自从去年底推出以来,对话式 AI 模型 ChatGPT 火遍了整个社区。
ChatGPT 的确是一个了不起的工具,就像一个「潘多拉魔盒」。一旦找到正确的打开方式,你或许会发现,自己再也离不开它了。
作为一个全能选手,人们给 ChatGPT 提出的要求五花八门,有人用它写论文,有人让它陪聊,这些都是常见的玩法。脑洞再打开一点,既然 ChatGPT 是 AI 中的「王者」,那它会不会写一个 AI?
近日,一位机器学习领域的博主突发奇想,他决定让 ChatGPT 构建一个神经网络,使用 Keras 解决 MNIST 问题。
技术提升
论文探讨、算法交流、求职内推、干货分享、解惑答疑,与2000+来自港大、北大、腾讯、科大讯飞、阿里等开发者互动学习。
项目源码、数据、技术交流提升,均可加交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
MNIST 算是机器学习领域的经典问题。即使这个手写数字数据集逐渐淡出了计算机视觉领域,但它的纪念意义仍然不可忽视,很多人入门深度学习的第一个数据集、验证算法的第一个实验都是 MNIST。

话不多说,想到了就开工。作者直接让 ChatGPT 写了一段代码,看上去完美无缺,甚至不需要更改任何内容。
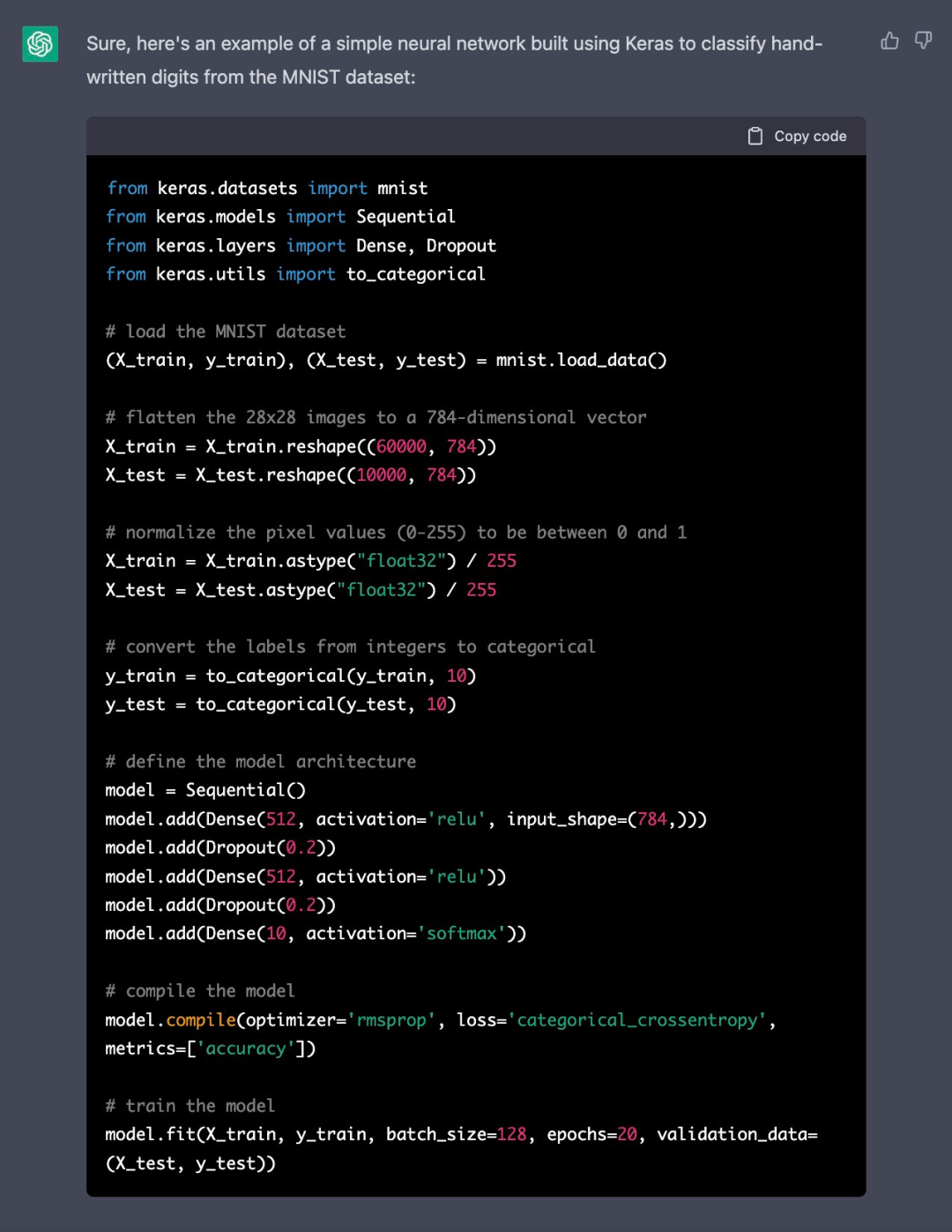
_这是一个很好的开始。
_
ChatGPT 选择了分类交叉熵作为损失函数。作者提出重写分类交叉熵这部分代码,ChatGPT 将其替换为稀疏分类交叉熵,更新之后的代码仍能 Work。可以发现,新的损失函数放弃了标签的分类转换。

ChatGPT 生成的代码使用了全连接层,但作者想使用卷积层。因此,ChatGPT 按照指示修改了代码,并添加了一个 Conv2D 和一个最大池化层(MaxPooling layer)。

然后来到了评估最终模型阶段,作者让 ChatGPT 使用测试集编写代码。

结果看起来很棒,而且 ChatGPT 的每一次回复都带有完整的解释。比如在这次评估中,它这样解释:
模型在训练期间使用了整个测试集作为验证数据。然后,作者让 ChatGPT 将其更改为训练数据的 20%。

此外,作者还想要更小的 batch 并运行更少 epoch 的代码。虽然这一步未必要用到 ChatGPT,但他不想在不更新 ChatGPT 上下文的情况下更改代码。
所以这项任务还是落在了 ChatGPT 头上:

接下来,作者打算绘制训练过程中的训练和测试损失图。ChatGPT 的建议是:需要更改适合模型的 line 以捕获其结果值。


为了展示数据集中的一些示例,作者让 ChatGPT 编写代码来输出图像和标签的组合。这些输出的代码也很完美,附有 20 张图片的合集。


构建模型时,查看其结构也是必要的。如果用这个问题去问 ChatGPT ,回复是:

ChatGPT 给出的是关于模型的总结:
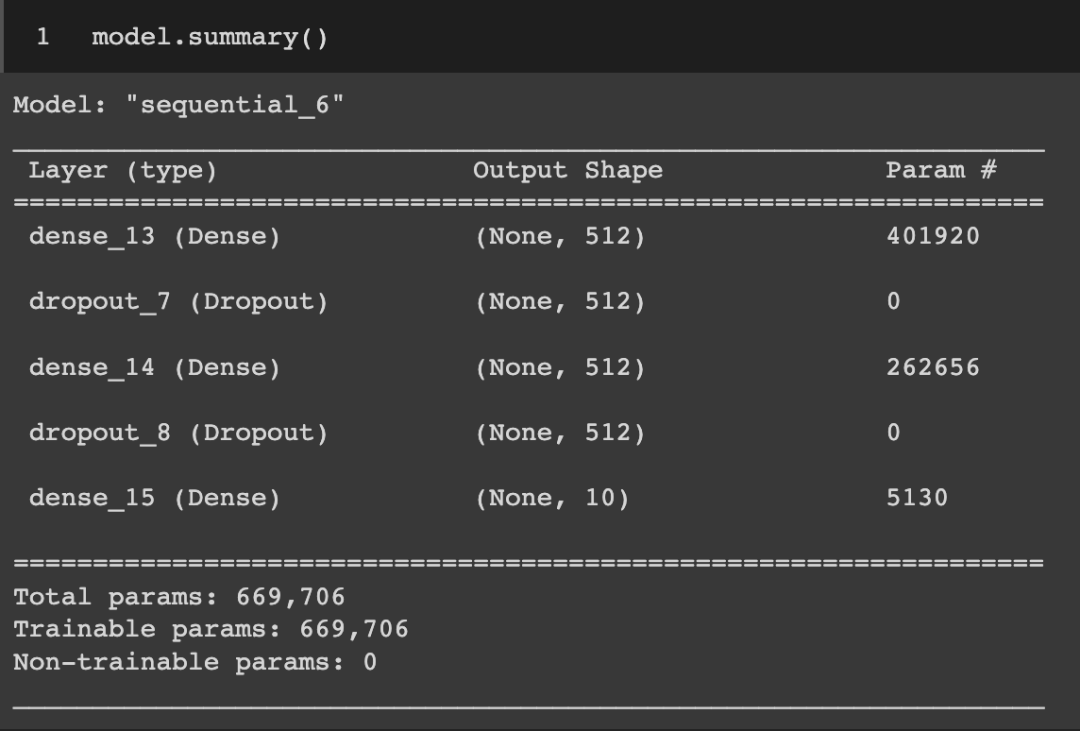
模型的总结很有用,但作者更想看到显示模型结构的图。所以继续问:


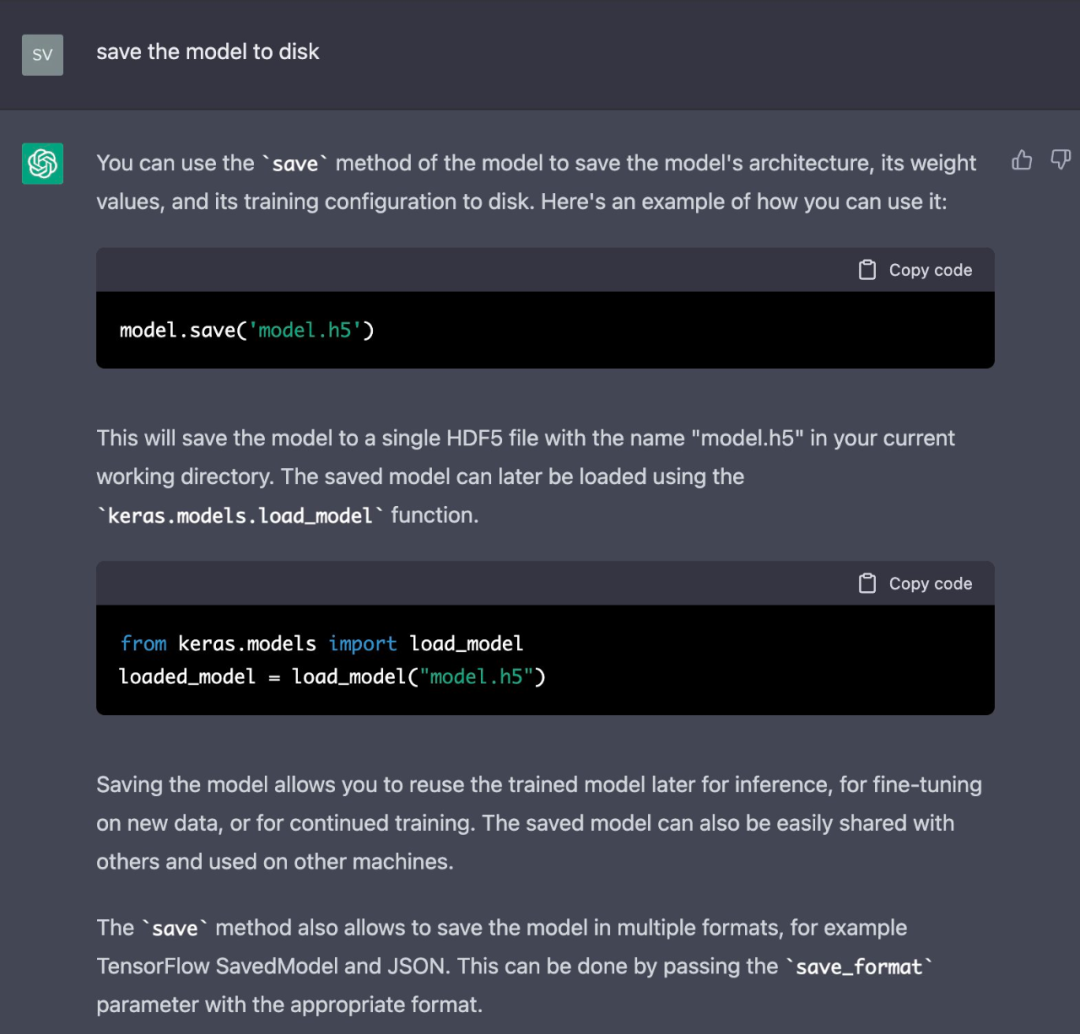
结果是满意的,最后就是准备部署这个模型了,让 ChatGPT 将模型保存到磁盘吧:
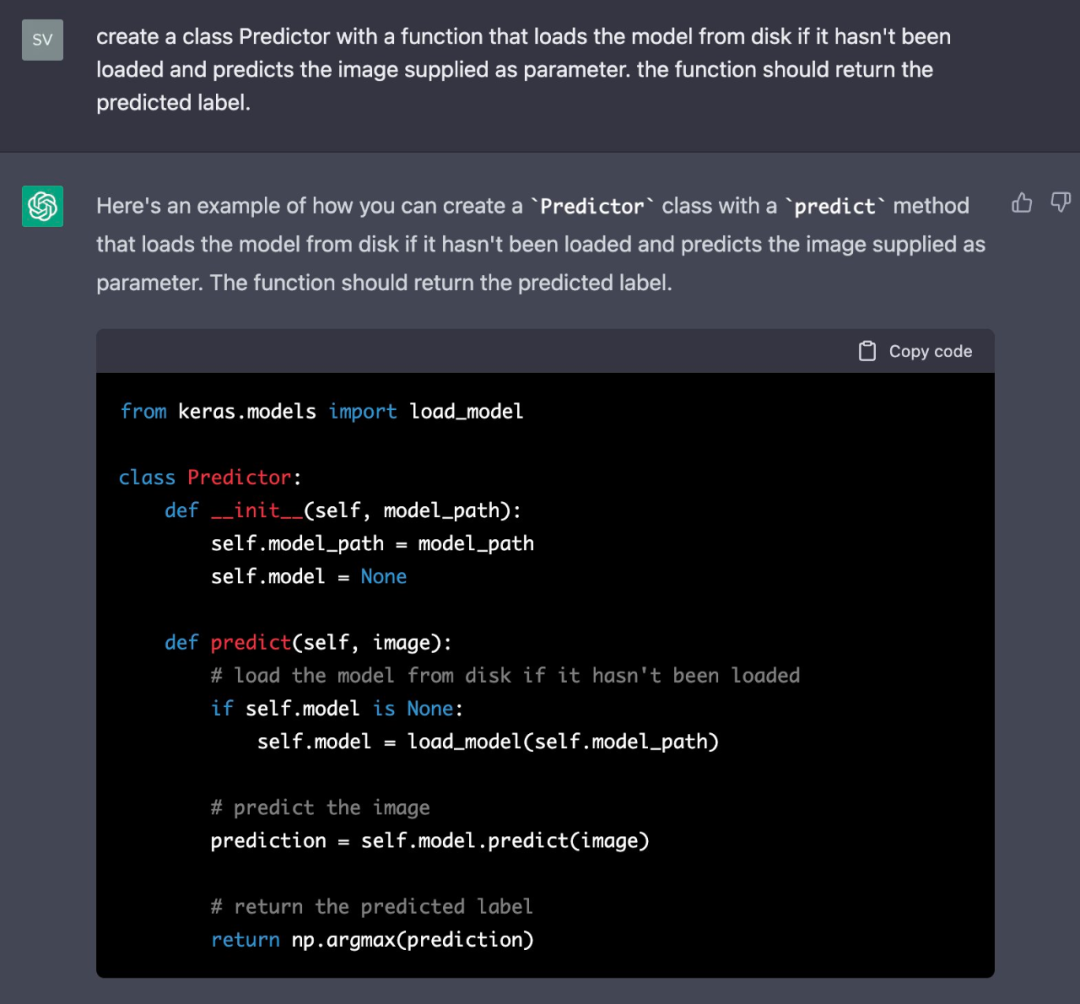
现在,作者想创建一个使用保存的模型进行预测的类。这是 prompt 很有趣,解决方案也很完美。
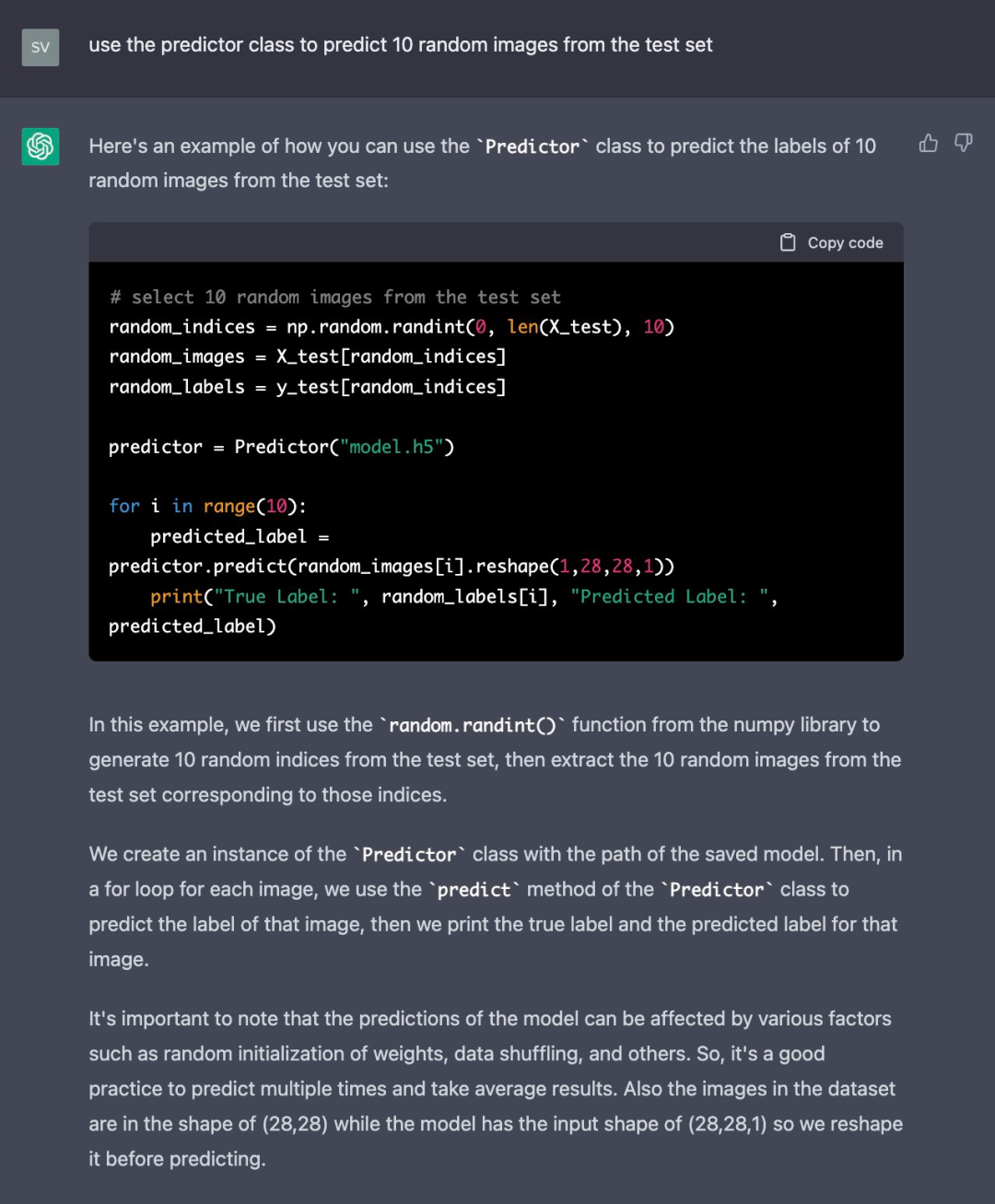
现在编写一个示例,使用预测器的类来预测 10 个随机图像的标签:
为了完成这个,作者让 ChatGPT 展示了一个混淆矩阵:
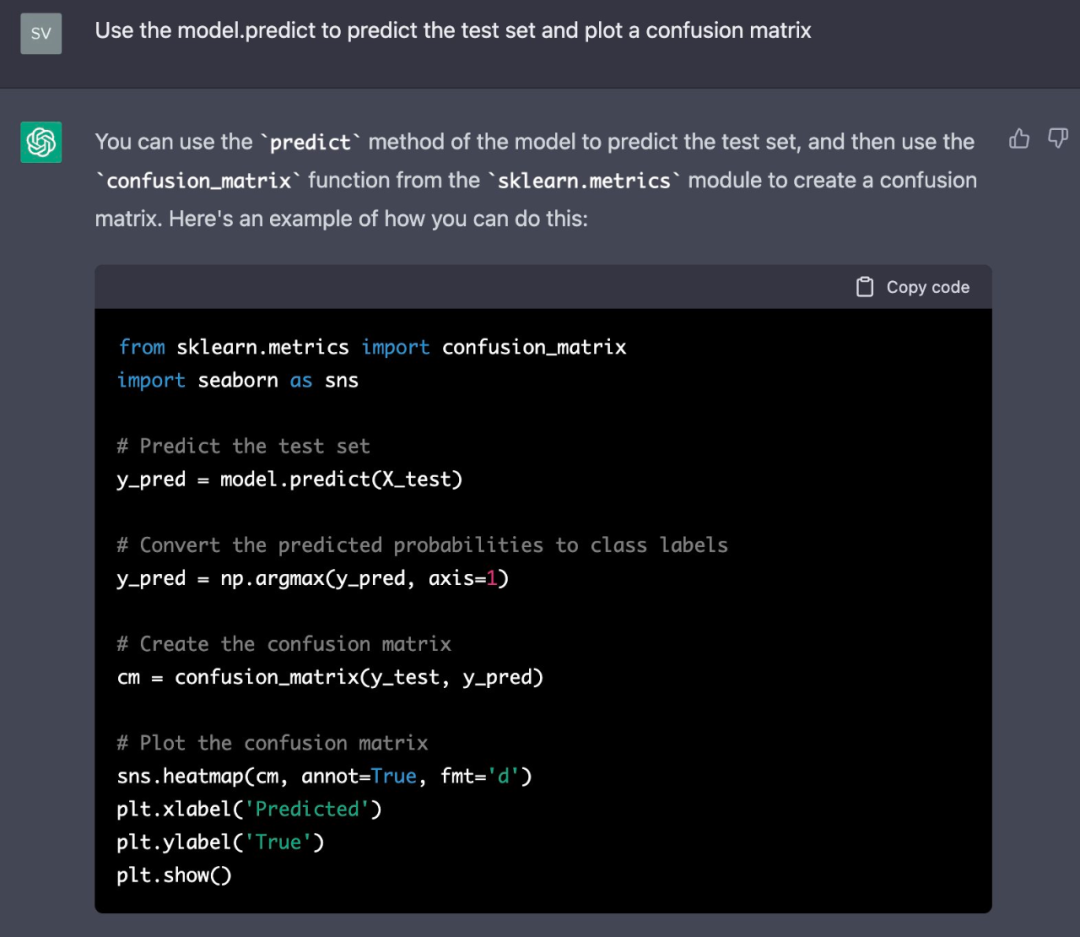
该说不说,ChatGPT 使用的样式还真挺好看。

完成所有试验后,作者将所有 ChatGPT 生成的代码公布了出来,你也可以上手试试:
地址:https://colab.research.google.com/drive/1JX1AVIfGtIlnLGqgHrK6WPylPhZvu9qe?usp=sharing
本文链接:https://my.lmcjl.com/post/9930.html
4 评论