标题:“Let’s Eat Grandma”: When Punctuation Matters in Sentence Representation for Sentiment Analysis
作者:Mansooreh Karami*, Ahmadreza Mosallanezhad∗ , Michelle V Mancenido, Huan Liu
机构:Arizona State University, Tempe AZ, USA
这个标题很点意思,我刚看到一脸懵“let's eat grandma”,让我们去吃奶奶???查了才发现这应该是国外的一个玩笑:
No, it's the girl, Red Riding Hood, talking to her grandmother. And with a well-placed comma it becomes: Let's eat, Grandma.
不,是小红帽在和祖母说话。其间应当放一个逗号,就变成了:我们吃饭吧,祖母。
以此来说明标点符号在文字表达中的重要性。这篇文章讲的就是在情感分析任务中将标点符号利用起来
摘要:基于神经网络的embedding已经成为创建文本的向量表示的主流方法,以捕捉词汇和语义的异同。在普遍的方法中,编码时将标点符号视为不重要的信息,因此在预处理阶段就被过滤掉了。在这篇论文中,我们假设标点符号在情感分析中发挥重要作用,并提出一种新的模型来提高句法和语境的表现。 我们通过在公开可用的数据集上进行实验来证实我们的发现,并验证我们的模型能够比其他最先进的基线方法更准确地识别情绪。
一句话总结:本文认为标点符号是文本数据的显著特征,通过利用标点符号和句法树(组成分析)之间的关联,使用一层BiGRU生成句法树向量再与原本的文本向量结合在一起生成新的句子嵌入。这些通过句法树增强后的词嵌入能够更好的传达句子的上下文意义(特别是当标点符号引起句子歧义时,如标题所示),并且更好区别这些句子(余弦相似度比其他模型小)。然后将这一嵌入应用在情感分析任务中,在三个数据集上都比最先进的基线模型(BERT)表现好。
这篇文章说是标点符号对文本语义的影响,不如说是在神经网络模型中加入句法树能够更好地表达上下文。
可借鉴的思路:
- 在词向量上扩充(考虑标点符号),使得语义的表达更加完善,比如引入组成分析生成句法树;
- 如何判断标点符号对句子的影响,人直接一读就知道两个句子意思不一样,而机器可以通过计算句子余弦相似度来判断
1.引言
文中引出了一个寓言故事,凯撒发布一条命令决定赦免一位肆无忌惮的将军:‘execute not,liberate’,但是在传递信息的时候出现错误,变成了“execute,not liberate”,结果就是这位将军被处死啦!
现在,人们的观点主要来自于网络上的文本数据,情感分析已经成为NLP领域很重要的任务之一。情感分析的目的就是判别人们对于产品、服务、文章等的观点或态度。传统的情感分类方法使用了复杂的特征工程,并且独立于上下文之间的联系。现在词和句子的embedding工具有word2vec、glove、bert等,他们创建了一个低维的潜在语义表示,使用向量之间的距离来计算语义相似性和推断上下文。此外,Wikipedia等公共语料库上预训练的嵌入被广泛使用,因为它们减少了训练NLP相关任务的非平凡计算时间。bert,一个预训练模型,通过结合两个方向的上下文信息(BERT是真正的双向模型)来解决其他方法的局限性,是目前在句子级别的情感分类中的gold standard.
在预训练语言模型中,标点符号要不就是在预处理阶段被过滤了,要不就是在数据中被当做一个普通的词(Li, Wang, and Eisner 2019)。然而这样做可能会导致符号的错位或消除,会改变原文的意义或者模糊文本的隐含情感,如“No investments will be made over three years”和“No, investments will be made over three years”完全就是两个相反的意思,但是使用bert获取的词向量会忽略逗号的作用,将两句话的词向量映射成一样的。
由于BERT等方法的明显局限性,引入标点符号来提高情感分析任务的性能是本文的主要重点。我们需要制定一种方法去表示和记录来自标点符号的句法和上下文信息,这里使用了解析树(parsing trees)去分析文本的标点符号和句法结构之间的相关性。更具体地说,我们提出了一个编码器,它集成了结构和文本嵌入,以便更准确地识别句子级别的情感。
贡献:
- 研究在文本表示中包含标点符号是否会改变句法树(基于前人的工作)
- 提出一种模型将句子的结构扩展到原始单词嵌入中
- 通过实验对比在IMDB、RottenTomatoes和斯坦福情感树库数据集上我们的方法具有一定的先进行
- 在最先进的单词和句子嵌入技术上对比不区分有标点符号和没有标点符号的句子对情感分析有啥不同。
2.相关工作
情感分析
情绪分析,也称为意见挖掘,是分析受试者的情绪、意见、情绪、态度和评价,以发现对产品、服务、组织、个人、问题、事件和主题等实体的极性。
情感分析通常沿着文本数据的三个主要层次进行(Liu,2012年):(1)寻求为整个文档分配情感标签的文档级别;(2)将句子的极性标识为正或负(在某些情况下为中性)的句子级别;(3)基于方面的分析,旨在指定针对特定方面或特征的细粒度分析。 在本文中,我们在句子层面上调查情绪,以确定一组单词是否表达了积极或消极的情绪。
词嵌入
单词和句子嵌入用于将文本映射到向量表示,使得向量之间的距离可以表示语义之间的距离。word2vec虽然他很强,但是呢在一些基于语法的问题上比如POS标注和依存句法分析上存在不足。BERT不仅编码了单词的语义还编码了单词的上下文关系,这样当同一个词处于不同语境时,也能区分出不同的意思。尽管在NLP中证明了BERT在广泛的任务中的有用性,但BERT在某些方面如常识、语用推理和否定的意义还是做得不够好。
情绪分析中的一个普遍问题是,word2vec或者说bert通常无法区分具有相似上下文但具有相反情绪极性的单词(例如wonderful terrible),因为它们被映射为潜在空间中紧密相连的向量。
在这项工作中,我们为情感分析任务设计了一个新的句子嵌入向量。
标点符号在NLP任务中的作用
(Nunberg 1990)将标点符号定义为与[词汇]语法相关的语言子系统,它传达了文本元素之间的结构关系的丰富信息。
在NLP中,标点符号已被证明在句法处理中是有用的(Jones1995;JamshidLou,Wang和Johnson2019),并可用于增强无监督依赖解析中的语法归纳。等等还很有多。
尽管有证据表明,合并标点符号可以改善NLP性能的各个方面,但很少有NLP模型能显著使用这些符号。
基于树结构的编码器
树结构编码器,是由一组单词或句子的句法结构构造的表示。一个例子就是Tree-LSTM,很好的解释句子拓扑结构的长期短期记忆。
除了改变LSTM体系结构外,另一种捕捉句子句法结构的方法是直接使用LSTM体系结构对句法结构进行编码。。。。。
本文的工作是遍历选区树,并将扩展到原始词嵌入,通过捕获结构信息来记录标点符号的位置。
3.问题陈诉
给定一组由单词和标点符号组成的文本数据X,学习一个嵌入E,它能解释句子的选区树(constituency tree structure)结构,并找到一个函数F进行分类
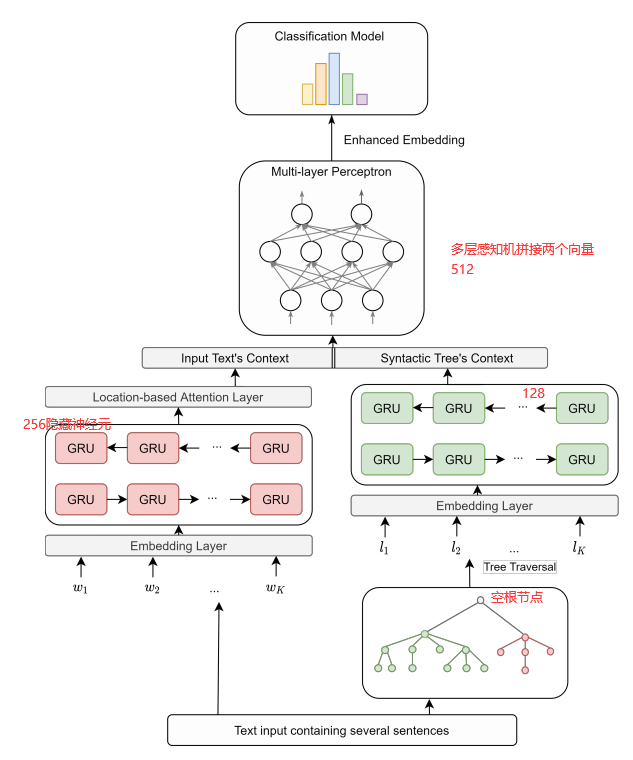
4.提出模型
我们假设,由于标点符号对句子的选区结构的影响,增加句子的结构嵌入可以提高模型的向量表示。如下图所示:一共有三层
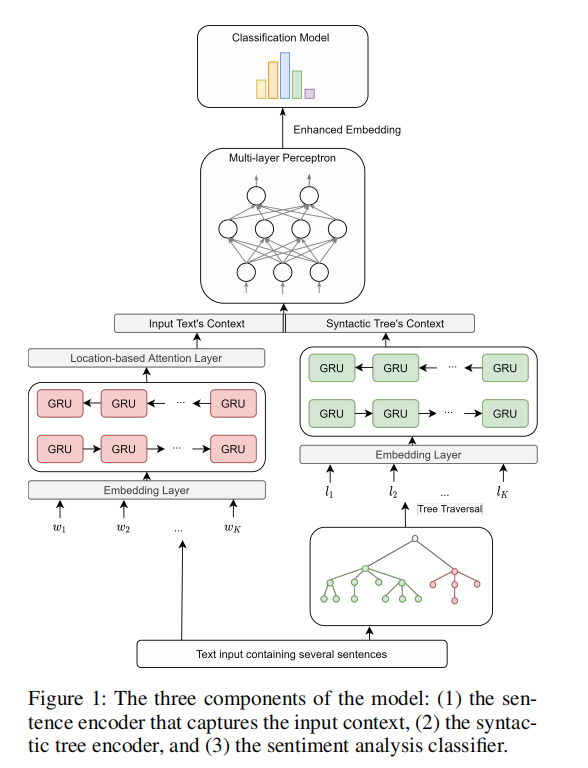
句子嵌入的情感分析Sentence Embedding for Sentiment Analysis
将文本通过编码层生成词向量,然后输入到BiGRU中生成双向的隐状态,然后将BiGRU的前向输出和后向输出连接起来,形成一个固定长度的上下文向量。(确定向量的长度是必要的,因为神经网络以处理长序列而臭名昭著),在输入到一个基于位置的注意机制中得到最终的文本上下文向量,公式如下所示:
(1)
(2)
(3)
增强的词嵌入The Enhanced Embedding
我们使用组成分析树constituency tree(组成分析介绍)来分析句子结构,并将单词组织成嵌套成分。 在选区树中,单词由叶子表示,而内部节点显示短语(NP AND VP 名词短语或者动词短语)或预终端部件-Of-Speech(POS)类别,如表1所示。树中的边缘表示语法规则集。 图2显示了一个对象树的示例,该示例树演示了的解析。

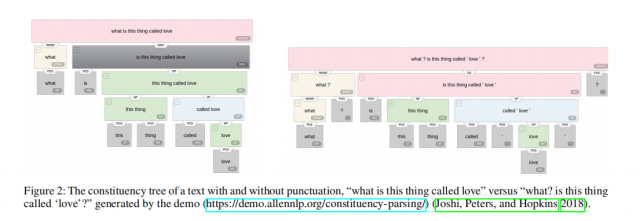
图2是句子的组成分析的可视化,可以看到,同样一句话,使用不同的标点符号,他的含义是不一样的,组成分析也是不一样的。所以我们可以利用组成分析来表示标点符号对句子含义的影响。
在使用工具生成句法树以后,采用(Liu, R.; Hu, J.; Wei, W.; Yang, Z.; and Nyberg, E. 2017. Structural embedding of syntactic trees for machine comprehension. arXiv preprint arXiv:1703.00572 . )的方法捕捉句法信息。我们遍历句法树并通过双向GRU创建句法树的表示:

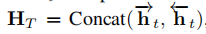
其中就表示句法树的上下文,再将句子嵌入向量的隐藏状态和通过公式(4)的前馈神经网络联合起来得到增强后的文本表示,它包含文本的语义信息和关于其句法树的信息。然后将增强后的文本表示用于情感分类任务
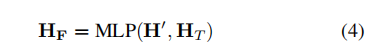
5.实验
为评估我们的方法在情绪分析任务中的有效性。 我们做了几个实验:
1.加入标点符号和未加标点符号的句子嵌入实验对比
2.使用三个流行的数据集(– IMDB(5万电影评论,积极Or消极), Rotten Tomatoes(来自腐烂番茄网站的48万部电影评论,被标记为“新鲜”(积极)或“腐烂”(消极)。), and Stanford Sentiment Treebank (SST) (10855样本数据,标签为1-5))进行情绪分析任务,并将所提出的模型的性能与其他基线进行比较。
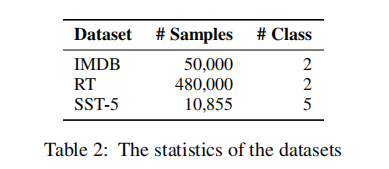
实验细节
我们选取文本每个句子的前128个词(大部分在128个词以内),然后提取每个句子的句法树,为了组合与文本相关的所有树,添加了一个空根作为句法树的所有其他根的父根。如下图所示
使用Glove将文本转换为词向量,词向量拼接在一起将句子转换为句向量。对于GloVe中不包含的单词和POS标记,使用可训练的随机向量作为代理。我们使用一个具有256个隐藏神经元的1层BiGRU来生成文本的上下文向量和一个128隐藏神经元BiGRU来生成句法树的上下文向量。为了结合这两个上下文向量,我们使用了一个简单的神经网络和512个输出神经元。 该神经网络的输出是包含输入文本的语义和句法信息的最终上下文向量HF,然后将HF用于文本分类。分类器包括三层,分别有512个、128个和C个神经元,其中C是类的数目。在训练阶段使用交叉熵损失函数更新,我们使用Adam优化器(Kingma和Ba2014)来更新网络的参数。
对比实验
分别使用四种不同的模型生成词向量,然后被用作三层神经网络分类器的输入作为对比实验。 每个句子的表示方法如下:
- BERT:用于各种NLP任务的模型,包括情感分析。 本文利用预先训练的BERT提取句子嵌入。
- BiGRU:我们设计了一个基线,使用双向GRU创建一个基于输入文本的上下文向量。 每个单词被其相应的GloVe向量替换,并通过双向门控递归单元。 然后将BiGRU的最终输出视为上下文向量。
- BiGRU+Attn但是使用基于位置的注意层(Luong、Pham和Manning,2015)来创建上下文向量。
-
SEDT-LSTM (Liu et al. 2017):使用句子的依赖树将每个单词转换为相应的向量。 对于文本中的每个单词w,该方法将w的GloVe向量与从依赖树中提取的固定长度上下文向量合并。 为了创建这个上下文向量,从w到依赖树中根节点的路径中的所有单词都被馈送到LSTM。
-
我们的模型:一个BiGRU生成常规的词向量(第二点中的方法),另一个GRU生成句法树的词向量(借鉴第四点中的方法),然后将他们结合起来生成增强后的句子嵌入。
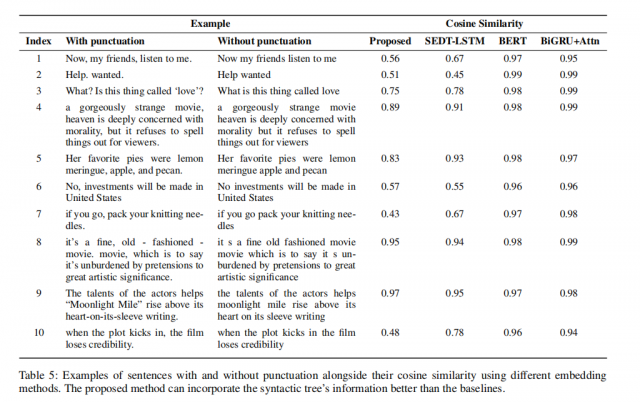
- 实验一:文本中有标点符号和没有标点符号的句子嵌入之间的相似性。使用余弦相似度计算相似性.结果如下图3所示:余弦相似度越大,说明两个句子越相似。这里的数据集如下表5所示:可以看到语料中,有标点符号影响句子意思的,也有标点符号不影响句子意思的。图3(a,b)的BERT和BIGRU模型具有较高的相似性度量。这意味着它们不会对有标点符号和没有标点符号的句子产生不同的嵌入。图3(c-d)的模型都是提取了句法树的信息, 表明有标点符号和没有标点符号的句子的表示向量是不同的,效果较好。 虽然SEDT-LSTM模型显示出很好的结果,在情绪分析任务中我们的模型仍然优于SEDT-LSTM。
( 这种差异可以解释为,在我们的模型中,我们使用BiGRU从与特定文本相关的多个选区树中创建潜在信息,这反过来又与GloVe嵌入到一个新的MLP神经网络中,以学习增强的句子表示。 另一方面,SEDTLSTM使用依赖树提取从Wordw到树根的路径中的单词;然后将其用作LSTM的输入,输出与w的GloVe向量连接。 SEDT-LSTM不像我们在模型中所做的那样考虑句法树。)

表5显示了所有模型的带标点符号和不带标点符号的样本句子的余弦相似性度量。 结果有趣的是,所提出的模型清楚地区分了句子之间的句法,其中标点符号是必要的(相似性度量较低)。 具体而言,这在表5的第1和第2句中是显而易见的(这两句的意思明显不同,所以相似度应该很低才对)。 此外,如果句子的上下文对标点符号是不可知的,我们提出的模型仍然表现得比较好(高余弦相似度量)。 这一点在表5的第4、8和9句中很明显。
实验二:情感分析实验
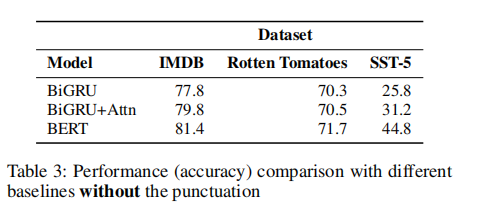
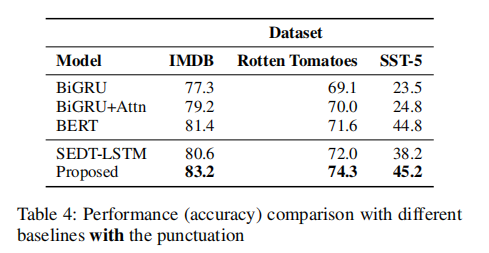
表3是没有标点符号时做情感分析,表4是带有标点符号。可以看出BiGRU,BiGRU+Attn,BERT有没有标点他们的准确率都差不多。而我们的模型是优于BERT的,这也说明了两点:一是标点符号对语义的表示是很重要的,加入标点符号进行训练能够提高情感分析的准确率;二是BERT对标点符号没有特殊的处理,所以加入标点符号没有起到什么作用,而我们提取句法树的信息加入到模型的中方法,也使得标点符号产生了作用。
本文链接:https://my.lmcjl.com/post/20898.html
4 评论