-
训练过程总览
-
理清演化路径
-
预训练(pretrain)
-
GPT-3概述
-
GPT 3模型的理念
-
GPT-3如何学习
-
数据集
-
-
指令微调 (Instruction Fine-Tuning,IFT)
-
有监督微调 (Supervised Fine-tuning, SFT)
-
人类反馈强化学习 (Reinforcement Learning From Human Feedback,RLHF)
-
其他方法
-
思维链 (Chain-of-thought,CoT)
-
-
与chatGPT类似的工作
训练过程总览
OpenAI 使用了 175B参数的大型语言模型(LM) 和 6B参数的奖励模型 (RM)。除预训练之外,训练过程分为三步:
-
收集NLP各种任务的数据集,加上任务描述和提示组装成新的数据集,并使用这些数据微调预训练的大型语言模型。包括指令微调和有监督微调。
-
从上述数据集中采样,使用大型语言模型生成多个响应,手动对这些响应进行排名,并训练奖励模型 (RM) 以适应人类偏好。
-
基于第一阶段的有监督微调模型和第二阶段的奖励模型,使用强化学习算法进一步训练大型语言模型。
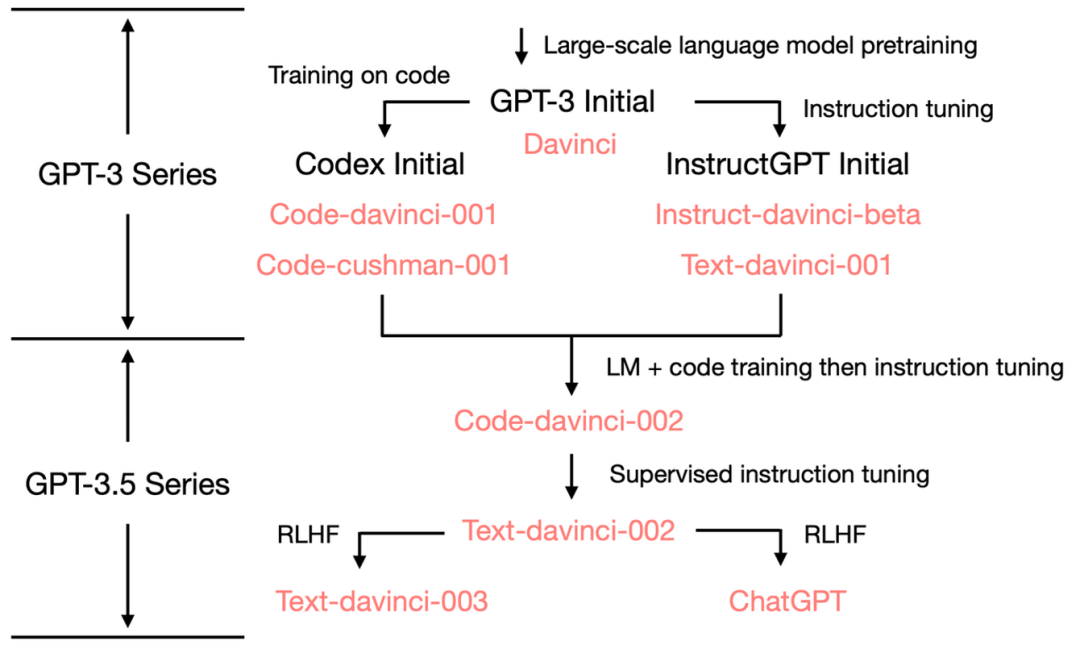
理清演化路径
GPT-3.5 参数量仍然为175B,总体进化树如下:
img

img
预训练(pretrain)
GPT-3概述

-
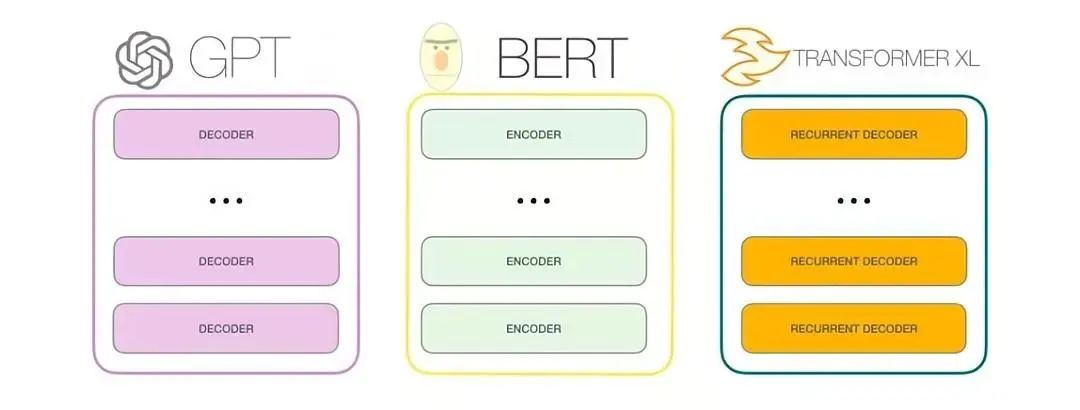
GPT-3是一种自回归模型,仅使用解码器,训练目标也是预测下一个单词(没有判断下一句任务)。
-
最大的GPT-3模型有175B参数,是BERT模型大470倍(0.375B)
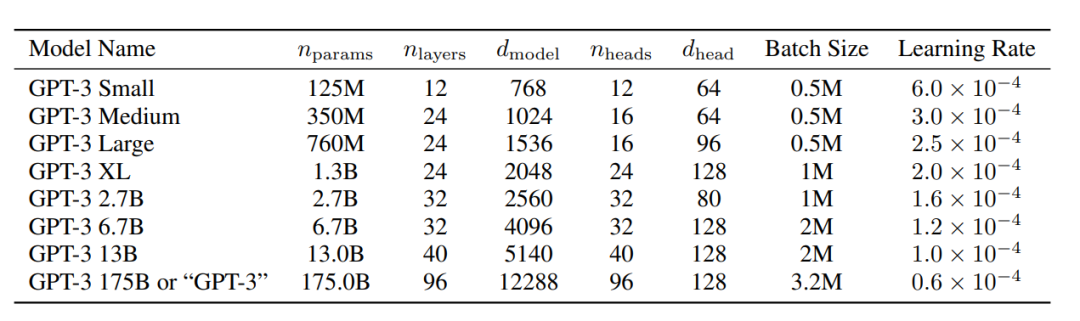
image-20230221144754842
GPT 3模型的理念
-
不需要接新的模型结构:如bert用于NER任务一般接LSTM+CRF
-
不需要微调
-
一个模型解决NLP多种任务
-
NLP任务都可以用生成模型解决
-
和人类一样,只需要看极少数量的样例就能学会
GPT-3如何学习
-
零样本学习:提供任务描述、提示
-
单样本学习:提供任务描述、一个样例、提示
-
少样本学习:提供任务描述、几个样例、提示

数据集
| 模型 | 发布时间 | 参数量 | 预训练数据量 |
|---|---|---|---|
| BERT-large | 2019 年 3 月 | 3.75 亿 | 约3.3GB |
| GPT | 2018 年 6 月 | 1.17 亿 | 约 5GB |
| GPT-2 | 2019 年 2 月 | 15 亿 | 40GB |
| GPT-3 | 2020 年 5 月 | 1,750 亿 | 45TB |
-
BERT-large:BooksCorpus 800M words、 English Wikipedia 2.5Bwords
-
GPT:WebText2, BooksCorpus、Wikipedia超过 5GB。
-
GPT-2:WebText2, BooksCorpus、Wikipedia总量达到了40GB。
-
GPT-3:**WebText2, BooksCorpus、Wikipedia、Common Crawl **等数据集45TB数据。

image-20230221153905277
指令微调 (Instruction Fine-Tuning,IFT)
收集NLP各种任务的数据集,加上任务描述和提示组装成新的数据集。chatGPT使用到的数据集如下:
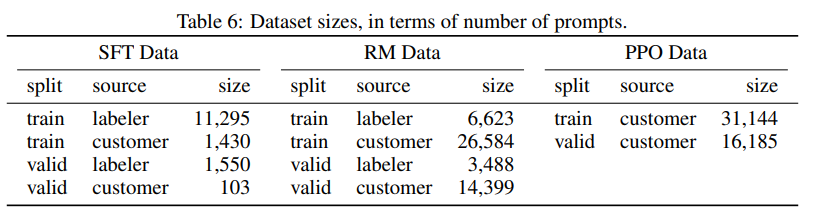
image-20230221113507381
相关的一些论文:
-
Unnatural Instructions (Honovich 等, '22): https://arxiv.org/abs/2212.09689
-
Super-natural instructions (Wang 等, '22): https://arxiv.org/abs/2204.07705
-
Self-Instruct (Wang 等, '22): https://arxiv.org/abs/2212.10560
-
T0 (Sanh 等, '22): https://arxiv.org/abs/2110.08207
-
Natural instructions 数据集 (Mishra 等, '22): https://arxiv.org/abs/2104.08773
-
FLAN LM (Wei 等, '22): https://arxiv.org/abs/2109.01652
-
OPT-IML (Iyer 等, '22): https://arxiv.org/abs/2212.12017
有监督微调 (Supervised Fine-tuning, SFT)
此步骤未为了防止遇到敏感话题时,回复【不知道】这种无意义的回答,以加入一些人工标注数据,增加回复安全性,百级别的数据集即可完成。

相关的一些论文:
-
Google 的 LaMDA:附录 A https://arxiv.org/abs/2201.08239
-
DeepMind 的 Sparrow: Sparrow :附录 F https://arxiv.org/abs/2209.14375
人类反馈强化学习 (Reinforcement Learning From Human Feedback,RLHF)
描述:
-
策略 (policy) :一个接受提示并返回一系列文本 (或文本的概率分布) 的 LM。
-
行动空间 (action space) :LM 的词表对应的所有词元 (一般在 50k 数量级) ,
-
观察空间 (observation space) 是可能的输入词元序列,也比较大 (词汇量 ^ 输入标记的数量) 。
-
奖励函数是偏好模型和策略转变约束 (Policy shift constraint) 的结合。
此过程分为两步:
-
聚合问答数据并训练一个奖励模型 (Reward Model,RM)
-
用强化学习 (RL) 方式微调 LM
开源数据集:
Anthropic/hh-rlhf · Datasets at Hugging Face
OpenAI 使用的是用户提交的反馈。
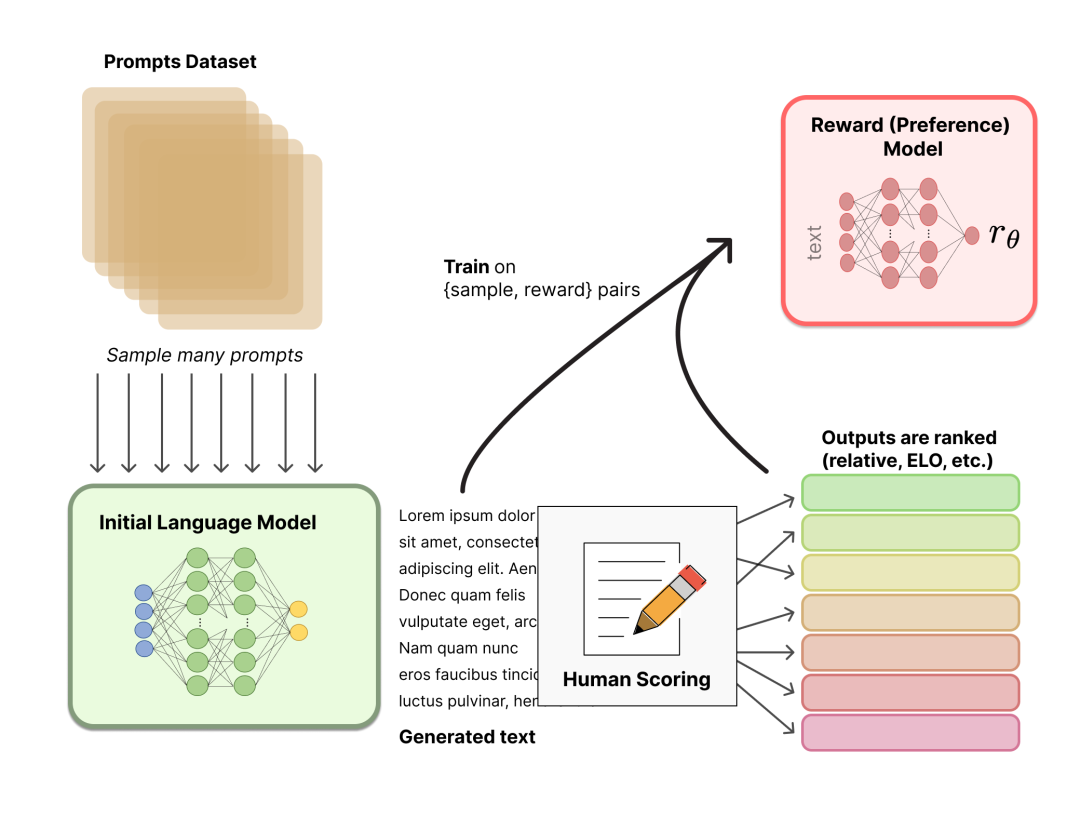
image-20230221111329526
其他方法
思维链 (Chain-of-thought,CoT)
如下图所示使用一些带有逐步推理的数据集进行微调
橙色是任务描述,粉色是问题和答案,蓝色是推理过程

思维链提示 (Wei 等, '22): https://arxiv.org/abs/2201.11903
与chatGPT类似的工作
-
Meta 的 BlenderBot: https://arxiv.org/abs/2208.03188
-
Google 的 LaMDA: https://arxiv.org/abs/2201.08239
-
DeepMind 的 Sparrow: https://arxiv.org/abs/2209.14375
-
Anthropic 的 Assistant: https://arxiv.org/abs/2204.05862
文章内容来自总结:一文搞懂chatGPT原理。
本文链接:https://my.lmcjl.com/post/9922.html
4 评论