今天是个伟大的日子,今天我做了两件貌似简单但实际上都不容易的事情:一、用电子琴录制了Realeza(WWE Alberto Del Rio Theme 2010)并用WIDI生成了MIDI版本;二、努力奋战、冥思苦想2天后,我终于达到了我的目标,完成了大名鼎鼎YARK系列的P25 PHP小程序。
所以,对我来说,这是划时代的一天,心情大好!
一、音乐部分
几个月前我就已经挖出家里的古董电子琴(小学时期的产物)来折腾Realeza了。一般熟练,但我只会右手,和弦对我来说是浮云,正如听音乐我只能辨别出主旋律一样。我一直在奢望自己能学会哪怕一点点左手,但电子琴的变压器不行,大号电池的电量也快没了,我得在电子琴还有声音之前赶快完成录制。
以下是xrspook极其简陋的两个自创版Realeza,请凑合着欣赏:
Realeza(WWE Alberto Del Rio Theme 2010)电子琴版[mp3]
Realeza(WWE Alberto Del Rio Theme 2010)WIDI转化MIDI版[midi]
说明:mp3就是拿着个mic对着电子琴录制的,没啥好说,请原谅我的古董电子琴没有跟电脑对接输出的玩意,毕竟那是1998年以前的产物啊,还只是386、486时代呢。midi嘛,不是我自己写的,是用WIDI把mp3转出的,因为是毋庸置疑的“独奏”,所以捕捉到的绝大多数音都是我的意图,但有几个高音电脑识别出来时一个变2个,没搞懂原因,但错有错着,恰逢那是高潮部分,出现这些我意想不到的小变动反而让音乐更丰满。
二、PHP程序部分
从有思路到PHP完全成型,我用了2天,超过15个小时!累着并快乐着!我这个喜欢折磨自己的人……这不能算折磨,这应该说是定下目标然后努力实现,I’m proud of myself.
先说说这个YARK – P25的整体思路,昨天已经说过,也就是“用正则提取,table输出,然后直接Excel粘贴保存”。昨天傍晚说到,我被正则难住了,但昨天晚上,我却突然惊醒地想出了正解。在WWE P25层层div的网页里成功提取出我需要的排名部分。用的是这条正则,针对的是我需要提取信息的开头和结尾部分做筛选。
1 | preg_match_all('/< div class="row(.|\n)*?<div class="clear">/', $data, $log); |
preg_match_all('/< div class="row(.|\n)*?<div class="clear">/', $data, $log);
这条规则是很有针对性的,可以把WWE P25页面我需要部分嵌套的div全部提取出来,但对其他嵌套div网页无效。这条规则的重点是“(.|\n)”意思是“除换行符以外的任意字符或者换行符”,也就是全包围了。从前提取img的时候“.*?”也就足够了,但提取div不一样,因为换行是习惯性的,之前我正是在换行这个问题上被卡住,看到某个网页的时候被这句很创意的“(.|\n)”激发,最终,琢磨出我的第一次正则。
筛选出的排名部分网页源代码包括神马呢?以下是详细说明:

1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | <div class="row none"> /* WWE P25页面里,一个选手的所有信息的开始,这里的class可能是row none、row fire、row ice或row (注意row后的空格)*/ <div class="info dir-up"> /*这里的class可能是info dir-up、info dir-dn或info dir-nm,升降平,你懂的*/ <div class="direction"></div> /*配合升降平的一个说明*/ <div class="thisweek"></div> /*本周排位,我需要的第一个信息点*/ <div class="lastweek"></div> /*上周排位,如果我把每周排位都收集了,某一周的上周排位对我来说当然没啥意义*/ </div> /*info dir-up结束*/ <div class="thumb"> /*小头像部分,这里没有我需要的信息*/ <a href="***"></a><a href="***" class="imagecache imagecache-98x105_thumb imagecache-linked imagecache-98x105_thumb_linked"><img src="***" alt="" title="" width="98" height="105" /></a> /*用了两层超链接,没搞懂为什么,外层没有class,内层有class,核心部分是小头像图片img,注意,有些选手是没有超链接的,比如说那些Tag Team*/ </div> /*thumb结束*/ <div class="thumb_none"> /*这里可能是thumb_none、thumb_ice、thumb_fire或thumb_,对应头像无特效、冰、火以及无头像状态*/ </div> /*thumb_none结束*/ <div class="details"> /*选手信息*/ <h2 class="double-arrow-title"> /*二级标题开始*/ <a href="***">***</a> /*选手名字+超链,选手名字是我需要的第二个信息点*/ </h2> /*二级标题结束*/ <div class="text">***</div> /*这周发生了神马事,我需要的第三个信息点*/ </div> /*details结束*/ <div class="clear"></div> /*纯粹的网页需要清浮处理 */ </div> /*row none结束*/ |
<div class="row none"> /* WWE P25页面里,一个选手的所有信息的开始,这里的class可能是row none、row fire、row ice或row (注意row后的空格)*/ <div class="info dir-up"> /*这里的class可能是info dir-up、info dir-dn或info dir-nm,升降平,你懂的*/ <div class="direction"></div> /*配合升降平的一个说明*/ <div class="thisweek"></div> /*本周排位,我需要的第一个信息点*/ <div class="lastweek"></div> /*上周排位,如果我把每周排位都收集了,某一周的上周排位对我来说当然没啥意义*/ </div> /*info dir-up结束*/ <div class="thumb"> /*小头像部分,这里没有我需要的信息*/ <a href="***"></a><a href="***" class="imagecache imagecache-98x105_thumb imagecache-linked imagecache-98x105_thumb_linked"><img src="***" alt="" title="" width="98" height="105" /></a> /*用了两层超链接,没搞懂为什么,外层没有class,内层有class,核心部分是小头像图片img,注意,有些选手是没有超链接的,比如说那些Tag Team*/ </div> /*thumb结束*/ <div class="thumb_none"> /*这里可能是thumb_none、thumb_ice、thumb_fire或thumb_,对应头像无特效、冰、火以及无头像状态*/ </div> /*thumb_none结束*/ <div class="details"> /*选手信息*/ <h2 class="double-arrow-title"> /*二级标题开始*/ <a href="***">***</a> /*选手名字+超链,选手名字是我需要的第二个信息点*/ </h2> /*二级标题结束*/ <div class="text">***</div> /*这周发生了神马事,我需要的第三个信息点*/ </div> /*details结束*/ <div class="clear"></div> /*纯粹的网页需要清浮处理 */ </div> /*row none结束*/
这段内容重复25次就是一个P25的完整排名信息。
第一次正则只是个开始,是把偌大一个网页的信息进行初步挖掘。其实也不能算一个网页,自从WWE 2011年头改版后,网页构成发生了巨大变化,比如说到处都有“LOAD MORE”的标志,你必须点击才能看更多内容,以P25的页面为例,我们看到的是:
http://us.wwe.com/inside/power25
但实际上,一共需要载入5个页面才能看到全部25个排名:
http://us.wwe.com/inside/power25
http://us.wwe.com/inside/power25?page=1
http://us.wwe.com/inside/power25?page=2
http://us.wwe.com/inside/power25?page=3
http://us.wwe.com/inside/power25?page=4
每个页面只有5个排名。这也就能解释为什么浏览WWE网页的速度会比从前快了,因为一次性加载的信息减少,信息加载随着浏览进程的推进而逐步增加,对于那些纯粹路过的人来说省事多了。
这5个页面的结构是一样的,对我这个需要提取信息的人来说WWE的这个“改进”完全是件坏事!一开始,我是这样提取页面信息的:
1 2 3 4 5 6 7 8 9 | $data0 = get_content($_POST['url']); $data1 = get_content($_POST['url']).'?page=1'; $data2 = get_content($_POST['url']).'?page=2'; $data3 = get_content($_POST['url']).'?page=3'; $data4 = get_content($_POST['url']).'?page=4'; /*经历N步操作,N步操作的工作量都是×5,我甚至都在考虑要不要来个for语句来减轻修改数字的压力了*/ $data = array_merge($data0[0], $data1[0], $data2[0], $data3[0], $data4[0]); |
$data0 = get_content($_POST['url']); $data1 = get_content($_POST['url']).'?page=1'; $data2 = get_content($_POST['url']).'?page=2'; $data3 = get_content($_POST['url']).'?page=3'; $data4 = get_content($_POST['url']).'?page=4'; /*经历N步操作,N步操作的工作量都是×5,我甚至都在考虑要不要来个for语句来减轻修改数字的压力了*/ $data = array_merge($data0[0], $data1[0], $data2[0], $data3[0], $data4[0]);
但后来,我发现完全可以这样嘛:
1 | $data = get_content($_POST['url']).get_content($_POST['url'].'?page=1').get_content($_POST['url'].'?page=2').get_content($_POST['url'].'?page=3').get_content($_POST['url'].'?page=4'); |
$data = get_content($_POST['url']).get_content($_POST['url'].'?page=1').get_content($_POST['url'].'?page=2').get_content($_POST['url'].'?page=3').get_content($_POST['url'].'?page=4');
如此一来,5个页面的信息也就能一次性地聚合到一起,快、准、狠!
我好像扯远了,回到第一次正则提取的内容。我昨天的思路是对其进行XML数组化,但很遗憾,XHTML网页不是XML,当信息传入外包的XML数组化程序时失败告终。于是,我就只能靠自己继续正则了。
上文已经提到,在第一次正则后的内容里,我有3个需要提取的信息点,它们分别是:
1 2 3 | <div class="thisweek"></div> /*本周排名*/ <h2 class="double-arrow-title"><a href="***">***</a></h2> /*选手名字*/ <div class="text">***</div> /*发生事件*/ |
<div class="thisweek"></div> /*本周排名*/ <h2 class="double-arrow-title"><a href="***">***</a></h2> /*选手名字*/ <div class="text">***</div> /*发生事件*/
一次正则后选手名字里有超链,头像里也有超链,“h2”本是选手名字的唯一标记,但由于中间多了个超链,万恶,所以,我也很万恶地一句正则把我不喜欢的东西全部干掉。
1 | $log[0] = preg_replace('/< a [^>]*>|< \/a>|<img [^/>]*>|\t|\r|\n/', '', $log[0]); |
$log[0] = preg_replace('/< a [^>]*>|< \/a>|<img [^/>]*>|\t|\r|\n/', '', $log[0]);
1 2 3 | < a [^>]*>|< \/a> /*干掉所有超链*/ <img [^/> /*干掉所有图片*/ \t|\r|\n /*干掉所有制表符、回车和换行符*/ |
< a [^>]*>|< \/a> /*干掉所有超链*/ <img [^/> /*干掉所有图片*/ \t|\r|\n /*干掉所有制表符、回车和换行符*/
二次正则过后,提取内容变得简洁。
必须提醒:在PHP里正则针对的都是字符串,所以,如果源数据已经是数组的话,请自行拆解。否则会报错,并且会暴露出当前运行脚本的完整路径,这可是安全性的问题啊,详见这里。
然后呢,因为一次正则我只提取到< div class="clear">显然后面仍应该有< /div>< /div>
才能让这个提取内容闭合完整。所以我加了这么一句:
1 | $log[0] = str_replace('< div class="clear">', '<div class="clear"></div>< /div>', $log[0]); |
$log[0] = str_replace('< div class="clear">', '<div class="clear"></div>< /div>', $log[0]);
到此为止,经过2次正则,1次字符串替换后,那坨东西符合我要求了,我可以进行第3、4、5次正则完成我的最终提取。
1 2 3 | preg_match_all('/< div class="thisweek">([^< ]*)/', $log[0][$i], $rank[$i]); preg_match_all('/<h2[^>]*>([^< ]*)/', $log[0][$i], $name[$i]); preg_match_all('/< div class="text">([^< ]*)/', $log[0][$i], $text[$i]); |
preg_match_all('/< div class="thisweek">([^< ]*)/', $log[0][$i], $rank[$i]); preg_match_all('/<h2[^>]*>([^< ]*)/', $log[0][$i], $name[$i]); preg_match_all('/< div class="text">([^< ]*)/', $log[0][$i], $text[$i]);
好吧,到此为止,整个分析、剥离过程完满结束,就只剩下按要求的规范化输出。就是把我提取到的东西table化,略。
整个过程的部分源程序如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 | function get_content($url) /*网址转化为网页内容*/ { $ch = curl_init(); curl_setopt ($ch, CURLOPT_URL, $url); curl_setopt ($ch, CURLOPT_HEADER, 0); ob_start(); curl_exec ($ch); curl_close ($ch); $string = ob_get_contents(); ob_end_clean(); return $string; } /*数据传入开始*/ $_POST['url'] = str_replace("www.wwe.com", "us.wwe.com", $_POST['url']); $data = get_content($_POST['url']).get_content($_POST['url'].'?page=1').get_content($_POST['url'].'?page=2').get_content($_POST['url'].'?page=3').get_content($_POST['url'].'?page=4'); /*数据传入结束*/ /*正则提取及替换开始*/ $data = str_replace("&", '&', $data); preg_match_all('/<div class="row(.|\n)*?<div class="clear">/', $data, $log); $log[0] = preg_replace('/< a [^>]*>|< \/a>|<img [^/>]*>|\t|\r|\n/', '', $log[0]); $log[0] = str_replace('< div class="clear">', '<div class="clear"></div></div>', $log[0]); for($i=0;$i < count($log[0]);$i++) { preg_match_all('/<div class="thisweek">([^< ]*)/', $log[0][$i], $rank[$i]); preg_match_all('/<h2[^>]*>([^< ]*)/', $log[0][$i], $name[$i]); preg_match_all('/<div class="text">([^< ]*)/', $log[0][$i], $text[$i]); } /*正则提取及替换结束*/ /*table格式化开始*/ echo '< table>< col>'; for($i=0;$i < count($log[0]);$i++) { echo '<tr>'; echo '<td>'.$rank[$i][1][0].'</td>'; echo '<td>'.$name[$i][1][0].'</td>'; echo '<td>'.$text[$i][1][0].'</td>'; echo ''; } echo ''; /*table格式化结束*/ |
function get_content($url) /*网址转化为网页内容*/ { $ch = curl_init(); curl_setopt ($ch, CURLOPT_URL, $url); curl_setopt ($ch, CURLOPT_HEADER, 0); ob_start(); curl_exec ($ch); curl_close ($ch); $string = ob_get_contents(); ob_end_clean(); return $string; } /*数据传入开始*/ $_POST['url'] = str_replace("www.wwe.com", "us.wwe.com", $_POST['url']); $data = get_content($_POST['url']).get_content($_POST['url'].'?page=1').get_content($_POST['url'].'?page=2').get_content($_POST['url'].'?page=3').get_content($_POST['url'].'?page=4'); /*数据传入结束*/ /*正则提取及替换开始*/ $data = str_replace("&", '&', $data); preg_match_all('/<div class="row(.|\n)*?<div class="clear">/', $data, $log); $log[0] = preg_replace('/< a [^>]*>|< \/a>|<img [^/>]*>|\t|\r|\n/', '', $log[0]); $log[0] = str_replace('< div class="clear">', '<div class="clear"></div></div>', $log[0]); for($i=0;$i < count($log[0]);$i++) { preg_match_all('/<div class="thisweek">([^< ]*)/', $log[0][$i], $rank[$i]); preg_match_all('/<h2[^>]*>([^< ]*)/', $log[0][$i], $name[$i]); preg_match_all('/<div class="text">([^< ]*)/', $log[0][$i], $text[$i]); } /*正则提取及替换结束*/ /*table格式化开始*/ echo '< table>< col>'; for($i=0;$i < count($log[0]);$i++) { echo '<tr>'; echo '<td>'.$rank[$i][1][0].'</td>'; echo '<td>'.$name[$i][1][0].'</td>'; echo '<td>'.$text[$i][1][0].'</td>'; echo ''; } echo ''; /*table格式化结束*/
截图是必须的
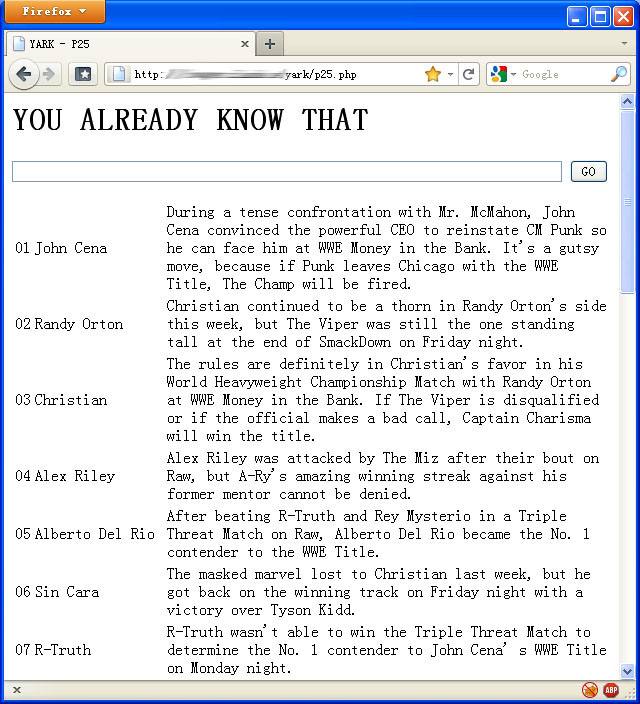
这就是YARK – P25的威力!你或许会问,就那么一大坨东西有神马用呢?呵呵,真正用法需要把它们贴到Excel。
关于复制那一大坨信息的Excel粘贴也有讲究。
首先,打开Excel,然后选择“编辑 – 选择性粘贴”,然后在“方式”里选择“文本”,按“确定”。最后简单调节表格列距以及单元格格式后,你就能得到如下图的效果:

你一定会问,为神马要如此折腾“粘贴”而不用“Ctrl+V”?呵呵,这和我的用途有关,你完全可以在“选择性粘贴”里用默认的“HTML”方式,结果跟直接用“Ctrl+V”一样,所有粘贴数据都全部挤在1个单元格里,这显然不符合我的设想,如果最后得出这样一个结果的话,我之前所做的事情都白费了。
为什么一定要以现在这个各信息分离的Excel形式呈现呢?因为,我做这么多事情的目的就是能更快更直接地提取我需要的信息,做P25的每周统计。
统计!统计是我的目的!!!!
还记得2天前我做的“ADR前46周的WWE P25”?那可花费了我半天的时间打开一个个网页,一段段信息复制粘贴并最终形成图表。如果,我要对WWE所有选手都这般干的话简直是天方夜谭,但我的确想获取那些信息,知道那个趋势,该怎么办呢?所以我有了弄YARK – P25的念头,并付诸行动,最终华丽地成功了!
YARK – P25在此!聪明的你肯定知道怎么用的。
往后,随着icon化的日益加剧,我真的可能不再看WWE的摔角而转投其他联盟,但我会记住WWE的,不单是因为他们把我引入摔角门,更重要的是为了提取信息,我从他们的网页我自学到了很多,他们的网页严谨规范,虽然可能不是最好的,但我已经从中领会到很多,难道这还不够么?!
哇咔咔,今天的blog很技术,有心人,你们会懂的。
本文链接:https://my.lmcjl.com/post/6254.html
4 评论