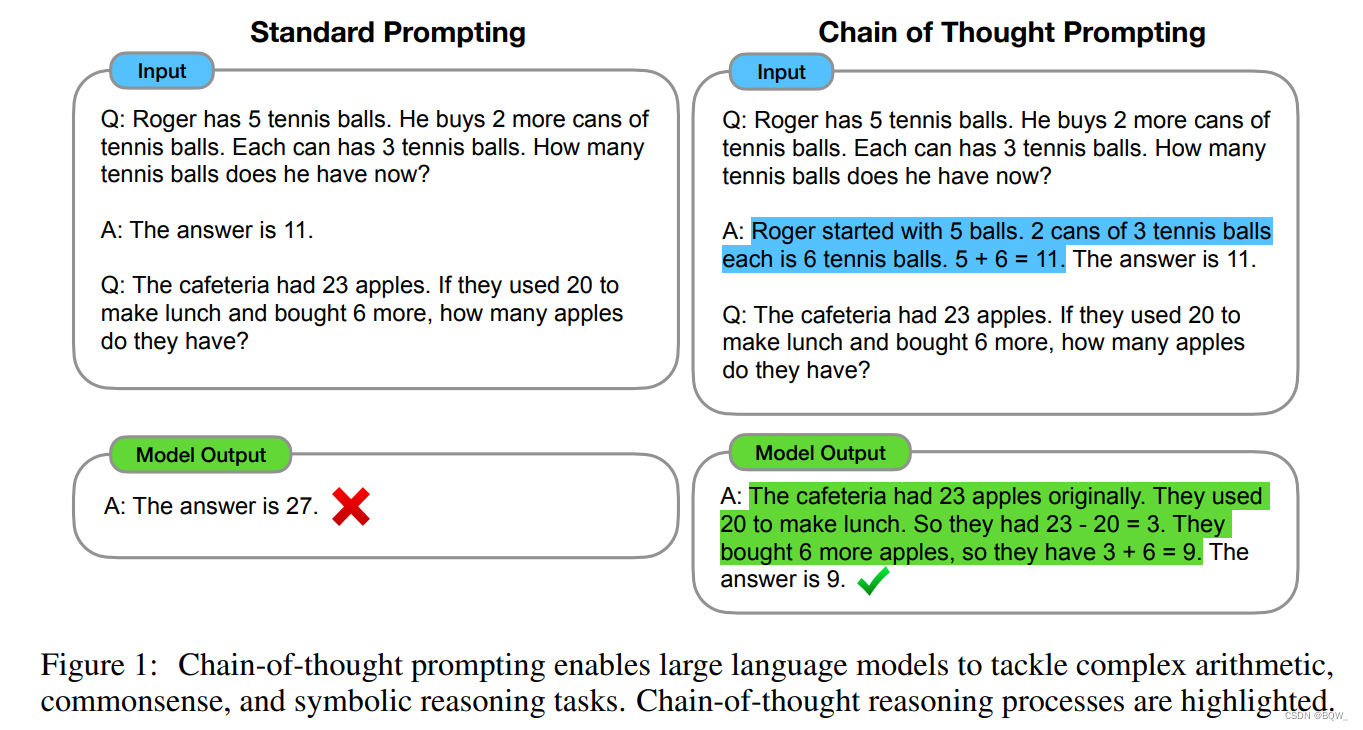
Chain-of-Thought Prompting:从大模型中引导出推理能力 《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》 论文地址:https://arxiv.org/pdf/2201.11903.pdf 一、简介 语言模型为自然语言处理带来了革命,而扩大语言模型规模可以提高下游任务效果、样本效率等一系列的好处。然而, 继续阅读
【自然语言处理】【ChatGPT系列】Chain of Thought:从大模型中引导出推理能力