = data;this.begin = begin;}public void deal() {for (int i = 0; i < dis.length; i++) {dis[i] = MAX;father[i] = -1;flags[i] = 0;}dis[begin] = 0;while (true) {// 找出最小的且未标记的值作为开始int minDis = MAX;int nextNode = -1;for (int i = 0; i < data.length; i++) {if (flags[i] == 0 && dis[i] < minDis) {minDis = dis[i];nextNode = i;}}if (nextNode == -1) {break;}flags[nextNode] = 1;// 从结点出发,更新表int[] childs = data[nextNode];for (int child = 0; child < childs.length; child++) {if (data[nextNode][child] != MAX && child != nextNode) {int cos = dis[nextNode] + data[nextNode][child];if (cos < dis[child]) {dis[child] = cos;father[child] = nextNode;}}}}System.out.println(Arrays.toString(dis));System.out.println(Arrays.toString(father));}
}
特点:
不像距离距离矢量路由协议那样,更新时发送整个路由表。链路状态路由协议只广播更新的或改变的网络拓扑,这使得更新信息更小,节省了带宽和 CPU 利用率。而且一旦一个路由器挂了,它的邻居都会广播这个消息,可以使得坏消息迅速收敛。
d. 动态路由协议
1) 基于链路状态路由算法的 OSPF
定义:开放式最短路径优先是一个基于链路状态路由协议,广泛应用在数据中心中的协议。由于主要用在数据中心内部,用于路由决策,因而称为内部网关协议(Interior Gateway Protocol,简称 IGP)。
目标:OSPF重点是找到最短的路径。在一个组织内部,路径最短往往最优。有时候 OSPF 可以发现多个最短的路径,可以在这多个路径中进行负载均衡,这常常被称为等价路由。
2) 基于距离矢量路由算法的BGP
定义:外网的路由协议。我们称为外网路由协议(Border Gateway Protocol,简称 BGP)
自治系统 AS(Autonomous System)分类:
- Stub AS:对外只有一个连接。这类 AS 不会传输其他 AS 的包。例如,个人或者小公司的网络。
- Multihomed AS:可能有多个连接连到其他的 AS,但是大多拒绝帮其他的 AS 传输包。例如一些大公司的网络。
- Transit AS:有多个连接连到其他的 AS,并且可以帮助其他的 AS 传输包。例如主干网。
自治系统特点:每个自治系统都有边界路由器,通过它和外面的世界建立联系
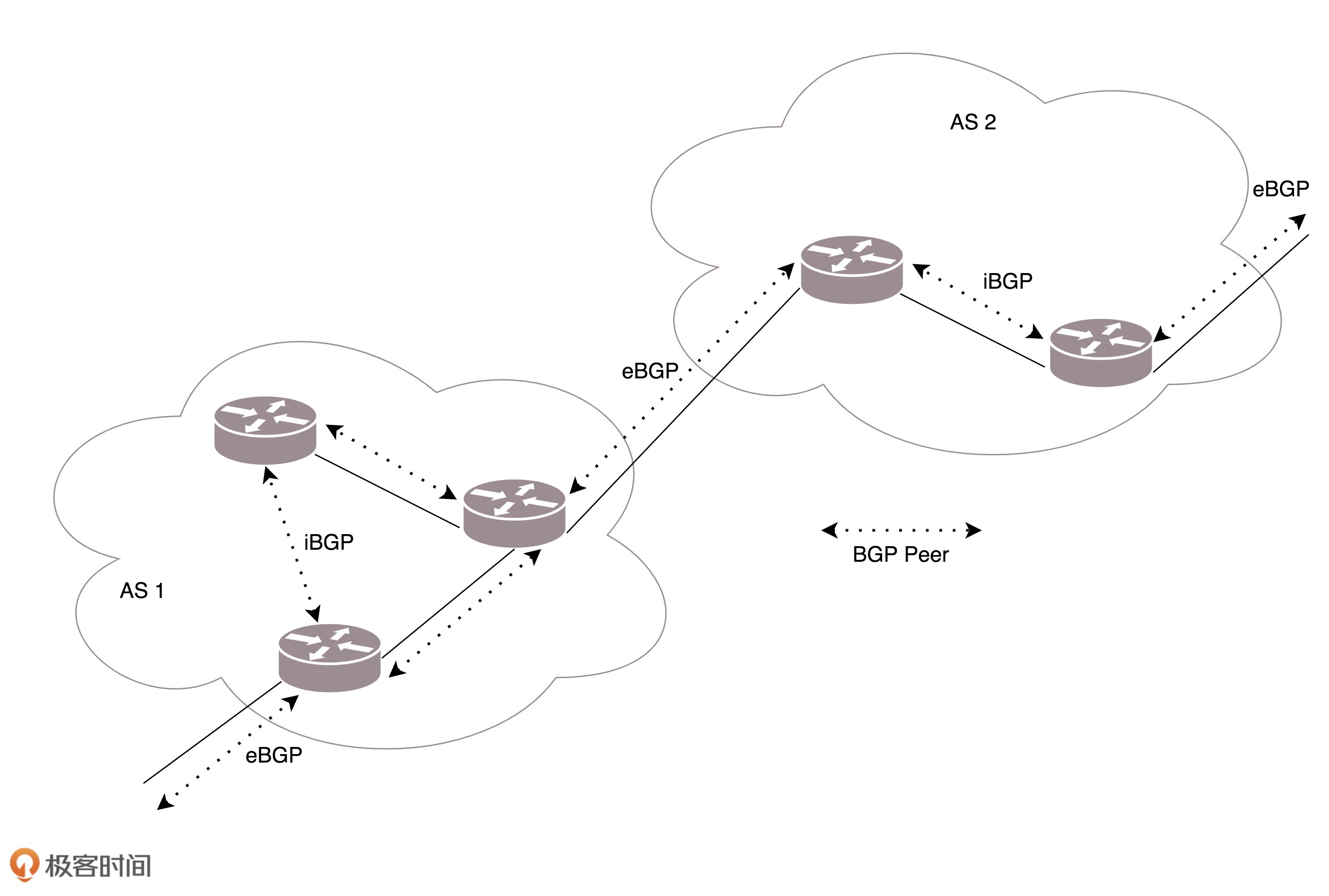
BGP分类:
- eBGP:自治系统间,边界路由器之间使用 eBGP 广播路由。内部网络也需要访问其他的自治系统。
- iBGP:边界路由器如何将 BGP 学习到的路由导入到内部网络呢?就是通过运行 iBGP,使得内部的路由器能够找到到达外网目的地的最好的边界路由器。
BGP协议核心算法:路径矢量路由协议。在 BGP 里面,除了下一跳 hop 之外,还包括了自治系统 AS 的路径,从而可以避免坏消息传得慢的问题
本文链接:https://my.lmcjl.com/post/13212.html
4 评论