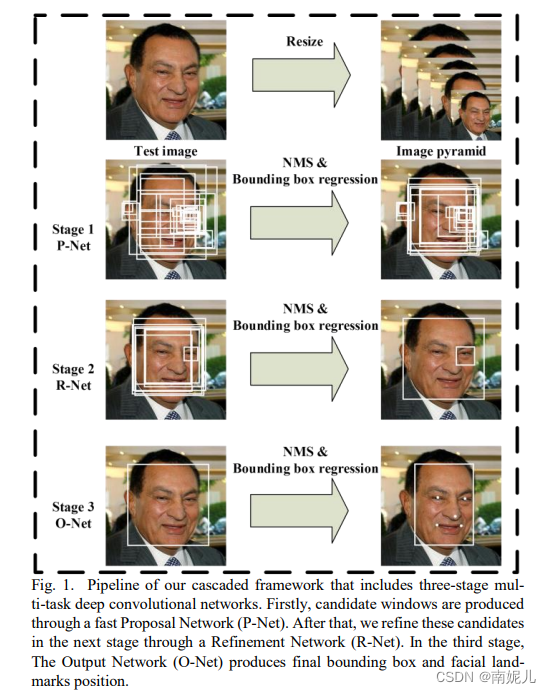
MTCNN 人脸检测
MTCNN,Multi-task convolutional neural network(多任务卷积神经网络),将人脸区域检测与人脸关键点检测放在了一起,它的主题框架类似于cascade。总体可分为P-Net、R-Net、和O-Net三层网络结构。这三个级联的网络分别是快速生成候选窗口的P-Net、进行高精度候选窗口过滤选择的R-Net和生成最终边界框与人脸关键点的O-Net。和很多处理图像问题的卷积神经网络模型,该模型也用到了图像金字塔、边框回归、非最大值抑制等技术。




参考文献
【论文解析】MTCNN论文要点翻译 - 向前奔跑的少年 - 博客园 (cnblogs.com)
Faster RCNN
YOLOV1

yolov1 的处理步骤:首先将图片调整为448,然后输入网络,最后通过置信度进行非极大抑制
检测框架



YOLO将检测问题看作是一个回归问题。YOLO将输入图像分为SxS的网格,如果一个物体的中心点落入网络中,则该网格负责检测该物体。
对于每一个网格会预测B个边界框,每一个边界框包含了5个张量,x,y,w,h,置信度。其中置信度的定义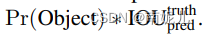
置信度反应了该边界框是否包含物体以及包含物体的可能性。
x,y 是相对于网格左上角归一化后的坐标。
w,h是边界框的宽和高相较于图像宽和高归一化后的结果。
在测试时,将置信度分数和类别分数相乘得到:

这表示 每个边界框的类别概率。注意这里每个网格负责检测一个物体,所以在测试时会选择置信度比较大的边界框进行检测。
网络结构
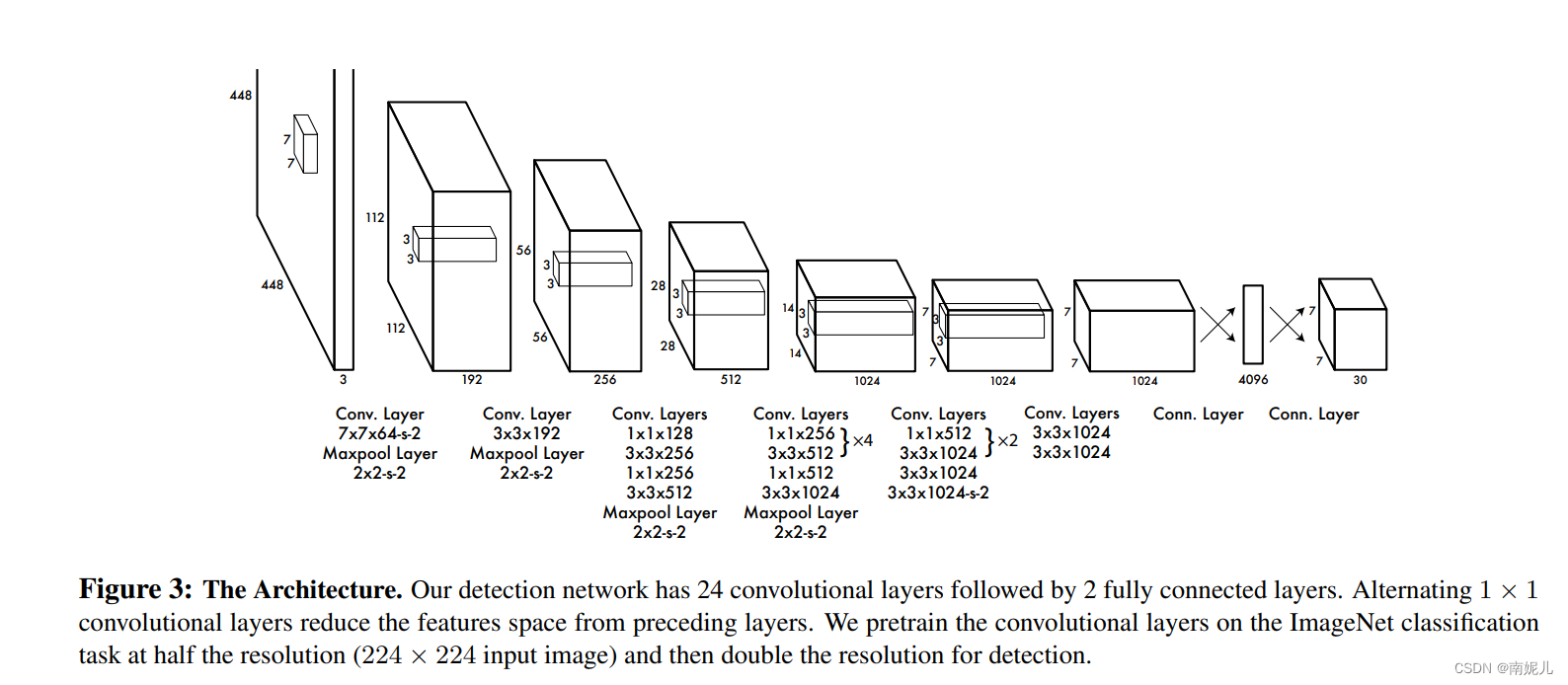
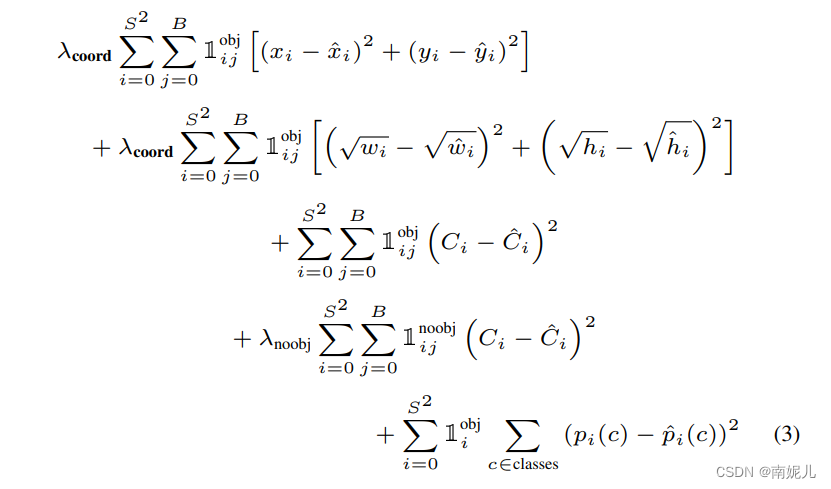

YOLO主要是建立一个CNN网络生成预测7×7×1024 的张量 ,然后通过两个全连接层进行线性回归。
为了优化目标,作者采取了平均差进行优化。但是平方差并不能提高MAP。为了提高定位精度,作者在坐标损失前加入一个参数。有些边界框并不包含物体,所以作者对于不包含物体的边界框赋予更小的权重。对于大框的小偏差和小框的大偏差的重要性是不一样的,所以对于宽和高进行开平方。
代码
从零开始实现yolov1目标检测算法
准备数据
"""
数据准备,将数据处理为两个文件,一个是train.csv,另一个是train.txt。同理也会有test.csv, test.txt
train.csv: 每一行是一张图片的标签,具体储存情况根据不同任务的需求自行设定
train.txt: 每一行是图片的路径,该文件每行的图片和train.csv的每一行标注应该是一一对应的
另外,根据需要将图片稍微离线处理一下,比如将原图片裁剪出训练使用的图片(resize成训练要求大小)后,保存在自定义文件夹中,train.txt里的路径应与自定义文件夹相同
"""
import xml.etree.ElementTree as ET
import numpy as np
import cv2
import random
import osGL_CLASSES = ['person', 'bird', 'cat', 'cow', 'dog', 'horse', 'sheep','aeroplane', 'bicycle', 'boat', 'bus', 'car', 'motorbike', 'train','bottle', 'chair', 'diningtable', 'pottedplant', 'sofa', 'tvmonitor']
GL_NUMBBOX = 2
GL_NUMGRID = 7
STATIC_DATASET_PATH = r'./VOCdevkit/VOC2012/'
STATIC_DEBUG = False # 调试用def convert(size, box):"""将bbox的左上角点、右下角点坐标的格式,转换为bbox中心点+bbox的w,h的格式并进行归一化"""dw = 1. / size[0]dh = 1. / size[1]x = (box[0] + box[1]) / 2.0y = (box[2] + box[3]) / 2.0w = box[1] - box[0]h = box[3] - box[2]x = x * dww = w * dwy = y * dhh = h * dhreturn (x, y, w, h)def convert_annotation(anno_dir, image_id, labels_dir):"""把图像image_id的xml文件转换为目标检测的label文件(txt)其中包含物体的类别,bbox的左上角点坐标以及bbox的宽、高并将四个物理量归一化"""in_file = open(os.path.join(anno_dir, 'Annotations/%s' % (image_id)))image_id = image_id.split('.')[0]tree = ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):difficult = obj.find('difficult').textcls = obj.find('name').textif cls not in GL_CLASSES or int(difficult) == 1:continuecls_id = GL_CLASSES.index(cls)xmlbox = obj.find('bndbox')points = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text))bb = convert((w, h), points)with open(os.path.join(labels_dir, '%s.txt' % (image_id)), 'a') as out_file:out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')def make_label_txt(anno_dir, labels_dir):"""在labels文件夹下创建image_id.txt,对应每个image_id.xml提取出的bbox信息"""filenames = os.listdir(os.path.join(anno_dir,'Annotations'))[:13]for file in filenames:convert_annotation(anno_dir, file, labels_dir)def img_augument(img_dir, save_img_dir, labels_dir):imgs_list = [x.split('.')[0]+".jpg" for x in os.listdir(labels_dir)]for img_name in imgs_list:print("process %s"%os.path.join(img_dir, img_name))img = cv2.imread(os.path.join(img_dir, img_name))h, w = img.shape[0:2]input_size = 448 # 输入YOLOv1网络的图像尺寸为448x448# 因为数据集内原始图像的尺寸是不定的,所以需要进行适当的padding,将原始图像padding成宽高一致的正方形# 然后再将Padding后的正方形图像缩放成448x448padw, padh = 0, 0 # 要记录宽高方向的padding具体数值,因为padding之后需要调整bbox的位置信息if h > w:padw = (h - w) // 2img = np.pad(img, ((0, 0), (padw, padw), (0, 0)), 'constant', constant_values=0)elif w > h:padh = (w - h) // 2img = np.pad(img, ((padh, padh), (0, 0), (0, 0)), 'constant', constant_values=0)img = cv2.resize(img, (input_size, input_size))cv2.imwrite(os.path.join(save_img_dir, img_name), img)# 读取图像对应的bbox信息,按1维的方式储存,每5个元素表示一个bbox的(cls,xc,yc,w,h)with open(os.path.join(labels_dir,img_name.split('.')[0] + ".txt"), 'r') as f:bbox = f.read().split('\n')bbox = [x.split() for x in bbox]bbox = [float(x) for y in bbox for x in y]if len(bbox) % 5 != 0:raise ValueError("File:"+ os.path.join(labels_dir,img_name.split('.')[0] + ".txt") + "——bbox Extraction Error!")# 根据padding、图像增广等操作,将原始的bbox数据转换为修改后图像的bbox数据if padw != 0:for i in range(len(bbox) // 5):bbox[i * 5 + 1] = (bbox[i * 5 + 1] * w + padw) / hbbox[i * 5 + 3] = (bbox[i * 5 + 3] * w) / hif STATIC_DEBUG:cv2.rectangle(img, (int(bbox[1] * input_size - bbox[3] * input_size / 2),int(bbox[2] * input_size - bbox[4] * input_size / 2)),(int(bbox[1] * input_size + bbox[3] * input_size / 2),int(bbox[2] * input_size + bbox[4] * input_size / 2)), (0, 0, 255))elif padh != 0:for i in range(len(bbox) // 5):bbox[i * 5 + 2] = (bbox[i * 5 + 2] * h + padh) / wbbox[i * 5 + 4] = (bbox[i * 5 + 4] * h) / wif STATIC_DEBUG:cv2.rectangle(img, (int(bbox[1] * input_size - bbox[3] * input_size / 2),int(bbox[2] * input_size - bbox[4] * input_size / 2)),(int(bbox[1] * input_size + bbox[3] * input_size / 2),int(bbox[2] * input_size + bbox[4] * input_size / 2)), (0, 0, 255))# 此处可以写代码验证一下,查看padding后修改的bbox数值是否正确,在原图中画出bbox检验if STATIC_DEBUG:cv2.imshow("bbox-%d"%int(bbox[0]), img)cv2.waitKey(0)with open(os.path.join(labels_dir, img_name.split('.')[0] + ".txt"), 'w') as f:for i in range(len(bbox) // 5):bbox = [str(x) for x in bbox[i*5:(i*5+5)]]str_context = " ".join(bbox)+'\n'f.write(str_context)def convert_bbox2labels(bbox):"""将bbox的(cls,x,y,w,h)数据转换为训练时方便计算Loss的数据形式(7,7,5*B+cls_num)注意,输入的bbox的信息是(xc,yc,w,h)格式的,转换为labels后,bbox的信息转换为了(px,py,w,h)格式"""gridsize = 1.0/GL_NUMGRIDlabels = np.zeros((7,7,5*GL_NUMBBOX+len(GL_CLASSES))) # 注意,此处需要根据不同数据集的类别个数进行修改for i in range(len(bbox)//5):gridx = int(bbox[i*5+1] // gridsize) # 当前bbox中心落在第gridx个网格,列gridy = int(bbox[i*5+2] // gridsize) # 当前bbox中心落在第gridy个网格,行# (bbox中心坐标 - 网格左上角点的坐标)/网格大小 ==> bbox中心点的相对位置gridpx = bbox[i * 5 + 1] / gridsize - gridxgridpy = bbox[i * 5 + 2] / gridsize - gridy# 将第gridy行,gridx列的网格设置为负责当前ground truth的预测,置信度和对应类别概率均置为1labels[gridy, gridx, 0:5] = np.array([gridpx, gridpy, bbox[i * 5 + 3], bbox[i * 5 + 4], 1])labels[gridy, gridx, 5:10] = np.array([gridpx, gridpy, bbox[i * 5 + 3], bbox[i * 5 + 4], 1])labels[gridy, gridx, 10+int(bbox[i*5])] = 1labels = labels.reshape(1, -1)return labelsdef create_csv_txt(img_dir, anno_dir, save_root_dir, train_val_ratio=0.9, padding=10, debug=False):"""TODO:将img_dir文件夹内的图片按实际需要处理后,存入save_dir最终得到图片文件夹及所有图片对应的标注(train.csv/test.csv)和图片列表文件(train.txt, test.txt)"""labels_dir = os.path.join(anno_dir, "labels")if not os.path.exists(labels_dir):os.mkdir(labels_dir)make_label_txt(anno_dir, labels_dir)print("labels done.")save_img_dir = os.path.join(os.path.join(anno_dir, "voc2012_forYolov1"), "img")if not os.path.exists(save_img_dir):os.mkdir(save_img_dir)img_augument(img_dir, save_img_dir, labels_dir)imgs_list = os.listdir(save_img_dir)n_trainval = len(imgs_list)shuffle_id = list(range(n_trainval))random.shuffle(shuffle_id)n_train = int(n_trainval*train_val_ratio)train_id = shuffle_id[:n_train]test_id = shuffle_id[n_train:]traintxt = open(os.path.join(save_root_dir, "train.txt"), 'w')traincsv = np.zeros((n_train, GL_NUMGRID*GL_NUMGRID*(5*GL_NUMBBOX+len(GL_CLASSES))),dtype=np.float32)for i,id in enumerate(train_id):img_name = imgs_list[id]img_path = os.path.join(save_img_dir, img_name)+'\n'traintxt.write(img_path)with open(os.path.join(labels_dir,"%s.txt"%img_name.split('.')[0]), 'r') as f:bbox = [float(x) for x in f.read().split()]traincsv[i,:] = convert_bbox2labels(bbox)np.savetxt(os.path.join(save_root_dir, "train.csv"), traincsv)print("Create %d train data." % (n_train))testtxt = open(os.path.join(save_root_dir, "test.txt"), 'w')testcsv = np.zeros((n_trainval - n_train, GL_NUMGRID*GL_NUMGRID*(5*GL_NUMBBOX+len(GL_CLASSES))),dtype=np.float32)for i,id in enumerate(test_id):img_name = imgs_list[id]img_path = os.path.join(save_img_dir, img_name)+'\n'testtxt.write(img_path)with open(os.path.join(labels_dir,"%s.txt"%img_name.split('.')[0]), 'r') as f:bbox = [float(x) for x in f.read().split()]testcsv[i,:] = convert_bbox2labels(bbox)np.savetxt(os.path.join(save_root_dir, "test.csv"), testcsv)print("Create %d test data." % (n_trainval-n_train))if __name__ == '__main__':random.seed(0)np.set_printoptions(threshold=np.inf)img_dir = os.path.join(STATIC_DATASET_PATH, "JPEGImages") # 原始图像文件夹anno_dirs = [STATIC_DATASET_PATH] # 标注文件save_dir = os.path.join(STATIC_DATASET_PATH, "voc2012_forYolov1") # 保存处理后的数据(图片+标签)的文件夹if not os.path.exists(save_dir):os.mkdir(save_dir)# 分别处理for anno_dir in anno_dirs:create_csv_txt(img_dir, anno_dir, save_dir, debug=False)

上面这个函数负责提取xml文件中的边框信息,并且把边框信息归一化,保存为下面的类型。其中第一项表示类别,后面是归一化后的中心的坐标和归一化后的宽和高

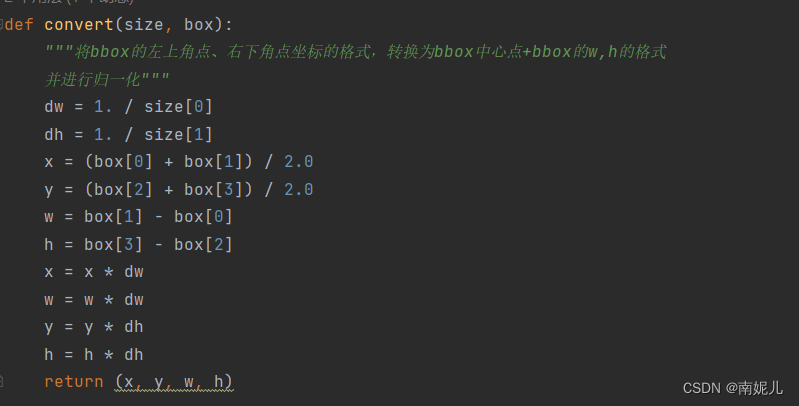
上面这个函数负责将坐标进行归一化。

def convert_bbox2labels(bbox):"""将bbox的(cls,x,y,w,h)数据转换为训练时方便计算Loss的数据形式(7,7,5*B+cls_num)注意,输入的bbox的信息是(xc,yc,w,h)格式的,转换为labels后,bbox的信息转换为了(px,py,w,h)格式"""gridsize = 1.0/GL_NUMGRIDlabels = np.zeros((7,7,5*GL_NUMBBOX+len(GL_CLASSES))) # 注意,此处需要根据不同数据集的类别个数进行修改for i in range(len(bbox)//5):gridx = int(bbox[i*5+1] // gridsize) # 当前bbox中心落在第gridx个网格,列gridy = int(bbox[i*5+2] // gridsize) # 当前bbox中心落在第gridy个网格,行# (bbox中心坐标 - 网格左上角点的坐标)/网格大小 ==> bbox中心点的相对位置gridpx = bbox[i * 5 + 1] / gridsize - gridxgridpy = bbox[i * 5 + 2] / gridsize - gridy# 将第gridy行,gridx列的网格设置为负责当前ground truth的预测,置信度和对应类别概率均置为1labels[gridy, gridx, 0:5] = np.array([gridpx, gridpy, bbox[i * 5 + 3], bbox[i * 5 + 4], 1])labels[gridy, gridx, 5:10] = np.array([gridpx, gridpy, bbox[i * 5 + 3], bbox[i * 5 + 4], 1])labels[gridy, gridx, 10+int(bbox[i*5])] = 1labels = labels.reshape(1, -1)return labels该函数将bbox转换为labels。
data.py
from torch.utils.data import Dataset, DataLoader
import numpy as np
import os
import random
import torch
from PIL import Image
import torchvision.transforms as transformsclass MyDataset(Dataset):def __init__(self, dataset_dir, seed=None, mode="train", train_val_ratio=0.9, trans=None):""":param dataset_dir: 数据所在文件夹:param seed: 打乱数据所用的随机数种子:param mode: 数据模式,"train", "val", "test":param train_val_ratio: 训练时,训练集:验证集的比例:param trans: 数据预处理函数TODO:1. 读取储存图片路径的.txt文件,并保存在self.img_list中2. 读取储存样本标签的.csv文件,并保存在self.label中3. 如果mode="train", 将数据集拆分为训练集和验证集,用self.use_ids来保存对应数据集的样本序号。注意,mode="train"和"val"时,必须传入随机数种子,且两者必须相同4. 保存传入的数据增广函数"""if seed is None:seed = random.randint(0, 65536)random.seed(seed)self.dataset_dir = dataset_dirself.mode = modeif mode=="val":mode = "train"img_list_txt = os.path.join(dataset_dir, mode+".txt").replace('\\','/') # 储存图片位置的列表label_csv = os.path.join(dataset_dir, mode+".csv").replace('\\','/') # 储存标签的数组文件self.img_list = []self.label = np.loadtxt(label_csv) # 读取标签数组文件# 读取图片位置文件with open(img_list_txt, 'r') as f:for line in f.readlines():self.img_list.append(line.strip())# 在mode=train或val时, 将数据进行切分# 注意在mode="val"时,传入的随机种子seed要和mode="train"相同self.num_all_data = len(self.img_list)all_ids = list(range(self.num_all_data))num_train = int(train_val_ratio*self.num_all_data)if self.mode == "train":self.use_ids = all_ids[:num_train]elif self.mode == "val":self.use_ids = all_ids[num_train:]else:self.use_ids = all_ids# 储存数据增广函数self.trans = transdef __len__(self):"""获取数据集数量"""return len(self.use_ids)def __getitem__(self, item):"""TODO:1. 按顺序依次取出第item个训练数据img及其对应的样本标签label2. 图像数据要进行预处理,并最终转换为(c, h, w)的维度,同时转换为torch.tensor3. 样本标签要按需要转换为指定格式的torch.tensor"""id = self.use_ids[item]label = torch.tensor(self.label[id, :])img_path = self.img_list[id]img = Image.open(img_path)if self.trans is None:trans = transforms.Compose([# transforms.Resize((112,112)),transforms.ToTensor(),])else:trans = self.transimg = trans(img) # 图像预处理&数据增广# transforms.ToPILImage()(img).show() # for debug# print(label)return img, labelif __name__ == '__main__':# 调试用,依次取出数据看看是否正确dataset_dir = "./VOCdevkit/VOC2012/voc2012_forYolov1"dataset = MyDataset(dataset_dir)image,label=dataset[1]print(image.shape)print(label.shape)# dataloader = DataLoader(dataset, 1)# for i in enumerate(dataloader):# input("press enter to continue")model.py
import torch
import torch.nn as nn
import torchvision.models as tvmodel
from prepare_data import GL_CLASSES, GL_NUMBBOX, GL_NUMGRID
from util import calculate_iouclass MyNet(nn.Module):"""@ 网络实际名称为了和后续接口对齐,此处类名固定为MyNet,具体是什么网络可以写在注释里。"""def __init__(self):""":param args: 构建网络所需要的参数TODO:在__init__()函数里,将网络框架搭好,并存在self里"""super(MyNet, self).__init__()resnet = tvmodel.resnet34(pretrained=True) # 调用torchvision里的resnet34预训练模型resnet_out_channel = resnet.fc.in_features # 记录resnet全连接层之前的网络输出通道数,方便连入后续卷积网络中self.resnet = nn.Sequential(*list(resnet.children())[:-2]) # 去除resnet的最后两层# 以下是YOLOv1的最后四个卷积层self.Conv_layers = nn.Sequential(nn.Conv2d(resnet_out_channel, 1024, 3, padding=1),nn.BatchNorm2d(1024), # 为了加快训练,这里增加了BN层,原论文里YOLOv1是没有的nn.LeakyReLU(inplace=True),nn.Conv2d(1024, 1024, 3, stride=2, padding=1),nn.BatchNorm2d(1024),nn.LeakyReLU(inplace=True),nn.Conv2d(1024, 1024, 3, padding=1),nn.BatchNorm2d(1024),nn.LeakyReLU(inplace=True),nn.Conv2d(1024, 1024, 3, padding=1),nn.BatchNorm2d(1024),nn.LeakyReLU(inplace=True),)# 以下是YOLOv1的最后2个全连接层self.Conn_layers = nn.Sequential(nn.Linear(GL_NUMGRID * GL_NUMGRID * 1024, 4096),nn.LeakyReLU(inplace=True),nn.Linear(4096, GL_NUMGRID * GL_NUMGRID * (5*GL_NUMBBOX+len(GL_CLASSES))),nn.Sigmoid() # 增加sigmoid函数是为了将输出全部映射到(0,1)之间,因为如果出现负数或太大的数,后续计算loss会很麻烦)def forward(self, inputs):""":param inputs: 输入网络的张量:return: 输出网络的结果TODO根据网络的结构,完成网络的前向传播计算。如果网络有多条分支,可以用self储存需要在别的地方使用的中间张量。如果网络有多个输出,需要将多个输出按后续inference的需求打包输出"""x = self.resnet(inputs)x = self.Conv_layers(x)x = x.view(x.size()[0], -1)x = self.Conn_layers(x)self.pred = x.reshape(-1, (5 * GL_NUMBBOX + len(GL_CLASSES)), GL_NUMGRID, GL_NUMGRID) # 记住最后要reshape一下输出数据return self.preddef calculate_loss(self, labels):"""TODO: 根据labels和self.outputs计算训练loss:param labels: (bs, n), 对应训练数据的样本标签:return: loss数值"""self.pred = self.pred.double()labels = labels.double()num_gridx, num_gridy = GL_NUMGRID, GL_NUMGRID # 划分网格数量noobj_confi_loss = 0. # 不含目标的网格损失(只有置信度损失)coor_loss = 0. # 含有目标的bbox的坐标损失obj_confi_loss = 0. # 含有目标的bbox的置信度损失class_loss = 0. # 含有目标的网格的类别损失n_batch = labels.size()[0] # batchsize的大小# 可以考虑用矩阵运算进行优化,提高速度,为了准确起见,这里还是用循环for i in range(n_batch): # batchsize循环for n in range(num_gridx): # x方向网格循环for m in range(num_gridy): # y方向网格循环if labels[i, 4, m, n] == 1: # 如果包含物体# 将数据(px,py,w,h)转换为(x1,y1,x2,y2)# 先将px,py转换为cx,cy,即相对网格的位置转换为标准化后实际的bbox中心位置cx,xy# 然后再利用(cx-w/2,cy-h/2,cx+w/2,cy+h/2)转换为xyxy形式,用于计算ioubbox1_pred_xyxy = ((self.pred[i, 0, m, n] + n) / num_gridx - self.pred[i, 2, m, n] / 2,(self.pred[i, 1, m, n] + m) / num_gridy - self.pred[i, 3, m, n] / 2,(self.pred[i, 0, m, n] + n) / num_gridx + self.pred[i, 2, m, n] / 2,(self.pred[i, 1, m, n] + m) / num_gridy + self.pred[i, 3, m, n] / 2)bbox2_pred_xyxy = ((self.pred[i, 5, m, n] + n) / num_gridx - self.pred[i, 7, m, n] / 2,(self.pred[i, 6, m, n] + m) / num_gridy - self.pred[i, 8, m, n] / 2,(self.pred[i, 5, m, n] + n) / num_gridx + self.pred[i, 7, m, n] / 2,(self.pred[i, 6, m, n] + m) / num_gridy + self.pred[i, 8, m, n] / 2)bbox_gt_xyxy = ((labels[i, 0, m, n] + n) / num_gridx - labels[i, 2, m, n] / 2,(labels[i, 1, m, n] + m) / num_gridy - labels[i, 3, m, n] / 2,(labels[i, 0, m, n] + n) / num_gridx + labels[i, 2, m, n] / 2,(labels[i, 1, m, n] + m) / num_gridy + labels[i, 3, m, n] / 2)iou1 = calculate_iou(bbox1_pred_xyxy, bbox_gt_xyxy)iou2 = calculate_iou(bbox2_pred_xyxy, bbox_gt_xyxy)# 选择iou大的bbox作为负责物体if iou1 >= iou2:coor_loss = coor_loss + 5 * (torch.sum((self.pred[i, 0:2, m, n] - labels[i, 0:2, m, n]) ** 2) \+ torch.sum((self.pred[i, 2:4, m, n].sqrt() - labels[i, 2:4, m, n].sqrt()) ** 2))obj_confi_loss = obj_confi_loss + (self.pred[i, 4, m, n] - iou1) ** 2# iou比较小的bbox不负责预测物体,因此confidence loss算在noobj中,注意,对于标签的置信度应该是iou2noobj_confi_loss = noobj_confi_loss + 0.5 * ((self.pred[i, 9, m, n] - iou2) ** 2)else:coor_loss = coor_loss + 5 * (torch.sum((self.pred[i, 5:7, m, n] - labels[i, 5:7, m, n]) ** 2) \+ torch.sum((self.pred[i, 7:9, m, n].sqrt() - labels[i, 7:9, m, n].sqrt()) ** 2))obj_confi_loss = obj_confi_loss + (self.pred[i, 9, m, n] - iou2) ** 2# iou比较小的bbox不负责预测物体,因此confidence loss算在noobj中,注意,对于标签的置信度应该是iou1noobj_confi_loss = noobj_confi_loss + 0.5 * ((self.pred[i, 4, m, n] - iou1) ** 2)class_loss = class_loss + torch.sum((self.pred[i, 10:, m, n] - labels[i, 10:, m, n]) ** 2)else: # 如果不包含物体noobj_confi_loss = noobj_confi_loss + 0.5 * torch.sum(self.pred[i, [4, 9], m, n] ** 2)loss = coor_loss + obj_confi_loss + noobj_confi_loss + class_loss# 此处可以写代码验证一下loss的大致计算是否正确,这个要验证起来比较麻烦,比较简洁的办法是,将输入的pred置为全1矩阵,再进行误差检查,会直观很多。return loss / n_batchdef calculate_metric(self, preds, labels):"""TODO: 根据preds和labels,以及指定的评价方法计算网络效果得分, 网络validation时使用:param preds: 预测数据:param labels: 预测数据对应的样本标签:return: 评估得分metric"""preds = preds.double()labels = labels[:, :(self.n_points*2)]l2_distance = torch.mean(torch.sum((preds-labels)**2, dim=1))return l2_distanceif __name__ == '__main__':# 自定义输入张量,验证网络可以正常跑通,并计算loss,调试用x = torch.zeros(5,3,448,448)net = MyNet()a = net(x)labels = torch.zeros(5, 30, 7, 7)loss = net.calculate_loss(labels)print(loss)print(a.shape)
train.py
import os
import datetime
import time
import torch
from torch.utils.data import DataLoaderfrom model import MyNet
from data import MyDataset
from my_arguments import Args
from prepare_data import GL_CLASSES, GL_NUMBBOX, GL_NUMGRID
from util import labels2bboxclass TrainInterface(object):"""网络训练接口,__train(): 训练过程函数__validate(): 验证过程函数__save_model(): 保存模型函数main(): 训练网络主函数"""def __init__(self, opts):""":param opts: 命令行参数"""self.opts = optsprint("=======================Start training.=======================")@staticmethoddef __train(model, train_loader, optimizer, epoch, num_train, opts):"""完成一个epoch的训练:param model: torch.nn.Module, 需要训练的网络:param train_loader: torch.utils.data.Dataset, 训练数据集对应的类:param optimizer: torch.optim.Optimizer, 优化网络参数的优化器:param epoch: int, 表明当前训练的是第几个epoch:param num_train: int, 训练集数量:param opts: 命令行参数"""model.train()device = opts.GPU_idavg_metric = 0. # 平均评价指标avg_loss = 0. # 平均损失数值# log_file是保存网络训练过程信息的文件,网络训练信息会以追加的形式打印在log.txt里,不会覆盖原有log文件log_file = open(os.path.join(opts.checkpoints_dir, "log.txt"), "a+")localtime = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S") # 打印训练时间log_file.write(localtime)log_file.write("\n======================training epoch %d======================\n"%epoch)for i,(imgs, labels) in enumerate(train_loader):labels = labels.view(1, GL_NUMGRID, GL_NUMGRID, 30)labels = labels.permute(0,3,1,2)if opts.use_GPU:imgs = imgs.to(device)labels = labels.to(device)preds = model(imgs) # 前向传播loss = model.calculate_loss(labels) # 计算损失optimizer.zero_grad() # 梯度清零loss.backward() # 反向传播optimizer.step() # 优化网络参数# metric = model.calculate_metric(preds, labels) # 计算评价指标# avg_metric = (avg_metric*i+metric)/(i+1)avg_loss = (avg_loss*i+loss.item())/(i+1)if i % opts.print_freq == 0: # 根据打印频率输出log信息和训练信息print("Epoch %d/%d | Iter %d/%d | training loss = %.3f, avg_loss = %.3f" %(epoch, opts.epoch, i, num_train//opts.batch_size, loss.item(), avg_loss))log_file.write("Epoch %d/%d | Iter %d/%d | training loss = %.3f, avg_loss = %.3f\n" %(epoch, opts.epoch, i, num_train//opts.batch_size, loss.item(), avg_loss))log_file.flush()log_file.close()@staticmethoddef __validate(model, val_loader, epoch, num_val, opts):"""完成一个epoch训练后的验证任务:param model: torch.nn.Module, 需要训练的网络:param _loader: torch.utils.data.Dataset, 验证数据集对应的类:param epoch: int, 表明当前训练的是第几个epoch:param num_val: int, 验证集数量:param opts: 命令行参数"""model.eval()log_file = open(os.path.join(opts.checkpoints_dir, "log.txt"), "a+")log_file.write("======================validate epoch %d======================\n"%epoch)preds = Nonegts = Noneavg_metric = 0.with torch.no_grad(): # 加上这个可以减少在validation过程时的显存占用,提高代码的显存利用率for i,(imgs, labels) in enumerate(val_loader):if opts.use_GPU:imgs = imgs.to(opts.GPU_id)pred = model(imgs).cpu().squeeze(dim=0).permute(1,2,0)pred_bbox = labels2bbox(pred) # 将网络输出经过NMS后转换为shape为(-1, 6)的bboxmetric = model.calculate_metric(preds, gts)print("Evaluation of validation result: average L2 distance = %.5f"%(metric))log_file.write("Evaluation of validation result: average L2 distance = %.5f\n"%(metric))log_file.flush()log_file.close()return metric@staticmethoddef __save_model(model, epoch, opts):"""保存第epoch个网络的参数:param model: torch.nn.Module, 需要训练的网络:param epoch: int, 表明当前训练的是第几个epoch:param opts: 命令行参数"""model_name = "epoch%d.pth" % epochsave_dir = os.path.join(opts.checkpoints_dir, model_name)torch.save(model, save_dir)def main(self):"""训练接口主函数,完成整个训练流程1. 创建训练集和验证集的DataLoader类2. 初始化带训练的网络3. 选择合适的优化器4. 训练并验证指定个epoch,保存其中评价指标最好的模型,并打印训练过程信息5. TODO: 可视化训练过程信息"""opts = self.optsif not os.path.exists(opts.checkpoints_dir):os.mkdir(opts.checkpoints_dir)random_seed = opts.random_seedtrain_dataset = MyDataset(opts.dataset_dir, seed=random_seed, mode="train", train_val_ratio=0.9)val_dataset = MyDataset(opts.dataset_dir, seed=random_seed, mode="val", train_val_ratio=0.9)train_loader = DataLoader(train_dataset, opts.batch_size, shuffle=True, num_workers=opts.num_workers)val_loader = DataLoader(val_dataset, batch_size=1, shuffle=False, num_workers=opts.num_workers)num_train = len(train_dataset)num_val = len(val_dataset)if opts.pretrain is None:model = MyNet()else:model = torch.load(opts.pretrain)if opts.use_GPU:model.to(opts.GPU_id)optimizer = torch.optim.SGD(model.parameters(), lr=opts.lr, momentum=0.9, weight_decay=opts.weight_decay)# optimizer = torch.optim.Adam(model.parameters(), lr=opts.lr, weight_decay=opts.weight_decay)best_metric=1000000for e in range(opts.start_epoch, opts.epoch+1):t = time.time()self.__train(model, train_loader, optimizer, e, num_train, opts)t2 = time.time()print("Training consumes %.2f second\n" % (t2-t))with open(os.path.join(opts.checkpoints_dir, "log.txt"), "a+") as log_file:log_file.write("Training consumes %.2f second\n" % (t2-t))if e % opts.save_freq==0 or e == opts.epoch+1:# t = time.time()# metric = self.__validate(model, val_loader, e, num_val, opts)# t2 = time.time()# print("Validation consumes %.2f second\n" % (t2 - t))# with open(os.path.join(opts.checkpoints_dir, "log.txt"), "a+") as log_file:# log_file.write("Validation consumes %.2f second\n" % (t2 - t))# if best_metric>metric:# best_metric = metric# print("Epoch %d is now the best epoch with metric %.4f\n"%(e, best_metric))# with open(os.path.join(opts.checkpoints_dir, "log.txt"), "a+") as log_file:# log_file.write("Epoch %d is now the best epoch with metric %.4f\n"%(e, best_metric))self.__save_model(model, e, opts)if __name__ == '__main__':# 训练网络代码args = Args()args.set_train_args() # 获取命令行参数train_interface = TrainInterface(args.get_opts())train_interface.main() # 调用训练接口
utils.py
import torch
import torch.nn as nn
import numpy as npclass DepthwiseConv(nn.Module):"""深度可分离卷积层"""def __init__(self, in_channels, out_channels, kernel_size, stride, padding=0, bias=True):super(DepthwiseConv, self).__init__()self.layers = nn.Sequential(nn.Conv2d(in_channels=in_channels, out_channels=in_channels, kernel_size=kernel_size, stride=stride,padding=padding, groups=in_channels, bias=bias),nn.BatchNorm2d(num_features=in_channels),nn.ReLU(),nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, bias=bias),nn.BatchNorm2d(num_features=out_channels),nn.ReLU())def forward(self, inputs):outputs = self.layers(inputs)return outputsclass InvertedBottleneck(nn.Module):"""MobileNet v2 的InvertedBottleneck"""def __init__(self, in_channels, out_channels, kernel_size, stride, t_factor, padding=0, bias=True):super(InvertedBottleneck, self).__init__()mid_channels = t_factor*in_channelsself.layers = nn.Sequential(nn.Conv2d(in_channels=in_channels, out_channels=mid_channels, kernel_size=1, bias=bias),nn.BatchNorm2d(num_features=mid_channels),nn.ReLU(),nn.Conv2d(in_channels=mid_channels, out_channels=mid_channels, kernel_size=kernel_size, stride=stride,padding=padding, bias=bias),nn.BatchNorm2d(num_features=mid_channels),nn.ReLU(),nn.Conv2d(in_channels=mid_channels, out_channels=out_channels, kernel_size=1, bias=bias))def forward(self, inputs):outputs = self.layers(inputs)return outputsclass Flatten(nn.Module):"""将三维张量拉平的网络层(n,c,h,w) -> (n, c*h*w)"""def __init__(self):super(Flatten, self).__init__()def forward(self, x):n_samples = x.shape[0]x = x.reshape(n_samples, -1)return xdef calculate_iou(bbox1, bbox2):"""计算bbox1=(x1,y1,x2,y2)和bbox2=(x3,y3,x4,y4)两个bbox的iou"""if bbox1[2]<=bbox1[0] or bbox1[3]<=bbox1[1] or bbox2[2]<=bbox2[0] or bbox2[3]<=bbox2[1]:return 0 # 如果bbox1或bbox2没有面积,或者输入错误,直接返回0intersect_bbox = [0., 0., 0., 0.] # bbox1和bbox2的重合区域的(x1,y1,x2,y2)intersect_bbox[0] = max(bbox1[0],bbox2[0])intersect_bbox[1] = max(bbox1[1],bbox2[1])intersect_bbox[2] = min(bbox1[2],bbox2[2])intersect_bbox[3] = min(bbox1[3],bbox2[3])w = max(intersect_bbox[2] - intersect_bbox[0], 0)h = max(intersect_bbox[3] - intersect_bbox[1], 0)area1 = (bbox1[2] - bbox1[0]) * (bbox1[3] - bbox1[1]) # bbox1面积area2 = (bbox2[2] - bbox2[0]) * (bbox2[3] - bbox2[1]) # bbox2面积area_intersect = w * h # 交集面积iou = area_intersect / (area1 + area2 - area_intersect + 1e-6) # 防止除0# print(bbox1,bbox2)# print(intersect_bbox)# input()return iou# 注意检查一下输入数据的格式,到底是xywh还是xyxy
def labels2bbox(matrix):"""将网络输出的7*7*30的数据转换为bbox的(98,25)的格式,然后再将NMS处理后的结果返回:param matrix: 注意,输入的数据中,bbox坐标的格式是(px,py,w,h),需要转换为(x1,y1,x2,y2)的格式再输入NMS:return: 返回NMS处理后的结果,bboxes.shape = (-1, 6), 0:4是(x1,y1,x2,y2), 4是conf, 5是cls"""if matrix.size()[0:2]!=(7,7):raise ValueError("Error: Wrong labels size: ", matrix.size(), " != (7,7)")matrix = matrix.numpy()bboxes = np.zeros((98, 6))# 先把7*7*30的数据转变为bbox的(98,25)的格式,其中,bbox信息格式从(px,py,w,h)转换为(x1,y1,x2,y2),方便计算ioumatrix = matrix.reshape(49,-1)bbox = matrix[:, :10].reshape(98, 5)r_grid = np.array(list(range(7)))r_grid = np.repeat(r_grid, repeats=14, axis=0) # [0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 ...]c_grid = np.array(list(range(7)))c_grid = np.repeat(c_grid, repeats=2, axis=0)[np.newaxis, :]c_grid = np.repeat(c_grid, repeats=7, axis=0).reshape(-1) # [0 0 1 1 2 2 3 3 4 4 5 5 6 6 0 0 1 1 2 2 3 3 4 4 5 5 6 6...]bboxes[:, 0] = np.maximum((bbox[:, 0] + c_grid) / 7.0 - bbox[:, 2] / 2.0, 0)bboxes[:, 1] = np.maximum((bbox[:, 1] + r_grid) / 7.0 - bbox[:, 3] / 2.0, 0)bboxes[:, 2] = np.minimum((bbox[:, 0] + c_grid) / 7.0 + bbox[:, 2] / 2.0, 1)bboxes[:, 3] = np.minimum((bbox[:, 1] + r_grid) / 7.0 + bbox[:, 3] / 2.0, 1)bboxes[:, 4] = bbox[:, 4]cls = np.argmax(matrix[:, 10:], axis=1)cls = np.repeat(cls, repeats=2, axis=0)bboxes[:, 5] = cls# 对所有98个bbox执行NMS算法,清理cls-specific confidence score较低以及iou重合度过高的bboxkeepid = nms_multi_cls(bboxes, thresh=0.1, n_cls=20)ids = []for x in keepid:ids = ids + list(x)ids = sorted(ids)return bboxes[ids, :]def nms_1cls(dets, thresh):"""单类别NMS:param dets: ndarray,nx5,dets[i,0:4]分别是bbox坐标;dets[i,4]是置信度score:param thresh: NMS算法设置的iou阈值"""# 从检测结果dets中获得x1,y1,x2,y2和scores的值x1 = dets[:, 0]y1 = dets[:, 1]x2 = dets[:, 2]y2 = dets[:, 3]scores = dets[:, 4]# 计算每个检测框的面积areas = (x2 - x1 + 1) * (y2 - y1 + 1)# 按照置信度score的值降序排序的下标序列order = scores.argsort()[::-1]# keep用来保存最后保留的检测框的下标keep = []while order.size > 0:# 当前置信度最高bbox的indexi = order[0]# 添加当前剩余检测框中得分最高的index到keep中keep.append(i)# 得到此bbox和剩余其他bbox的相交区域,左上角和右下角xx1 = np.maximum(x1[i], x1[order[1:]])yy1 = np.maximum(y1[i], y1[order[1:]])xx2 = np.minimum(x2[i], x2[order[1:]])yy2 = np.minimum(y2[i], y2[order[1:]])# 计算相交的面积,不重叠时面积为0w = np.maximum(0.0, xx2 - xx1 + 1)h = np.maximum(0.0, yy2 - yy1 + 1)inter = w * h# 计算IoU:重叠面积/(面积1+面积2-重叠面积)iou = inter / (areas[i] + areas[order[1:]] - inter)# 保留IoU小于阈值的bboxinds = np.where(iou <= thresh)[0]order = order[inds+1]return keepdef nms_multi_cls(dets, thresh, n_cls):"""多类别的NMS算法:param dets:ndarray,nx6,dets[i,0:4]是bbox坐标;dets[i,4]是置信度score;dets[i,5]是类别序号;:param thresh: NMS算法的阈值;:param n_cls: 是类别总数"""# 储存结果的列表,keeps_index[i]表示第i类保留下来的bbox下标listkeeps_index = []for i in range(n_cls):order_i = np.where(dets[:,5]==i)[0]det = dets[dets[:, 5] == i, 0:5]if det.shape[0] == 0:keeps_index.append([])continuekeep = nms_1cls(det, thresh)keeps_index.append(order_i[keep])return keeps_indexif __name__ == '__main__':a = torch.randn((7,7,30))print(a)labels2bbox(a)
该函数首先将labels转换为(98,6)格式,其中前四个表示坐标,第五个表示置信度,第六个表示类别。然后执行NMS算法去掉重叠较高的边界框。
test.py
import os
from my_arguments import Args
import torch
from torch.utils.data import DataLoaderfrom model import MyNet
from data import MyDataset
from util import labels2bbox
from prepare_data import GL_CLASSES
import torchvision.transforms as transforms
from PIL import Image
import cv2COLOR = [(255,0,0),(255,125,0),(255,255,0),(255,0,125),(255,0,250),(255,125,125),(255,125,250),(125,125,0),(0,255,125),(255,0,0),(0,0,255),(125,0,255),(0,125,255),(0,255,255),(125,125,255),(0,255,0),(125,255,125),(255,255,255),(100,100,100),(0,0,0),] # 用来标识20个类别的bbox颜色,可自行设定class TestInterface(object):"""网络测试接口,main(): 网络测试主函数"""def __init__(self, opts):self.opts = optsprint("=======================Start inferring.=======================")def main(self):"""具体测试流程根据不同项目有较大区别,需要自行编写代码,主要流程如下:1. 获取命令行参数2. 获取测试集3. 加载网络模型4. 用网络模型对测试集进行测试,得到测试结果5. 根据不同项目,计算测试集的评价指标, 或者可视化测试结果"""opts = self.optsimg_list = os.listdir(opts.dataset_dir)trans = transforms.Compose([# transforms.Resize((112, 112)),transforms.ToTensor(),])model = torch.load(opts.weight_path)if opts.use_GPU:model.to(opts.GPU_id)for img_name in img_list:img_path = os.path.join(opts.dataset_dir, img_name)img = Image.open(img_path).convert('RGB')img = trans(img)img = torch.unsqueeze(img, dim=0)print(img_name, img.shape)if opts.use_GPU:img = img.to(opts.GPU_id)preds = torch.squeeze(model(img), dim=0).detach().cpu()preds = preds.permute(1,2,0)bbox = labels2bbox(preds)draw_img = cv2.imread(img_path)self.draw_bbox(draw_img, bbox)def draw_bbox(self, img, bbox):"""根据bbox的信息在图像上绘制bounding box:param img: 绘制bbox的图像:param bbox: 是(n,6)的尺寸,0:4是(x1,y1,x2,y2), 4是conf, 5是cls"""h, w = img.shape[0:2]n = bbox.shape[0]for i in range(n):confidence = bbox[i, 4]if confidence<0.2:continuep1 = (int(w * bbox[i, 0]), int(h * bbox[i, 1]))p2 = (int(w * bbox[i, 2]), int(h * bbox[i, 3]))cls_name = GL_CLASSES[int(bbox[i, 5])]print(cls_name, p1, p2)cv2.rectangle(img, p1, p2, COLOR[int(bbox[i, 5])])cv2.putText(img, cls_name, p1, cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255))cv2.putText(img, str(confidence), (p1[0],p1[1]-10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255))cv2.imshow("bbox", img)cv2.waitKey(0)if __name__ == '__main__':# 网络测试代码args = Args()args.set_test_args() # 获取命令行参数test_interface = TestInterface(args.get_opts())test_interface.main() # 调用测试接口参考文献:
睿智的目标检测5——yolo1、yolo2、yolo3和SSD的网络结构汇总对比_睿智的网络csdn_Bubbliiiing的博客-CSDN博客
【YOLO系列】YOLOv1论文超详细解读(翻译 +学习笔记)_路人贾'ω'的博客-CSDN博客
YOLOV2

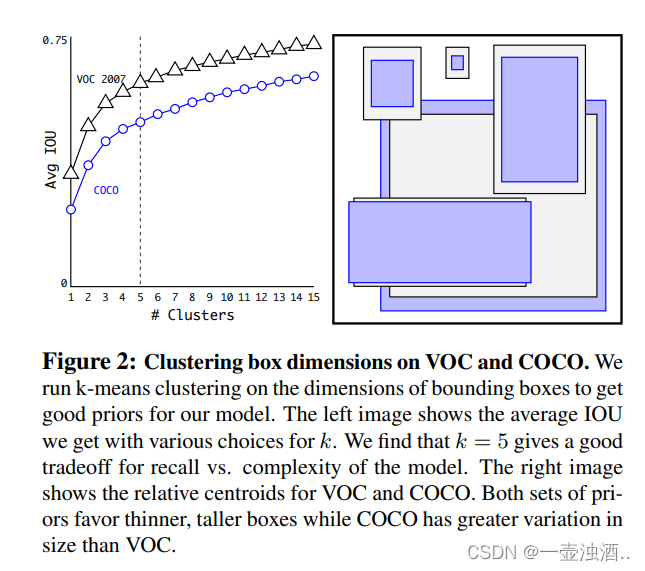
使用Kmean聚类来自动找到更好的boxes。

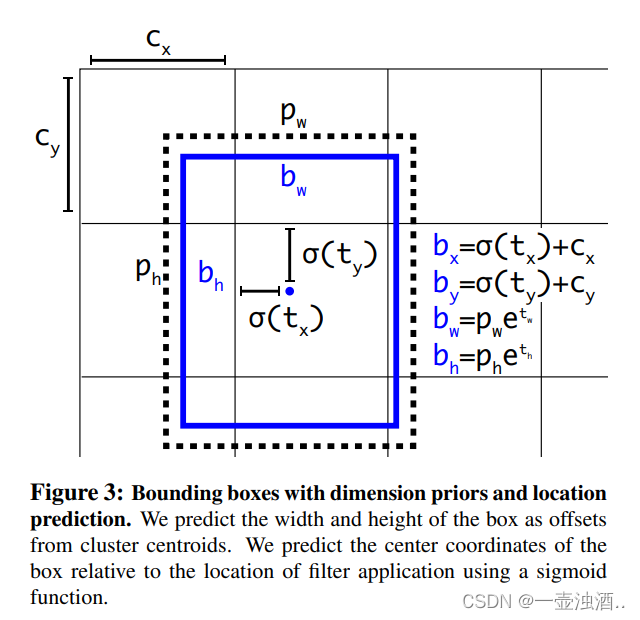
代码
voc0712.py
读取voc图片和注释,其中注释的格式是(x,y,w,h,cls)
"""VOC Dataset ClassesOriginal author: Francisco Massa
https://github.com/fmassa/vision/blob/voc_dataset/torchvision/datasets/voc.pyUpdated by: Ellis Brown, Max deGroot
"""
import os
import os.path as osp
import sys
import torch
import torch.utils.data as data
import cv2
import numpy as np
import random
import xml.etree.ElementTree as ETVOC_CLASSES = ( # always index 0'aeroplane', 'bicycle', 'bird', 'boat','bottle', 'bus', 'car', 'cat', 'chair','cow', 'diningtable', 'dog', 'horse','motorbike', 'person', 'pottedplant','sheep', 'sofa', 'train', 'tvmonitor')class VOCAnnotationTransform(object):"""Transforms a VOC annotation into a Tensor of bbox coords and label indexInitilized with a dictionary lookup of classnames to indexesArguments:class_to_ind (dict, optional): dictionary lookup of classnames -> indexes(default: alphabetic indexing of VOC's 20 classes)keep_difficult (bool, optional): keep difficult instances or not(default: False)height (int): heightwidth (int): width"""def __init__(self, class_to_ind=None, keep_difficult=False):self.class_to_ind = class_to_ind or dict(zip(VOC_CLASSES, range(len(VOC_CLASSES))))self.keep_difficult = keep_difficultdef __call__(self, target, width, height):"""Arguments:target (annotation) : the target annotation to be made usablewill be an ET.ElementReturns:a list containing lists of bounding boxes [bbox coords, class name]"""res = []for obj in target.iter('object'):difficult = int(obj.find('difficult').text) == 1if not self.keep_difficult and difficult:continuename = obj.find('name').text.lower().strip()bbox = obj.find('bndbox')pts = ['xmin', 'ymin', 'xmax', 'ymax']bndbox = []for i, pt in enumerate(pts):cur_pt = int(bbox.find(pt).text) - 1# scale height or widthcur_pt = cur_pt / width if i % 2 == 0 else cur_pt / heightbndbox.append(cur_pt)label_idx = self.class_to_ind[name]bndbox.append(label_idx)res += [bndbox] # [xmin, ymin, xmax, ymax, label_ind]# img_id = target.find('filename').text[:-4]return res # [[xmin, ymin, xmax, ymax, label_ind], ... ]class VOCDetection(data.Dataset):"""VOC Detection Dataset Objectinput is image, target is annotationArguments:root (string): filepath to VOCdevkit folder.image_set (string): imageset to use (eg. 'train', 'val', 'test')transform (callable, optional): transformation to perform on theinput imagetarget_transform (callable, optional): transformation to perform on thetarget `annotation`(eg: take in caption string, return tensor of word indices)dataset_name (string, optional): which dataset to load(default: 'VOC2007')"""def __init__(self, data_dir=None,image_sets=[('2007', 'trainval')],transform=None, target_transform=VOCAnnotationTransform(),dataset_name='VOC0712'):self.root = data_dirself.image_set = image_setsself.transform = transformself.target_transform = target_transformself.name = dataset_nameself.annopath = osp.join('%s', 'Annotations', '%s.xml')self.imgpath = osp.join('%s', 'JPEGImages', '%s.jpg')self.ids = list()for (year, name) in image_sets:rootpath = osp.join(self.root, 'VOC' + year)for line in os.listdir(os.path.join(rootpath,'JPEGImages')):line=line.split('.')[0]self.ids.append((rootpath,line))# for line in open(osp.join(rootpath, 'ImageSets', 'Main', name + '.txt')):# self.ids.append((rootpath, line.strip()))def __getitem__(self, index):index=index%len(self.ids)im, gt, h, w = self.pull_item(index)return im, gtdef __len__(self):return len(self.ids)def pull_item(self, index):# load an imageindex=index%len(self.ids)img_id = self.ids[index]img = cv2.imread(self.imgpath % img_id)height, width, channels = img.shape# load a targettarget = ET.parse(self.annopath % img_id).getroot()if self.target_transform is not None:target = self.target_transform(target, width, height)# check targetif len(target) == 0:target = np.zeros([1, 5])else:target = np.array(target)# transformif self.transform is not None:img, boxes, labels = self.transform(img, target[:, :4], target[:, 4])# to rgbimg = img[:, :, (2, 1, 0)]# to tensorimg = torch.from_numpy(img).permute(2, 0, 1).float()# targettarget = np.hstack((boxes, np.expand_dims(labels, axis=1)))return img, target, height, widthdef pull_image(self, index):'''Returns the original image object at index in PIL formNote: not using self.__getitem__(), as any transformations passed incould mess up this functionality.Argument:index (int): index of img to showReturn:PIL img'''img_id = self.ids[index]return cv2.imread(self.imgpath % img_id, cv2.IMREAD_COLOR), img_iddef pull_anno(self, index):'''Returns the original annotation of image at indexNote: not using self.__getitem__(), as any transformations passed incould mess up this functionality.Argument:index (int): index of img to get annotation ofReturn:list: [img_id, [(label, bbox coords),...]]eg: ('001718', [('dog', (96, 13, 438, 332))])'''img_id = self.ids[index]anno = ET.parse(self.annopath % img_id).getroot()gt = self.target_transform(anno, 1, 1)return img_id[1], gtdef pull_tensor(self, index):'''Returns the original image at an index in tensor formNote: not using self.__getitem__(), as any transformations passed incould mess up this functionality.Argument:index (int): index of img to showReturn:tensorized version of img, squeezed'''return torch.Tensor(self.pull_image(index)).unsqueeze_(0)if __name__ == "__main__":def base_transform(image, size, mean):x = cv2.resize(image, (size, size)).astype(np.float32)x -= meanx = x.astype(np.float32)return xclass BaseTransform:def __init__(self, size, mean):self.size = sizeself.mean = np.array(mean, dtype=np.float32)def __call__(self, image, boxes=None, labels=None):return base_transform(image, self.size, self.mean), boxes, labelsimg_size = 640# datasetdataset = VOCDetection(data_dir='../VOCdevkit/',image_sets=[('2007', 'trainval')],transform=BaseTransform(img_size, (0, 0, 0)))for i in range(1000):# im, gt, h, w = dataset.pull_item(i)im,gt=dataset[i]img = im.permute(1,2,0).numpy()[:, :, (2, 1, 0)].astype(np.uint8)img = img.copy()for box in gt:xmin, ymin, xmax, ymax, _ = boxxmin *= img_sizeymin *= img_sizexmax *= img_sizeymax *= img_sizeimg = cv2.rectangle(img, (int(xmin), int(ymin)), (int(xmax), int(ymax)), (0,0,255), 2)cv2.imshow('gt', img)cv2.waitKey(0)
tools.py
import numpy as np
from data import *
import torch.nn as nn
import torch.nn.functional as F# We use ignore thresh to decide which anchor box can be kept.
ignore_thresh = 0.5class MSEWithLogitsLoss(nn.Module):def __init__(self, reduction='mean'):super(MSEWithLogitsLoss, self).__init__()self.reduction = reductiondef forward(self, logits, targets, mask):inputs = torch.sigmoid(logits)# We ignore those whose tarhets == -1.0. pos_id = (mask==1.0).float()neg_id = (mask==0.0).float()pos_loss = pos_id * (inputs - targets)**2neg_loss = neg_id * (inputs)**2loss = 5.0*pos_loss + 1.0*neg_lossif self.reduction == 'mean':batch_size = logits.size(0)loss = torch.sum(loss) / batch_sizereturn losselse:return lossdef compute_iou(anchor_boxes, gt_box):"""Input:anchor_boxes : ndarray -> [[c_x_s, c_y_s, anchor_w, anchor_h], ..., [c_x_s, c_y_s, anchor_w, anchor_h]].gt_box : ndarray -> [c_x_s, c_y_s, anchor_w, anchor_h].Output:iou : ndarray -> [iou_1, iou_2, ..., iou_m], and m is equal to the number of anchor boxes."""# compute the iou between anchor box and gt box# First, change [c_x_s, c_y_s, anchor_w, anchor_h] -> [xmin, ymin, xmax, ymax]# anchor box :ab_x1y1_x2y2 = np.zeros([len(anchor_boxes), 4])ab_x1y1_x2y2[:, 0] = anchor_boxes[:, 0] - anchor_boxes[:, 2] / 2 # xminab_x1y1_x2y2[:, 1] = anchor_boxes[:, 1] - anchor_boxes[:, 3] / 2 # yminab_x1y1_x2y2[:, 2] = anchor_boxes[:, 0] + anchor_boxes[:, 2] / 2 # xmaxab_x1y1_x2y2[:, 3] = anchor_boxes[:, 1] + anchor_boxes[:, 3] / 2 # ymaxw_ab, h_ab = anchor_boxes[:, 2], anchor_boxes[:, 3]# gt_box : # We need to expand gt_box(ndarray) to the shape of anchor_boxes(ndarray), in order to compute IoU easily. gt_box_expand = np.repeat(gt_box, len(anchor_boxes), axis=0)gb_x1y1_x2y2 = np.zeros([len(anchor_boxes), 4])gb_x1y1_x2y2[:, 0] = gt_box_expand[:, 0] - gt_box_expand[:, 2] / 2 # xmingb_x1y1_x2y2[:, 1] = gt_box_expand[:, 1] - gt_box_expand[:, 3] / 2 # ymingb_x1y1_x2y2[:, 2] = gt_box_expand[:, 0] + gt_box_expand[:, 2] / 2 # xmaxgb_x1y1_x2y2[:, 3] = gt_box_expand[:, 1] + gt_box_expand[:, 3] / 2 # yminw_gt, h_gt = gt_box_expand[:, 2], gt_box_expand[:, 3]# Then we compute IoU between anchor_box and gt_boxS_gt = w_gt * h_gtS_ab = w_ab * h_abI_w = np.minimum(gb_x1y1_x2y2[:, 2], ab_x1y1_x2y2[:, 2]) - np.maximum(gb_x1y1_x2y2[:, 0], ab_x1y1_x2y2[:, 0])I_h = np.minimum(gb_x1y1_x2y2[:, 3], ab_x1y1_x2y2[:, 3]) - np.maximum(gb_x1y1_x2y2[:, 1], ab_x1y1_x2y2[:, 1])S_I = I_h * I_wU = S_gt + S_ab - S_I + 1e-20IoU = S_I / Ureturn IoUdef set_anchors(anchor_size):"""Input:anchor_size : list -> [[h_1, w_1], [h_2, w_2], ..., [h_n, w_n]].Output:anchor_boxes : ndarray -> [[0, 0, anchor_w, anchor_h],[0, 0, anchor_w, anchor_h],...[0, 0, anchor_w, anchor_h]]."""anchor_number = len(anchor_size)anchor_boxes = np.zeros([anchor_number, 4])for index, size in enumerate(anchor_size): anchor_w, anchor_h = sizeanchor_boxes[index] = np.array([0, 0, anchor_w, anchor_h])return anchor_boxesdef generate_txtytwth(gt_label, w, h, s, all_anchor_size):xmin, ymin, xmax, ymax = gt_label[:-1]# compute the center, width and heightc_x = (xmax + xmin) / 2 * wc_y = (ymax + ymin) / 2 * hbox_w = (xmax - xmin) * wbox_h = (ymax - ymin) * hif box_w < 1. or box_h < 1.:# print('A dirty data !!!')return False # map the center, width and height to the feature map sizec_x_s = c_x / sc_y_s = c_y / sbox_ws = box_w / sbox_hs = box_h / s# the grid cell locationgrid_x = int(c_x_s)grid_y = int(c_y_s)# generate anchor boxesanchor_boxes = set_anchors(all_anchor_size)gt_box = np.array([[0, 0, box_ws, box_hs]])# compute the IoUiou = compute_iou(anchor_boxes, gt_box)# We consider those anchor boxes whose IoU is more than ignore thresh,iou_mask = (iou > ignore_thresh)result = []if iou_mask.sum() == 0:# We assign the anchor box with highest IoU score.index = np.argmax(iou)p_w, p_h = all_anchor_size[index]tx = c_x_s - grid_xty = c_y_s - grid_ytw = np.log(box_ws / p_w)th = np.log(box_hs / p_h)weight = 2.0 - (box_w / w) * (box_h / h)result.append([index, grid_x, grid_y, tx, ty, tw, th, weight, xmin, ymin, xmax, ymax])return resultelse:# There are more than one anchor boxes whose IoU are higher than ignore thresh.# But we only assign only one anchor box whose IoU is the best(objectness target is 1) and ignore other # anchor boxes whose(we set their objectness as -1 which means we will ignore them during computing obj loss )# iou_ = iou * iou_mask# We get the index of the best IoUbest_index = np.argmax(iou)for index, iou_m in enumerate(iou_mask):if iou_m:if index == best_index:p_w, p_h = all_anchor_size[index]tx = c_x_s - grid_xty = c_y_s - grid_ytw = np.log(box_ws / p_w)th = np.log(box_hs / p_h)weight = 2.0 - (box_w / w) * (box_h / h)result.append([index, grid_x, grid_y, tx, ty, tw, th, weight, xmin, ymin, xmax, ymax])else:# we ignore other anchor boxes even if their iou scores all higher than ignore threshresult.append([index, grid_x, grid_y, 0., 0., 0., 0., -1.0, 0., 0., 0., 0.])return result def gt_creator(input_size, stride, label_lists, anchor_size):"""Input:input_size : list -> the size of image in the training stage.stride : int or list -> the downSample of the CNN, such as 32, 64 and so on.label_list : list -> [[[xmin, ymin, xmax, ymax, cls_ind], ... ], [[xmin, ymin, xmax, ymax, cls_ind], ... ]], and len(label_list) = batch_size;len(label_list[i]) = the number of class instance in a image;(xmin, ymin, xmax, ymax) : the coords of a bbox whose valus is between 0 and 1;cls_ind : the corresponding class label.Output:gt_tensor : ndarray -> shape = [batch_size, anchor_number, 1+1+4, grid_cell number ]"""# prepare the all empty gt datasbatch_size = len(label_lists)h = w = input_size# We make gt labels by anchor-free method and anchor-based method.ws = w // stridehs = h // strides = stride# We use anchor boxes to build training target.all_anchor_size = anchor_sizeanchor_number = len(all_anchor_size)gt_tensor = np.zeros([batch_size, hs, ws, anchor_number, 1+1+4+1+4])for batch_index in range(batch_size):for gt_label in label_lists[batch_index]:# get a bbox coordsgt_class = int(gt_label[-1])results = generate_txtytwth(gt_label, w, h, s, all_anchor_size)if results:for result in results:index, grid_x, grid_y, tx, ty, tw, th, weight, xmin, ymin, xmax, ymax = resultif weight > 0.:if grid_y < gt_tensor.shape[1] and grid_x < gt_tensor.shape[2]:gt_tensor[batch_index, grid_y, grid_x, index, 0] = 1.0gt_tensor[batch_index, grid_y, grid_x, index, 1] = gt_classgt_tensor[batch_index, grid_y, grid_x, index, 2:6] = np.array([tx, ty, tw, th])gt_tensor[batch_index, grid_y, grid_x, index, 6] = weightgt_tensor[batch_index, grid_y, grid_x, index, 7:] = np.array([xmin, ymin, xmax, ymax])else:gt_tensor[batch_index, grid_y, grid_x, index, 0] = -1.0gt_tensor[batch_index, grid_y, grid_x, index, 6] = -1.0gt_tensor = gt_tensor.reshape(batch_size, hs * ws * anchor_number, 1+1+4+1+4)return gt_tensordef multi_gt_creator(input_size, strides, label_lists, anchor_size):"""creator multi scales gt"""# prepare the all empty gt datasbatch_size = len(label_lists)h = w = input_sizenum_scale = len(strides)gt_tensor = []all_anchor_size = anchor_sizeanchor_number = len(all_anchor_size) // num_scalefor s in strides:gt_tensor.append(np.zeros([batch_size, h//s, w//s, anchor_number, 1+1+4+1+4]))# generate gt datas for batch_index in range(batch_size):for gt_label in label_lists[batch_index]:# get a bbox coordsgt_class = int(gt_label[-1])xmin, ymin, xmax, ymax = gt_label[:-1]# compute the center, width and heightc_x = (xmax + xmin) / 2 * wc_y = (ymax + ymin) / 2 * hbox_w = (xmax - xmin) * wbox_h = (ymax - ymin) * hif box_w < 1. or box_h < 1.:# print('A dirty data !!!')continue # compute the IoUanchor_boxes = set_anchors(all_anchor_size)gt_box = np.array([[0, 0, box_w, box_h]])iou = compute_iou(anchor_boxes, gt_box)# We only consider those anchor boxes whose IoU is more than ignore thresh,iou_mask = (iou > ignore_thresh)if iou_mask.sum() == 0:# We assign the anchor box with highest IoU score.index = np.argmax(iou)# s_indx, ab_ind = index // num_scale, index % num_scales_indx = index // anchor_numberab_ind = index - s_indx * anchor_number# get the corresponding strides = strides[s_indx]# get the corresponding anchor boxp_w, p_h = anchor_boxes[index, 2], anchor_boxes[index, 3]# compute the gride cell locationc_x_s = c_x / sc_y_s = c_y / sgrid_x = int(c_x_s)grid_y = int(c_y_s)# compute gt labelstx = c_x_s - grid_xty = c_y_s - grid_ytw = np.log(box_w / p_w)th = np.log(box_h / p_h)weight = 2.0 - (box_w / w) * (box_h / h)if grid_y < gt_tensor[s_indx].shape[1] and grid_x < gt_tensor[s_indx].shape[2]:gt_tensor[s_indx][batch_index, grid_y, grid_x, ab_ind, 0] = 1.0gt_tensor[s_indx][batch_index, grid_y, grid_x, ab_ind, 1] = gt_classgt_tensor[s_indx][batch_index, grid_y, grid_x, ab_ind, 2:6] = np.array([tx, ty, tw, th])gt_tensor[s_indx][batch_index, grid_y, grid_x, ab_ind, 6] = weightgt_tensor[s_indx][batch_index, grid_y, grid_x, ab_ind, 7:] = np.array([xmin, ymin, xmax, ymax])else:# There are more than one anchor boxes whose IoU are higher than ignore thresh.# But we only assign only one anchor box whose IoU is the best(objectness target is 1) and ignore other # anchor boxes whose(we set their objectness as -1 which means we will ignore them during computing obj loss )# iou_ = iou * iou_mask# We get the index of the best IoUbest_index = np.argmax(iou)for index, iou_m in enumerate(iou_mask):if iou_m:if index == best_index:# s_indx, ab_ind = index // num_scale, index % num_scales_indx = index // anchor_numberab_ind = index - s_indx * anchor_number# get the corresponding strides = strides[s_indx]# get the corresponding anchor boxp_w, p_h = anchor_boxes[index, 2], anchor_boxes[index, 3]# compute the gride cell locationc_x_s = c_x / sc_y_s = c_y / sgrid_x = int(c_x_s)grid_y = int(c_y_s)# compute gt labelstx = c_x_s - grid_xty = c_y_s - grid_ytw = np.log(box_w / p_w)th = np.log(box_h / p_h)weight = 2.0 - (box_w / w) * (box_h / h)if grid_y < gt_tensor[s_indx].shape[1] and grid_x < gt_tensor[s_indx].shape[2]:gt_tensor[s_indx][batch_index, grid_y, grid_x, ab_ind, 0] = 1.0gt_tensor[s_indx][batch_index, grid_y, grid_x, ab_ind, 1] = gt_classgt_tensor[s_indx][batch_index, grid_y, grid_x, ab_ind, 2:6] = np.array([tx, ty, tw, th])gt_tensor[s_indx][batch_index, grid_y, grid_x, ab_ind, 6] = weightgt_tensor[s_indx][batch_index, grid_y, grid_x, ab_ind, 7:] = np.array([xmin, ymin, xmax, ymax])else:# we ignore other anchor boxes even if their iou scores are higher than ignore thresh# s_indx, ab_ind = index // num_scale, index % num_scales_indx = index // anchor_numberab_ind = index - s_indx * anchor_numbers = strides[s_indx]c_x_s = c_x / sc_y_s = c_y / sgrid_x = int(c_x_s)grid_y = int(c_y_s)gt_tensor[s_indx][batch_index, grid_y, grid_x, ab_ind, 0] = -1.0gt_tensor[s_indx][batch_index, grid_y, grid_x, ab_ind, 6] = -1.0gt_tensor = [gt.reshape(batch_size, -1, 1+1+4+1+4) for gt in gt_tensor]gt_tensor = np.concatenate(gt_tensor, 1)return gt_tensordef iou_score(bboxes_a, bboxes_b):"""bbox_1 : [B*N, 4] = [x1, y1, x2, y2]bbox_2 : [B*N, 4] = [x1, y1, x2, y2]"""tl = torch.max(bboxes_a[:, :2], bboxes_b[:, :2])br = torch.min(bboxes_a[:, 2:], bboxes_b[:, 2:])area_a = torch.prod(bboxes_a[:, 2:] - bboxes_a[:, :2], 1)area_b = torch.prod(bboxes_b[:, 2:] - bboxes_b[:, :2], 1)en = (tl < br).type(tl.type()).prod(dim=1)area_i = torch.prod(br - tl, 1) * en # * ((tl < br).all())return area_i / (area_a + area_b - area_i + 1e-14)def loss(pred_conf, pred_cls, pred_txtytwth, pred_iou, label):# loss funcconf_loss_function = MSEWithLogitsLoss(reduction='mean')cls_loss_function = nn.CrossEntropyLoss(reduction='none')txty_loss_function = nn.BCEWithLogitsLoss(reduction='none')twth_loss_function = nn.MSELoss(reduction='none')iou_loss_function = nn.SmoothL1Loss(reduction='none')# predpred_conf = pred_conf[:, :, 0]pred_cls = pred_cls.permute(0, 2, 1)pred_txty = pred_txtytwth[:, :, :2]pred_twth = pred_txtytwth[:, :, 2:]pred_iou = pred_iou[:, :, 0]# gt gt_conf = label[:, :, 0].float()gt_obj = label[:, :, 1].float()gt_cls = label[:, :, 2].long()gt_txty = label[:, :, 3:5].float()gt_twth = label[:, :, 5:7].float()gt_box_scale_weight = label[:, :, 7].float()gt_iou = (gt_box_scale_weight > 0.).float()gt_mask = (gt_box_scale_weight > 0.).float()batch_size = pred_conf.size(0)# objectness lossconf_loss = conf_loss_function(pred_conf, gt_conf, gt_obj)# class losscls_loss = torch.sum(cls_loss_function(pred_cls, gt_cls) * gt_mask) / batch_size# box losstxty_loss = torch.sum(torch.sum(txty_loss_function(pred_txty, gt_txty), dim=-1) * gt_box_scale_weight * gt_mask) / batch_sizetwth_loss = torch.sum(torch.sum(twth_loss_function(pred_twth, gt_twth), dim=-1) * gt_box_scale_weight * gt_mask) / batch_sizebbox_loss = txty_loss + twth_loss# iou lossiou_loss = torch.sum(iou_loss_function(pred_iou, gt_iou) * gt_mask) / batch_sizereturn conf_loss, cls_loss, bbox_loss, iou_lossif __name__ == "__main__":gt_box = np.array([[0.0, 0.0, 10, 10]])anchor_boxes = np.array([[0.0, 0.0, 10, 10], [0.0, 0.0, 4, 4], [0.0, 0.0, 8, 8], [0.0, 0.0, 16, 16]])iou = compute_iou(anchor_boxes, gt_box)print(iou)train.py
from __future__ import divisionimport os
import random
import argparse
import time
import cv2
import numpy as np
from copy import deepcopyimport torch
import torch.optim as optim
import torch.backends.cudnn as cudnn
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDPfrom data.voc0712 import VOCDetection
from data.coco2017 import COCODataset
from data import config
from data import BaseTransform, detection_collateimport toolsfrom utils import distributed_utils
from utils.com_paras_flops import FLOPs_and_Params
from utils.augmentations import SSDAugmentation, ColorAugmentation
from utils.cocoapi_evaluator import COCOAPIEvaluator
from utils.vocapi_evaluator import VOCAPIEvaluator
from utils.modules import ModelEMAdef parse_args():parser = argparse.ArgumentParser(description='YOLO Detection')# basicparser.add_argument('--cuda', action='store_true', default=False,help='use cuda.')parser.add_argument('-bs', '--batch_size', default=16, type=int, help='Batch size for training')parser.add_argument('--lr', default=1e-3, type=float, help='initial learning rate')parser.add_argument('--wp_epoch', type=int, default=2,help='The upper bound of warm-up')parser.add_argument('--start_epoch', type=int, default=0,help='start epoch to train')parser.add_argument('-r', '--resume', default=None, type=str, help='keep training')parser.add_argument('--momentum', default=0.9, type=float, help='Momentum value for optim')parser.add_argument('--weight_decay', default=5e-4, type=float, help='Weight decay for SGD')parser.add_argument('--num_workers', default=8, type=int, help='Number of workers used in dataloading')parser.add_argument('--num_gpu', default=1, type=int, help='Number of GPUs to train')parser.add_argument('--eval_epoch', type=int,default=10, help='interval between evaluations')parser.add_argument('--tfboard', action='store_true', default=False,help='use tensorboard')parser.add_argument('--save_folder', default='weights/', type=str, help='Gamma update for SGD')parser.add_argument('--vis', action='store_true', default=False,help='visualize target.')# modelparser.add_argument('-v', '--version', default='yolov2_d19',help='yolov2_d19, yolov2_r50, yolov2_slim, yolov3, yolov3_spp, yolov3_tiny')# datasetparser.add_argument('-root', '--data_root', default='./',help='dataset root')parser.add_argument('-d', '--dataset', default='voc',help='voc or coco')# train trickparser.add_argument('--no_warmup', action='store_true', default=False,help='do not use warmup')parser.add_argument('-ms', '--multi_scale', action='store_true', default=False,help='use multi-scale trick') parser.add_argument('--mosaic', action='store_true', default=False,help='use mosaic augmentation')parser.add_argument('--ema', action='store_true', default=False,help='use ema training trick')# DDP trainparser.add_argument('-dist', '--distributed', action='store_true', default=False,help='distributed training')parser.add_argument('--dist_url', default='env://', help='url used to set up distributed training')parser.add_argument('--world_size', default=1, type=int,help='number of distributed processes')parser.add_argument('--sybn', action='store_true', default=False, help='use sybn.')return parser.parse_args()def train():args = parse_args()print("Setting Arguments.. : ", args)print("----------------------------------------------------------")# set distributedprint('World size: {}'.format(distributed_utils.get_world_size()))if args.distributed:distributed_utils.init_distributed_mode(args)print("git:\n {}\n".format(distributed_utils.get_sha()))# cudaif args.cuda:print('use cuda')# cudnn.benchmark = Truedevice = torch.device("cuda")else:device = torch.device("cpu")model_name = args.versionprint('Model: ', model_name)# load model and config fileif model_name == 'yolov2_d19':from models.yolov2_d19 import YOLOv2D19 as yolo_netcfg = config.yolov2_d19_cfgelif model_name == 'yolov2_r50':from models.yolov2_r50 import YOLOv2R50 as yolo_netcfg = config.yolov2_r50_cfgelif model_name == 'yolov3':from models.yolov3 import YOLOv3 as yolo_netcfg = config.yolov3_d53_cfgelif model_name == 'yolov3_spp':from models.yolov3_spp import YOLOv3Spp as yolo_netcfg = config.yolov3_d53_cfgelif model_name == 'yolov3_tiny':from models.yolov3_tiny import YOLOv3tiny as yolo_netcfg = config.yolov3_tiny_cfgelse:print('Unknown model name...')exit(0)# path to save modelpath_to_save = os.path.join(args.save_folder, args.dataset, args.version)os.makedirs(path_to_save, exist_ok=True)# multi-scaleif args.multi_scale:print('use the multi-scale trick ...')train_size = cfg['train_size']val_size = cfg['val_size']else:train_size = val_size = cfg['train_size']# Model ENAif args.ema:print('use EMA trick ...')# dataset and evaluatorif args.dataset == 'voc':data_dir = os.path.join(args.data_root, 'VOCdevkit/')num_classes = 20dataset = VOCDetection(data_dir=data_dir, transform=SSDAugmentation(train_size))evaluator = VOCAPIEvaluator(data_root=data_dir,img_size=val_size,device=device,transform=BaseTransform(val_size))elif args.dataset == 'coco':data_dir = os.path.join(args.data_root, 'COCO')num_classes = 80dataset = COCODataset(data_dir=data_dir,transform=SSDAugmentation(train_size))evaluator = COCOAPIEvaluator(data_dir=data_dir,img_size=val_size,device=device,transform=BaseTransform(val_size))else:print('unknow dataset !! Only support voc and coco !!')exit(0)print('Training model on:', dataset.name)print('The dataset size:', len(dataset))print("----------------------------------------------------------")# build modelanchor_size = cfg['anchor_size_voc'] if args.dataset == 'voc' else cfg['anchor_size_coco']net = yolo_net(device=device, input_size=train_size, num_classes=num_classes, trainable=True, anchor_size=anchor_size)model = netmodel = model.to(device).train()# SyncBatchNormif args.sybn and args.distributed:print('use SyncBatchNorm ...')model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)# DDPmodel_without_ddp = modelif args.distributed:model = DDP(model, device_ids=[args.gpu])model_without_ddp = model.module# compute FLOPs and Paramsif distributed_utils.is_main_process:model_copy = deepcopy(model_without_ddp)model_copy.trainable = Falsemodel_copy.eval()FLOPs_and_Params(model=model_copy, size=train_size, device=device)model_copy.trainable = Truemodel_copy.train()if args.distributed:# wait for all processes to synchronizedist.barrier()# dataloaderbatch_size = args.batch_size * distributed_utils.get_world_size()if args.distributed and args.num_gpu > 1:dataloader = torch.utils.data.DataLoader(dataset=dataset, batch_size=batch_size, collate_fn=detection_collate,num_workers=args.num_workers,pin_memory=True,drop_last=True,sampler=torch.utils.data.distributed.DistributedSampler(dataset))else:# dataloaderdataloader = torch.utils.data.DataLoader(dataset=dataset, shuffle=True,batch_size=batch_size, collate_fn=detection_collate,num_workers=args.num_workers,pin_memory=True,drop_last=True)# keep trainingif args.resume is not None:print('keep training model: %s' % (args.resume))model.load_state_dict(torch.load(args.resume, map_location=device))# EMAema = ModelEMA(model) if args.ema else None# use tfboardif args.tfboard:print('use tensorboard')from torch.utils.tensorboard import SummaryWriterc_time = time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))log_path = os.path.join('log/', args.dataset, c_time)os.makedirs(log_path, exist_ok=True)tblogger = SummaryWriter(log_path)# optimizer setupbase_lr = (args.lr / 16) * batch_sizetmp_lr = base_lroptimizer = optim.SGD(model.parameters(), lr=base_lr, momentum=args.momentum,weight_decay=args.weight_decay)max_epoch = cfg['max_epoch']epoch_size = len(dataloader)best_map = -1.warmup = not args.no_warmupt0 = time.time()# start training loopfor epoch in range(args.start_epoch, max_epoch):if args.distributed:dataloader.sampler.set_epoch(epoch) # use step lrif epoch in cfg['lr_epoch']:tmp_lr = tmp_lr * 0.1set_lr(optimizer, tmp_lr)for iter_i, (images, targets) in enumerate(dataloader):# WarmUp strategy for learning rateni = iter_i + epoch * epoch_size# warmupif epoch < args.wp_epoch and warmup:nw = args.wp_epoch * epoch_sizetmp_lr = base_lr * pow(ni / nw, 4)set_lr(optimizer, tmp_lr)elif epoch == args.wp_epoch and iter_i == 0 and warmup:# warmup is overwarmup = Falsetmp_lr = base_lrset_lr(optimizer, tmp_lr)# multi-scale trickif iter_i % 10 == 0 and iter_i > 0 and args.multi_scale:# randomly choose a new sizer = cfg['random_size_range']train_size = random.randint(r[0], r[1]) * 32model.set_grid(train_size)if args.multi_scale:# interpolateimages = torch.nn.functional.interpolate(images, size=train_size, mode='bilinear', align_corners=False)targets = [label.tolist() for label in targets]# visualize labelsif args.vis:vis_data(images, targets, train_size)continue# label assignmentif model_name in ['yolov2_d19', 'yolov2_r50']:targets = tools.gt_creator(input_size=train_size, stride=net.stride, label_lists=targets, anchor_size=anchor_size)else:targets = tools.multi_gt_creator(input_size=train_size, strides=net.stride, label_lists=targets, anchor_size=anchor_size)# to deviceimages = images.float().to(device)targets = torch.tensor(targets).float().to(device)# forwardconf_loss, cls_loss, box_loss, iou_loss = model(images, target=targets)# compute losstotal_loss = conf_loss + cls_loss + box_loss + iou_lossloss_dict = dict(conf_loss=conf_loss,cls_loss=cls_loss,box_loss=box_loss,iou_loss=iou_loss,total_loss=total_loss)loss_dict_reduced = distributed_utils.reduce_dict(loss_dict)# check NAN for lossif torch.isnan(total_loss):print('loss is nan !!')continue# backproptotal_loss.backward() optimizer.step()optimizer.zero_grad()# emaif args.ema:ema.update(model)# displayif distributed_utils.is_main_process() and iter_i % 10 == 0:if args.tfboard:# viz losstblogger.add_scalar('conf loss', loss_dict_reduced['conf_loss'].item(), iter_i + epoch * epoch_size)tblogger.add_scalar('cls loss', loss_dict_reduced['cls_loss'].item(), iter_i + epoch * epoch_size)tblogger.add_scalar('box loss', loss_dict_reduced['box_loss'].item(), iter_i + epoch * epoch_size)tblogger.add_scalar('iou loss', loss_dict_reduced['iou_loss'].item(), iter_i + epoch * epoch_size)t1 = time.time()cur_lr = [param_group['lr'] for param_group in optimizer.param_groups]# basic inforlog = '[Epoch: {}/{}]'.format(epoch+1, max_epoch)log += '[Iter: {}/{}]'.format(iter_i, epoch_size)log += '[lr: {:.6f}]'.format(cur_lr[0])# loss inforfor k in loss_dict_reduced.keys():log += '[{}: {:.2f}]'.format(k, loss_dict[k])# other inforlog += '[time: {:.2f}]'.format(t1 - t0)log += '[size: {}]'.format(train_size)# print log inforprint(log, flush=True)t0 = time.time()if distributed_utils.is_main_process():# evaluationif (epoch % args.eval_epoch) == 0 or (epoch == max_epoch - 1):if args.ema:model_eval = ema.emaelse:model_eval = model_without_ddp# check evaluatorif evaluator is None:print('No evaluator ... save model and go on training.')print('Saving state, epoch: {}'.format(epoch + 1))weight_name = '{}_epoch_{}.pth'.format(args.version, epoch + 1)checkpoint_path = os.path.join(path_to_save, weight_name)torch.save(model_eval.state_dict(), checkpoint_path) else:print('eval ...')# set eval modemodel_eval.trainable = Falsemodel_eval.set_grid(val_size)model_eval.eval()# evaluateevaluator.evaluate(model_eval)cur_map = evaluator.mapif cur_map > best_map:# update best-mapbest_map = cur_map# save modelprint('Saving state, epoch:', epoch + 1)weight_name = '{}_epoch_{}_{:.2f}.pth'.format(args.version, epoch + 1, best_map*100)checkpoint_path = os.path.join(path_to_save, weight_name)torch.save(model_eval.state_dict(), checkpoint_path) if args.tfboard:if args.dataset == 'voc':tblogger.add_scalar('07test/mAP', evaluator.map, epoch)elif args.dataset == 'coco':tblogger.add_scalar('val/AP50_95', evaluator.ap50_95, epoch)tblogger.add_scalar('val/AP50', evaluator.ap50, epoch)# set train mode.model_eval.trainable = Truemodel_eval.set_grid(train_size)model_eval.train()# wait for all processes to synchronizeif args.distributed:dist.barrier()if args.tfboard:tblogger.close()def set_lr(optimizer, lr):for param_group in optimizer.param_groups:param_group['lr'] = lrdef vis_data(images, targets, input_size):# vis datamean=(0.406, 0.456, 0.485)std=(0.225, 0.224, 0.229)mean = np.array(mean, dtype=np.float32)std = np.array(std, dtype=np.float32)img = images[0].permute(1, 2, 0).cpu().numpy()[:, :, ::-1]img = ((img * std + mean)*255).astype(np.uint8)img = img.copy()for box in targets[0]:xmin, ymin, xmax, ymax = box[:-1]# print(xmin, ymin, xmax, ymax)xmin *= input_sizeymin *= input_sizexmax *= input_sizeymax *= input_sizecv2.rectangle(img, (int(xmin), int(ymin)), (int(xmax), int(ymax)), (0, 0, 255), 2)cv2.imshow('img', img)cv2.waitKey(0)if __name__ == '__main__':train()
model.py
import numpy as np
import torch
import torch.nn as nn
from utils.modules import Conv, reorg_layerfrom backbone import build_backbone
import toolsclass YOLOv2D19(nn.Module):def __init__(self, device, input_size=None, num_classes=20, trainable=False, conf_thresh=0.001, nms_thresh=0.5, anchor_size=None):super(YOLOv2D19, self).__init__()self.device = deviceself.input_size = input_sizeself.num_classes = num_classesself.trainable = trainableself.conf_thresh = conf_threshself.nms_thresh = nms_threshself.anchor_size = torch.tensor(anchor_size)self.num_anchors = len(anchor_size)self.stride = 32self.grid_cell, self.all_anchor_wh = self.create_grid(input_size)# backbone darknet-19self.backbone = build_backbone(model_name='darknet19', pretrained=trainable)# detection headself.convsets_1 = nn.Sequential(Conv(1024, 1024, k=3, p=1),Conv(1024, 1024, k=3, p=1))self.route_layer = Conv(512, 64, k=1)self.reorg = reorg_layer(stride=2)self.convsets_2 = Conv(1280, 1024, k=3, p=1)# prediction layerself.pred = nn.Conv2d(1024, self.num_anchors*(1 + 4 + self.num_classes), kernel_size=1)def create_grid(self, input_size):w, h = input_size, input_size# generate grid cellsws, hs = w // self.stride, h // self.stridegrid_y, grid_x = torch.meshgrid([torch.arange(hs), torch.arange(ws)])grid_xy = torch.stack([grid_x, grid_y], dim=-1).float()grid_xy = grid_xy.view(1, hs*ws, 1, 2).to(self.device)# generate anchor_wh tensoranchor_wh = self.anchor_size.repeat(hs*ws, 1, 1).unsqueeze(0).to(self.device)return grid_xy, anchor_whdef set_grid(self, input_size):self.input_size = input_sizeself.grid_cell, self.all_anchor_wh = self.create_grid(input_size)def decode_xywh(self, txtytwth_pred):"""Input: \ntxtytwth_pred : [B, H*W, anchor_n, 4] \nOutput: \nxywh_pred : [B, H*W*anchor_n, 4] \n"""B, HW, ab_n, _ = txtytwth_pred.size()# b_x = sigmoid(tx) + gride_x# b_y = sigmoid(ty) + gride_yxy_pred = torch.sigmoid(txtytwth_pred[..., :2]) + self.grid_cell# b_w = anchor_w * exp(tw)# b_h = anchor_h * exp(th)wh_pred = torch.exp(txtytwth_pred[..., 2:]) * self.all_anchor_wh# [B, H*W, anchor_n, 4] -> [B, H*W*anchor_n, 4]xywh_pred = torch.cat([xy_pred, wh_pred], -1).view(B, -1, 4) * self.stridereturn xywh_preddef decode_boxes(self, txtytwth_pred):"""Input: \ntxtytwth_pred : [B, H*W, anchor_n, 4] \nOutput: \nx1y1x2y2_pred : [B, H*W*anchor_n, 4] \n"""# txtytwth -> cxcywhxywh_pred = self.decode_xywh(txtytwth_pred)# cxcywh -> x1y1x2y2x1y1x2y2_pred = torch.zeros_like(xywh_pred)x1y1_pred = xywh_pred[..., :2] - xywh_pred[..., 2:] * 0.5x2y2_pred = xywh_pred[..., :2] + xywh_pred[..., 2:] * 0.5x1y1x2y2_pred = torch.cat([x1y1_pred, x2y2_pred], dim=-1)return x1y1x2y2_preddef nms(self, dets, scores):""""Pure Python NMS baseline."""x1 = dets[:, 0] #xminy1 = dets[:, 1] #yminx2 = dets[:, 2] #xmaxy2 = dets[:, 3] #ymaxareas = (x2 - x1) * (y2 - y1)order = scores.argsort()[::-1]keep = []while order.size > 0:i = order[0]keep.append(i)xx1 = np.maximum(x1[i], x1[order[1:]])yy1 = np.maximum(y1[i], y1[order[1:]])xx2 = np.minimum(x2[i], x2[order[1:]])yy2 = np.minimum(y2[i], y2[order[1:]])w = np.maximum(1e-10, xx2 - xx1)h = np.maximum(1e-10, yy2 - yy1)inter = w * h# Cross Area / (bbox + particular area - Cross Area)ovr = inter / (areas[i] + areas[order[1:]] - inter)#reserve all the boundingbox whose ovr less than threshinds = np.where(ovr <= self.nms_thresh)[0]order = order[inds + 1]return keepdef postprocess(self, bboxes, scores):"""bboxes: (HxW, 4), bsize = 1scores: (HxW, num_classes), bsize = 1"""cls_inds = np.argmax(scores, axis=1)scores = scores[(np.arange(scores.shape[0]), cls_inds)]# thresholdkeep = np.where(scores >= self.conf_thresh)bboxes = bboxes[keep]scores = scores[keep]cls_inds = cls_inds[keep]# NMSkeep = np.zeros(len(bboxes), dtype=np.int)for i in range(self.num_classes):inds = np.where(cls_inds == i)[0]if len(inds) == 0:continuec_bboxes = bboxes[inds]c_scores = scores[inds]c_keep = self.nms(c_bboxes, c_scores)keep[inds[c_keep]] = 1keep = np.where(keep > 0)bboxes = bboxes[keep]scores = scores[keep]cls_inds = cls_inds[keep]return bboxes, scores, cls_inds@ torch.no_grad()def inference(self, x):# backbonefeats = self.backbone(x)# reorg layerp5 = self.convsets_1(feats['layer3'])p4 = self.reorg(self.route_layer(feats['layer2']))p5 = torch.cat([p4, p5], dim=1)# headp5 = self.convsets_2(p5)# predpred = self.pred(p5)B, abC, H, W = pred.size()# [B, num_anchor * C, H, W] -> [B, H, W, num_anchor * C] -> [B, H*W, num_anchor*C]pred = pred.permute(0, 2, 3, 1).contiguous().view(B, H*W, abC)# [B, H*W*num_anchor, 1]conf_pred = pred[:, :, :1 * self.num_anchors].contiguous().view(B, H*W*self.num_anchors, 1)# [B, H*W, num_anchor, num_cls]cls_pred = pred[:, :, 1 * self.num_anchors : (1 + self.num_classes) * self.num_anchors].contiguous().view(B, H*W*self.num_anchors, self.num_classes)# [B, H*W, num_anchor, 4]reg_pred = pred[:, :, (1 + self.num_classes) * self.num_anchors:].contiguous()# decode boxreg_pred = reg_pred.view(B, H*W, self.num_anchors, 4)box_pred = self.decode_boxes(reg_pred)# batch size = 1conf_pred = conf_pred[0]cls_pred = cls_pred[0]box_pred = box_pred[0]# scorescores = torch.sigmoid(conf_pred) * torch.softmax(cls_pred, dim=-1)# normalize bboxbboxes = torch.clamp(box_pred / self.input_size, 0., 1.)# to cpuscores = scores.to('cpu').numpy()bboxes = bboxes.to('cpu').numpy()# post-processbboxes, scores, cls_inds = self.postprocess(bboxes, scores)return bboxes, scores, cls_indsdef forward(self, x, target=None):if not self.trainable:return self.inference(x)else:# backbonefeats = self.backbone(x)# reorg layerp5 = self.convsets_1(feats['layer3'])p4 = self.reorg(self.route_layer(feats['layer2']))p5 = torch.cat([p4, p5], dim=1)# headp5 = self.convsets_2(p5)# predpred = self.pred(p5)B, abC, H, W = pred.size()# [B, num_anchor * C, H, W] -> [B, H, W, num_anchor * C] -> [B, H*W, num_anchor*C]pred = pred.permute(0, 2, 3, 1).contiguous().view(B, H*W, abC)# [B, H*W*num_anchor, 1]conf_pred = pred[:, :, :1 * self.num_anchors].contiguous().view(B, H*W*self.num_anchors, 1)# [B, H*W, num_anchor, num_cls]cls_pred = pred[:, :, 1 * self.num_anchors : (1 + self.num_classes) * self.num_anchors].contiguous().view(B, H*W*self.num_anchors, self.num_classes)# [B, H*W, num_anchor, 4]reg_pred = pred[:, :, (1 + self.num_classes) * self.num_anchors:].contiguous()reg_pred = reg_pred.view(B, H*W, self.num_anchors, 4)# decode bboxx1y1x2y2_pred = (self.decode_boxes(reg_pred) / self.input_size).view(-1, 4)x1y1x2y2_gt = target[:, :, 7:].view(-1, 4)reg_pred = reg_pred.view(B, H*W*self.num_anchors, 4)# set conf targetiou_pred = tools.iou_score(x1y1x2y2_pred, x1y1x2y2_gt).view(B, -1, 1)gt_conf = iou_pred.clone().detach()# [obj, cls, txtytwth, x1y1x2y2] -> [conf, obj, cls, txtytwth]target = torch.cat([gt_conf, target[:, :, :7]], dim=2)# loss(conf_loss,cls_loss,bbox_loss,iou_loss) = tools.loss(pred_conf=conf_pred,pred_cls=cls_pred,pred_txtytwth=reg_pred,pred_iou=iou_pred,label=target)return conf_loss, cls_loss, bbox_loss, iou_loss if __name__=='__main__':import cv2from utils.vocapi_evaluator import VOCAPIEvaluatorfrom utils.augmentations import SSDAugmentationfrom data import BaseTransformdef vis_data(images, targets, input_size):# 可视化数据mean = (0.406, 0.456, 0.485)std = (0.225, 0.224, 0.229)mean = np.array(mean, dtype=np.float32)std = np.array(std, dtype=np.float32)img = images.permute(1, 2, 0).cpu().numpy()[:, :, ::-1]img = ((img * std + mean) * 255).astype(np.uint8)img = img.copy()for box in targets:xmin, ymin, xmax, ymax = box[:-1]# print(xmin, ymin, xmax, ymax)xmin *= input_sizeymin *= input_sizexmax *= input_sizeymax *= input_sizecv2.rectangle(img, (int(xmin), int(ymin)), (int(xmax), int(ymax)), (0, 0, 255), 2)cv2.imshow('img', img)cv2.waitKey(0)from data.voc0712 import VOCDetectiondevice = 'cuda' if torch.cuda.is_available() else 'cpu'dataset = VOCDetection(data_dir='../VOCdevkit/',transform=SSDAugmentation(416))evaluator = VOCAPIEvaluator(data_root='../VOCdevkit/',img_size=416,device=device,transform=BaseTransform(416))image,label=dataset[0]anchor_size=[[1.19, 1.98], [2.79, 4.59], [4.53, 8.92], [8.06, 5.29], [10.32, 10.65]]model = YOLOv2D19(device=device,input_size=640,num_classes=20,anchor_size=anchor_size)print(model)optimizer = torch.optim.SGD(model.parameters(),lr=0.001,momentum=0.99,weight_decay=0.01)for epoch in range(10):for image,labels in dataset:labels=[label.tolist() for label in labels]vis_data(image, labels, 416)# 标签对齐targets = tools.gt_creator(input_size=640,stride=model.stride,label_lists=labels,anchor_size=anchor_size)conf_loss, cls_loss, box_loss, iou_loss = model(image, target=targets)total_loss = conf_loss + cls_loss + box_loss + iou_losstotal_loss.backward()optimizer.step()optimizer.zero_grad()print('loss',total_loss.item)# 模型评估best_map = -1000model_eval = model# set eval modemodel_eval.trainable = Falsemodel_eval.set_grid(416)model_eval.eval()# evaluateevaluator.evaluate(model_eval)cur_map = evaluator.mapprint('map', cur_map)if cur_map > best_map:# update best-mapbest_map = cur_map参考文献:
yolov2-yolov3-PyTorch-master.zip资源-CSDN文库
【YOLO系列】YOLOv2论文超详细解读(翻译 +学习笔记)_路人贾'ω'的博客-CSDN博客
YOLOV2详解_白鲸先神的博客-CSDN博客
tztztztztz/yolov2.pytorch: YOLOv2 algorithm reimplementation with pytorch (github.com)
longcw/yolo2-pytorch: YOLOv2 in PyTorch (github.com)
yjh0410/yolov2-yolov3_PyTorch (github.com)
YOLOV3
参考文献:
YOLOv3详解_yolov3是什么_wq_0708的博客-CSDN博客
睿智的目标检测26——Pytorch搭建yolo3目标检测平台_Bubbliiiing的博客-CSDN博客
yolov3模型训练——使用yolov3训练自己的模型_萝北村的枫子的博客-CSDN博客
YOLOv3原理详解(绝对通俗易懂)2021-07-01_YD-阿三的博客-CSDN博客
本文链接:https://my.lmcjl.com/post/9528.html
4 评论