我们大流量采集站课程录制出来后需要用到一些工具软件来采集内容,其实这些采集工具,软件使用起来都挺简单的,大多数需要用到的参数我都是配置好了之后直接导出来的。 但是为了防止很多新手朋友拿到软件不会使用,所以我录制了一份使用教程供咱们展友会朋友使用。 一般情况下很多人采集内容都是用火车头直接针对不同的网站,撰写不同的采集规则来实现采集别人网站内容。 但这样采集会出现一个问题,就是基本上都是采集别人网站已有的内容,我个人不太愿意去采集一些 继续阅读
聚沙计划第三节:火车头/py工具批量采集

查询到最新的12条
我们大流量采集站课程录制出来后需要用到一些工具软件来采集内容,其实这些采集工具,软件使用起来都挺简单的,大多数需要用到的参数我都是配置好了之后直接导出来的。 但是为了防止很多新手朋友拿到软件不会使用,所以我录制了一份使用教程供咱们展友会朋友使用。 一般情况下很多人采集内容都是用火车头直接针对不同的网站,撰写不同的采集规则来实现采集别人网站内容。 但这样采集会出现一个问题,就是基本上都是采集别人网站已有的内容,我个人不太愿意去采集一些 继续阅读
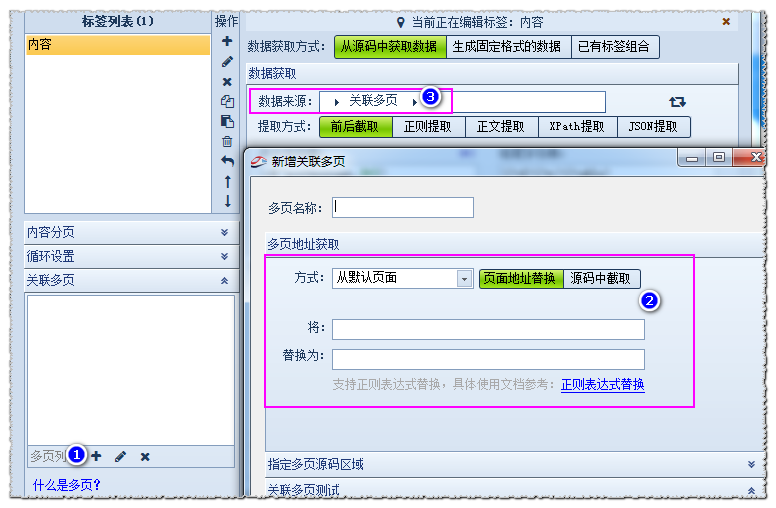
我们以内容页网址http://kimi201406.1688.com/page/creditdetail.htm为例,来获取它的公司介绍和联系方式页面的联系方式信息。 公司介绍在网址http://kimi201406.1688.com/page/creditdetail.htm里获取,而联系方式信息在网址http://kimi201406.1688.com/page/contactinfo.htm里获取。所以我们需要借助多页功能来实现。前者叫默认页地址,后者叫做多页地 继续阅读
这里是刘小顺的旅行和生活研究所。 青岛是我国山东省经济最发达的第一大城市,同时也是一座著名的海滨旅游城市,青岛因其独特的海滨风光以及中西合璧的人文特色而吸引着大量游客来到青岛旅游。 如果你来过山东青岛旅游的话,除了大家都非常熟悉的著名旅游景点之外,还有一个地方肯定会给你留下非常深刻的印象,那就是青岛火车站。 青岛火车站位于山东省青岛市市南区的泰安路,这里是青岛老城区的中心地段,临近青岛的著名地标“栈桥”,位置可以说是相当优越的。 继续阅读
本文将从多个方面详细讲解如何使用Python采集抖音数据,希望本文能对初学者有所帮助。 一、安装必要的包和工具 在采集抖音数据之前,我们需要安装一些必要的包和工具。首先需要安装Python,建议安装最新版本的Python 3。在安装Python之后,我们需要安装一些第三方包,包括requests、pymongo、beautifulsoup4等。 pip install requests pip install pymongo pip install beaut 继续阅读
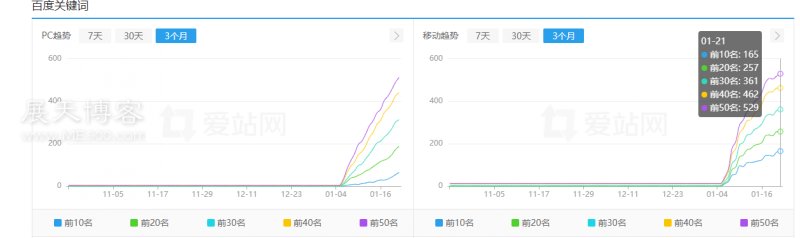
说起做网站,做采集站,又回到了老本行了哈,展天2010年接触互联网之后先是做的淘宝,然后就是做网站,并且基本都是采集站。 并且这些年采集站手上一直都有,也陆陆续续有变现,因为采集站简单粗暴,不需要花太多的时间在上面,每天大概一个小时不到就能完成一个网站的维护,所以一直当成一个项目再做。 那么采集站怎么做: 采集站如其名,就是靠采集来的,采集就是采集不是很多人说的那种每天复制粘贴几篇文章就叫采集了,很多采集站的数据都是几十上百万,非常夸张! 继续阅读

2022.9.10日更新大流量进阶课程。 录制这套课程之前就已经做好了录制计划,因为网站涉及的东西非常多,所以咱们这套大流量采集站采用阶段性录制。 第一套课程重点讲的是稍微基础东西,比如做站前的准备工作,网站布局,关键词设置,关键词挖掘整理,网站数据填充等。 进阶课程主要是讲,新上线的站点如何快速起站,网站优化逻辑,以及变现优化方面的问题。 比如常见的网站上线没有蜘蛛抓取,网站页面优化逻辑,以及如何大批量为网站制作高质量页面,以及网 继续阅读
之前有同学纳闷,为什么就是做网站,但你的课程分为了两种,一种是采集站赚钱,另一个又是做运营站赚钱。 难道这两者之间有什么区别吗? 肯定有区别的,并且区别还是非常的大。 下面咱们就简单的来说一下采集站和运营站的区别,希望给一些朋友一些参考。 一句话概括就是:采集站做第三方工具权重和泛流量,运营站做精准流量变现 对于一些新手来说,他们并不清楚其中的区别,但是对于很多运营站长他们就非常明白其中的关系。 采集站 采集站顾名思义就是采集大量内容的网 继续阅读

在之前的文章 “安装独立的 Elastic Agents 并采集数据 - Elastic Stack 8.0”,我们详述了如何使用 No Fleet Server 来把数据写入到 Elasticsearch 中。在今天的文章中,我们来详述如下使用 Elastic Agents 在独立(standalone)模式下来采集数据并把数据最终通过 Logstash 来写入到 Elasticsearch 中去。 在今天的练习中,我 继续阅读

在互联网上做内容就是做流量,但是我们很多人知识储备非常有限,写不出来比较优秀文章,很多人觉得原创文章非常费力,那么就不要勉强自己。 这个时候我们只需要做两件事即可。 收集–改编 …. 当下互联网优质内容比较多的几个平台,知乎,公众号,头条。 特别是知乎上面有很多优质的回答文章,这个时候如果我们想整理一部分文章出来,一篇一篇去复制,太费力了。 所以聚沙计划第二节给大家说一个批量采集知乎文章的方法,按照此方法 继续阅读
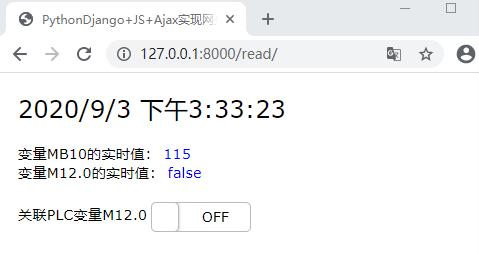
Python-snap7与S7-1500的通讯可以查阅前几篇。篇末演示功能实现的效果。利用PythonDjango+JS+Ajax技术来实现:网页发送读写请求至服务器,服务器写入数据至PLC,并读取相关数据返回网页前端,网页动态显示PLC变量的实时值。简单示例:一、使用Pycharm创建Django工程1、New Project --->Django --->填写项目名称(在More Setti 继续阅读
去年一直忙于手头上一点小项目,就没有更新公众号,网站也是随机更新,有时间就写两篇,没有时间就放在那里。 就算是写文章也是针对搜索引擎而写,并没有发布到公众号上面。 因为我觉得公众号上面的文章至少稍微有点自己的心得感悟,放在公众号上面才算是一篇合格的文章。 所以,去年几个月写了差不多上百篇文章都没有发布到公众号上面。 直到今天我想把这些文章搬运到我的另外一个公众号上面,结果发现了一个非常尴尬的事情。 有人把我的这些文章全部搬到公众号上 继续阅读
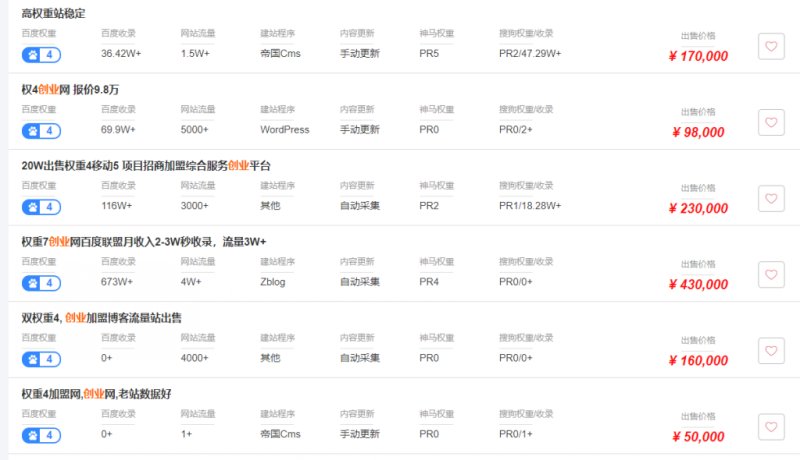
这几天把xx联盟打包出售了,这个博客站才是自己拿在手上运营的,xx联盟几乎就没有怎么管过,后面都是直接挂着采集的。 xx联盟最开始就是因为很多人采集我原创文章站,然后就弄了个域名,对着采。 之前关于采集站和文章搬运这篇文章也说过,搞到现在差不多了,也就卖了。 因为xx联盟一直都是留的我的联系方式,现在卖了,也就发了一个朋友圈说明了一下,以前的一些广告主,还有一些业务合作自行去辨别,因为现在网站已经打包出售了,所以也就失去了对于网站的管理权 继续阅读