本文基于阿里云机器学习PAI实现大语言模型Llama2低代码 Lora 微调及部署,适合想要快速开箱体验预训练模型的开发者 前言 近期,Meta 宣布大语言模型 Llama2 开源,包含7B、13B、70B不同尺寸,分别对应70亿、130亿、700亿参数量,并在每个规格下都有专门适配对话场景的优化模型Llama-2-Chat。Llama2 可免费用于研究场景和商业用途(但月活超过7亿以上的企业需要申请 继续阅读
Search Results for: 开源LLM微调训练指南
查询到最新的12条
训练ChatGPT的必备资源:语料、模型和代码库完全指南

前言近期,ChatGPT成为了全网热议的话题。ChatGPT是一种基于大规模语言模型技术(LLM, large language model)实现的人机对话工具。但是,如果我们想要训练自己的大规模语言模型,有哪些公开的资源可以提供帮助呢?在这个github项目中,人民大学的老师同学们从模型参数(Checkpoints)、语料和代码库三个方面,为 继续阅读
深入解析大型语言模型:从训练到部署大模型
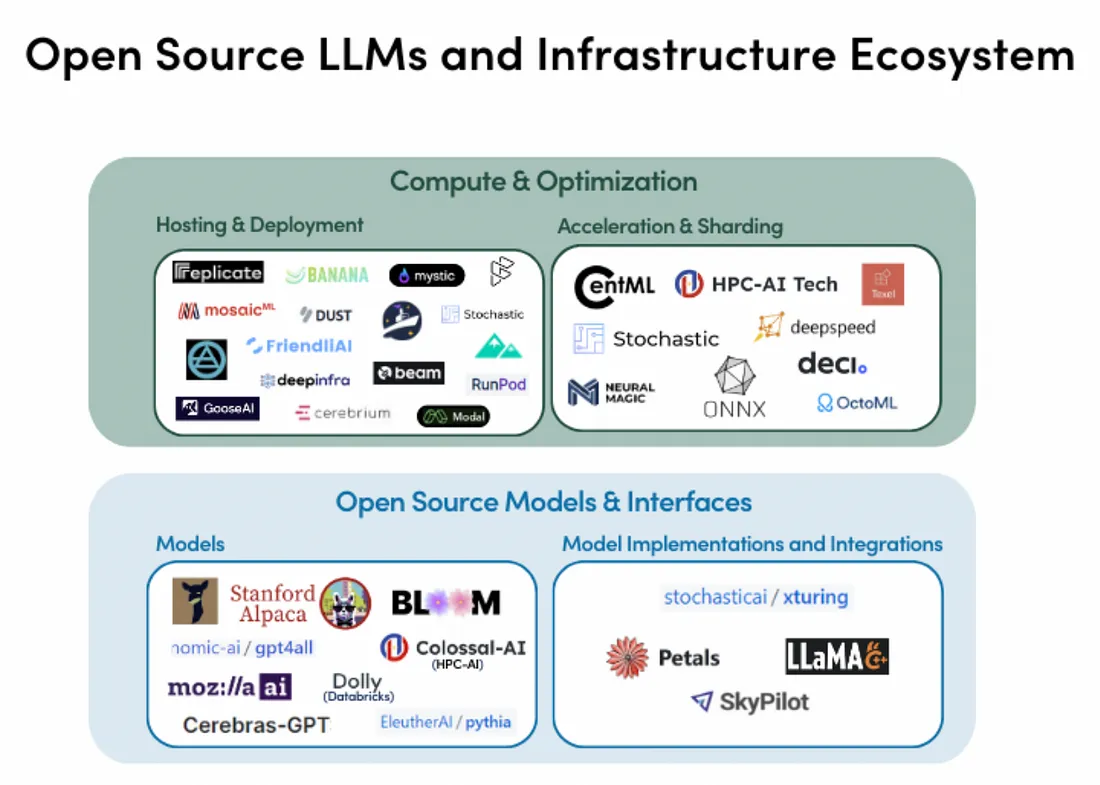
简介 随着数据科学领域的深入发展,大型语言模型—这种能够处理和生成复杂自然语言的精密人工智能系统—逐渐引发了更大的关注。 LLMs是自然语言处理(NLP)中最令人瞩目的突破之一。这些模型有潜力彻底改变从客服到科学研究等各种行业,但是人们对其能力和局限性的理解尚未全面。 LLMs依赖海量的文本数据进行训练,从而能够生成极其准确的预测和回应。像GPT-3和T5这样的LLMs在诸如语言翻译、问答、以及摘要等多个NLP任务中已经 继续阅读
Chatgpt训练过程使用的是什么平台和技术
在ChatGPT的训练过程中,使用了Docker等容器技术来支持实现训练过程中不同组件之间的隔离,并且使部署和运行更加快速和可靠。 Docker是一种开源的容器化平台,可以创建、部署和运行应用程序的容器。使用Docker技术,可以先将训练任务需要的环境和软件组件打包到容器镜像中,然后在不同的系统和环境中使用该容器镜像,使系统间的组件隔离,降低不同组件之间产生干扰和冲突的概率,保证训练 继续阅读
国内用户轻松训练类ChatGPT等大语言模型,使得人人都能拥有自己的ChatGPT!

4月12日,微软宣布开源了Deep Speed Chat,帮助用户轻松训练类ChatGPT等大语言模型,使得人人都能拥有自己的ChatGPT!(国内chatgpt平台阿猫智能机器人项目合作地址:3AMaoGptChat, AI, APIhttp://1search.top/ 据悉,Deep Speed Chat是基于微软Deep Speed深度学习优化库开发而成,具备训练、强化推理 继续阅读
国产开源类ChatGPT模型,ChatGLM-6b初步微调实验
ChatGLM-6b初步微调实验 chatglm-6b微调/推理, 样本为自动生成的整数/小数加减乘除运算, 可gpu/cpu chatglm-6b fine-tuning/inference, The sample is an automatically generated, integer/decimal of add, sub, mul and div operation, that can be gpu/cpu 项目地址 https://github.com/yongzhuo/ch 继续阅读
国产开源ChatGPT模型对比
国产开源ChatGPT模型对比(大雾) 概述 为什么要做国产开源ChatGPT模型对比呢(大雾),答案显而易见嘛。最近尤其是这阵子ChatGPT爆火, 2月3日在ChatGPT推出仅两个月后,它在2023年1月末的月活用户已经突破了1亿,成为史上用户增长速度最快的消费级应用程序。 而要达到这个用户量,TikTok用了9个月,Instagram则花了2年半的时间。作为一款聊天机器人,凭借大规模预训练模型GPT3 继续阅读
ChatGPT开源平替(2)llama
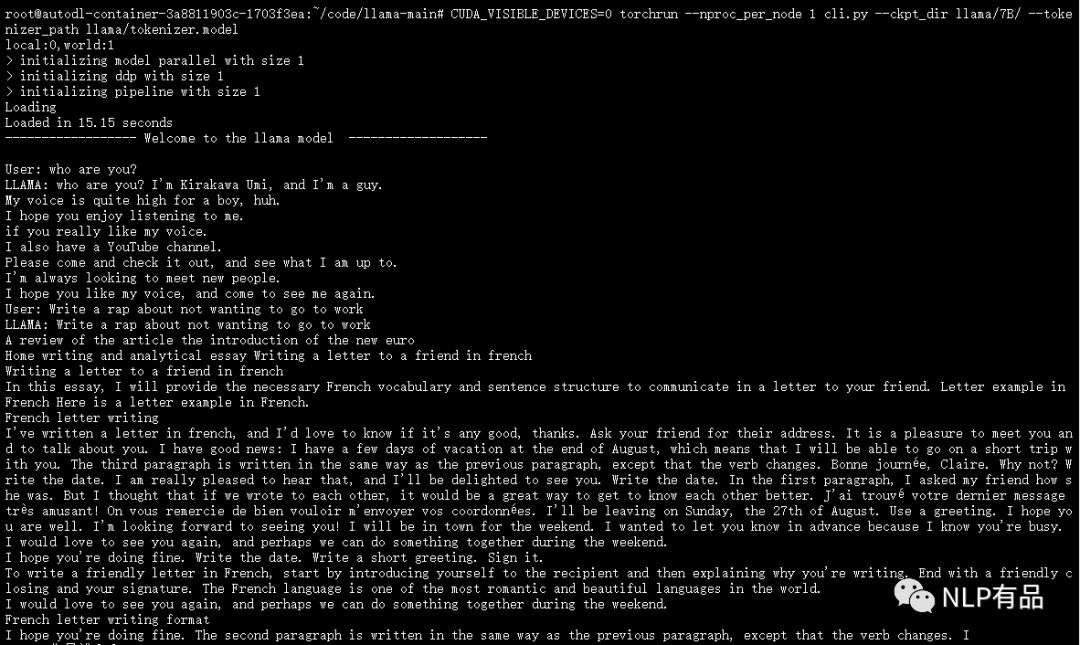
最近,FacebookResearch 开源了他们最新的大语言模型 LLaMA,训练使用多达14,000 tokens 语料,包含不同大小参数量的模型 7B、13B 、30B、 65B,研究者可以根据自身算力配置进行选择。 经过测试,(1)在算力要求上,7B的模型,需要19G显存要求,单卡3090可部署。(2& 继续阅读
一种平价的chatgpt实现方案,基于清华的 ChatGLM-6B + LoRA 进行finetune.(ai
** 清华大学的chatglm-6b开源模型对话能力虽然能基本满足对话需求,但是针对专业领域和垂直领域回答显得智商捉急,这个时候就需要进行微调来提升效果,但是但是同学们显卡的显存更捉急,这时候一种新的微调方式诞生了,现在大火的ai作画里面的lora训练方式直接应用到微调里面,chatglm-lora方式进行微调** 下面是是教程和注意事项 第一步 下载代码 git clone https://github.c 继续阅读
【自然语言处理】【大模型】Chinchilla:训练计算利用率最优的大语言模型

Chinchilla:训练计算利用率最优的大语言模型 《Training Compute-Optimal Large Language Models》 论文地址:https://arxiv.org/pdf/2203.15556.pdf 一、简介 近期出现了一些列的大语言模型(Large Language Models, LLM),最大的稠密语言模型已经超过了500B的参数。这些大的自回归transformers已经在各个任务上展现 继续阅读
本地化部署AI语言模型RWKV指南,ChatGPT顿时感觉不香了。
之前由于ChatGpt处处受限,又没法注册的同学们有福了,我们可以在自己电脑上本地化部署一套AI语言模型,且对于电脑配置要求也不是非常高,对它就是RWKV。 关于RWKV RWKV是一个开源且允许商用的大语言模型,灵活性很高且极具发展潜力,它是一种纯 RNN 的架构,能够进行语言建模,目前最大参数规模已经做到了 14B,该模型训练由Stability赞助。本文发布时R 继续阅读
huggingface - PEFT.参数效率微调

GitHub - huggingface/peft: 🤗 PEFT: State-of-the-art Parameter-Efficient Fine-Tuning. 最先进的参数高效微调 (PEFT) 方法 Parameter-Efficient Fine-Tuning (PEFT) 方法可以使预训练语言模型 (PLM) 高效适应各种下游应用程序,而无需微调模型的所有参数。微调大型 PLM 的成本通常高得令人望而却步。在这方面,PE 继续阅读