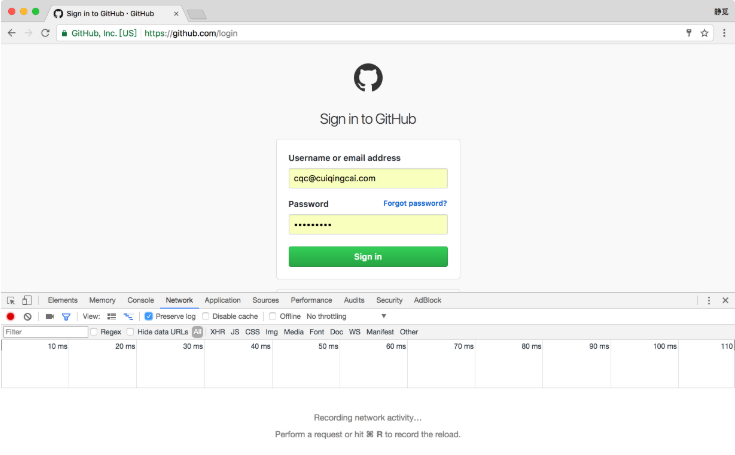
我们先以一个最简单的实例来了解模拟登录后页面的抓取过程,其原理在于模拟登录后 Cookies 的维护。 1. 本节目标 本节将讲解以 GitHub 为例来实现模拟登录的过程,同时爬取登录后才可以访问的页面信息,如好友动态、个人信息等内容。 我们应该都听说过 GitHub,如果在我们在 Github 上关注了某些人,在登录之后就会看到他们最近的动态信息,比如他们最近收藏了哪个 Repository,创建了哪个组织,推送了哪些代码。但是退出登录之后,我们就无 继续阅读
Python3以GitHub为例来实现模拟登录和爬取的实例讲解