在开源大模型LLaMA等成熟后,目前业界焦点在于:如何才能让 LLM 按照我们的要求去做,也就是prompt工程,设计产生大量prompt训练语料用于微调大模型
设计原则
首先要说的是设计原则,主要包含以下几个:
- 清晰,切忌复杂或歧义,如果有术语,应定义清楚。
- 具体,描述语言应尽量具体,不要抽象或模棱两可。
- 聚焦,问题避免太泛或开放。
- 简洁,避免不必要的描述。
- 相关,主要指主题相关,而且是整个对话期间,不要东一瓢西一瓢。
生成策略
生成相关指令-斯坦福Alpaca self-instruct
https://www.toutiao.com/article/7210616578801533472/?app=news_article×tamp=1678855351&use_new_style=1&req_id=2023031512423069CE4A3C83F23872EDE2&group_id=7210616578801533472&share_token=2EDD020F-68F0-42EC-BBBA-26BC4E8EAE16&source=m_redirect
Alpaca 使用 LLaMA 7B 模型的监督学习在 text-davinci-003 以 self-instruct 方式生成的 52K 指令遵循样本上进行微调。
Alpaca 的研究团队首先使用 self-instruct 种子集中的 175 个人工编写的指令输出(instruction-output)对,然后用该种子集作为 in-context 样本 prompt text-davinci-003 来生成更多指令。该研究通过简化生成 pipeline 改进了 self-instruct 方法,并显著降低了成本。
方法概览
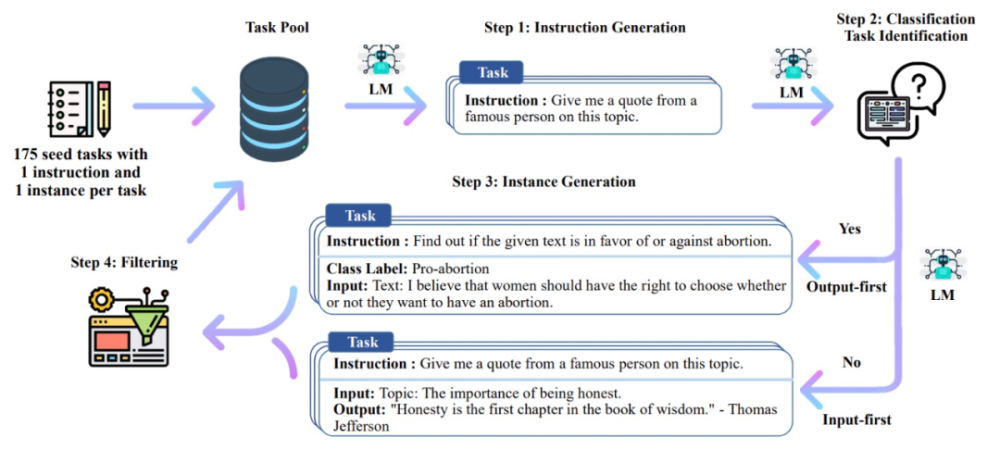

指令模板
生成新指令的模板如下:

评估
在将 text-davinci-003 和 Alpaca 7B 进行 blind pairwise 比较之后,研究者发现这两个模型的性能非常相似,并且 Alpaca 略优于 text-davinci-003。
能生成大规模指令,但新指令的质量完全依赖于大模型的水平,实验中,Alpaca 还表现出语言模型的几种常见缺陷,包括幻觉、毒性和刻板印象,其中幻觉问题尤其严重。
生成同义指令-APE(Automatic Prompt Engineer)
https://m.thepaper.cn/baijiahao_20718621
研究者从 LLM 的三个特性入手。首先,使用 LLM 作为推理模型,根据输入 - 输出对形式的一小组演示生成指令候选。接下来,通过 LLM 下的每条指令计算一个分数来指导搜索过程。最后,他们提出一种迭代蒙特卡洛搜索方法,LLM 通过提出语义相似指令变体来改进最佳候选指令。
方法概览
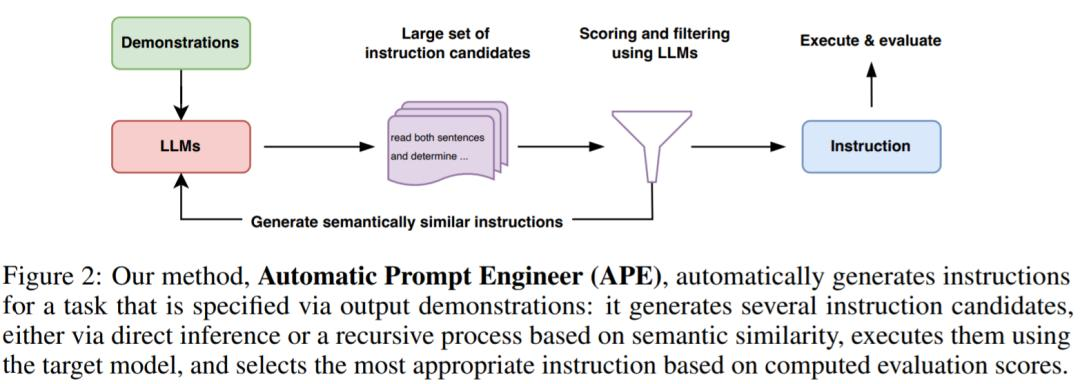
步骤流程
下图为 APE 的执行过程。它可以通过直接推理或基于语义相似度的递归过程生成几个候选 prompt,评估其性能,并迭代地提出新的 prompt。

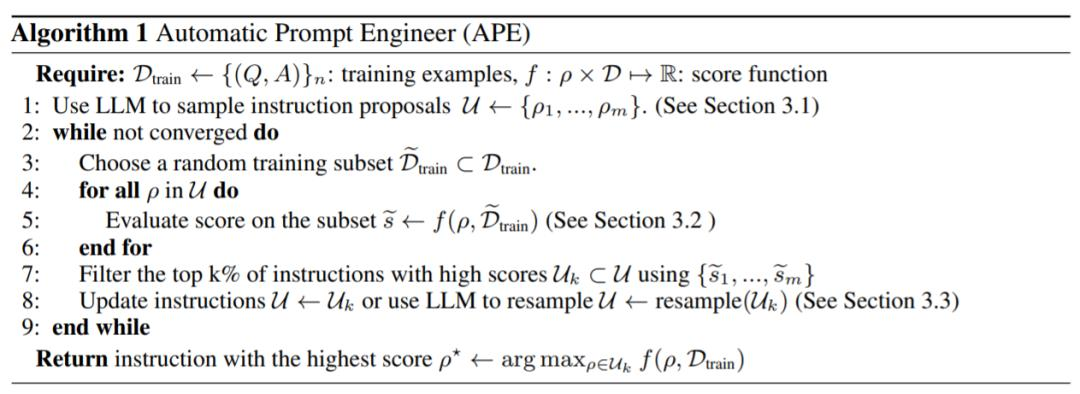
第一步:基于多个输入/输出示例让大模型预测指令
第二步:采用上步得到的预测指令作为新指令让大模型预测给出的输入对应的输出结果,并根据标准答案评分
第三步:对多个预测的指令按分数排序,去掉低分指令
第四步:(可选)通过大模型预测高分指令的同义指令
第五步:(可选)对同义指令让大模型预测给出的输入对应的输出结果,并根据标准答案评分
第六步:(可选)对多个同义指令按分数排序,去掉低分指令
评估
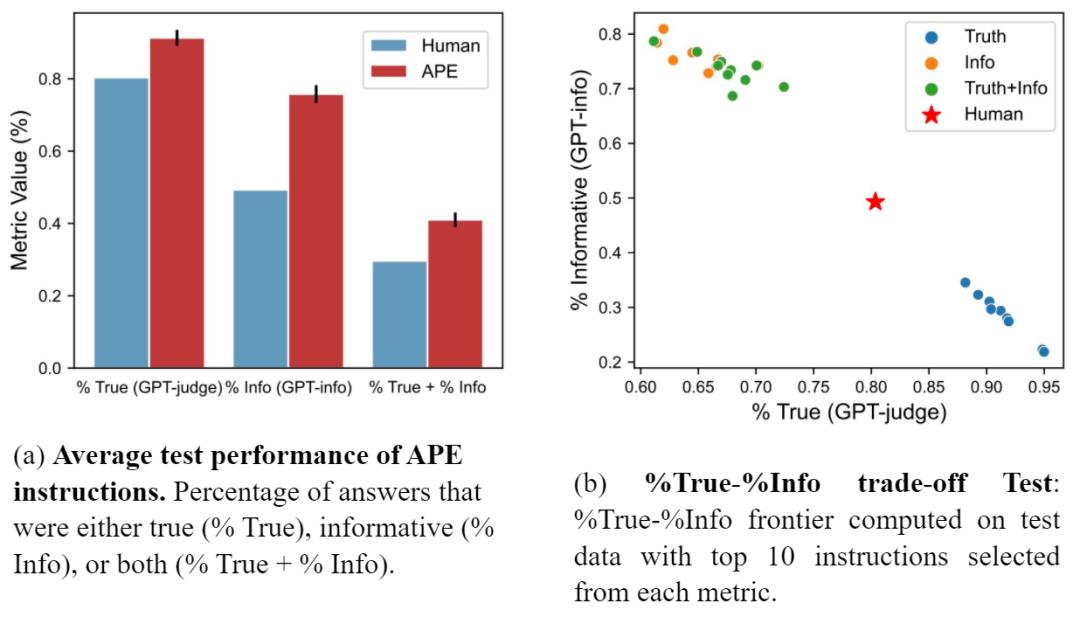
研究者还将 APE prompt 与 Lin 等人提出的人工 prompt 进行了对比。图 (a) 显示 APE 指令在所有三个指标上的表现都优于人工 prompt。图(b)显示了 truthfulness 和 informativeness 之间的权衡。
该方法仅适用于生成同义指令,应用范围有效,但用它来增强其他大模型的指令理解能力还是有效的
基于模板生成指令-面向信息抽取任务
https://zhuanlan.zhihu.com/p/615093883
最近有篇文章《Zero-Shot Information Extraction via Chatting with ChatGPT》很有趣,该工作将零样本IE任务转变为一个两阶段框架的多轮问答问题(Chat IE),并在三个IE任务中广泛评估了该框架:实体关系三元组抽取、命名实体识别和事件抽取。
方法概览
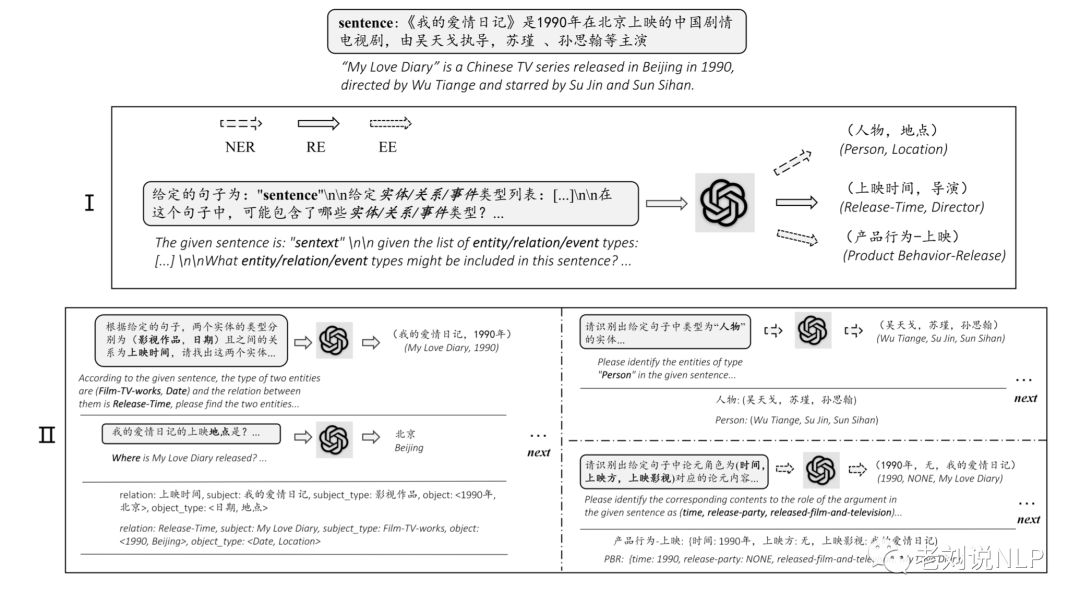
其实现基本原理为,通过制定任务实体关系三元组抽取、命名实体识别和事件抽取,并为每个任务设计了2个步骤的prompt-pattern,第一步用于识别类型,第二步用于识别指定类型的值。将抽取的任务定义(抽取要素)进行prompt填充,然后调用chatgpt接口,在取得结果后进行规则解析,结构化相应答案。
评估
适用于生成大规模信息抽取类指令,对大模型理解文本语义有价值
人工标注指令
https://baijiahao.baidu.com/s?id=1763047882981744476&wfr=spider&for=pc
根据 Databricks 首席执行官 Ali Ghodsi 的说法,虽然已有其他大模型可以用于商业目的,但「它们不会像 Dolly 2.0 那样与你交谈。」而且基于 Dolly 2.0 模型,用户可以修改和改进训练数据,因为它是在开源许可下免费提供的。所以你可以制作你自己的 Dolly 版本。
Databricks 发布了 Dolly 2.0 在其上进行微调的数据集,称为 databricks-dolly-15k。这是由数千名 Databricks 员工生成的超过 1.5 万条记录的语料库,Databricks 称这是「第一个开源的、人工生成的指令语料库,专门设计用于让大型语言能够展示出 ChatGPT 的神奇交互性。」
数据分布如下:
| 类型 | 占比 |
| 开放问答 | 24% |
| 生成问答 | 14.6% |
| 分类 | 14.2% |
| 封闭问答 | 12.1% |
| 头脑风暴 | 11.7% |
| 信息抽取 | 10% |
| 摘要 | 8.4% |
| 改写 | 4.7% |
参考
- 收集了各种场景的模板指令 https://zhuanlan.zhihu.com/p/616393703
- Dolly 2.0人工标注指令 https://baijiahao.baidu.com/s?id=1763047882981744476&wfr=spider&for=pc
- Zero-Shot Information Extraction via Chatting with ChatGPT https://zhuanlan.zhihu.com/p/615093883
- Automatic Prompt Engineer https://m.thepaper.cn/baijiahao_20718621
- 斯坦福Alpaca self-instruct https://www.toutiao.com/article/7210616578801533472/?app=news_article×tamp=1678855351&use_new_style=1&req_id=2023031512423069CE4A3C83F23872EDE2&group_id=7210616578801533472&share_token=2EDD020F-68F0-42EC-BBBA-26BC4E8EAE16&source=m_redirect
- Prompt统一NLP新范式Pre-train, Prompt, and Predict 论文阅读:Prompt统一NLP新范式Pre-train, Prompt, and Predict - 知乎
本文链接:https://my.lmcjl.com/post/9045.html
4 评论