在 AIGC 这个概念如日中天的大背景下, “让 AI 直接生成能运行的应用” 是许多低代码厂商以及相关从业者的最高理想。早在 AIGC 这个概念兴起之初,潘征老师及其团队就对 AIGC 与低代码的结合进行了一系列的探索,而以 ChatGPT 为新锐代表的大模型的兴起,也为 AIGC 带来代际革新;本文将以 AIGC 在不同时期与低代码的结合为主线,挑选一些有代表性的场景,为大家展示 AIGC 与低代码 “协作” 的魅力。
01
AIGC 与低代码结合的初期探索:2017-2019
实践场景 —— 根据用户要求自动生成网页模板
以下是一个低代码建站系统的功能展示,当用户选定一系列要求(如行业、色调等)后,系统会根据用户需求自动生成一系列网站模板供用户选择。

图1 能够根据用户输入自动生成网站模板的建站系统
从图1可以看出,生成的效果有好有坏,以大众的审美标准来说,部分模板的确看起来 “还不错”,也有部分模板相当地 “辣眼睛”。
在 2017 - 2019 这个时期,类似的 “自动生成设计风格” 的 AIGC 落地场景相当普遍,除了自动生成网页设计,还有在美工短缺的情况下生成大量商品图、自动生成符合某类艺术风格的人物、风景图片等。
这类实践的背后,都普遍依赖当时非常 “火” 的一项 AI 技术 —— GAN。
时代的关键词:GAN(Generative Adversarial Network,生成对抗网络)
Generative Adversarial Network,简称 GAN,生成对抗网络。
顾名思义,“生成” 和 “对抗” 是生成对抗网络的核心概念,下面我们通过几张简单的图来看一看 “生成对抗网络” 是如何执行 “智能生成” 这项任务。
第一步:准备判断器和特征素材库
这里我们绕过艰涩的理论,以比较通俗的方法来解释判断器和素材库的作用:
-
“判断器” 会在下一步的生成对抗网络训练中起 “判断生成结果质量” 的作用
-
“特征素材库” 指的是将同类物料 “打散” 后的材料库,比方说如果我们的任务是 “生成网页设计”,那么 “素材库” 中的内容可能是左侧列表、banner图、按钮色彩等元素,在后续生成的过程中 AI 会根据用户输入去选择这些素材并按一定的规则进行拼装,从而得到最终的网页设计

图2 判断器和特征素材库的准备过程
第二步:对内容生成器进行训练
在这一步,内容生成器和判断器会以 “对抗” 的方式进行协同训练,内容生成器会从特征素材库中取一些材料来 “组合” 成 “作品”,而判断器则负责对这些“作品” 进行打分,而内容生成器则会根据判断器的反馈不断调整自身的参数,直到生成的 “作品” 大部分能获得 “高分” 评价。

图3 由判断器和内容生成器进行的“对抗式”训练
第三步:将训练好的模型部署到线上
最后,我们可以将训练好的内容生成器部署到生产环境,至此,一个基于对抗生成网络的内容生成器正式开始服务。
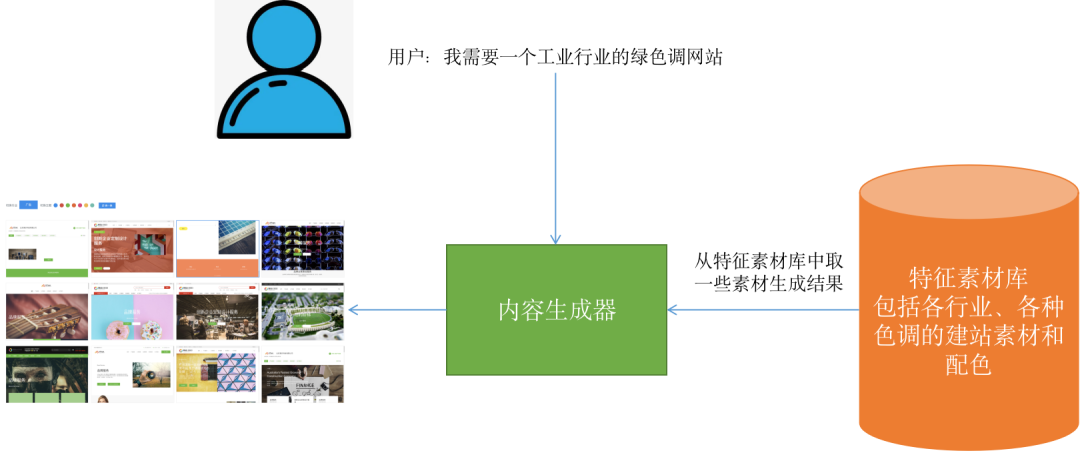
图4 生成器根据用户输入生成不同的结果
对这一时期的小结
从开头的自动生成网页模板,以及同时期的商品图生成等实践场景可以看出,基于 GAN 的生成网络更 “擅长” 的是处理一些对结果的 “准确性” 要求不高的任务。
例如在网页设计这个任务中,GAN 能比较好地处理 “视觉设计” 的部分,但无法做到在少量输入的前提下精确地 “生成” 网站制作者想要的点击交互、数据获取等复杂逻辑。故而这一阶段最终成功落地的场景,以艺术作品生成、风格处理类居多;而 “让 AI 直接生成能运行的应用” 这一目标,在这一阶段则完成得比较鸡肋。
02
AIGC 与低代码结合的现状:2020 - -
实践场景 —— 根据数据模型的字段智能生成报表
这里我们同样以一个实践场景作为切入点。
以下是一个 BI 系统中的 “数据模型” 列表,数据模型对应的是单个数据库表或多个数据库表的连接聚合。
图5 带自动分析功能的数据模型
当用户点击 “自动分析” 按钮时,弹窗会显示数据模型中的字段列表,包括字段名和字段类型等信息,用户可以勾选相应字段并进行自动分析
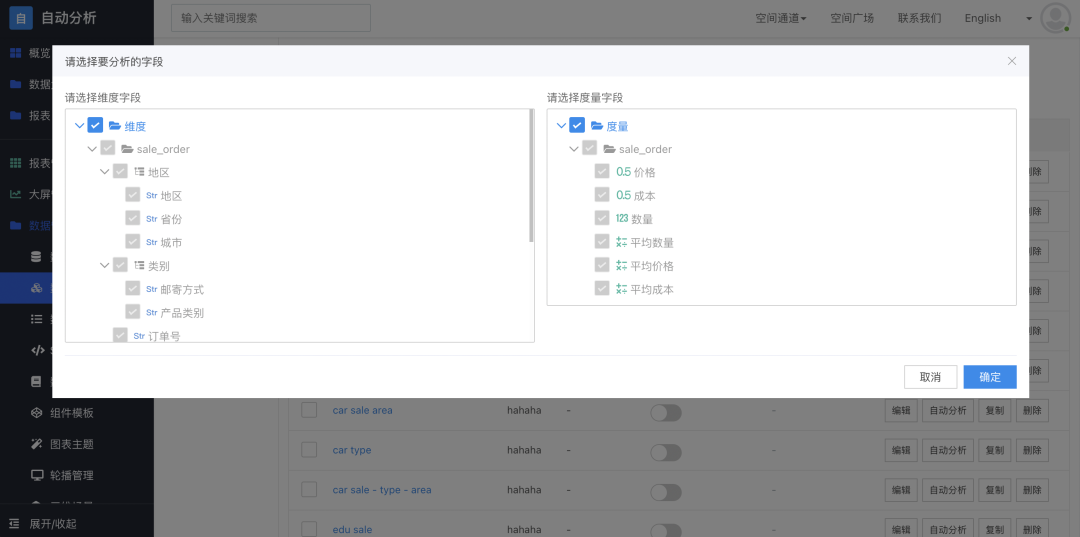
图6 数据模型中包含一系列字段
自动分析结束后,系统内置的 AIGC 引擎会根据数据字段的具体情况智能生成报表。
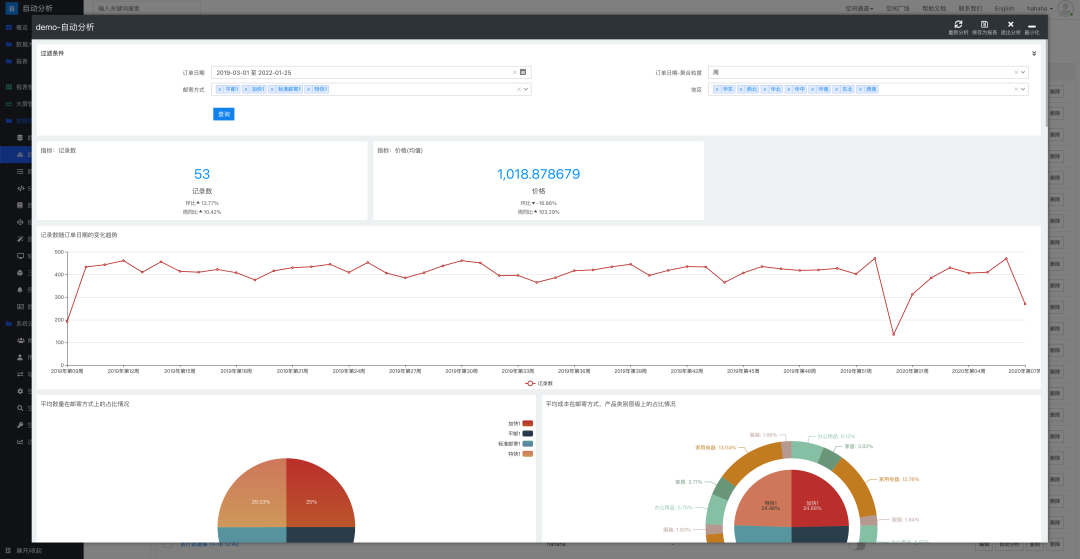
图7 AIGC 引擎生成的报表
用户可将智能生成的报表保存下来,在低代码编辑器中对其进行二次编辑
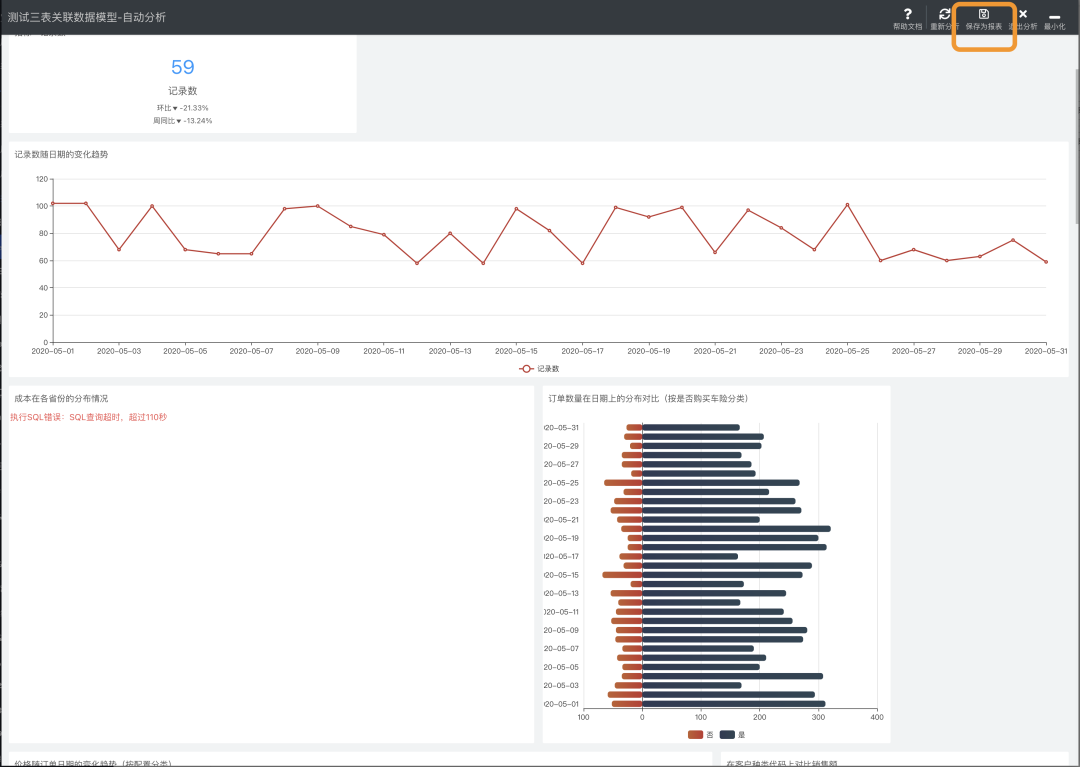
图8 在编辑器中对智能生成的报表进行二次编辑
AIGC 智能报表背后的原理
从上一节可以看到,点击 “自动分析” 后,AIGC 引擎会根据数据模型中的字段自动生成用于数据展示的报表,并自动决策应当用何种图表来展示数据、为哪些字段生成筛选组件(如为日期字段生成日期范围筛选)等,这个过程看起来很神奇,事实上也是 “有迹可循” 的。
下面我们取其中一个切面,来说明这个功能的实现原理:
-
首先我们假设数据中有一个字段,它的标题是 “销售日期”,格式类似 2023-01-01,可能是以文本格式存储的,综合以上各种因素,AIGC 引擎就可以判断出这是一个 “日期” 类型的字段,其作用可能是用于描述 “销售” 相关的时间,其他类型和含义的字段同理。
-
初步判断出该字段的关系后,在数据中寻找 “可能和该字段有关系” 的其他字段
-
判断该字段和关联字段应当用何种图表来展示
在这个过程中,每一步的决策,都可以由训练过的模型来承担,经由不同环节及步骤的决策,最终 “得出” 一个自动生成的报表
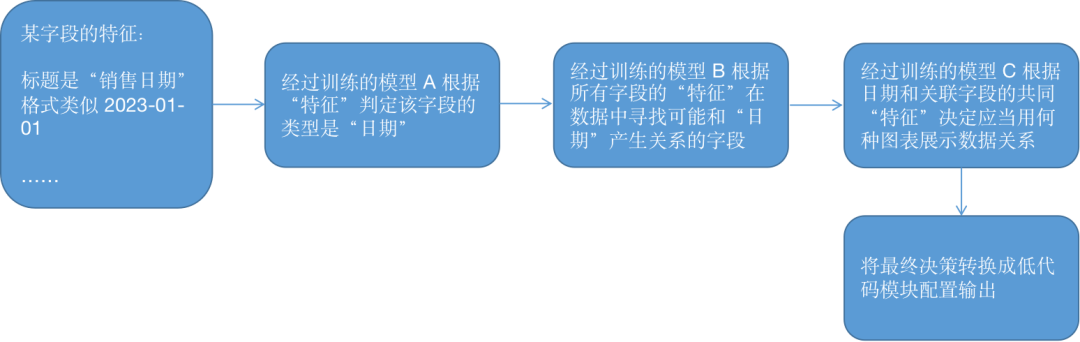
图9 智能报表的生成过程拆解
对这一时期的小结
从上面智能报表的例子中可以看出,相较于上一代简单粗暴的输入 - 输出,这一代低代码平台上 AIGC 的产出物更为精细,也肉眼可见地比上一代的产物更 “实用”。
同时,由于这一阶段正是推荐技术大热的时期,所以 AIGC 的落地很大程度上受到了 “推荐” 的影响,例如智能报表的整个生成过程,就可以抽象为一个根据字段特征 “推荐” 不同报表的过程。
03
AIGC 领域的代际革新 —— ChatGPT
ChatGPT能做什么?
这里我们先阐述几个大前提:
-
amis (https://github.com/baidu/amis)是由作者所在团队维护的一个开源的低代码前端框架,截至本文写作日期,在 github 上 star 数为 13.3 k,客观来说,知名度属于开源项目中的中等水平
-
我们从未主动向 ChatGPT 引擎提交过任何关于 amis 的材料
-
amis 实现了低代码平台中常见的将 json 配置转换为页面组件的能力
打开 ChatGPT 官网,在聊天窗中输入 “生成一段amis报名表单的配置”,可以看到,ChatGPT 自动生成了一段基本能用的配置。
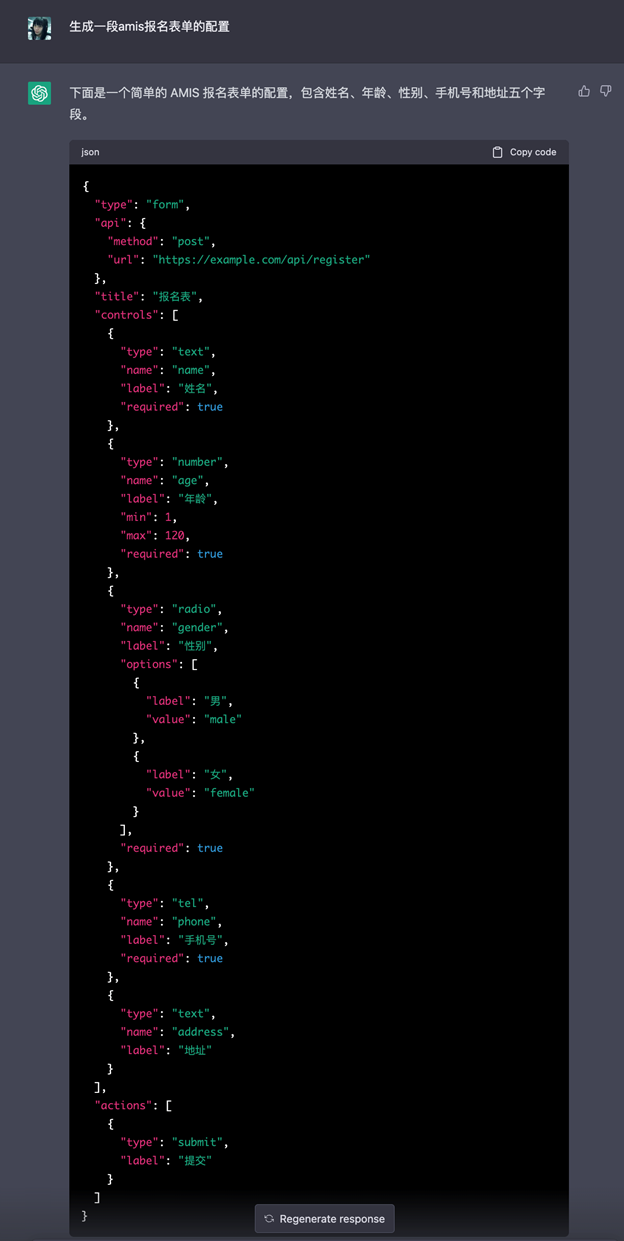
图 10第一轮生成了“接近正确答案”的结果
当然,由于 ChatGPT 参考的是内容稍微滞后的英文文档,生成的内容略有一些问题,作者与其进行了一轮 “沟通”,ChatGPT “理解” 并改正了自己的错误。
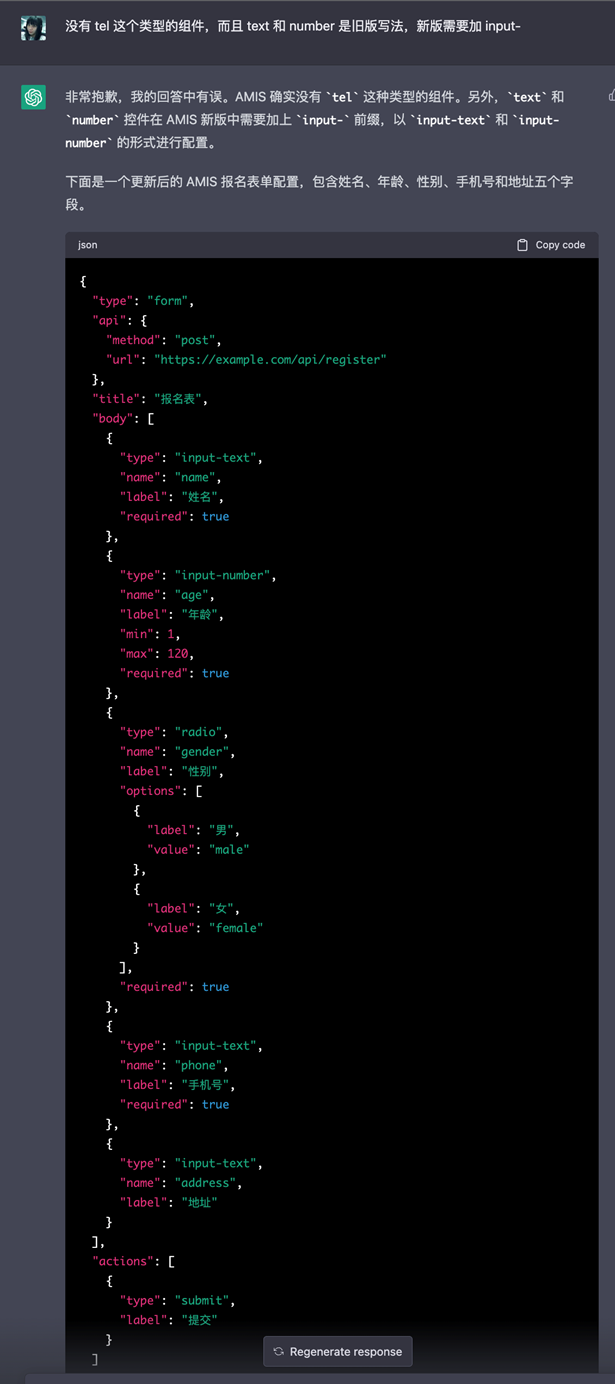
图 11第二轮沟通后,生成的结果已经接近正确
将最终生成的配置贴到对应的可视化编辑器中,可以看到基本能够正常渲染,有一个组件的类型还是错了,但是大致能跑。
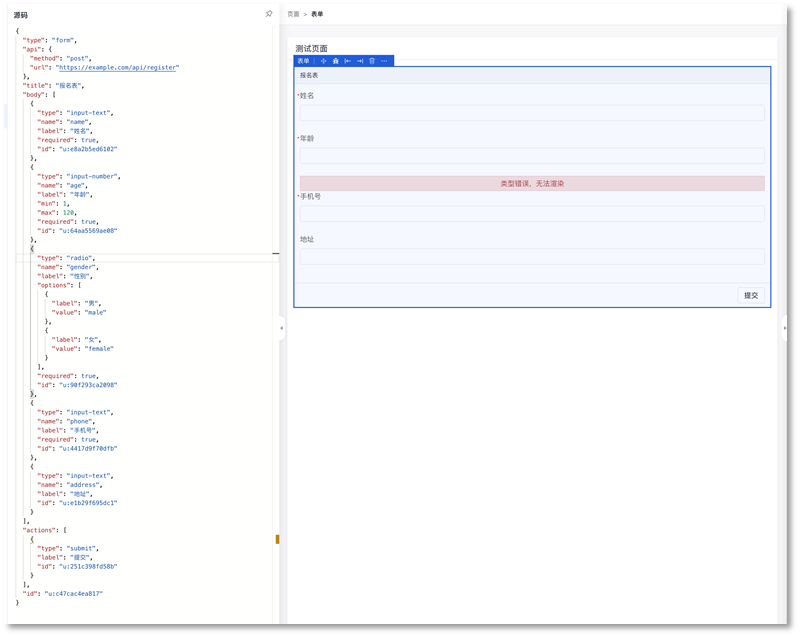
图 12 ChatGPT生成的配置在可视化编辑器中基本能够正常渲染
在整个过程中,ChatGPT仅凭一句 “生成报名表单” 的信息,就完成了以下任务:
-
规划一个报名表单应当具备哪些字段
-
决策每个字段应当用什么组件(事实上 ChatGPT 为 “性别” 字段选择了一个单选框 radio 组件,但由于实际组件名是 radios 导致没有渲染出来,但也很智能了)
-
每个字段是否必填,上限和下限等(从图中可以看到,在ChatGPT生成的配置中,姓名、年龄、手机号是必填,地址是非必填,同时为年龄字段设置了一个 1-120 的上下限)
相较前代需要大量详尽输入的 AIGC,ChatGPT 根据一句模糊的需求就能产出完整的结果,从效果上来说的确令人震惊。同时,在作者团队没有主动输入的前提下,ChatGPT 在公网上 “主动找到” 了 AMis 并对其进行了 “学习”,这也是一个非常有趣的事实。
为什么说 ChatGPT / 预训练大模型是 “代际” 革新
ChatGPT 背后的技术是 “预训练大语言模型”。这个词指的是 “预先训练” 好的 “大型” “语言领域” 模型。
相较于传统各自为战的小模型,预训练大模型更推崇的理念是在厂商训练好的大的 “通识” 模型之上辅以少量数据去进行精调,从而使整个模型具备专业知识的能力 —— 这是一个很重要的理念上的革新。
传统模式下的模型落地中,业务方拿到的通常是一个不具备任何能力的 “初始” 模型,在业务方使用业务数据(通常需要大量数据)对模型进行训练后,模型才具备处理专业领域问题的能力,当前比较成熟的产线质检,OCR 文字识别等场景,大都基于这个技术框架来实施。
而预训练大模型则在出厂的时候就具备厂商 “预训练” 好的 “常识” 能力,相比传统模型,进行专业知识训练时需要的数据量更小,训练难度更低。

图 13传统AI模型和预训练大模型的机制区别
ChatGPT / 预训练大模型在低代码领域的思考及落地场景展望
一点思考:开源、开放预训练大模型的 “通识教育”
结合上一节的分析,ChatGPT 目前对外公开的实际上是未经受专业训练的 “通识” 部分,这也是许多人觉得问到专业问题的时候 ChatGPT 会显得很 “傻” 的原因。
以下是向 ChatGPT 咨询三个不同项目生成答案的 “完成度” 对比,ECharts 代码直接拷贝保存就能直接跑起来,AMis 配置有一些问题,但也基本能正常运行,对爱速搭的回答则比较 “抽象”。
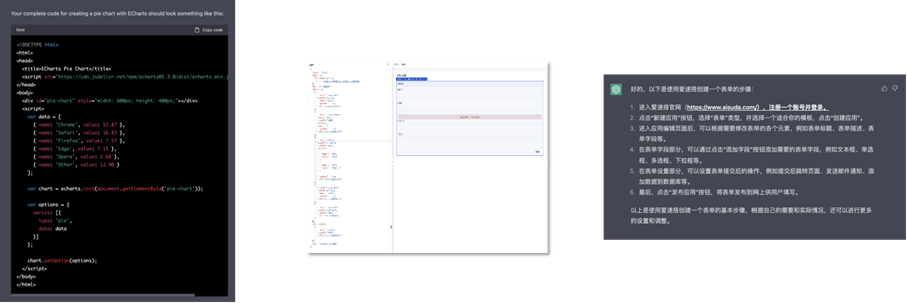
图 14著名开源项目ECharts、中等知名度开源项目AMis、非开源平台爱速搭在“通识”方面的差异
显而易见,越“开放”,公网资料越丰富的项目,ChatGPT 生成的答案质量就越好。也就是说,当前阶段如果期望 ChatGPT 或类似的公开大模型能协助处理更多的问题,把更多资料完善并公开到公网是一个不错的选择。
而对于一些不便放到公网供大模型 “学习” 的企业内部数据,综合各方情报,可能会有精简版通识基座部署内网的模式(OpenAI 目前有开放相关的邮件咨询渠道),也可能会有公有云基座 + 用户专区的模式,具体如何目前尚未有定论。
最后抛出两个作者对于落地场景的畅想,也期望在这个热潮中业界能涌现出更多灵感。
场景畅想一:降低从业人员培训难度
传统低代码开发人员的培训由一系列的课程和考试认证体系组成,非常繁琐且 “千人一面”,使用文档等数据进行训练之后,ChatGPT 能够更好地承担“帮助用户上手平台” 的任务。
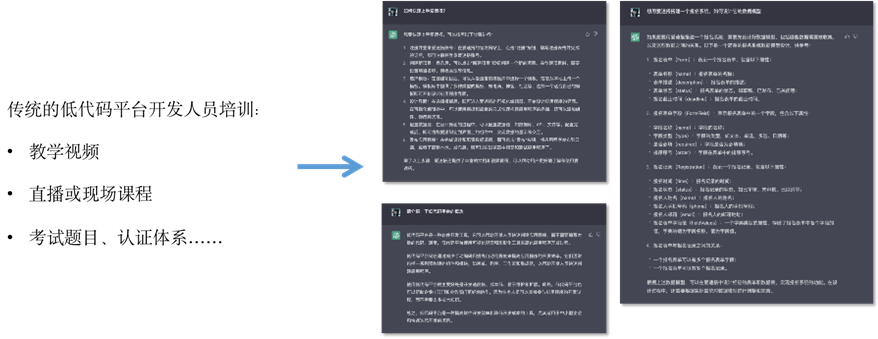
图 15用更人性化的“问答”代替传统模式化的培训
场景畅想二:通过少量数据的 “专业知识” 训练为企业生成贴合自身业务的页面 / 应用模板
每个企业都有自己自身的业务特征诉求,通过输入一些企业自身特有的常用场景精调,可以迅速地为企业打造内部专属的 “通用模板库”。
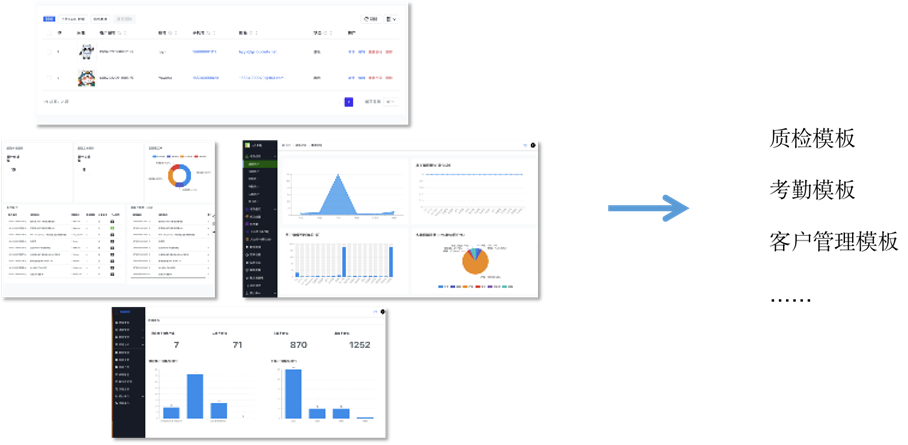
图 16将企业自身的常见场景转化为企业内的通用模板
结语
AIGC 从开始到现在经历了数轮技术迭代,在每一轮迭代中,AI 的能力比起前一代都有着质的提升。而新一代以大模型为代表的 AIGC 技术正成为时下最热的话题,在惊叹于其 “无所不知” 般优秀能力的同时,我们也有理由期望未来更多的落地场景,期待以 ChatGPT 为先锋的预训练大模型技术为低代码这个领域注入更多的 “新鲜血液”。
本文链接:https://my.lmcjl.com/post/5010.html
4 评论