| 🍺NLP开发系列相关文章编写如下🍺: | |
|---|---|
| 1 | 🎈【小沐学NLP】Python实现词云图🎈 |
| 2 | 🎈【小沐学NLP】Python实现图片文字识别🎈 |
| 3 | 🎈【小沐学NLP】Python实现中文、英文分词🎈 |
| 4 | 🎈【小沐学NLP】Python实现聊天机器人(ELIZA))🎈 |
| 5 | 🎈【小沐学NLP】Python实现聊天机器人(ALICE)🎈 |
| 6 | 🎈【小沐学NLP】Python实现聊天机器人(微软Azure)🎈 |
| 7 | 🎈【小沐学NLP】Python实现聊天机器人(微软小冰)🎈 |
| 8 | 🎈【小沐学NLP】Python实现聊天机器人(钉钉机器人)🎈 |
| 9 | 🎈【小沐学NLP】Python实现聊天机器人(微信机器人)🎈 |
| 10 | 🎈【小沐学NLP】Python实现聊天机器人(Selenium、七嘴八舌)🎈 |
| 11 | 🎈【小沐学NLP】Python实现聊天机器人(若干在线聊天机器人)🎈 |
| 12 | 🎈【小沐学NLP】Python实现聊天机器人(ChatterBot,代码示例)🎈 |
| 13 | 🎈【小沐学NLP】Python实现聊天机器人(ChatterBot,集成前端页面)🎈 |
| 14 | 🎈【小沐学NLP】Python实现聊天机器人(ChatterBot,集成web服务)🎈 |
| 15 | 🎈【小沐学NLP】Python实现聊天机器人(OpenAI,模型概述笔记)🎈 |
文章目录
- 1、简介
- 1.1 OpenAI
- 1.1.1 发布时间
- 1.1.2 论文出处
- 1.1.3 算法示意图
- 1.2 ChatGPT
- 2、研究(Research)
- 2.1 Text
- 2.2 Image
- 2.3 Audio
- 3、模型(Model)
- 3.1 GPT
- 3.2 DALL·E
- 3.3 Whisper
- 4、开发接口(Made for developers)
- 4.1 Chat
- 4.2 Embeddings
- 4.3 Analysis
- 4.4 Fine-tuning
- 5、定价(Pricing)
- 5.1 GPT-4
- 5.2 Chat
- 5.2 InstructGPT
- 5.3 Fine-tuning models
- 5.4 Embedding models
- 5.5 Image models
- 5.6 Audio models
- 结语
1、简介
1.1 OpenAI
OpenAI是全球最著名的人工智能研究机构,发布了许多著名的人工智能技术和成果,如大语言模型GPT系列、文本生成图片预训练模型DALL·E系列、语音识别模型Whisper系列等。由于这些模型在各自领域都有相当惊艳的表现,引起了全世界广泛的关注。


- 2020年5月28日,OpenAI的研究人员直接提交了论文《Language Models are Few-Shot Learners》,正式公布了GPT-3相关的研究结果,这也是当时全球最大的预训练模型,参数1750亿!GPT-3在论文中展示了强大的能力,但是如前面的版本一样,官方没有公布预训练结果文件。但是,同年9月,GPT-3的商业化授权给了微软。
- 2021年8月10日,OpenAI发布了Codex。OpenAI Codex是GPT-3的后代;它的训练数据既包含自然语言,也包含数十亿行公开的源代码,包括GitHub公共存储库中的代码。OpenAI Codex就是Github Coplilot背后的模型。当然,Codex也没有公布,而是OpenAI收费的API。
- 2022年1月27日,OpenAI发布了InstructGPT。这是比GPT-3更好的遵循用户意图的语言模型,同时也让它们更真实,且less toxic,使用的技术是通过alignment研究开发的。这些InstructGPT模型是在人类的参与下训练的,这是一个AI对话系统,也是OpenAI收费的API。
- 2022年3月15日,OpenAI新版本的GPT-3和Codex发布,新增了编辑和插入新内容的能力。也就是说除了之前的生成能力外,新增编辑和修改。
- 2022年11月30日,OpenAI发布ChatGPT系统,这是一个AI对话系统,其强大的能力也让大家再次见识到了其强大的能力。ChatGPT在很多问题上近乎完美的表现使得它仅仅5天就有了100万用户。它可以帮助我们写代码、写博客、解释技术,可以多轮对话,写短剧等等。
1.1.1 发布时间
| 模型 | 发布时间 | 参数量 | 描述 |
|---|---|---|---|
| GPT | 2018 年 6 月 | 1.17 亿 | 无监督预训练,分为无监督的预训练和有监督的模型微调 |
| GPT-2 | 2019 年 2 月 | 15 亿 | 多任务学习,使用无监督的预训练模型做有监督的任务。 |
| GPT-3 | 2020 年 5 月 | 1750 亿 | 海量参数 |
| GPT-4 | 2023 年 3 月 | 大于1750亿 | 100万亿参数,多了对对于图片的理解。多模模型,Large Multimodal Model |

1.1.2 论文出处
-
GPT-1
第一代模型 GPT-1,当时的论文叫做「通过生成式预训练模型,来提升对于语言本身的理解」Improving Language Understanding by Generative Pre-Training。其中的 Generative Pre-Training,便是现在 GPT 的来源。
2018年6月,OpenAI发表了GPT-1,GPT家族首次登上历史舞台。GPT-1模型训练使用了BooksCorpus数据集。训练主要包含两个阶段:第一个阶段,先利用大量无标注的语料预训练一个语言模型,接着,在第二个阶段对预训练好的语言模型进行精调,将其迁移到各种有监督的NLP任务。也就是前面提到过的“预训练+精调”模式。
GPT-1的核心是Transformer。Transformer在数学上是大矩阵的计算,通过计算不同语义之间的关联度(概率)来生成具有最高概率的语义反馈。
GPT-1着重解决两个问题:
1)通过无监督训练解决需要大量高质量标注数据的问题。
2)通过大量语料训练解决训练任务的泛化问题。

-
GPT-2
第二代模型 GPT-2, OpenAI 手头拿着学会了语言模型,但的确是没什么用。他们就在思考,现在是能理解文字了,但是这什么也不能干呀,这个模型到底能做什么呢?提出了第二篇论文「大语言模型,是无需监督的多任务学习者」Language Models are Unsupervised Multitask Learners。即它可以自己学会做很多很多事,不用监督瞪大眼睛看它学对没,先学再说。学会的知识,应该是具备普适性的,能够处理很多任务。
2019年,OpenAI发表了另一篇关于他们最新模型GPT-2的论文(Language Models are Unsupervised Multitask Learners)。该模型开源并在一些NLP任务中开始使用。相对GPT-1,GPT-2是泛化能力更强的词向量模型,尽管并没有过多的结构创新,但是训练数据集(WebText,来自于Reddit上高赞的文章)和模型参数量更大。目前很多开源的GPT类模型是基于GPT-2进行的结构修改或优化。 -
GPT-3
第三代模型 GPT-3,也就是大家熟悉的 ChatGPT 的前身。这个阶段,OpenAI 在冲着充分堆料,已经学会很多内容的模型陷入深深思考。第三篇论文「大语言模型,通过几个例子就能学会你要他做什么」Language Models are Few-Shot Learners。比如,如果你和一个智慧球举例,说从一数到一百,1,2,3… 它就应该能根据你的例子,去完成内容补全。甚至多学学,不用举例子也行。
2020年6月,OpenAI发表了另一篇关于GPT-3模型的论文(Language Models are Few-Shot Learners)。该模型的参数是GPT-2的100倍(175B),并且在更大的文本数据集(低质量的Common Crawl,高质量的WebText2,Books1,Books2和Wikipedia)上进行训练,从而获得更好的模型性能。GPT-3实际上由多个版本组成的第3代家族,具有不同数量的参数和所需的计算资源。包括专门用于代码编程的code系列。GPT-3的后继知名版本包括InstructGPT和ChatGPT。 -
GPT-3.5
OpenAI 手头的这几个模型一个比一个大,但是最大的问题在于,它们擅长生成符合人类说话风格的胡言乱语,但是这不符合和人类和他们交流的习惯。如果学会了世界上所有代码,应该能给人带来帮助。于是在此尝试下,推出了包含代码数据集的 OpenAI Codex,并且把这个包含了代码和新数据训练的模型叫做 GPT-3.5。
2022年3月15日,OpenAI发布了名为“text-davinci-003”的新版GPT-3,该模型被描述为比以前版本的GPT更强大。目前有若干个属于GPT-3.5系列的模型分支,其中code-davinci针对代码完成任务进行了优化。
ChatGPT是基于GPT-3.5(Generative Pre-trained Transformer 3.5)架构开发的对话AI模型,是InstructGPT的兄弟模型。ChatGPT很可能是OpenAI在GPT-4正式推出之前的演练,或用于收集大量对话数据。
OpenAI使用RLHF(Reinforcement Learning from Human Feedback,人类反馈强化学习)技术对ChatGPT进行了训练,且加入了更多人工监督进行微调。
ChatGPT具有以下特征:
1)可以主动承认自身错误。若用户指出其错误,模型会听取意见并优化答案。
2)ChatGPT可以质疑不正确的问题。例如被询问“哥伦布2015年来到美国的情景”的问题时,机器人会说明哥伦布不属于这一时代并调整输出结果。
3)ChatGPT可以承认自身的无知,承认对专业技术的不了解。
4)支持连续多轮对话。 -
InstructGPT
因为在人类世界中,我说上句你补充下句意义不大。重点还是交流,交流涉及沟通,于是便训练了基于 GPT-3.5 的对话模型 InstructGPT。这个模型中用到了很多人工反馈,对问答方式和表述方式进行更符合人性的指导。而我们现在最熟悉,最出圈的 ChatGPT,就是 InstructGPT 的一个更适合大众的姊妹模型变种。 -
GPT-4
第四代模型 GPT-4,重点强化了创作能力,如作曲,写小说等;增加了对于长文本的处理能力。最重要的,还是多了一种新的交互方式,就是对于图片的理解。也就是本次新论文的标题「多模模型」 Large Multimodal Model。与大语言模型(LLM)相比,多模态大语言模型(Multi-modal Large Language Model,MLLM)可实现更好的常识推理性能,跨模态迁移更有利于知识获取,产生更多新的能力,加速了能力的涌现。这
1.1.3 算法示意图
- GPT-1
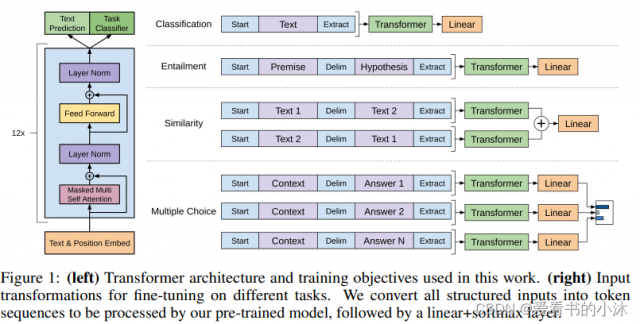
- GPT-2
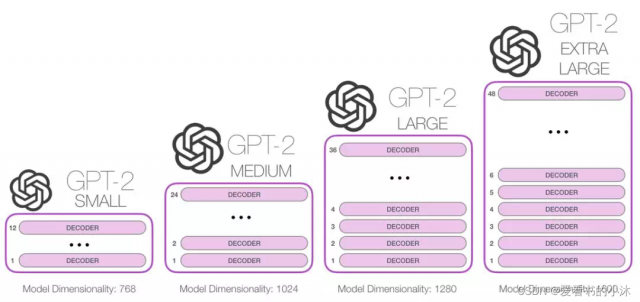
- GPT-3

1.2 ChatGPT
ChatGPT(全名:Chat Generative Pre-trained Transformer)是由 OpenAI 开发的一个人工智能聊天机器人程序,于 2022 年 11 月推出。该程序使用基于 GPT-3.5 架构的大型语言模型并通过强化学习进行训练。

ChatGPT的前世是GPT-3(Generative Pretrained Transformer-3),GPT-3是一种基于预训练的自然语言生成模型,是当前最大的语言生成模型。为了更好地处理对话任务,OpenAI在GPT-3的基础上改进了模型,并命名为ChatGPT,以适应对话应用领域的需求。
2017年,谷歌大脑团队(Google Brain)在神经信息处理系统大会(NeurIPS,该会议为机器学习与人工智能领域的顶级学术会议)发表了一篇名为“Attention is all you need”(自我注意力是你所需要的全部)的论文。作者在文中首次提出了基于自我注意力机制(self-attention)的变换器(transformer)模型,并首次将其用于理解人类的语言,即自然语言处理。
Transformer模型能够同时并行进行数据计算和模型训练,训练时长更短,并且训练得出的模型可用语法解释,也就是模型具有可解释性。
由于ChatGPT并没有放出论文,我们没法直接了解ChatGPT的设计细节。但它的blog中提到一个相似的工作InstructGPT,两者的区别是ChatGPT在后者的基础上针对多轮对话的训练任务做了优化,因此我们可以参考后者的论文去理解ChatGPT。

OpenAI已经训练了一个名为ChatGPT的模型,它以对话方式进行交互。对话形式使 ChatGPT 能够回答后续问题、承认错误、挑战不正确的前提并拒绝不适当的请求。
ChatGPT 是一个兄弟模型指示GPT,经过训练以遵循提示中的说明并提供详细的响应。
https://chat.openai.com/
我们使用来自人类反馈的强化学习(RLHF)训练了这个模型,使用的方法与InstructGPT,但在数据收集设置上略有不同。我们使用监督微调训练了一个初始模型:人类人工智能训练师提供对话,他们在其中扮演双方——用户和人工智能助手。我们让培训师可以访问模型编写的建议,以帮助他们撰写答案。我们将这个新的对话数据集与 InstructGPT 数据集混合,并将其转换为对话格式。
为了创建强化学习的奖励模型,我们需要收集比较数据,其中包括两个或多个按质量排名的模型响应。为了收集这些数据,我们进行了人工智能培训师与聊天机器人的对话。我们随机选择了一个模型编写的消息,抽样了几个替代完成,并让AI培训师对它们进行排名。使用这些奖励模型,我们可以通过以下方式微调模型近端策略优化.我们执行了此过程的多次迭代。

ChatGPT 是从 GPT-3.5 系列中的模型进行微调的,该模型于 2022 年初完成训练。您可以了解有关 3.5 系列的更多信息这里.ChatGPT 和 GPT-3.5 在 Azure AI 超级计算基础架构上进行了训练。
2、研究(Research)
2.1 Text
OpenAI的文本模型是先进的语言处理工具,可以以高度的连贯性和准确性生成、分类和总结文本。

2.2 Image
OpenAI对图像生成建模的研究导致了诸如CLIP之类的表示模型,它可以在文本和图像之间制作AI可以读取的地图,以及DALL-E,一种用于从文本描述中创建生动图像的工具。

2.3 Audio
OpenAI对将人工智能应用于音频处理和音频生成的研究导致了自动语音识别和原创音乐作品的发展。

3、模型(Model)
GPT-4 的开发,这是一种大规模的多模式模型,可以 接受图像和文本输入并生成文本输出。虽然能力不如 在许多现实世界场景中,GPT-4 在 各种专业和学术基准,包括通过模拟酒吧 考试成绩在考生中排名前 10% 左右。GPT-4 是一个 预先训练的基于转换器的模型,用于预测文档中的下一个标记。 培训后对齐过程可提高度量值的性能 事实性和对期望行为的坚持。
3.1 GPT

- 创造力
GPT-4 比以往任何时候都更具创造力和协作性。它可以生成、编辑和迭代用户进行创意和技术写作任务,例如创作歌曲、编写剧本或学习用户的写作风格。 - 视觉输入
GPT-4 可以接受图像作为输入并生成标题、分类和分析。 - 更长的背景
GPT-4 能够处理超过 25,000 字的文本,允许使用长篇内容创建、扩展对话以及文档搜索和分析等用例。 - 基础设施
GPT-4 在 Microsoft Azure AI 超级计算机上接受训练。Azure 的 AI 优化基础结构还使我们能够向世界各地的用户提供 GPT-4。 - 局限性
GPT-4 仍然存在许多我们正在努力解决的已知限制,例如社会偏见、幻觉和对抗性提示。 - 可用性
GPT-4 可在 ChatGPT Plus 上使用,并作为开发人员构建应用程序和服务的 API。

3.2 DALL·E
- Image generation
达尔·E 2 可以从文本描述中创建原始、逼真的图像和艺术。它可以组合概念、属性和样式。 - Outpainting
达尔·E 2 可以将图像扩展到原始画布之外,从而创建广阔的新构图。 - Inpainting
达尔·E 2 可以从自然语言标题对现有图像进行逼真的编辑。它可以添加和删除元素,同时考虑阴影、反射和纹理。 - Variations
达尔·E 2 可以拍摄图像并创建受原件启发的不同变体。
3.3 Whisper
Whisper可以将语音转录为文本,并将多种语言翻译成英语。
4、开发接口(Made for developers)
开发人员可以通过简单的 API 调用开始构建。
import openaiopenai.Completion.create(engine="davinci",prompt="Make a list of astronomical observatories:"
)
开始使用:
https://platform.openai.com/signup
阅读文档:
https://platform.openai.com/docs/introduction
4.1 Chat
开发人员可以使用 GPT-3 构建交互式聊天机器人和虚拟助手,以自然且引人入胜的方式进行对话。
4.2 Embeddings
借助 GPT-3,开发人员可以生成可用于文本分类、搜索和聚类等任务的嵌入。
4.3 Analysis
开发人员可以使用 GPT-3 来汇总、合成和回答有关大量文本的问题。
4.4 Fine-tuning
开发人员可以通过对自定义数据进行训练,在特定任务或域上微调 GPT-3,以提高其性能。
5、定价(Pricing)
Why OpenAI?
- 免费开始 开始尝试 5 美元的免费信用额度,可在前 3 个月内使用。
- 即用即付 为了使事情变得简单灵活,请只为您使用的资源付费。
- 选择您的型号 为作业使用正确的型号。我们提供一系列功能和价位。
5.1 GPT-4

5.2 Chat
ChatGPT 模型针对对话进行了优化。gpt-3.5-turbo的性能与Instruct Davinci相当。

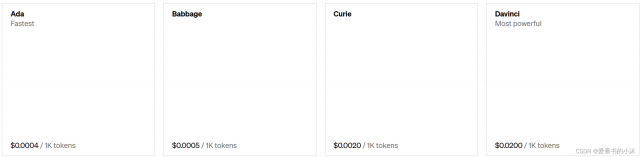
5.2 InstructGPT
Instruct models are optimized to follow single-turn instructions. Ada is the fastest model, while Davinci is the most powerful.
指令模型是经过优化的满足单轮指令集。Ada 是最快的模型,而Davinci 是最强大的。
5.3 Fine-tuning models
通过使用训练数据微调基本模型来创建自己的自定义模型。微调模型后,只需为在对该模型的请求中使用的令牌付费。

5.4 Embedding models
使用我们的嵌入产品构建高级搜索、聚类、主题建模和分类功能。

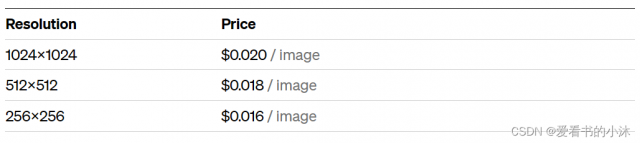
5.5 Image models
Build DALL·E directly into your apps to generate and edit novel images and art. Our image models offer three tiers of resolution for flexibility.
5.6 Audio models
Whisper can transcribe speech into text and translate many languages into English.

结语
如果您觉得该方法或代码有一点点用处,可以给作者点个赞,或打赏杯咖啡;╮( ̄▽ ̄)╭
如果您感觉方法或代码不咋地//(ㄒoㄒ)//,就在评论处留言,作者继续改进;o_O???
如果您需要相关功能的代码定制化开发,可以留言私信作者;(✿◡‿◡)
感谢各位大佬童鞋们的支持!( ´ ▽´ )ノ ( ´ ▽´)っ!!!

本文链接:https://my.lmcjl.com/post/20399.html
4 评论